

В C++ есть несколько "умных указателей" - std::unique_ptr, std::shared_ptr, std::weak_ptr. Также есть более нестандартные умные указатели, например в boost1: intrusive_ptr, local_shared_ptr.
В этой статье мы рассмотрим новый вид умного указателя, который можно назвать static_ptr. Больше всего он похож на std::unique_ptr без динамической аллокации памяти.
std::unique_ptr<T>
std::unique_ptr<T>2 это обертка над простым указателем T*. Наверное, все программисты на C++ использовали этот класс.
Одна из самых популярных причин использования этого указателя - динамический полиморфизм.
Если мы на этапе компиляции не "знаем", объект какого именно класса будем создавать в некой точке выполнения, то из-за этого не знаем значение, на которое надо увеличивать указатель стека, а значит такой объект на стеке создавать нельзя - можем создать его только в куче.
Пусть у нас есть виртуальный класс IEngine и его наследники TSteamEngine, TRocketEngine, TEtherEngine. Объект "какого-то наследника IEngine, известного в run-time" это чаще всего именно std::unique_ptr<IEngine>, в таком случае память для объекта аллоцируется в куче.

Аллокация маленьких объектов
Аллокации в куче нужны для "больших объектов" (std::vector с кучей элементов, etc.), в то время как стек лучше подходит для "маленьких объектов".
В Linux для получения размера стека для процесса можно запустить:
ulimit -sпо умолчанию покажется невысокое число, на моих системах это 8192 KiB = 8 MiB. В то время как память из кучи можно хавать гигабайтами.
Аллокация большого количества маленьких объектов фрагментирует память и негативно отражается на кэше. Для устранения таких проблем может использоваться memory pool - есть крутая статья на эту тему3, рекомендую ее прочитать.
Объекты на стеке
Как можно сделать объект, аналогичный std::unique_ptr, но полностью стековый?
В C++ есть std::aligned_storage4, который дает сырую память на стеке, и в этой памяти при помощи конструкции placement new5 можно создать объект нужного класса T. Надо проконтролировать, чтобы памяти было не меньше чем sizeof(T).
Таким образом за счет микроскопического оверхеда (несколько незанятых байтов) на стеке можно создавать объекты произвольного класса.
sp::static_ptr<T>
Имея намерение сделать stack-only аналог std::unique_ptr<T>, я решил поискать уже готовые реализации, потому что идея, казалось бы, лежит на поверхности.
Придумав такие слова как stack_ptr, static_ptr и пр., и поискав их на GitHub, я нашел вменяемую реализацию в проекте ceph6, в ceph/static_ptr.h7 и увидел там некоторые полезные идеи. Впрочем, в проекте этот класс используется мало где, и в реализации есть ряд существенных промахов.
Реализация может выглядеть так - есть сам буфер для объекта (в виде std::aligned_storage); и какие-то данные, которые позволяют правильно рулить объектом: например, вызывать деструктор именно того типа, который сейчас содержится в static_ptr.
")
Реализация: насколько сложен move?
Здесь я опишу пошаговую реализацию и множество подводных камней, которые могут всплыть.
Сам класс static_ptr я решил поместить внутри namespace sp (от static pointer).
Реализации контейнеров, умных указателей, и прочих вещей - это вообще одни из самых сложных программ на C++, потому что приходится задумываться над вещами, про которые в нормальных проектах не подозревают.
Допустим, мы хотим вызвать move-конструктор из одного участка памяти в другой. Можно написать так:
template <typename T>
struct move_constructer {
static void call(T* lhs, T* rhs) {
new (lhs) T(std::move(*rhs));
}
};
// call `move_constructer<T>::call(dst, src);`Однако что делать, если класс T не имеет move-конструктора?
Есть шанс, что T имеет move-оператор присваивания, тогда надо использовать его. Если и его нет, то надо "сломать" компиляцию.
Чем новее стандарт C++, тем легче писать код для таких вещей. Получим такой код (скомпилируется в C++17):
template <typename T>
struct move_constructer {
static void call(T* lhs, T* rhs) {
if constexpr (std::is_move_constructible_v<T>) {
new (lhs) T(std::move(*rhs));
} else if constexpr (std::is_default_constructible_v<T> && std::is_move_assignable_v<T>) {
new (lhs) T();
*lhs = std::move(*rhs);
} else {
[]<bool flag = false>(){ static_assert(flag, "move constructor disabled"); }();
}
}
};(на 10 строке слом компиляции в виде static_assert происходит с хаком8)
Однако неплохо бы еще указывать noexcept-спецификатор, когда это возможно. В C++20 получаем такой код, настолько простой, насколько возможно в данный момент:
template <typename T>
struct move_constructer {
static void call(T* lhs, T* rhs)
noexcept (std::is_nothrow_move_constructible_v<T>)
requires (std::is_move_constructible_v<T>)
{
new (lhs) T(std::move(*rhs));
}
static void call(T* lhs, T* rhs)
noexcept (std::is_nothrow_default_constructible_v<T> && std::is_nothrow_move_assignable_v<T>)
requires (!std::is_move_constructible_v<T> && std::is_default_constructible_v<T> && std::is_move_assignable_v<T>)
{
new (lhs) T();
*lhs = std::move(*rhs);
}
};Аналогичным образом с разбором кейсов можно сделать структуру move_assigner. Можно было бы еще сделать copy_constructer и copy_assigner, но в нашей реализации они не нужны. В static_ptr будут удалены copy constructor и copy assignment operator (как и в unique_ptr).
Реализация: std::type_info на коленке
Хотя в static_ptr может лежать любой объект, нам все равно нужно как-то "знать" о том, что за тип там лежит. Например, чтобы мы могли вызывать деструктор именно этого объекта, и делать прочие вещи.
