
Привет, меня зовут Сергей Алямкин, я CTO компании Expasoft. В сфере моих профессиональных интересов: ML/DL, нейросети, квантизация, компьютерное зрение (полный список). В своей первой статье на Хабре хочу поделиться нашим пилотным проектом – как мы разрабатывали модель предиктивного обслуживания нефтедобывающих насосов для компаний из Северной Америки и России.

82% нефти в РФ качают установки электроприводного центробежного насоса (УЭЦН), их поломки – серьезная проблема
На Хабре уже есть хорошая статья про добычу нефти и устройство различных насосов, в том числе и УЭЦН. Автор приводит статистику: «На УЭЦН приходится 63% скважин, при этом 82% нефти в стране добывается именно с помощью УЭЦН, что говорит о большей эффективности именно этого способа».
УЭЦН – сложная система из наземных и подземных узлов.

При всей сложности одно из преимуществ УЭЦН – длительный межремонтный период, от 500 суток до 2-3 лет и более. Даже если у компании в эксплуатации сотни насосов, их поломки – очень редкие события, буквально единицы в год.
К примеру, в рамках описываемого пилотного проекта мы получили от заказчика выгрузку из журнала событий со всеми остановками насосов за два года. В списке было 283055 записей, при этом реальных аварийных прецедентов было всего 384 (меньше 0,2% от общего числа остановок).
Однако каждая аварийная остановка – критически важное событие для нефтедобывающей компании. Насосы часто находятся в труднодоступных местах, и для ремонта нужно организовать выезд инженера на объект, при необходимости вынимать погружные узлы на поверхность, тратить время на заказ и доставку запчастей. В некоторых случаях нужно организовать транспортировку и замену насоса целиком.
Устранение поломки УЭЦН – долгий и сложный процесс, требующий колоссальных ресурсов. И самое главное, на время ремонта скважина простаивает, а это прямые потери денег. Если требуется полная замена насоса, прибавляем еще и стоимость новой установки, это тоже крупные издержки.
Нефтедобывающим компаниями необходимо снижать издержки, связанные с ремонтом насосов. А для этого нужно предвидеть аварийные ситуации. Чтобы следить за состоянием УЭЦН, на них устанавливают датчики: тока, температуры, давления и так далее. В сумме около 50 разных датчиков. Все они снимают показатели в режиме реального времени и генерируют огромные массивы данных. По ним эксперты, топовые инженеры с подтвержденными компетенциями и квалификацией, оценивают состояние каждого насоса и в случае необходимости запускают сервисный цикл.
Сервисные инженеры – ограниченный ресурс, ML позволяет использовать его эффективнее
Вполне реалистичная ситуация: по данным с датчиков эксперт оценил вероятность поломки насоса в 90%, вовремя подал рапорт, запустил дополнительную проверку. В итоге скорректировали параметры УЭЦН (частоту вращения, давление и т.д.) и избежали дорогостоящего ремонта – оборудование продолжает работать, нефтедобыча не прервалась, компания избежала многомиллионных издержек.
Таким образом каждый инженер сможет следить за парой-тройкой десятков насосов. А у компании тысячи насосов – соответственно, нужен большой штат высококвалифицированных специалистов.
Кроме того, иногда по одним данным два эксперта делают противоречивые выводы. Например, один утверждает, что данные отражают переходный процесс, а второй требует полной замены насоса уже через три дня. В таких неоднозначных ситуациях непредвзятое мнение машины может стать ключевым.
Простое правило
Если эксперт может объяснить на словах, как он сделал конкретный вывод по конкретным данным, значит, в этих данных действительно есть ценная информация и их можно давать на вход математической модели.
В отличие от человека, алгоритм может следить не за 20-30 насосами, а за всем оборудованием компании, предсказывая вероятность остановки каждого насоса от 0 до 100%. Внедрение такой предиктивной модели может повысить производительность каждого инженера на порядок, чтобы один специалист отвечал не за двадцать насосов, а за двести.
Еще раз, одним списком – в чем потенциальная польза ML в рамках данного кейса:
автоматизированный анализ данных с датчиков;
предсказание поломок – инженер сможет заранее остановить или перенастроить насос;
помощь в принятии любого решения по обслуживанию УЭЦН: от заказа деталей для ремонта до составления графика выездов на место добычи.
Критерий успешности пилотного проекта – достижение любого базового уровня точности, при котором модель реально помогает эксперту принять верное решение.
