
Как обнаружить утечку?
Все просто, посмотреть на график изменения потребления памяти вашим сервисом в системе мониторинга.

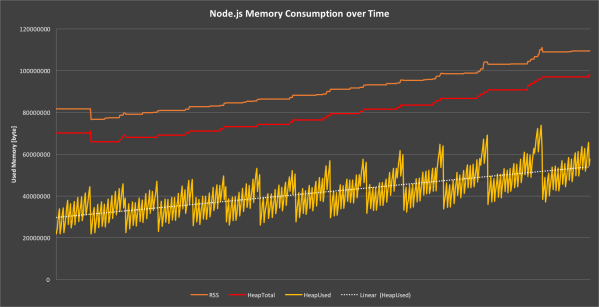

На всех этих картинках видно, что график потребления памяти только растет со временем, но никогда не убывает. Интервал может быть любым, посмотрите график за день, неделю или месяц.
Как настроить мониторинг?
Тестировать наш сервис мы будем локально без помощи DevOps-инженеров. Для работы нам понадобится git, Docker и терминал, а разворачивать мы будем связку Grafana и Prometheus.
Grafana это интерфейс для построения красивых графиков, диаграмм и dashboard-ов из них. Prometheus это система, которая включает в себя базу данных временных рядов и специального агента, который занимается сбором метрик с ваших сервисов.
Для того что бы быстро развернуть это всё на локальной машине воспользуемся готовым решением https://github.com/vegasbrianc/prometheus:
$ git clone git@github.com:vegasbrianc/prometheus.git
$ cd prometheus
$ HOSTNAME=$(hostname) docker stack deploy -c docker-stack.yml promПосле запуска по ссылке http://<Host IP Address>:3000 у нас должна открыться Grafana. Читайте README в репозитории, там всё подробно расписано.
Prometheus client
Теперь нам нужно научить наш сервис отдавать метрики, для этого нам понадобится Prometheus client.
Код примера из официального репозитория
package main
import (
"flag"
"log"
"net/http"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var addr = flag.String("listen-address", ":8080", "The address to listen on for HTTP requests.")
func main() {
flag.Parse()
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(*addr, nil))
}Самые важные строчки это 8 и 15 в 90% случаев их будет достаточно.
"github.com/prometheus/client_golang/prometheus/promhttp"
...
http.Handle("/metrics", promhttp.Handler())
...После запуска проверьте, что на endpoint-е /metrics появились данные.
Добавляем job в Prometheus agent
В папке репозитория prometheus найдите файлик prometheus.yml, там есть секция scrape_configs, добавьте туда свою job-у
scrape_configs:
- job_name: 'my-service'
scrape_interval: 5s
static_configs:
- targets: ['192.168.1.4:8080']194.168.1.4 это IP адрес вашей локальной машины. Узнать его можно командой ipconfig, ifconfig обычно интерфейс называется en0
$ ifconfig
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
options=6463<RXCSUM,TXCSUM,TSO4,TSO6,CHANNEL_IO,PARTIAL_CSUM,ZEROINVERT_CSUM>
ether f4:d4:88:7a:99:ce
inet6 fe80::1413:b61f:c073:6a8e%en0 prefixlen 64 secured scopeid 0xe
inet 192.168.1.4 netmask 0xffffff00 broadcast 192.168.1.255
nd6 options=201<PERFORMNUD,DAD>
media: autoselect
status: activeТак же не забудьте поменять в своём сервисе IP адрес запуска, сейчас там прописано ":8080" что по факту означает IP адрес текущей машины 127.0.0.1, для верности напишите "192.168.1.4:8080"
var addr = flag.String("listen-address", "192.168.1.4:8080", "The address to listen on for HTTP requests.")
Зачем прописывать IP?
Дело в том что docker stack в данной конфигурации запускает Grafana и Prometheus в своем изолированном network-е, они не видят ваш localhost, он у них свой. Конечно можно запустить ваш сервис в контексте сети docker-а, но прописать прямой IP локального интерфейса это самый простой путь подружить контейнеры запущенные внутри сети докера с вашими сервисами запущенными локально.
Применяем настройки
В папке с репозиторием выполняем команды
$ docker stack rm prom
$ HOSTNAME=$(hostname) docker stack deploy -c docker-stack.yml promУбедиться, что все заработало после перезапуска, можно посмотрев на панель targets prometheus-а по адресу http://localhost:9090/
Настраиваем Grafana
Тут всё просто, надо поискать красивый dashboard для Go на официальном сайте и импортировать его себе.
Лично мне понравился этот: ссылка на dashboard.
Нагрузочное тестирование
Что бы выявить утечку сервис нужно нагрузить реальной работой. В веб разработке основные транспортные протоколы между беком и фронтом это HTTP и Web Socket. Для них существует масса утилит нагрузочного тестирования, например
$ ab -n 10000 -kc 100 http://192.168.1.4:8080/endpoint
$ wrk -c 100 -d 10 -t 2 http://192.168.1.4:8080/endpointили тот же Jmeter, но мы будем использовать artillery.io так как у нас web socket-ы и мне было необходимо воспроизвести определенный сценарий, что бы словить memory leak.
