

Практически невозможно найти двух людей, которые отформатировали бы даже самый простой SQL-запрос одинаково. Причем каждый будет абсолютно уверен, что именно его стиль наиболее понятный и правильный. Что приводит к спорам и баталиям на code review, а самое главное к трудностям при чтении чужих запросов. Не существует и какого-нибудь большого авторитетного style-guide для SQL, какие существуют для других языков. И все решается в основном делом вкуса, о котором как известно не спорят. Возможно проблема в отсутствии теоретической основы, некого физического обоснования почему стоит придерживаться каких либо определенных правил при оформлении SQL кода. Давайте попробуем разобраться.
Примечание от переводчика:
Этот небольшой текст неожиданно вызвал довольно бурное обсуждение на Reddit'е, поэтому я решил поделиться им на Хабре.
Если я прихожу, например, на очередной Java-проект, то просто настраиваю авто форматирование в IDEA согласно внутренним или внешним стандартам кодирования, а за тем, чтобы у всех было все одинаково и понятно, следит внимательный и беспощадный Checkstyle на процессе сборки. Можно немного поспорить по поводу места открывающей фигурной скобки, однострочных if'ов для особо принципиальных, ну может быть еще несколько мелочей. Но по большому счету все более-менее уже успокоились, и в других языках и платформах дела обстоят примерно так же, но только не в SQL.
И это ожидаемо, ввиду декларативной природы SQL. В императивных языках мы определяем и контролируем порядок выполнения операций, и это напрямую отражается на форматировании — отступы, переносы, скобки и пр. Но при написании SQL запроса мы понятия не имеем в каком порядке он будет исполняться и это лишает нас важной точки опоры. В результате мы не имеем единого принятого стиля оформления, каждый опирается на своё чувство прекрасного.
Но почти все эти разные стили (каждый из которых хорош по своему) имеют одну общую деталь. В типографике это называется "коридор" и считается дефектом верстки. Для примера рассмотрим простой запрос. Коридор (отмечен красным) визуально разрывает наш запрос на 2 неаккуратных куска и взгляд (особенно читающего впервые) проваливается в него, теряется в соседних коридорах (прям как в Хогвартсе), тем самым отвлекая внимание от ключевых конструкций запроса и усложняя его понимание:
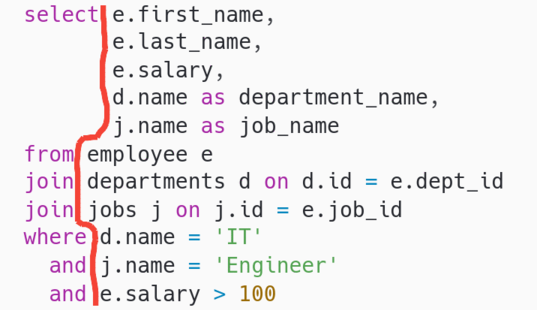
Но Легендарный Джо Селко в своей книге "Стиль программирования Джо Селко на SQL" предлагает пойти дальше и вытягивать SQL коридоры в вертикальные оси, что задает единую структуру всему запросу, конструктивно выделяет его отдельные части и облегчает его чтение и понимание. Рассмотрим тот же запрос, но с осью вместо коридора:
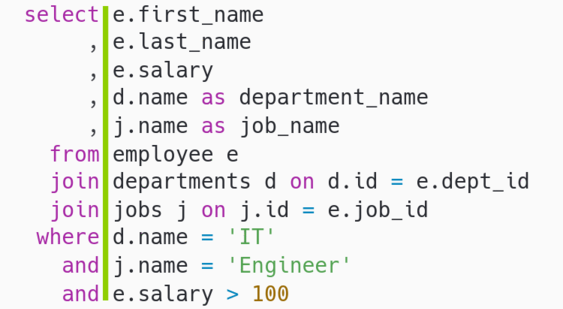
Теперь визуально весь запрос "закреплен" на оси и выглядит гораздо устойчивее. А теперь более сложный пример с подзапросами:

