

MemQ — это дополнение к Kafka, отделяющее аппаратную часть чтения и записи от слоя хранения данных. Разработчики Pinterest постепенно заменяют Kafka на MemQ: балансировка с ним не только проще благодаря унификации данных, но и дешевле в 10 раз. К старту флагманского курса по Data Science приглашаем под кат за подробностями.
Ввод и транспортировку всех данных Pinterest обеспечивает Logging Platform. В основе этой платформы лежат распределённые системы PubSub, помогающие нашим клиентам транспортировать/буферизировать данные и потреблять данные асинхронно.

Мы представляем MemQ (произносится «mem queue»): эффективную, масштабируемую систему PubSub для облака компании Pinterest. Эта система работает с середины 2020 года и дополняет Kafka, при этом она в 10 раз экономичнее последней.
История
Почти десять лет Pinterest полагалась на Apache Kafka как на единственную систему PubSub. По мере роста Pinterest увеличивался объём данных, возникали проблемы, связанные с эксплуатацией крупномасштабной распределённой платформы PubSub.
Работа Apache Kafka в большом масштабе дала обширное представление о том, как построить масштабируемую систему PubSub. Глубоко изучив проблемы эксплуатации и масштабируемости нашей среды PubSub, мы пришли к следующим основным выводам:
Не каждый набор данных требует обслуживания с субсекундной задержкой, задержка и стоимость должны быть обратно пропорциональны: меньшая задержка должна стоить дороже.
Компоненты хранения и обслуживания системы PubSub должны быть разделены, чтобы обеспечить независимую масштабируемость на основе ресурсов.
Упорядочивание по чтению, а не по записи обеспечивает необходимую гибкость в конкретных случаях использования потребителями: разные приложения могут иметь разные требования к одному и тому же набору данных.
Строгое упорядочивание разделов в Pinterest в большинстве случаев необязательно и часто приводит к проблемам масштабируемости.
Ребалансировка в Kafka дорого стоит, часто приводит к снижению производительности и оказывает негативное влияние на потребителей в насыщенном кластере.
Выполнение пользовательской репликации в облачной среде — это также дорого.
В 2018 году мы экспериментировали с новым типом системы PubSub, которая использовала бы облачные технологии. А уже в 2019 году официально начали изучать варианты решения проблем масштабируемости PubSub и взвесили несколько технологий этого типа на основе стоимости операций и стоимости реинжиниринга существующих технологий для удовлетворения потребностей Pinterest.
Вывод: нам нужна технология PubSub, которая основана на наработках Apache Kafka, Apache Pulsar, Facebook LogDevice и создана для облака.

MemQ — это новая система PubSub, которая в Pinterest дополняет Kafka. Она использует подобную Apache Pulsar и Facebook Logdevice архитектуру раздельного хранения и обслуживания.
Однако для хранения данных она полагается на подключаемый реплицируемый слой хранения, т. е. Object Store / DFS / NFS. В результате получается система PubSub, которая:
работает со скоростями трафика Гб/с;
масштабирует, записывает и читает независимо;
не требует дорогостоящей ребалансировки для обработки роста трафика;
на 90% экономичнее по сравнению с нашим Kafka.