После нескольких попыток я выработал такой вариант - нужна структура ops:
struct ops {
using binary_func = void(*)(void* dst, void* src);
using unary_func = void(*)(void* dst);
binary_func move_construct_func;
binary_func move_assign_func;
unary_func destruct_func;
};И пара вспомогательных функций для перевода void* в T*...
template<typename T, typename Functor>
void call_typed_func(void* dst, void* src) {
Functor::call(static_cast<T*>(dst), static_cast<T*>(src));
}
template<typename T>
void destruct_func(void* dst) {
static_cast<T*>(dst)->~T();
}И теперь мы можем для каждого типа T иметь свой экземпляр ops:
template<typename T>
static constexpr ops ops_for{
.move_construct_func = &call_typed_func<T, move_constructer<T>>,
.move_assign_func = &call_typed_func<T, move_assigner<T>>,
.destruct_func = &destruct_func<T>,
};
using ops_ptr = const ops*;static_ptr будет хранить внутри себя ссылку на ops_for<T>, где T это класс объекта, который сейчас лежит в static_ptr.
Реализация: I like to move it, move it
Копировать static_ptr будет нельзя - можно только мувать в другой static_ptr. Выбор способа мува зависит от того, что за тип у объектов, которые лежат в этих двух static_ptr:
Оба
static_ptrпустые (dst_ops = src_ops = nullptr): ничего не делать.static_ptrсодержат один и тот же тип (dst_ops = src_ops): делаем move assign и разрушаем объект вsrc.static_ptrсодержат разные типы (dst_ops != src_ops): разрушаем объект вdst, делаем move construct, разрушаем объект вsrc, делаем присваиваниеdst_ops = src_ops.
Получится такой метод:
// moving objects using ops
static void move_construct(void* dst_buf, ops_ptr& dst_ops,
void* src_buf, ops_ptr& src_ops) {
if (!src_ops && !dst_ops) {
// both object are nullptr_t, do nothing
return;
} else if (src_ops == dst_ops) {
// objects have the same type, make move
(*src_ops->move_assign_func)(dst_buf, src_buf);
(*src_ops->destruct_func)(src_buf);
src_ops = nullptr;
} else {
// objects have different type
// delete the old object
if (dst_ops) {
(*dst_ops->destruct_func)(dst_buf);
dst_ops = nullptr;
}
// construct the new object
if (src_ops) {
(*src_ops->move_construct_func)(dst_buf, src_buf);
(*src_ops->destruct_func)(src_buf);
}
dst_ops = src_ops;
src_ops = nullptr;
}
}Реализация: размер буфера и выравнивание
Сейчас надо решить, какой будет дефолтный размер буфера и какое будет выравнивание9, потому что std::aligned_storage требует знать эти два значения.
Понятно, что выравнивание класса-наследника может превышать выравнивание класса-предка10. Поэтому выравнивание должно быть максимально возможным, которое только бывает. В этом нам поможет тип std::max_align_t11:
static constexpr std::size_t align = alignof(std::max_align_t);На моих системах это значение 16, но где-то могут быть нестандартные значения.
Кстати, память из кучи (из malloc) тоже выравнивается по максимально возможному alignment, автоматически.
Дефолтный размер буфера можно поставить в 16 байт или в sizeof(T) - что будет больше.
template<typename T>
struct static_ptr_traits {
static constexpr std::size_t buffer_size = std::max(static_cast<std::size_t>(16), sizeof(T));
};Понятно, что почти всегда это значение нужно будет переопределять на свою величину, чтобы помещались объекты всех классов-наследников. Желательно сделать это в виде макроса, чтобы было быстро писать. Можно сделать такой макрос для переопределения размера буфера в одном классе:
#define STATIC_PTR_BUFFER_SIZE(Tp, size) \
namespace sp { \
template<> struct static_ptr_traits<Tp> { \
static constexpr std::size_t buffer_size = size; \
}; \
}
// example:
STATIC_PTR_BUFFER_SIZE(IEngine, 1024)Однако этого недостаточно, чтобы выбранный размер "наследовался" всеми классами-наследниками нужного. Для этого можно сделать еще один макрос с использованием std::is_base:
#define STATIC_PTR_INHERITED_BUFFER_SIZE(Tp, size) \
namespace sp { \
template<typename T> requires std::is_base_of_v<Tp, T> \
struct static_ptr_traits<T> { \
static constexpr std::size_t buffer_size = size; \
}; \
}
// example:
STATIC_PTR_INHERITED_BUFFER_SIZE(IEngine, 1024)Реализация: sp::static_ptr<T>
Теперь можно привести реализацию самого класса. У него всего два поля - ссылка на ops и буфер для объекта:
template<typename Base>
requires(!std::is_void_v<Base>)
class static_ptr {
private:
static constexpr std::size_t buffer_size = static_ptr_traits<Base>::buffer_size;
static constexpr std::size_t align = alignof(std::max_align_t);
// Struct for calling object's operators
// equals to `nullptr` when `buf_` contains no object
// equals to `ops_for<T>` when `buf_` contains a `T` object
ops_ptr ops_;
// Storage for underlying `T` object
// this is mutable so that `operator*` and `get()` can
// be marked const
mutable std::aligned_storage_t<buffer_size, align> buf_;
// ...В первую очередь реализуем метод reset, который удаляет объект - этот метод часто используется:
// destruct the underlying object
void reset() noexcept(std::is_nothrow_destructible_v<Base>) {
if (ops_) {
(ops_->destruct_func)(&buf_);
ops_ = nullptr;
}
}Реализуем базовые конструкторы по аналогии с std::unique_ptr:
// operators, ctors, dtor
static_ptr() noexcept : ops_{nullptr} {}
static_ptr(std::nullptr_t) noexcept : ops_{nullptr} {}
static_ptr& operator=(std::nullptr_t) noexcept(std::is_nothrow_destructible_v<Base>) {
reset();
return *this;
}Теперь можно реализовать move constructor и move assignment operator. Чтобы принимался тот же тип, надо сделать так:
static_ptr(static_ptr&& rhs) : ops_{nullptr} {
move_construct(&buf_, ops_, &rhs.buf_, rhs.ops_);
}
static_ptr& operator=(static_ptr&& rhs) {
move_construct(&buf_, ops_, &rhs.buf_, rhs.ops_);
return *this;
}Однако лучше, если мы сможем принимать static_ptr для других типов. Другой тип должен влезать в буфер и быть наследником текущего типа:
template<typename Derived>
struct derived_class_check {
static constexpr bool ok = sizeof(Derived) <= buffer_size && std::is_base_of_v<Base, Derived>;
};И надо объявить "друзьями" все инстанциации класса:
// support static_ptr's conversions of different types
template <typename T> friend class static_ptr;Тогда два предыдущих метода можно переписать так:
template<typename Derived = Base>
static_ptr(static_ptr<Derived>&& rhs)
requires(derived_class_check<Derived>::ok)
: ops_{nullptr}
{
move_construct(&buf_, ops_, &rhs.buf_, rhs.ops_);
}
template<typename Derived = Base>
static_ptr& operator=(static_ptr<Derived>&& rhs)
requires(derived_class_check<Derived>::ok)
{
move_construct(&buf_, ops_, &rhs.buf_, rhs.ops_);
return *this;
}Копирование запрещено:
static_ptr(const static_ptr&) = delete;
static_ptr& operator=(const static_ptr&) = delete;Деструктор разрушает объект в буфере:
~static_ptr() {
reset();
}Для создания объекта в буфере сделаем метод emplace. Старый объект удалится (если он есть), в буфере создастся новый, и обновится указатель на ops.