Здесь наш взгляд сразу наталкивается на 3 оси, а в результате и на 3 соответствующих им запроса, что позволяет достаточно быстро разобраться что этот запрос делает.
В этом посте я использую свой (наверняка не самый лучший) способ построения осей, но уверен, что вы найдете свой собственный более подходящий способ.
Комментарии (43)

MFilonen2
12.02.2022 21:47+3По-моему, так проблема не в форматировании, а просто в огромной вложенности этих запросов. Вы вот представьте, что код с такой вложенностью на любом другом языке кто-то бы залил на ревью – сразу бы были просьбы разнести по шагам. А здесь все как бы нормально…

EvilMan
13.02.2022 00:37+17Давайте попробуем каждый отформатировать эти два запроса (попроще и посложнее), желательно с пояснениями. Может кому-то чьи-то идеи и понравятся и пригодятся. Начну, пожалуй.
/* запрос попроще */ SELECT e.first_name, e.last_name, e.salary, d.name AS department_name, j.name AS job_name FROM employee e JOIN departments d ON d.id = e.dept_id JOIN jobs j ON j.id = e.job_id WHERE d.name = 'IT' AND j.name = 'Engineer' AND e.salary > 100 ; /* запрос посложнее */ SELECT e.first_name, e.last_name, e.salary, d.name, j.name, ( SELECT SUM(o.cost) FROM orders o WHERE o.employee_id = e.id AND o.status = 'closed' ) AS sum_cost FROM employee e JOIN departments d ON d.id = e.dept_id JOIN jobs j ON j.id = e.job_id WHERE e.salary > ( SELECT AVG(se.salary) FROM employee se JOIN departments sd ON sd.id = se.dept_it WHERE d.name = 'IT' ) ;Основные моменты:
Служебные слова в верхнем регистре, чтобы за них глаз цеплялся
Визуальное разбиение запроса на секции (SELECT, FROM, WHERE, GROUP BY и т.п.)
Подзапросы должны бросаться в глаза
Точка с запятой на отдельной строке оставлена специально, чтобы при копи-пасте её забывать, и запрос не выполнялся сразу при вставке.

unsignedchar
13.02.2022 00:54Так лучше. Коридор с точки зрения типографики, возможно, красивое. Но лучше всё же видеть структуру заклинания.

mentin
13.02.2022 01:11+2То что надо, я так же форматирую, с одним изменением: таблицы employee и departments тут равнозначны (можно поменять местами, ничего не изменится), нет причины сдвигать правую часть JOIN вбок. Я форматирую
FROM employee e JOIN departments d ON d.id = e.dept_idИли короткий вариант,
FROM employee e JOIN departments d ON d.id = e.dept_idОбщая идея, что FROM и JOIN равноуровневые конструкции.

PsihXMak
13.02.2022 01:26+3Вот вариант от меня. Компактный, коридорно-блочный. На первый взгляд выглядит перегружено, но читается очень просто. Пользуюсь много лет.
/* запрос попроще */ SELECT e.first_name, e.last_name, e.salary, d.name AS department_name, j.name AS job_name FROM employee e JOIN departments d ON d.id = e.dept_id JOIN jobs j ON j.id = e.job_id WHERE d.name = 'IT' AND j.name = 'Engineer' AND e.salary > 100; /* запрос посложнее */ SELECT e.first_name, e.last_name, e.salary, d.name, j.name, ( SELECT SUM(o.cost) FROM orders o WHERE o.employee_id = e.id AND o.status = 'closed' ) AS sum_cost FROM employee e JOIN departments d ON d.id = e.dept_id JOIN jobs j ON j.id = e.job_id AND ... AND ... LEFT JOIN jobs2 j2 ON j2.id = e.job_id WHERE e.salary > ( SELECT AVG(se.salary) FROM employee se JOIN departments sd ON sd.id = se.dept_it WHERE d.name = 'IT' );Служебные слова в верхнем регистре
Разбиение запросов и подзапросов на коридоры и блоки
Все служебные команды всегда с новой строки, за исключением AS
Пустой строкой можно выделять сложные блоки, требующие внимания
Скобки - всегда в одну линию
AND и OR - для каждой вложенности должен быть сделать отступ
Внутри блока, можно комбинировать что угодно и как угодно без ограничений, если это соответствует предыдущим правилам
Можно делать бесконечное количество вложенных запросов, но, при этом они все будут выглядеть одинаково, компактно и читаемо
Схемка