Секретный ингредиент
Секрет MemQ заключается в микропакетах и иммутабельной записи, чтобы добиться архитектуры, где количество необходимых на слое хранения операций ввода-вывода в секунду (далее — IOPS) значительно ниже, что позволяет использовать облачное хранилище объектов, например Amazon S3, экономически эффективно.
Этот подход в смысле сетей аналогичен коммутации пакетов по сравнению с коммутацией каналов; иными словами это одно большое непрерывное хранилище данных, например раздел Kafka.
MemQ разбивает непрерывный поток логов на блоки (объекты), наподобие бухгалтерских книг в Pulsar, но они отличаются тем, что записываются как объекты и являются иммутабельными. Размер этих «пакетов» или «объектов», известных в MemQ как Batch, играет роль в определении задержки End-to-End (E2E).
За счёт большего количества IOPS чем меньше пакеты, тем быстрее они могут записываться. Таким образом, MemQ позволяет настраивать задержку E2E благодаря более высоким IOP.
Ключевое преимущество этой архитектуры — отделение аппаратной части чтения и записи от нижележащего слоя хранения, позволяющее записи и чтению масштабироваться независимо, в виде пакетов, которые можно распределить по слою хранения.
Это устранило ограничения Kafka, где для восстановления реплики раздел нужно повторно реплицировать с самого начала. В случае с MemQ базовое реплицированное хранилище должно восстановить только конкретный пакет, количество реплик которого уменьшилось из-за отказов хранилища.
Однако, поскольку MemQ в Pinterest работает на Amazon S3, восстановление, шардинг и масштабирование хранилища AWS выполняется без ручного вмешательства Pinterest.
Компоненты MemQ
Клиент
Клиент MemQ обнаруживает кластер с помощью начального узла и затем подключается к этому узлу, чтобы обнаружить метаданные и брокеров, размещающих TopicProcessor для данного Topic или (в случае потребителя) адрес очереди уведомлений.
Брокер
Подобно другим системам PubSub, MemQ имеет концепцию брокера. Брокер в MemQ — это часть кластера, в основном отвечающая за обработку метаданных и запросов на запись. Запросы на чтение в MemQ могут обрабатываться слоем хранения напрямую, если не используются брокеры чтения.
Кластер Governor
Governor — ведущий узел кластера MemQ, он отвечает за автоматическую ребалансировку и назначение TopicProcessor, взаимодействуя с брокерами с помощью Zookeeper, который также используется при выборе Governor. Стать Governor может любой брокер.
Governer принимает решения о назначении TopicProcessor при помощи подключаемого алгоритма. По умолчанию для принятия решений о распределении этот алгоритм оценивает доступную ёмкость брокера. Эту возможность Governor использует для обработки отказов брокера и восстановления ёмкости для топиков.
Topic и TopicProcessor
Подобно другим системам PubSub, MemQ использует логическое понятие «топик». Топики MemQ на брокере обрабатываются модулем под названием TopicProcessor. Брокер может содержать один или несколько TopicProcessor, где каждый экземпляр TopicProcessor обрабатывает один топик.
Топики имеют разделы для записи и чтения. Разделы записи используются для создания нескольких TopicProcessor в соотношении 1:1, а разделы чтения — чтобы определить уровень параллелизма, необходимого потребителю для обработки данных. Количество разделов для чтения равно количеству разделов очереди уведомлений.
Хранилище
Хранилище MemQ состоит из двух частей:
Реплицированного хранилища (Object Store / DFS).
Очереди уведомлений (Kafka, Pulsar, и т.д.).
1. Реплицированное хранилище
MemQ позволяет использовать подключаемые обработчики хранения данных. На момент публикации статьи реализован обработчик хранения для Amazon S3. Amazon S3 предлагает экономически эффективное решение для отказоустойчивого хранения данных по требованию.
Для создания высокопроизводительного и масштабируемого слоя хранения MemQ на S3 используется следующий формат префикса:
s3://<bucketname>/<(a) 2 байтовой хеш идентификатора первого клиентского запроса в пакете>/<(b) cluster>/topics/<topicname>
(a) используется для создания разделов внутри S3, чтобы обрабатывать запросы с большей скоростью, если необходимо.
(b) — имя кластера MemQ.
Доступность и отказоустойчивость
S3 — хранилище объектов веб-масштаба с высокими гарантиями доступности, поэтому MemQ полагается на его доступность в первую очередь.
Чтобы приспособиться к будущему перераспределению разделов S3, MemQ добавляет двухзначный шестнадцатеричный хеш на первом уровне префикса, создавая 256 базовых префиксов. В теории префиксы могут обрабатываться независимыми разделами S3, просто чтобы сделать его устойчивым.
Согласованность
Согласованность базового слоя хранения определяет характеристики согласованности MemQ. В случае S3 каждая запись (PUT) в S3 Standard перед подтверждением гарантированно реплицируется как минимум в три зоны доступности (AZ).
2. Очередь сообщений
Система уведомлений используется MemQ для доставки указателей на местоположение данных потребителю. На момент публикации статьи используется внешняя очередь уведомлений в форме Kafka.
Как только данные записываются на слой хранения, обработчик хранения генерирует сообщение — уведомление, записывающее атрибуты записи, включая её местоположение, размер, топик и т. д.
Эта информация используется потребителем для получения данных (пакета) из слоя хранения. Чтобы проксировать пакеты для потребителей, можно включить брокеров MemQ но в ущерб эффективности. Очередь обеспечивает кластеризацию/балансировку нагрузки для потребителей.
Формат данных MemQ