// in-place (re)initialization
template<typename Derived = Base, typename ...Args>
Derived& emplace(Args&&... args)
noexcept(std::is_nothrow_constructible_v<Derived, Args...>)
requires(derived_class_check<Derived>::ok)
{
reset();
Derived* derived = new (&buf_) Derived(std::forward<Args>(args)...);
ops_ = &ops_for<Derived>;
return *derived;
}Методы-аксесоры сделаем такие же, как у std::unique_ptr:
// accessors
Base* get() noexcept {
return ops_ ? reinterpret_cast<Base*>(&buf_) : nullptr;
}
const Base* get() const noexcept {
return ops_ ? reinterpret_cast<const Base*>(&buf_) : nullptr;
}
Base& operator*() noexcept { return *get(); }
const Base& operator*() const noexcept { return *get(); }
Base* operator&() noexcept { return get(); }
const Base* operator&() const noexcept { return get(); }
Base* operator->() noexcept { return get(); }
const Base* operator->() const noexcept { return get(); }
operator bool() const noexcept { return ops_; }По аналогии с std::make_unique и std::make_shared, сделаем метод sp::make_static:
template<typename T, class ...Args>
static static_ptr<T> make_static(Args&&... args) {
static_ptr<T> ptr;
ptr.emplace(std::forward<Args>(args)...);
return ptr;
}Реализация доступна на GitHub12!
Как пользоваться sp::static_ptr<T>?
Это просто! Я сделал юнит-тесты, которые показывают лайфтайм объектов, живущих внутри static_ptr13.
В тесте можно посмотреть типичные сценарии работы со static_ptr и то, что происходит с объектами внутри них.
Бенчмарк
Для бенчмарков я использовал библиотеку google/benchmark14. Код для этого есть в репозитории15.
Я рассмотрел два сценария, в каждом из них проверяется std::unique_ptr и sp::static_ptr:
Создание умного указателя и вызов метода объекта.
Итерирование по вектору из 128 умных указателей, у каждого вызывается метод.
В первом сценарии выигрыш у sp::static_ptr должен быть за счет отсутствия аллокации, во втором сценарии за счет локальности памяти. Хотя, конечно, понятно, что компиляторы очень умные и умеют хорошо оптимизировать "плохие" сценарии в зависимости от флагов оптимизации.
Запустим бенчмарк в сборке Debug:
***WARNING*** Library was built as DEBUG. Timings may be affected.
-------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------------------------
BM_SingleSmartPointer<std::unique_ptr<IEngine>> 207 ns 207 ns 3244590
BM_SingleSmartPointer<sp::static_ptr<IEngine>> 39.1 ns 39.1 ns 17474886
BM_IteratingOverSmartPointer<std::unique_ptr<IEngine>> 3368 ns 3367 ns 204196
BM_IteratingOverSmartPointer<sp::static_ptr<IEngine>> 1716 ns 1716 ns 397344В сборке Release:
-------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------------------------
BM_SingleSmartPointer<std::unique_ptr<IEngine>> 14.5 ns 14.5 ns 47421573
BM_SingleSmartPointer<sp::static_ptr<IEngine>> 3.57 ns 3.57 ns 197401957
BM_IteratingOverSmartPointer<std::unique_ptr<IEngine>> 198 ns 198 ns 3573888
BM_IteratingOverSmartPointer<sp::static_ptr<IEngine>> 195 ns 195 ns 3627462Таким образом, есть определенный выигрыш в перфомансе у sp::static_ptr, который представляет собой stack-only аналог std::unique_ptr.
Ссылки
C++ Memory Pool and Small Object Allocator | by Debby Nirwan
godbolt.com - выравнивание класса-наследника больше, чем у класса-предка
Комментарии (64)

NN1
14.05.2022 23:02+1std::aligned_storage_t объявлен устаревшим
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2019/p1413r2.pdf

Izaron Автор
14.05.2022 23:21+1Устаревший он с C++23. Компилятор может скомпилировать с ворнингом что "это фича из более нового стандарта", но может и не скомпилировать. Это пока в тестовом формате.
Начиная с C++23 было бы так:
alignas(align) std::byte buf_[buffer_size];

Readme
14.05.2022 23:19+1Всё уже украдено до насВаше решение очень напоминает идиому "Fast Pimpl" (презентации Антона Полухина: https://apolukhin.github.io/presentations/Taxi%20C++%20Tricks.pdf), механика и мотивация создания такого умного указателя практически совпадают с изложенными вами. Там же можно найти интересные решения по точкам кастомизации (помимо специализацийstatic_ptr_traits, последний раздел "Parse"). Оставлю пару заметок:- Интересный подход с сохранением специальных функций. Правда, раздувает размер указателя, и производительность может немного просесть из-за дополнительного уровня обращения, но такова плата за "полиморфизм".