shashurup
13.02.2022 08:26Мне идея с коридором тоже понравилась, до тех пор пока я LEFT OUTER JOIN не написал :(
PsihXMak
13.02.2022 10:00В моём варианте эта проблема решена
SELECT * FROM tabel1 t1 LEFT OUTER JOIN table2 t2 ON t2.id = t1.id RIGHT INNER JOIN table3 t3 ON t3.id = t1.id WHERE ...shashurup
13.02.2022 10:20+2Дык коридор-то не получился - table2 и table3 не под table1.
PsihXMak
13.02.2022 11:40+3Идея коридора немного в другом. Коридор лишь показывает, где начинается запрос и где он прерывается.
Из своего опыта я пришёл к выводу, что читаемая структура запроса намного важнее содержания запроса, по этому, использую блоки внутри коридора. В этих блоках форматирование свободное.
Например так
Можно сказать, что выравнивание по коридору у меня с левого края. А в правой части всё довольно свободно.

RekGRpth
13.02.2022 06:30я вот так бы отформатировал
/* запрос попроще */ SELECT e.first_name, e.last_name, e.salary, d.name AS department_name, j.name AS job_name FROM employee e JOIN departments d ON d.id = e.dept_id JOIN jobs j ON j.id = e.job_id WHERE d.name = 'IT' AND j.name = 'Engineer' AND e.salary > 100; /* запрос посложнее */ SELECT e.first_name, e.last_name, e.salary, d.name, j.name, ( SELECT SUM(o.cost) FROM orders o WHERE o.employee_id = e.id AND o.status = 'closed' ) AS sum_cost FROM employee e JOIN departments d ON d.id = e.dept_id JOIN jobs j ON j.id = e.job_id WHERE e.salary > ( SELECT AVG(se.salary) FROM employee se JOIN departments sd ON sd.id = se.dept_it WHERE d.name = 'IT' );

IsUnavailable
13.02.2022 12:16+2/* запрос попроще */ select e.first_name as first_name, e.last_name as last_name, e.salary as salary, d.name as department_name, j.name as job_name from employee e join departments d on d.id = e.dept_id join jobs j on j.id = e.job_id where d.name = 'IT' and j.name = 'Engineer' and e.salary > 100; /* запрос посложнее */ select e.first_name, e.last_name, e.salary, d.name, j.name, (select sum(o.cost) from orders o where o.employee_id = e.id and o.status = 'closed') as sum_cost from employee e join departments d on d.id = e.dept_id join jobs j on j.id = e.job_id where e.salary > (select avg(se.salary) from employee se join departments sd on sd.id = se.dept_it where d.name = 'IT'); /* пример case */ select case when col_1 = 1 then 1 when col_1 = 2 and col_2 = 1 then 2 when col_1 = 3 and col_2 = 1 and col_3 = 2 and col_4 = 3 then 3 else 4 end as test_case from test_table-
Служебные слова не выделяются регистром. Это вроде как принято сообществом за условие по умолчанию, но пользуясь приведённым мной кодстайлом несколько лет, я не вижу смысла в выделении капсом. Служебные слова выделяются цветом. Это одновременно действенно и не раздражает глаз при просматривании кода.
Строки, например, не выделяются ничем кроме цвета (кавычки в расчёт не беру т.к. попробуйте отключить подсветку в запросе с кучей строк и конкатенацией) и это никак не мешает их распознаванию.
Тот самый "коридор". Это красиво) И в то же время это дополнительный уровень отделения служебных слов от остального текста. К тому же, коридор довольно простой в распознавании и написании принцип. Все служебные слова выстраиваются вдоль него, а не по какой-то сложной, ветвистой логике.
С case всё сложнее. Мне сложно сказать оптимален ли приведённый мной пример написания case даже для меня. Пока я пришёл к тому, что в зависимости от конкретной ситуации case будет лучше читаться и выглядеть в разных стилях.
Всё описанное - ИМХО, да и вообще, тема стайлгайдов как по мне хоть и имеет под собой какую-то объективную базу, но как будто бы, эта база совсем небольшая (если она там вообще есть), а вот всю остальную долю темы занимает субъективное восприятие людей, которое довольно хорошо подстраивается под разные условия. Если бы мне приходилось писать несколько лет запросы в стиле EvilMan то, вероятно, я бы так же находил плюсы в этом стиле и не хотел писать по другому :)
P.S. редактор комментариев хабра для меня загадка. При написании/редактировании подсветка SQL кода одна, а после отправки комментария - другая. Да ещё и после отправки отредактированного комментария подсветка вообще слетает, и появится только после обновления страницы.
-