Для artillery понадобится node и npm, а так как я когда-то я программировал на node.js мне нравится проект volta.sh, это что-то вроде виртуального окружения в python, позволяет для каждого проекта иметь свою версию node.js и его утилит, но выбор за вами.
Ставим артиллерию:
$ npm install -g artillery@latest
$ artillery -vПишем сценарий нагрузочного тестирования test.yml:
config:
target: "ws://192.168.1.4:8080/v1/ws"
phases:
# - duration: 60
# arrivalRate: 5
# - duration: 120
# arrivalRate: 5
# rampTo: 50
- duration: 600
arrivalRate: 50
scenarios:
- engine: "ws"
name: "Get current state"
flow:
- think: 0.5Последняя фаза добавляет 50 виртуальных пользователей каждую секунду в течение десяти минут. Каждый из которых сидит и думает 0.5 секунд, а можно сделать какие-нибудь запросы по сокетам или даже несколько.
Запускаем и смотрим графики в Grafana:
artillery run test.yml
На что стоит обратить внимание
Кроме памяти стоит посмотреть, как ведут себя ваши goroutine. Часто проблемы бывают из-за того что рутина остается "висеть" и вся память выделенная ей и все переменные указатели на которые попали в нее остаются "висеть" мертвым грузом в памяти и не удаляются garbage collector-ом. Вы так же увидите это на графике. Банальный пример обработчик запроса в котором запускается рутина для "тяжелых" вычислений:
func (s *Service) Debug(w http.ResponseWriter, r *http.Request) {
go func() { ... }()
w.WriteHeader(http.StatusOK)
...
}Эту проблему можно решить например через context, waitGroup, errGroup:
func (s *Service) Debug(w http.ResponseWriter, r *http.Request) {
ctx, cancel := context.WithCancel(r.Context())
go func() {
for {
select {
case <-ctx.Done():
return
default:
}
...
}
}()
w.WriteHeader(http.StatusOK)
...
}Либо при регистрации клиента вы выделяете под него память, например данные его сессии, но не освобождаете её, когда клиент отключился от вас аварийно. Что-то типа
type clientID string
type session struct {
role string
refreshToken string
...
}
var clients map[clientID]*clientSessionСледите за тем как вы передаете аргументы в функцию, по указателю или по значению. Используете ли вы глобальные переменные внутри пакетов? Не зависают ли в каналах и рутинах указатели на структуры данных? Graceful shutdown это про вас?
Дать конкретные советы невозможно, каждый проект индивидуален, но знать как самостоятельно настроить мониторинг и отследить утечку, это большой шаг на пути к стабильности 99.9%.
cerebrum666
Название статьи не соответствует содержимому. "Гайд по поиску и устранению утечек памяти в Go сервисах" - где поиск локализации утечек? Где гайд по устранению утечек? В статье только визуализация утечек в разрезе времени, и ничего больше (для этого и консольного наблюдения достаточно).
Gariks Автор
Привет минуса :) Как я написал в последнем абзаце "дать конкретные советы невозможно, каждый проект индивидуален", описать все возможные кейсы не реально. Например Мартин Фаулер издал 8 книг с 1996 года в каждой из которых по 400-500 страниц примеров кода и продолжает вести свой блог по рефакторингу и архитектуре. На сайте govnokod.ru сейчас 28 000 записей :)
"консольного наблюдения достаточно" - если мы говорим про команду top, её большой минус это отсутсвие визуализации изменения значения во времени. Можно пропустить тот момент когда было 10 мегабайт потом стало резко 300, потом 20, но 20 ведь тоже не нормально должно же быть 10. Или как понять что происходило с памятью в течении 2х месяцев эксплуатации сервиса в продакшене, кушает ли он память?
Я могу лишь дать базовые советы по отладке. Пишите debug логи в начале и конце функции, например через defer, так вы сможете отследить ее завершение и понять по логам сервиса при каких обстоятельствах он упал или память начала расти. Не стесняйтесь в лог выводить переменные, например идентификатор клиента, который подключился, параметры "флаги" запуска сервиса. Обычно в логах присутствует timestamp, посмотрев на графике, когда начался рост и почитав логи в ELK за этот период, можно будет понять, что примерно происходило в программе и попытаться воспроизвести этот сценарий. Внимательно проверяйте все ли вы открытое закрываете, особенно это хорошо проявляется при отладке graceful shutdown. Например известный кейс с "close response body". Если интерфейс предоставляет метод close или подобный возьмите за правило после его инициализации писать defer *.close()
Продолжать можно бесконечно долго :)
myaut12
Это очень плохие советы по отладке, хотя бы потому что для высоконагруженного приложения это сильная потеря производительности, а утечка, такая зараза, такая любит воспроизводиться только в продакшене, потому что там есть какой-то уникальный фактор а вы не знаете какой, рейт создания объектов определённого типа например.
В го прекрасный тулинг: профилировщик выделений памяти прямо из коробки например, который правда ещё придётся научиться читать, а ковырятель coredump'ов (описанный в https://wiki.crdb.io/wiki/spaces/CRDB/pages/1931018299/Using+viewcore+to+analyze+core+dumps) которым в связке с gdb можно найти "утекшие" или по крайней мере слишком популярные объекты.
Как нетрудно догадаться, я через viewcore дебажил отнюдь не CockroachDB, так что это вполне себе универсальный совет.