-
max_align_tне сможет помочь для over-aligned типов (например, "кэш-линия" ~ 64). Можно попробовать использоватьmax(alignof(T), alignof(max_align_t)). Также, можно хранить внутри доп. указатель-смещение, полученный черезstd::align, и всегда выделять буффер немного больше и с немного более строгим выравниванием, но это уже звучит ещё большим додумыванием семантики.
Izaron Автор
14.05.2022 23:40+3Действительно, идея "витает в воздухе", но здесь позволю себе не согласиться с вами ???? Какая мотивация у Антона:
Нужно реализовать идиому PImpl, чтобы быстрее компилировалось (убрался инклюд) и т.д.
"Стандартный подход" заключается в замене
Tнаstd::unique_ptr<T>, потому что там ок чтобыTбыл incomplete type (а у меня кстати не так, мне нуженTcomplete).Этот подход медленный из-за кучи, поэтому
Tзаменяют на обертку надstd::aligned_storage<sizeof(T), alignof(T)>, причем эти два числа надо посчитать руками.
И там совсем не про "динамический полиморфизм на стеке", тип жестко фиксирован. Из общего только использование aligned_storage...
Про вторую заметку: интересно, какие есть кейсы, где используются over-aligned типы? Я сам с таким еще не сталкивался.
Readme
17.05.2022 13:15Из общего только использование aligned_storage...
Заново изучил статью, преисполнился, соглашусь.
Про over-aligned типы такие идеи имеют место быть: помимо локальности и убирания косвенных обращений (что чаще всего хорошо из-за кэширований), иногда нам может быть полезно наоборот немного разнести данные в пространстве ("локальные, но чуть-чуть"), чтобы избежать false sharing. Например, это когда несколько потоков молотят один вектор, но каждый только свой элемент, но при этом постоянно инвалидируют ячейки соседей, просто потому что несколько ячеек попало в одну кэш-линию.

myxo
14.05.2022 23:24+2Я возможно глупый, но я ничего не понял. Что это, зачем это…
Как можно сделать объект, аналогичный std::unique_ptr, но полностью стековый?
А в чем отличие от простого создания переменной на стеке и передачи указателя на него.
DistortNeo
14.05.2022 23:50Я тоже поначалу не понял. Потом понял: это просто резервирование памяти в буфере и обёртка для placement new/delete. Может быть полезно при наследовании с виртуальными вызовами.
Izaron Автор
14.05.2022 23:50+2Пусть есть виртуальный абстрактный класс
IEngineи его наследникиTSteamEngine,TRocketEngine,TEtherEngine.Нужно завести контейнер из объектов, чей тип - какой-то наследник
IEngine. Как вы это сделаете?Стандартный подход:
std::vector<std::unique_ptr<IEngine>>.Этот подход значит, что в куче лежит память вектора для
NобъектовEngine*, каждый объект указывает еще куда-нибудь в кучу в рандомное место (и каждый раз при добавлении объекта происходит аллокация).Подход с
std::vector<sp::static_ptr<IEngine>>значит, что в куче лежит память вектора дляNобъектов размераstatic_ptr_traits<IEngine>::buffer_size, и больше ничего, это круче из-за локальности памяти.DistortNeo
15.05.2022 00:23+1Но это будет работать только в том случае, если:
Каждый из дочерних объектов умещается в
static_ptr_traits<IEngine>::buffer_size.
Хранимый объект допускает перемещение.
Izaron Автор
15.05.2022 00:35Хранимый объект допускает перемещение.
Кстати,
std::vector<T>как раз требует, чтобы объектTбыл перемещаемым или хотя бы копируемым. А то не скомпилируется кусок кода отвечающий за перемещение объектов при переаллокации.(Соответственно этого не требуется для
std::listи подобных контейнеров)
datacompboy
15.05.2022 14:15Так в данном случае T - - это uniq<Q>, который перемещаемости Q не требует

AnthonyMikh
15.05.2022 00:25+6Простите, но если у вас все наследники интерфейсов известны заранее (иначе вы бы просто не смогли корректно подсчитать необходимый размер буфера), то что мешает потерпеть небольшой оверхед по памяти и просто хранить
std::variantиз типов наследников? Это уж точно проще, чем делать собственный умный указатель.Izaron Автор
15.05.2022 00:58Как быстро получить указатель на базовый класс? У меня вышло так:
using TEngine = std::variant<TSteamEngine, TRocketEngine, TEtherEngine>; // ... IEngine* GetEngine(TEngine* engine) { if (auto ptr = std::get_if<TSteamEngine>(engine)) return ptr; if (auto ptr = std::get_if<TRocketEngine>(engine)) return ptr; if (auto ptr = std::get_if<TEtherEngine>(engine)) return ptr; return nullptr; }std::variantиз всех наследников выглядит как-то жутковато) Но идея похоже рабочаяP. S. Только бы еще оттуда удалить copy constructor и copy assignment operator...

0xd34df00d
15.05.2022 06:52+2Как быстро получить указатель на базовый класс?
IEngine& GetEngine(TEngine& engine) { return std::visit([](auto& e) -> IEngine& { return e; }, engine); }Пишу с мобильника, поэтому за компилируемость не ручаюсь.
Только бы еще оттуда удалить copy constructor и copy assignment operator...
Удалите у базового класса.

Antervis
15.05.2022 14:51+1к сожалению компиляторы не очень-то умеют в std::visit. Так будет виртуальный вызов с исключением при valueless_by_exception, а версия выше скомпилится в что-то вполне вменяемое.
0xd34df00d
15.05.2022 20:28+2Зависит от компилятора. Например, gcc 12.1 компилирует
struct B {}; template<int N> struct D : B { char data[N + 1]; }; using ADT = std::variant<D<0>, D<1>, D<2>>; B& get1(ADT& adt) { return std::visit([](auto& d) -> B& { return d; }, adt); }в очень простую функцию:
get1(std::variant<D<0>, D<1>, D<2> >&): mov rax, rdi retclang вот что-то какую-то хрень делает, да.