vasyakolobok77
13.02.2022 12:43Безусловно это все вкусовщина, но в вашем примере код стал вертикально "выше". В последнем примере ко всему прочему добавились горизантальные пробелы. В итоге код стал "размазан", снизилась концентрация, стало немного сложнее читать.

KislyFan
13.02.2022 13:01+1На правах ИМХО
На правильность не претендует, но облегчает жизнь во время постоянного редактирования запроса.
За несколько лет работы с SQL скриптами я пришел к похожему форматированию, особенно после того как пришлось разбираться со скриптами уволившихся коллег
-- в SELECT разбиваем 100500 выводимых колонок на логические группы, -- каждая из которых начинается с новой строки SELECT e.first_name, e.last_name ,e.salary -- любое изменение будь то введение alias'a, формула и тд -- пишем с новой строки, один столбец - ода строка ,d.name AS departament_name ,j.name AS job_name -- также одна строка отступа перед FROM и перед каждым очередным JOIN -- это визуально разделяет запрос на группы FROM employee e JOIN departments d -- магическая строка 1 = 1 всегда равна TRUE и потому игнорируется -- но позволяет в КАЖДОЙ строке условия писать AND в начале строки -- по той же причине по которой мы пишем "," в начале строки в SELECT ON 1 = 1 AND d.id = e.dept_id JOIN ( -- в простых запросах скорее всего нет смысла делать отступы перед FROM или WHERE -- это усложнит чтение SELECT * FROM jobs WHERE 1 = 1 AND REGEXP_LIKE(name, '([^=,]+)', 1, 4) = 'WTF' ) j ON 1 = 1 AND j.id = e.job_id WHERE 1 = 1 AND d.name = 'IT' -- AND e.last_name <> 'Ivanov' AND j.name = 'Engineer' AND e.salary > 100Так же с недавнего времени пришел к выводу, что если мы не придерживаемся синтаксиса полного именования
schema.departament.name = schema.wfttable.departamentа пользуемся псевдонимами для таблиц, то это очень быстро родит путаницу с названиями полей. Поэтому на мой взгляд, несмотря на лаконичность названий id, name, description и других "общих" названий и зарезервированных ключевых слов, стоит называть их как departament_id, departament_name, departament_description и тд.

shane54
13.02.2022 15:52С условием "1=1" в каждом запросе "для красоты" (для удобства последующего комментирования одного или другого условия WHERE) нужно быть осторожным, как минимум в Oracle иногда, в совсем сложных случаях, добавление условия "1=1" является "трюком", с помощью которого заставляют оптимизатор поменять свое поведение в ту или иную сторону. Не вдаваясь в детали, просто стоит помнить что "1=1" может иметь значение для выполнения конкретного SQL запроса.
KislyFan
13.02.2022 16:05Я сравнивал планы запроса и что-то не заметил разницы. Может быть были неподходящие примеры..