Витрина данных
Для моделирования нам предоставили три группы сырых данных:
Показания датчиков, установленных на насосах.
Данные по типам насосов: наименование производителя, эксплуатационные параметры, версия ПО и т.д.
Выгрузка из журнала событий: когда и почему был остановлен конкретный насос.
Часто в компаниях из консервативных отраслей данные собираются как попало. Вдобавок, помним, что УЭЦН это удалённые объекты, часто в труднодоступных местах без стабильной связи. Замеры с датчиков иногда выгружаются буквально на флэшке. Потребовались усилия даже для того, чтобы просто собрать исходные данные в одном месте.
Естественно, в результате получается очень неоднородный датасет:
разные датчики делали замеры с разной частотой, от 5 до 15 минут;
на одних насосах замеры велись полгода, на других в течение двух лет;
на разных насосах установлен разный набор датчиков: на одном могло стоять 30 датчиков, на другом – 10, а на пересечении этих множеств вообще всего 5 датчиков;
для разных скважин данные были предоставлены в разных форматах: CSV, ARH, выгруженные данные из программного комплекса АДКУ и системы управления;
некоторые форматы имели критически важные недостатки — например, утерянное название площади месторождения или цеха. Из-за этого мы не могли понять, на каком насосе сделаны замеры;
описания насосов и записи из журнала событий тоже были неполные – во многих не хватало данных о скважинах. Из-за этого мы не могли соотнести их с данными от датчиков.
Нужно было причесать весь этот беспорядок: убрать весь шум (записи с недостающими данными) и оставить только полные записи, пригодные для машинного обучения. Суммарная таблица по всем сырым данным выглядела так (осознанно не вдаёмся в нюансы с форматами данных, для этой статьи это не так важно):
Формат данных с датчиков |
Количество скважин |
Количество скважин с описанием насоса |
Количество скважин с описание насоса и описанием остановок |
1 |
118 |
- |
- |
2 |
53 |
- |
- |
3 |
539 |
294 |
118 |
4 |
216 |
77 |
46 |
5 |
336 |
321 |
82 |
В идеале, нам для обучения алгоритма нужен был наиболее полный и однородный датасет: с одним форматом данных с датчиков, с описанием насосов, на которых стоят датчики, и с указанием неполадки, из-за которой были остановлены насосы. Таким требованиям удовлетворял набор данных со 118 скважин. Для решили проверить, достаточно ли его для построения хорошей предиктивной модели.
В уме держали опцию – расширить набор данных путем сведения данных из трех источников (3, 4 и 5 форматы) с общим количеством скважин 246. При этом надо понимать, что состав признаков результирующего набора данных уменьшится до размера пересечения составов признаков отдельных источников.
Итак, итоговый источник данных для построения модели выглядел так:
Данные датчиков с 118 скважин (всего 49 датчиков на каждом насосе). Данные усреднялись по интервалу в 1 час.
Данные о параметрах используемых насосов: напор, количество ступеней, мощность.
Данные об остановках и их причинах: недогрузка по току, низкое давление на приеме насоса, температура ПЭД, перегрузка по току, недогрузка, перегрузка, высокие фазные напряжения, низкое сопротивление изоляции, низкие фазные напряжения, разбаланс фазных токов.
Как и в любом ML проекте, возня с данными это 90% усилий. После того, как мы закончили с витриной, осталась вишенка на торте – построить модель.
Построение модели
В качестве признаков использовались усредненные по часовым интервалам показания 49 датчиков за 24 последовательных часа. Параметры насосов использовались в качестве дополнительных признаков. Вектор признаков данных имел длину 24 (часа) х 49 (датчиков) + 3 (признаки УЭЦН) = 1179.
Датасет набирался из всех возможных 24-часовых последовательностей для всех возможных скважин. Для каждого 24-часового примера датасета определялась бинарная метка целевой переменной: 0, если в следующий временной интервал (1 час) не было остановки, 1 – если остановка была.
В качестве ML модели решили использовать градиентный бустинг на решающих деревьях (библиотека xgboost). Почему выбрали именно его:
это быстрый и мощный инструмент для задач машинного обучения,
он может обучаться на разреженных данных с пропусками,
не требует дополнительной обработки входных данных.
Выбранные параметры обучения модели:
eta (скорость обучения) = 0.15,
max_depth (глубина деревьев) = 1,
num_round (количество деревьев) = 50.