0xd34df00d
15.05.2022 20:41+3Хотя это ж C++17, можно обмазаться fold expressions:
template<typename Base, typename... Args> Base& getT(std::variant<Args...>& adt) { Base *ptr = nullptr; ((ptr = ptr ? ptr : std::get_if<Args>(&adt)), ...); return *ptr; } B& get2(ADT& adt) { return getT<B>(adt); }тогда и gcc, и clang выдают достаточно оптимальный код, пусть и с лишними проверками:
get2(std::variant<D<0>, D<1>, D<2> >&): xor eax, eax cmp BYTE PTR [rdi+3], 2 cmovbe rax, rdi retИнтересно, что если попытаться избежать проверки чем-нибудь вроде такого
template<typename Base, typename... Args> Base& getT(std::variant<Args...>& adt) { const auto thePtr = (reinterpret_cast<std::uintptr_t>(std::get_if<Args>(&adt)) | ...); return *(reinterpret_cast<B*>(thePtr)); }то компилятор перестаёт понимать, что от него хотят, и генерирует что-то более сложное.
Antervis
15.05.2022 21:36Там сильно зависит от версии компилятора и от того, является ли базовый класс виртуальным. Хотя признаться я изначально смотрел на более старых компиляторах.
Хотя это ж C++17, можно обмазаться fold expressions:
да, так тоже можно, правда там UB - нельзя брать ссылку от nullptr.
то компилятор перестаёт понимать, что от него хотят, и генерирует что-то более сложное.
ну тут не только компилятор перестанет понимать чего от него хотят...
0xd34df00d
15.05.2022 21:53и от того, является ли базовый класс виртуальным
Интересно, а почему?
да, так тоже можно, правда там UB — нельзя брать ссылку от nullptr.
Я предполагаю, что в
adtчто-то есть. Гарантировать отсутствие valueless by exception предлагается читателю в качестве упражнения.ну тут не только компилятор перестанет понимать чего от него хотят...
Ну тут всё просто: конвертируем каждый указатель в
uintptr_t.nullptrЕМНИП конвертируется в нулевойuintptr_t, и так как только один указатель будет ненулевым, то побитовое или всехuintptr_t'ов будет равно как раз тому указателю, который не ноль, и мы это обратно преобразуем.Antervis
15.05.2022 23:01Интересно, а почему?
полагаю потому, что как только дело доходит до исключений, компиляторы сходят с ума и теряют возможность оптимизировать даже тривиальные сценарии.
Я предполагаю, что в
adtчто-то есть. Гарантировать отсутствие valueless by exception предлагается читателю в качестве упражнения.лучше добавить проверку, учитывая что это может помочь компилятору
Ну тут всё просто:
я понял как это работает благодаря пониманию что этот метод должен делать. Без этого понимания пришлось бы почесать лоб и помянуть добрым словом автора.
0xd34df00d
16.05.2022 00:22+1полагаю потому, что как только дело доходит до исключений, компиляторы сходят с ума и теряют возможность оптимизировать даже тривиальные сценарии.
«Плюсы — это гарантированная производительность», говорили они. А по факту надо полагаться на достаточно умный компилятор, как и в более других языках.
лучше добавить проверку, учитывая что это может помочь компилятору
И её теперь надо протаскивать везде — вызывающий метод тоже должен быть готов к тому, что вернётся
nullptr. А я хочу ссылочку, потому чтоnullptrпо логике быть не может никогда.я понял как это работает благодаря пониманию что этот метод должен делать. Без этого понимания пришлось бы почесать лоб и помянуть добрым словом автора.
ХЗ, более-менее стандартный код для этого нашего байтоложеского лоу-летенси.
Antervis
16.05.2022 01:14«Плюсы — это гарантированная производительность», говорили они
кто "они" то? Производительность не бывает "гарантированной", однако возможность написать производительный код на плюсах всегда остается. В большинстве других ЯП вопрос экономии на аллокациях даже не ставится...
А я хочу ссылочку, потому что
nullptrпо логике быть не может никогда.ну раз nullptr никогда не будет, то и UB в случае которого никогда не будет не проблема, верно?
ХЗ, более-менее стандартный код для этого нашего байтоложеского лоу-летенси.
брр
0xd34df00d
16.05.2022 01:23+1Производительность не бывает "гарантированной", однако возможность написать производительный код на плюсах всегда остается
Подглядывая в ассемблер.
В большинстве других ЯП вопрос экономии на аллокациях даже не ставится...
В некоторых других ЯП короткоживущий мусор на хипе стоит сильно дешевле плюсового хипа (bump/arena allocator, nursery, вот это всё).
ну раз nullptr никогда не будет, то и UB в случае которого никогда не будет не проблема, верно?
Абсолютно верно. Только что вы напишете внутри ифа, если таки хотите вернуть ссылку?
__builtin_unreachable();?брр
Да, я тоже рад, что уже третий год практически не прикасаюсь к плюсам.
Antervis
16.05.2022 11:16Подглядывая в ассемблер.
ну во-первых, жертвуя переносимостью. Во-вторых, в асме тоже можно начудить - компиляторы нынче учитывают больше нюансов и особенностей архитектуры при микрооптимизациях чем человек в состоянии знать. Не говоря о том, что как только доходит дело до макрооптимизаций, проще писать на тех же плюсах, чем переизобретать структуры данных.
В некоторых других ЯП короткоживущий мусор на хипе стоит сильно дешевле плюсового хипа (bump/arena allocator, nursery, вот это всё).
В плюсах у программиста есть свобода переопределять аллокатор глобально, а также в масштабах контейнеров и отдельных классов.
Абсолютно верно. Только что вы напишете внутри ифа, если таки хотите вернуть ссылку?
__builtin_unreachable();?ну да, сработает же
Да, я тоже рад, что уже третий год практически не прикасаюсь к плюсам.
это я так тонко намекнул что проблема может быть не в плюсах, а в этом "вашем байтоложенском лоулейтенси"
0xd34df00d
16.05.2022 19:00+2ну во-первых, жертвуя переносимостью.