nikolayv81
14.02.2022 10:08Это трюк для того чтобы перестать использовать сохранённый план, т.к. hash запроса меняется, может помочь с т.н. "прибитыми гвоздями" планами, но если лезть в такие дебри, то тут уже не до красоты....
В дополнение про стиль, сам предпочитаю для join использовать:
Отступ от линии from на два пробела
Написание inner join/left join
on в новой строчке с отступом 2 пробела от линии join
В условии on для условий длиной более 1 сравнения используем заключение каждого условия в скобки, это позволяет выровнять визуально линию and/or-ов
Для or всегда использую скобки, что бы в итоге не получить выгрузку во всю таблицу из-за неудачного редактирования списка из 10 and-ов...
select --+ hint a.a -- comment A , b.b from tableA a left join tableB b on ( ( b.c = a.c ) and ( ( b.d > 100 ) or ( b.x <> a.x ) ) ) where ( ( a.y like 'n%' ) and ( a.z = 1 ) )Т.е. по факту у нас избыток скобок (что к примеру ломает автоподмтановку в Terrada SQL Assistant, Но это мелочи), но при этом более менее видны границы условий что важно на некоторых запросах под 100 строк с CTE (with)

Akina
13.02.2022 18:13Логические операторы в условиях должны быть на одном уровне, если они на одном уровне (пардон за тавтологию).
То есть правильно
WHERE {condition 1} AND {condition 2}а вовсе даже не
WHERE {condition 1} AND {condition 2}Во втором случае приходится глазами прыгать в сторону, чтобы понять, как именно объединяются условия в выражении... а если выражение длинное, и оператор за границами экрана? тогда как первый вариант не прячет "скелет" выражения.
А вот если выражение сложное, и приоритет задаётся скобками - то тут используем обычное форматирование, применяемое для логических выражений, с форматирующими отступами.

Kilor
14.02.2022 09:03+1Мои 5 копеек (вот тут живет форматтер по этим правилам):
SELECT e.first_name , e.last_name , e.salary , d.name department_name , j.name job_name FROM employee e JOIN departments d ON d.id = e.dept_id JOIN jobs j ON j.id = e.job_id WHERE d.name = 'IT' AND j.name = 'Engineer' AND e.salary > 100; SELECT e.first_name , e.last_name , e.salary , d.name , j.name , ( SELECT sum(o.cost) FROM orders o WHERE o.employee_id = e.id AND o.status = 'closed' ) sum_cost FROM employee e JOIN departments d ON d.id = e.dept_id JOIN jobs j ON j.id = e.job_id WHERE e.salary > ( SELECT avg(se.salary) FROM employee se JOIN departments sd ON sd.id = se.dept_it WHERE d.name = 'IT' );служебные слова в uppercase, чтобы сразу бросались в глаза
смещение "уровня" в 2 пробела
запятые в начале, чтобы иметь возможность быстро закомментить столбцы - кроме первого, который обычно является ключевым и нужен всегда
ASубирается везде, где это допустимоWITH-SELECT-FROM-JOIN-WHERE-GROUP-HAVING-ORDER-LIMITзадают первый уровень запроса, таблицы и WHERE-условия - второй,ON- третийподзапросы всегда с новой строки



shavluk
13.02.2022 03:57+2Как будем LEFT JOIN форматировать?
shashurup
13.02.2022 08:27LEFT OUTER JOIN - еще веселей и реалистичнее.