Для сообщений и пакетов MemQ использует собственный формат хранения/передачи по сети. Единица передачи данных самого низкого уровня в MemQ называется LogMessage. Она похожа на Pulsar Message или Kafka ProducerRecord.
Обёртки для LogMessage позволяют использовать различные уровни пакетной обработки, которую делает MemQ. Вот эта иерархия:
Пакет — единица устойчивости.
Сообщение — единица загрузки производителя.
LogMessage — единица взаимодействия приложений с чем-либо.
Производство данных

За отправку данных брокерам отвечает производитель MemQ. Он использует модель асинхронной отправки, позволяющую выполнять неблокирующие отправки, не ожидая подтверждений.
Эта модель была очень важна, чтобы скрыть задержки загрузки слоёв хранения ниже, сохраняя при этом подтверждения на уровне хранилища. Это привело к созданию собственного протокола и клиента MemQ: мы не могли использовать существующие протоколы PubSub, которые полагались на синхронные подтверждения.
MemQ поддерживает три типа подтверждений:
ack=0 — производитель не сработал и забыл сообщение;
ack=1 — брокер получил сообщение;
ack=all — хранилище приняло сообщение;
При ack=all коэффициент репликации (RF) определяется базовым слоем хранения. Например, в S3 Standard RF=3 [по трём зонам доступности].
В случае неудачного ack производитель MemQ могут явно или неявно инициировать повторные попытки.
Хранение данных
TopicProcessor MemQ представляет собой концептуальный RingBuffer. Это виртуальное кольцо разделено на пакеты, что упрощает запись. Сообщения заносятся в текущий доступный пакет по мере их поступления через сеть до тех пор, пока пакет не заполнится или не сработает временной триггер. Как только пакет финализирован, он передаётся в StorageHandler для загрузки на слой хранения (например, S3).
Если загрузка прошла успешно, с помощью AckHandler уведомление отправляется через очередь уведомлений вместе с подтверждениями (ack) для отдельных сообщений в пакете к соответствующим этим производителям сообщениям, если производители запросили подтверждения.
Потребление данных
Потребитель MemQ позволяет приложениям читать данные из MemQ. Для обнаружения указателей на очередь уведомлений он использует API метаданных брокера. На основе опроса приложению предоставляется интерфейс.
В этом интерфейсе каждый запрос из опроса возвращает итератор LogMessages, позволяющий читать все LogMessages пакета. Пакеты обнаруживаются с помощью очереди уведомлений и извлекаются напрямую из слоя хранения.
Другие особенности
Обнаружение потери данных: перенос рабочих нагрузок с Kafka на MemQ требовал строгой проверки на предмет потери данных, поэтому MemQ имеет встроенную систему аудита, позволяющую эффективно отслеживать доставку каждого сообщения E2E и публиковать метрики почти в режиме реального времени.
Унификация пакетной и потоковой обработки: MemQ использует внешнюю систему хранения, что даёт возможность поддерживать запуск прямой пакетной обработки необработанных данных MemQ без преобразования в другие форматы.
Это позволяет пользователям выполнять на MemQ специальные проверки без серьёзных проблем с производительностью поиска, пока слой хранения может независимо масштабировать чтение и запись.