Ну а как называется то, чем мы тут занимались? Написали один вариант, посмотрели, что gcc оптимизирует так, clang оптимизирует сяк. Написали другой вариант, посмотрели…
Во-вторых, в асме тоже можно начудить — компиляторы нынче учитывают больше нюансов и особенностей архитектуры при микрооптимизациях чем человек в состоянии знать.
Ну про подсчёт количества копий символа в строке я и так всех задолбал, поэтому давайте сделаем что-нибудь ещё проще. Например, посчитаем среднее арифметическое двух чисел! Как это сделать на ассемблере под amd64?
mov rax, a add rax, b rcr rax, 1Как это сделать на плюсах? Ну, например,
unsigned long avg1(unsigned long a, unsigned long b) { const auto min = std::min(a, b); const auto max = std::max(a, b); return min + (max - min) / 2; }Ассемблер?
avg1(unsigned long, unsigned long): cmp rsi, rdi jb .L2 mov rax, rsi mov rsi, rdi cmovb rax, rdi mov rdi, rax .L2: sub rdi, rsi shr rdi lea rax, [rdi+rsi] retМожет, повыпендриваемся?
unsigned long avg2(unsigned long a, unsigned long b) { return a / 2 + b / 2 + (a & b & 1); }Неа, всё равно ерунда:
avg2(unsigned long, unsigned long): mov rax, rdi mov rdx, rsi and rdi, rsi shr rax shr rdx and edi, 1 add rax, rdx add rax, rdi retну да, сработает же
Только это уже не стандартный C++ :]
это я так тонко намекнул что проблема может быть не в плюсах, а в этом "вашем байтоложенском лоулейтенси"
А зачем плюсы вне подобных задач?
Antervis
16.05.2022 20:21Ну а как называется то, чем мы тут занимались? Написали один вариант, посмотрели, что gcc оптимизирует так, clang оптимизирует сяк. Написали другой вариант, посмотрели…
тем не менее код будет работать под все поддерживаемые платформы, даже если не везде оптимально. В этом и заключается свойство переносимости. Опять же, оптимизации, сделанные на миддленде, будут применены под любую архитектуру.
Как это сделать на ассемблере под amd64?
Как это сделать на плюсах?
Ну вы сами того не заметив подкрепили все мои же аргументы. Во-первых, ваша asm версия с ошибкой - rcr это циклический сдвиг вправо, т.е. будет возвращать некорректный результат при нечетных a + b. Во-вторых, вы либо слукавили либо допустили вторую ошибку - реализация на asm в отличие от с++ версий еще и не обрабатывает переполнение. Две ошибки в трех командах, хах. В-третьих, как я и сказал, компиляторы микрооптимизируют лучше - складывают через lea.
Только это уже не стандартный C++ :]
честно говоря я забыл что unreachable еще не является стандартным аттрибутом. Опять же, он нужен для оптимизаций компилятора, а не для обеспечения корректности кода.
А зачем плюсы вне подобных задач?
везде где данных/rps по-настоящему много, реализация на с++ сэкономит больше на железе даже без микрооптимизаций.
0xd34df00d
16.05.2022 21:51+1тем не менее код будет работать под все поддерживаемые платформы, даже если не везде оптимально.
Если вам действительно нужно оптимально, то у вас либо сильно ограниченное число целевых платформ (как в этом нашем hft, где вы пишете под конкретный процессор), либо у вас несколько реализаций кода на ассемблере или интринсиках (как в ffmpeg), либо вы делаете что-то ещё наркоманистое (как atlas, во время компиляции перебирающий и бенчмаркающий кучу разных реализаций под конкретное железо).
Во-первых, ваша asm версия с ошибкой — rcr это циклический сдвиг вправо, т.е. будет возвращать некорректный результат при нечетных a + b.
Нет:
unsigned long avg(unsigned long a, unsigned long b) { unsigned long res; asm("mov %1, %0\n\t" "add %2, %0\n\t" "rcr $1, %0\n\t" : "=r" (res) : "r" (a), "r" (b)); return res; } int main() { return avg(3, 5); }возвращает 4.
avg(3, 6)возвращает тоже 4, как и версия на плюсах.Возможно, я тут накосячил с инлайн-ассемблером — всё ж очень давно не писал подобные вещи.
Во-вторых, вы либо слукавили либо допустили вторую ошибку — реализация на asm в отличие от с++ версий еще и не обрабатывает переполнение.
Обрабатывает как раз за счёт rcr — rcr учитывает carry flag, в отличие от ror.
Две ошибки в трех командах, хах.
Ноль ошибок в трёх командах (с точностью до порядка операторов, он в at&t syntax и intel syntax разный, но суть-то понятна).
В-третьих, как я и сказал, компиляторы микрооптимизируют лучше — складывают через lea.