pankraty
13.02.2022 08:56+5Ну, OUTER в принципе избыточно, т.к. LEFT подразумевает OUTER. Но ваш вопрос вполне актуален для случаев, когда нам надо написать LEFT MERGE JOIN или INNER HASH JOIN, например.
Лично мне вариант с коридорами неудобен тем, что от замены одного оператора может поползти верстка большого куска запроса (в пределе - запроса целиком). Заменил один LEFT на INNER - и либо нарушил аккуратное форматирование ("ад перфекциониста"), либо получил diff на 200 строк.
shashurup
13.02.2022 09:10+1Лично мне вариант с коридорами неудобен тем, что от замены одного оператора может поползти верстка большого куска запроса (в пределе - запроса целиком). Заменил один LEFT на INNER - и либо нарушил аккуратное форматирование ("ад перфекциониста"), либо получил diff на 200 строк.
Кстати, да - очень весомый аргумент против коридора.
shashurup
13.02.2022 09:18+2Ну, OUTER в принципе избыточно, т.к. LEFT подразумевает OUTER.
вот блин, всегда явно писал OUTER :-)
Иногда полезно перечитать документацию по, казалось бы, простым и давно понятным вещам.

Tellamonid
13.02.2022 18:48Коридор же не так работает. Пусть мы пишем простой селект. Тогда слово select будет начинаться прямо с начала строки, перед from будет два пробела, перед where – один, перед having – ни одного, перед left – два, и так далее. То есть от замены join на left join ничего не поползёт. Поползти может только если будет ключевое слово больше шести букв длиной, но это достаточно редко бывает.
select t1.a, t2.b, count(1) as cnt from t1 left join t2 on (t1.my_key = t2.my_key) where t1.city = 'CHICAGO' having count(1) > 1

Ustas4
13.02.2022 09:12+3Холивар вечен.
Можете форматировать как хотите. Но тут два фактора
Работает старый код? Не тронь
Корпоративное форматирование в приоритете