Выбор метрики
В задаче присутствует исходный дисбаланс классов. На итоговом наборе данных поломка происходит лишь в 0,37% всех наблюдений, поэтому не все стандартные метрики классификации можно использовать для определения обобщающей способности и качества модели.
Поясню на примере. Большую часть времени УЭЦН работает нормально – соответственно, метрика достоверность (accuracy) высокая. То есть всегда можно смело говорить, что поломки не будет, и в 98% случаев это окажется правдой.
В техническом плане задача формулировалась так:
Минимизировать ошибки первого рода: не пропускать поломки. Иначе зачем вообще такой алгоритм нужен?
Минимизировать ошибки второго рода: не давать ложноположительных прогнозов. Иначе сервисные эксперты будут тратить время на ложные срабатывания, когда поломки на самом деле нет.
Это классическая задача бинарной классификации. И самые адекватные метрики для ее оценки, определяющие эффективность поиска объектов целевого класса:
Полнота (recall) – сколько поломок от общего числа мы сможем предсказать на сутки вперед;
Точность (precision) – доля объектов, которые классификатор определил как поломки и которые действительно являются поломками.
Результаты и выводы по итогам пилотного проекта
Ниже графики для нескольких скважин. По горизонтали – часы. По вертикали – вероятность остановки. Целевая переменная выглядела так:
0, пока насос работает;
1 в момент, когда он ломается и во все последующие.
Модель выдает значения в диапазоне от 0 до 1. Зеленые и красные полосы – аварийные остановки насосов из журнала событий (разными цветами обозначены остановки по разным причинам).
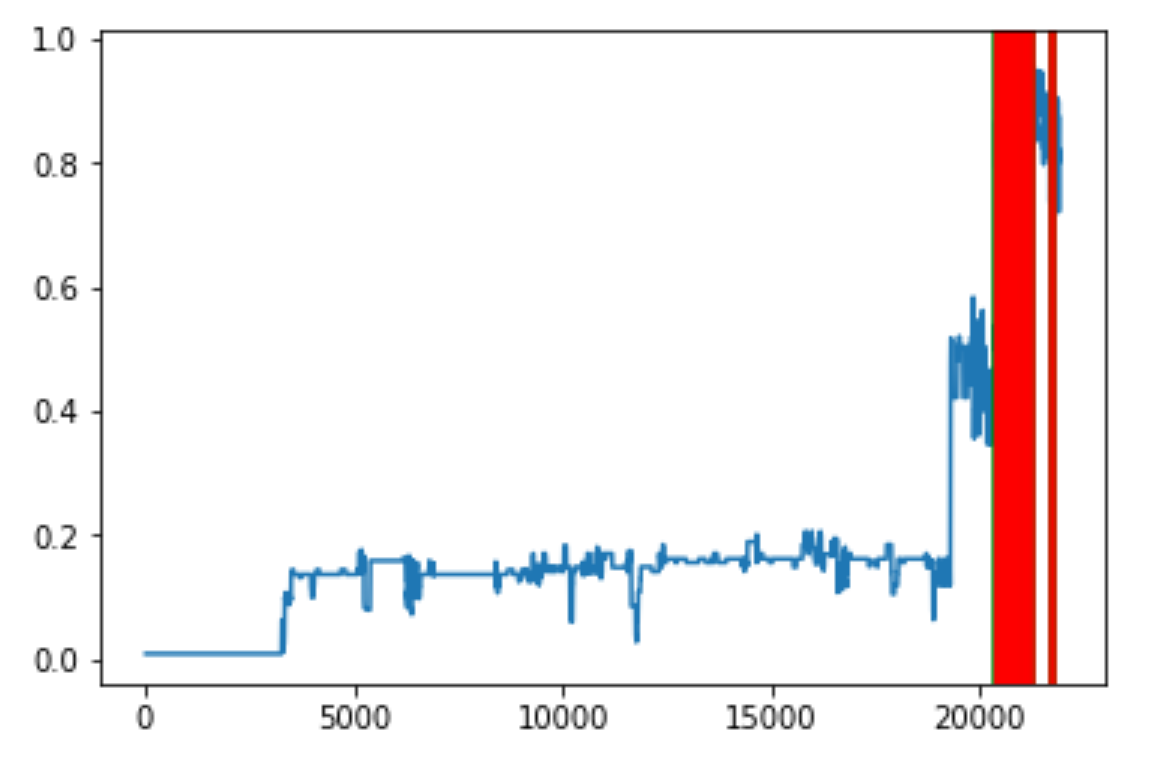