Не лучше: получается всё равно ерунда, хоть с lea, хоть без lea. Версия с
rcrв три раза быстрее наивной версии с минимумом-максимумом, и в полтора — с выпендриванием сa & b & 1: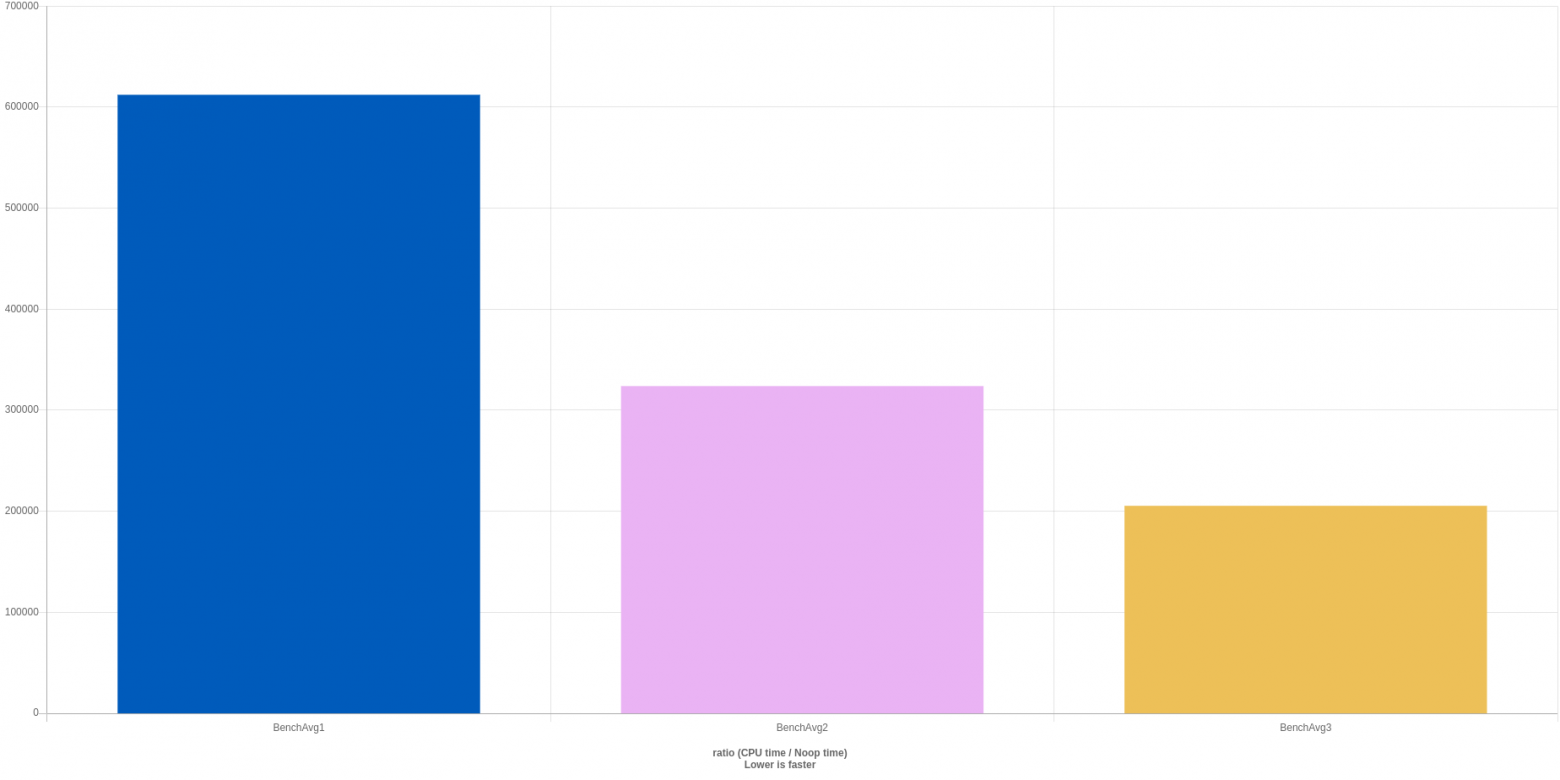
(via)
Не, если посмотреть таблички Агнера Фога, то там у некоторых процессоров
rcrдействительно стоит очень дорого, но даже на тех железках, гдеrcr r, 1стоит один-два такта, компилятор не осиливает её использовать.везде где данных/rps по-настоящему много, реализация на с++ сэкономит больше на железе даже без микрооптимизаций.
Утверждаю, что писать на хаскеле код, более-менее равный плюсам без микрооптимизаций, не сильно сложно, и с лихвой компенсируется простотой нечувствительных к производительности частей.
Antervis
16.05.2022 22:37Нет:
ok my bad. Такое чувство словно инструкция rcr была заведена под этот кейс...
Если вам действительно нужно оптимально
то подавляющее большинство ЯП отпали пару порядков оптимизаций назад. Из оставшихся, которые можно пересчитать по пальцам одной руки, с инлайн асмом/интринсиками справятся все.
Утверждаю, что писать на хаскеле код, более-менее равный плюсам без микрооптимизаций, не сильно сложно, и с лихвой компенсируется простотой нечувствительных к производительности частей.
хаскель как минимум функциональный язык. Остальное субъективно.
0xd34df00d
16.05.2022 22:59Из оставшихся, которые можно пересчитать по пальцам одной руки, с инлайн асмом/интринсиками справятся все.
Ура. Можно ссылаться на этот тред, когда в следующий раз вдруг в комментах зайдёт речь, что для производительности необходимо и достаточно брать плюсы.
хаскель как минимум функциональный язык
Ну, да. Но как это здесь мешает?
Antervis
17.05.2022 05:10Можно ссылаться на этот тред, когда в следующий раз вдруг в комментах зайдёт речь, что для производительности необходимо и достаточно брать плюсы.
не помню чтобы я утверждал ни про необходимость, ни про достаточность. По крайней мере безоговорочно.
Ну, да. Но как это здесь мешает?
может мешать, в зависимости от задачи/архитектуры/команды

KanuTaH
15.05.2022 23:43и мы это обратно преобразуем
Только в том случае, если там действительно есть хотя бы один не ноль. Преобразование из нуля в
nullptrили в null pointer любого типа черезreinterpret_castв общем случае делать нельзя.0xd34df00d
16.05.2022 00:23А он там обязан быть, если вариант не пустой. А функция предполагает, что он непустой.

ReadOnlySadUser
16.05.2022 17:18А как на счёт написать что-нибудь такое?
template <typename Base, typename ...T> struct MyVariant : public std::variant<T...> { using std::variant<T...>::variant; Base& getBase() { uintptr_t ptr = ((0 + ... + reinterpret_cast<uintptr_t>(std::get_if<T>(this)))); return *reinterpret_cast<Base*>(ptr); } };
naviUivan
16.05.2022 18:10А как это будет работать при множественном наследовании? Если тип T будет наследником чего-то еще кроме Base? Не говоря уже про виртуальное наследование. Мне кажется reinterpret_cast тут плохой идеей.
ReadOnlySadUser
16.05.2022 18:38А как множественное наследование будет работать в остальных вариантах?