shane54
13.02.2022 12:26+2В упомянутом в статье обсуждении на Reddit (How do you format your SQL queries?), в комментах есть ссылка на библиотеку Poor Man's T-SQL Formatter - она представлена и в виде CLI, для подключения в системы сборки, в виде плагина для Visual Studio и SSMS - а также в виде online формы, куда можно скопировать "сырой" запрос и тут же увидеть результат. Повставлял туда запросы из комментов к этой статье - интересно, работает, можно всякие опции налету менять и сразу видеть результат. В общем, рекомендую пощелкать, интересно.
Правда, в описании этой библиотеки Poor SQL, автор честно признается - парсер на данный момент достаточно примитивный и множество функций не реализовано. Последняя активность в репозитории на GitHub около 2.5 лет назад.
И из этого же обсуждения на Reddit - ещё пара ссылок на релевантные статьи, чтоб уж всё полезное по теме собрать в одном месте:
shane54
13.02.2022 13:02+1И ещё вот такая мысль: в большинстве основных IDE есть кнопка "сделать красиво" - в смысле, запускается линтер и SQL запрос форматируется соответственно заданным правилам. На сколько я понимаю, нет единого стандарта для конфигов этих линтеров - в Toad for Oracle свой, в PL/SQL Developer свой, в Oracle SQL Developer свой, в IDE от JetBrains (вроде DataGrip) свой - и тд. (перечислил только инструменты для работы с Oracle, бо это моё направление). Так вот, при работе в команде, обычно же все должны следовать принятым стандартам - всякие Code Style Guide, именование версий, формат тикетов, комментов к коммитам и тд и тп. И вот для общего стандартного форматирования SQL запросов, конфиг файл с правилами для SQL линтера в IDE хранят и версионируют так же, как и другие такого рода конфиги. И новый член команды, приходя на проект и настраивая свое рабочее окружение, кроме всего прочего берет последнюю версию конфига для линтера и настраивает свою IDE "как у всех". И очевидно что проблема тут - поддержка всех разных форматов этих конфигов, если разрешено использовать IDE по своему вкусу. Будь формат конфигов стандартизирован, можно было бы и внутри проектных команд удобно и просто поддерживать свой SQL Style Guide, обновляя и дополняя его по ходу эволюции - так и "где-то в интернетах" могли бы накапливаться конфиги со всякими "стиль как в Google, в Facebook, в Microsoft" и тд - как сейчас есть различные Style Guide'ы по основным языкам программирования от больших компаний.
Xeldos
А то, что глаз спотыкается о запятые на каждой строчке - так, мелочи. Главное, красивую линию в нужном месте провести.
411
Да запятые эт отдельная тема для холивара. Те же trailing запятые (не в SQL, но к примеру в js) кто-то любит, кто-то нет (я). Кто-то для избавления от trailing запятых начинает добавлять leading запятые, примерно как в посте (не я).
Тут и люди с отступами табами могут повозмущаться.
Идея вертикальной линии мне в целом нравится, если редактор или IDE будет уметь это делать автоматом. Если нет, можно и не заморачиваться на мой взгляд.
mgramin Автор
Да, согласен, про лидирующие запятые это отдельная тема. Я там в конце статьи специально отметил, что способов для осей может быть много, это только пример.
WaterSmith
Главная польза лидирующих запятых, это при редактировании запроса, если отдельные поля удаляются, не возникает ситуации, когда запятую в конце забыли поставить, как и ситуации, когда она оказывается в конце последней строки.
Например, если в первом запросе (который с коридором) удалить строку j.name as job_name то очень легко забыть при этом удалить запятую в конце предыдущей строке. В запросе с осью, такой ситуации не возникнет.
Xeldos
Речь не о пользе, а о "красоте". И о том, что чтение строки начинается с запятой, а красивая линия проведена после нее.
vasyakolobok77
Красота всегда субъективна. Но кроме красоты здесь важна еще и функциональность, и подверженность ошибкам.
shashurup
До тех пор, пока не удалишь первое поле и будет лишняя лидирующая запятая. ИМХО, как-то принципиально проблема не решается, а выглядит ужасно.
vasyakolobok77
Большей частью это вкусовщина, но чаще столбцы добавляются и удаляются с конца, нежели с начала. Сужу сугубо по своей практике.
Akina
Лукавите.
При лидирующих запятых и удалении полей из списка вывода дополнительные телодвижения нужны только в случае, когда удаляется самое первое из полей списка вывода (ну или несколько первых). Но при финализирующих запятых всё абсолютно так же - дополнительные телодвижения нужны лишь в случае, когда удаляется самое последнее из полей списка вывода (ну или несколько последних).
Так что разницы - вообще никакой. И там, и там есть ситуация, когда "очень легко забыть при этом удалить запятую". Но забывчивость отдельно взятого программиста ну никак не может служить основанием для формирования или изменения стиля форматирования кода.
Если же сравнивать такие два стиля по-настоящему, то разница между ними имеется. При ведущих запятых "ось" располагается между двумя группами символов. Тогда как при финализирующих запятых слева от оси символов не будет.
Кстати, а как насчёт вторичных осей - в секции FROM? я насчёт выравнивания по вертикали кляуз ON. Или альтернативно - ON опускается на строку и выравнивается по оси справа. Т.е. соответственно
или
BASic_37
Польза лидирующей запятой точно такая же как и вред (ну либо польза от лидирующей такая же как от завершающающей), разница только в том когда мы словами ошибку, при удалении первого поля в запросе, либо последнего...
ATwn
Не забывайте и про то, что запятые в начале помогают контролю версий (при добавлении или удалении параметра в конце списка изменяется одна строка, а не две, т.к. нет нужды добавлять или убирать запятую в конец крайней строки).
XaBoK
У лидирующей запятой есть плюс - легко закоментить конкретную строку или вклинить еще одну. Во времена динамического построения запросов - это было очень удобно. Такой вот модулярный формат получался.
CORRECTOR86
Истинно )))) Но автор - все равно красивчик