Как я уже говорил в начале, ремонтировать УЭЦН долго, поэтому после каждой аварийной остановки насос какое-то время простаивал в неисправном состоянии. В это время датчики продолжали снимать показания, соответственно, и модель предсказывает поломку, хотя на самом деле это последствия того же события. В целом, ложноположительных срабатываний было мало – precision 87%.
Для обученной модели проводили анализ важности признаков. На рисунке ниже топ-10 признаков по важности, полученных методом «gain» из библиотеки xgboost. Столбцы – это признаки, они состоят из названия (например, коэффициент мощности) и временного интервала (например, -16, то есть за 16 часов до поломки). Соответственно, чем выше столбец, тем больше вклад этого признака в точность получаемых предсказаний.

По итогам всего проекта в точке оптимальной отсечки пилотная модель давала следующие значение метрик:
Достоверность (Accuracy) |
98,0 |
Полнота (Recall) |
72,0 |
Точность (Precision) |
87,0 |
Что можно сказать по этим результатам? Модель действительно находит закономерности в данных, приводящие к аварийной остановке и потенциально может быть использована для уменьшения издержек эксплуатации УЭЦН. Точность 87% и полнота 72% – это значения, с которыми однозначно можно работать дальше.
На взгляд заказчика (да и на наш тоже) пилотный проект можно считать успешным – мы показали, что технологию можно внедрять и получать профит:
минимизацию убытков,
сокращение простоев скважин,
оптимизацию логистики,
сокращение штата специалистов.
Казалось бы, все получилось. Мы отдали пилот, закрыли договор …и тишина. Мы до сих пор достоверно не знаем, вырос ли проект во что-то большее или нет. Почему? Ответ касается цифровой трансформации в нефтедобывающей отрасли в целом.
Только 9% добывающих компаний масштабируют хотя бы половину своих цифровых решений
Это данные Accenture. При этом 36% компаний смогли тиражировать и того меньше – всего 1-10% IT-проектов.
Вообще, по темпам внедрения цифровых инициатив нефтегазовый сектор сильно уступает той же банковской сфере. Цена ошибки в нефтегазе высока, а выгоды от цифровой трансформации не до конца очевидны. Успешных пилотных IT-проектов много много, но распространить полученный опыт на все филиалы удается в единичных случаях. Наш пилот из той же серии.
Зато есть о чем рассказать на Хабре :)
Комментарии (6)

amarao
01.04.2022 15:47В таких неоднозначных ситуациях непредвзятое мнение машины может стать ключевым.
Правильно говорить, что "в таких ситуациях, обученная на человеческих ошибках, криво размеченных и нестерильных данных нейронка выдаст какой-то результат, и может быть, это будет не оверфитинг, и не ложное срабатывание, а всего лишь learning bias, который, может быть, даже и будет похож на правду".

Stas911
02.04.2022 04:18А они как-то планируют унифицировать датчики и упорядочить сбор данных? Раз уж все равно насосы меняют каждые пару лет.


evgenis
02.04.2022 10:40Ещё в 2005 году участвовал в разработке подобной системы. Называлась "Система поддержки принятия решений для моделирования процессов добычи нефти "Нефтепромысел"". Она позволяла следующее:
- Мониторинг и управление фондом скважин;
- Подбор оборудования и оптимизация режима;
- Диагностика геолого-технического состояния скважин;
- Расчёт индикаторной диаграммы;
- Анализ и оптимизация технологических, гидравлических, энергетических и технико-экономических показателей эксплуатации скважин;
- Визуализация и исследование истории параметров эксплуатации скважин;
- Расчёт потребности в оборудовании для цеха, предприятия;
- Расчёт эффективности намечаемых и проведённых мероприятий;
- Учёт движения оборудования.
Даже делали внедрение её в TNK-BP. Но по политическим причинам дело не пошло.
К сожалению, в сети уже не найти ссылки на её описание... :(

ChePeter
Слишком простой, прямолинейный подход.
Насос ломается обычно вследствие износа ( или по глупости эксплуатанта )
А на этот износ расходуется энергия и начало разрушения и весь предшествующий износ хорошо видно в спектре колебаний.