В зависимости от механизма хранения потребители MemQ могут выполнять одновременную выборку, что в определённых случаев стриминга позволяет значительно ускорить перезаполнение.
Производительность
Задержка загрузки
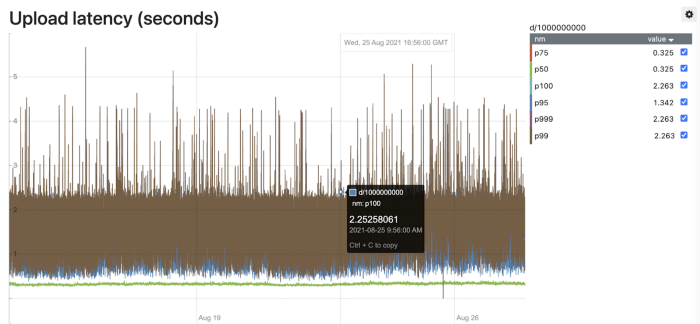
MemQ поддерживает передачу данных на слой хранения как по размеру, так и по времени, что в дополнение к нескольким оптимизациям для уменьшения джиттера позволяет жёстко ограничить максимальный хвост задержки.
На данный момент при использовании AWS S3 Storage удалось достичь задержки p99 E2E в 30 секунд, и мы активно работаем над сокращением задержек MemQ, что увеличивает количество переносимых с Kafka на MemQ сценариев использования.
Стоимость
MemQ на S3 Standard оказался в 10 (в среднем ~5 раз дешевле), чем эквивалентное развёртывание Kafka с тремя репликами на трёх зонах доступности с использованием экземпляров i3. Такая экономия обусловлена несколькими факторами, такими как:
снижение IOPS;
устранение ограничений на упорядочивание;
разделение вычислений и хранения данных;
снижение стоимости репликации за счёт отказа от вычислительного оборудования;
ослабление ограничений на задержку.
Масштабируемость
MemQ с S3 масштабируется налету в зависимости от требований к пропускной способности при записи и чтении. Чтобы обеспечить достаточную ёмкость записи до тех пор, пока вычисления могут быть предоставлены, Governor MemQ выполняет ребалансировку в режиме реального времени.
Брокеры масштабируются линейно — добавлением брокеров и обновлением требований к пропускной способности трафика. Если потребителю требуется дополнительный параллелизм для обработки данных, разделы для чтения обновляются вручную.

В Pinterest мы запускаем MemQ непосредственно на EC2 и масштабируем кластеры в зависимости от трафика и новых требований к использованию ресурсов.
Дальнейшая работа
Мы активно работаем в следующих областях:
сокращение задержек E2E (<5 с) для MemQ, чтобы использовать MemQ в новых ситуациях;
обеспечение встроенной интеграции с потоковыми и пакетными системами;
упорядочение ключей при чтении.
Заключение
MemQ предоставляет гибкий и недорогой нативный облачный подход к PubSub, обеспечивает сбор и транспортировку всех тренировочных данных ML в Pinterest. Мы активно распространяем технологию на другие наборы данных и оптимизируем издержки.
В дополнение к решению проблемы PubSub хранилище MemQ позволяет использовать данные PubSub для пакетной обработки без значительного влияния на производительность с низкой задержкой пакетной обработки.
Следите за постами о том, как мы оптимизировали внутренние компоненты MemQ, чтобы решить проблемы масштабируемости, а также о релизе MemQ в Open Source.
А мы поможем вам освоить надёжную профессию IT или развить ваши навыки:
Выбрать другую востребованную профессию.

Краткий каталог курсов и профессий
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также
ivankudryavtsev
Первая фраза и сразу косяк: MemQ — это дополнение к Kafka
Получите новый говноперевод от SkillFactory.