Можно и без reinterpret_cast https://godbolt.org/z/rfWc173YE
naviUivan
16.05.2022 21:55В остальных вариантах будет корректный неявный каст к ссылке на базовый класс. Так же как и в вашем примере без reinterpret_cast. Ну или, как отметили ниже, через промежуточный каст к Base*
0xd34df00d
16.05.2022 19:02При множественном наследовании надо просто сделать два каста:
reinterpret_cast<uintptr_t>(static_cast<Base*>(std::get_if<T>(this)))


xxxphilinxxx
15.05.2022 00:17+5Одна из самых популярных причин использования этого указателя - динамический полиморфизм.
Если мы на этапе компиляции не "знаем", объект какого именно класса будем создавать в некой точке выполнения, то из-за этого не знаем значение, на которое надо увеличивать указатель стека, а значит такой объект на стеке создавать нельзя - можем создать его только в куче.Важными причинами использования умных указателей я бы назвал решение проблемы утечек памяти и управление совместным доступом к объекту. А в описанном случае с выделением памяти и семейством классов (slicing problem), сгодится и "глупый" си-шный указатель, разве нет? И, кстати, вовсе необязательно на кучу, сам концепт вашего указателя это подтверждает.
Сделать свой умный указатель/аллокатор/контейнер - интересная задачка, но получился аналог только одного из трех классических - unique_ptr, что, конечно, и решает проблему утечек, и стеком вместо кучи дает оперировать, но не позволяет даже просто переиспользовать объект без полной передачи или вложения в другой объект. Вы не рассматривали вариант написать/взять стековый аллокатор/делитер для использования с уже существующими указателями?

rafuck
15.05.2022 00:23А зачем стековый «делитер»?
xxxphilinxxx
15.05.2022 10:48*thinking* действительно, незачем. Без аллокатора недостаточно, с аллокатором не нужно - только если сам конкретный тип требует.
Izaron Автор
15.05.2022 00:31-1А в описанном случае с выделением памяти ..., сгодится и "глупый" си-шный указатель, разве нет?
А где будет находиться объект, куда указывает "глупый" указатель? В куче не может - цель уйти от кучи. На стеке может только в aligned_storage, а из этого вытекают разные вопросы, которые попытался решить в статье.
sp::static_ptrкстати решает еще одну специфическую проблему - теперь объект невозможно случайно скопировать (передать по значению, etc.)не позволяет даже просто переиспользовать объект без полной передачи или вложения в другой объект
К сожалению не понял, что имеется в виду под "нельзя переиспользовать объект". Указываемый объект возможно использовать также, как в других умных указателях:
sp::static_ptr<TObj> p; // ... в `p` лежит объект TObj obj{std::move(*p)};0xd34df00d
15.05.2022 06:55А где будет находиться объект, куда указывает "глупый" указатель?
Можно создать на стеке как обычно этот делают, и потом переписать программу в continuation passing style, но это очень на любителя [хардкорной функциональщины].
xxxphilinxxx
15.05.2022 10:34+1А где будет находиться объект, куда указывает "глупый" указатель? В куче не может - цель уйти от кучи. На стеке может только в aligned_storage, а из этого вытекают разные вопросы, которые попытался решить в статье.
В общем случае - что в куче, что на стеке, под отдельной переменной или в хранилище. Меня заявления смутили во вводной части с причиной использования именно unique_ptr (а не вообще любого указателя), слайсингом (который иногда может быть приемлем) и "только в куче":
Одна из самых популярных причин использования этого указателя - динамический полиморфизм.
Если мы на этапе компиляции не "знаем", объект какого именно класса будем создавать в некой точке выполнения, то из-за этого не знаем значение, на которое надо увеличивать указатель стека, а значит такой объект на стеке создавать нельзя - можем создать его только в куче.А хранилищем не обязательно должно быть aligned_storage, можно хоть самому написать: например, тупо взять на стеке char[N] и хранить там разнородные объекты, используя placement new, арифметику указателей, ну и дополнительный реестр.
К сожалению не понял, что имеется в виду под "нельзя переиспользовать объект"
Я имел в виду shared_ptr / weak_ptr - оба можно копировать и предоставлять множественный доступ к объекту. Объект будет жить, пока есть хотя бы одна копия shared указателя на него. А ваш указатель, если я правильно понял, как и unique_ptr, надо либо передавать через move, отбирая его у предыдущего владельца, либо вкладывать в другой объект (поле класса или контейнер) и шарить уже его.
sp::static_ptr p;
// ... вpлежит объект
TObj obj{std::move(*p)};Теперь я не понял :) почему в p лежит объект? Указатель ведь. И что остается в p на месте объекта после move? Так понимаю, что мусор и p больше использовать нельзя. Еще тут Вы вовсе отказываетесь от своего указателя: извлекаете объект и используете напрямую, возвращаясь к старому управлению его жизненным циклом.

rafuck
15.05.2022 00:46+1У меня вопрос, зачем это нужно вообще? Ну то есть динамический буфер в стеке — это старый добрый alloca или (что по сути обсуждаемого вопроса то же самое) VLA. Тут вроде бы корректный вызов деструкторов. Но. Если такое делаешь, то уж как-нибудь за собой подберешь. А так получается, что условно даются спички детям. В общем, я, кажется, против таких умных указателей на стек.
Izaron Автор
15.05.2022 01:03+3Наверное картинки в статье вводят всех в заблуждение. Объекты
sp::static_ptr<T>не живут только на стеке.Например в
std::vector<sp::static_ptr<T>>alloca/VLA ничем не помогут. Почему, например, такой вектор круче - описал тут https://habr.com/ru/post/665632/#comment_24343986"Динамический буфер" - буфер все таки статический, хотя в compile-time проверяется что объекты туда залезут.
rafuck
15.05.2022 01:13Да, я это понимаю. С локальностью памяти так и поступают выделяя память сразу куском (и в куче), а потом формируя вектор из указателей на объекты. Но это важно в очень ограниченном классе программ, например, в тех, которые молотят числа.
Antervis
15.05.2022 01:25+2можно было просто сделать аллокатор, выделяющий объекты на стеке и корректно их вычищаюший, после чего этот
static_ptrреализуется как:template <typename T> using static_ptr = std::unique_ptr<T, stack_allocator<T>>;Еще можно было переопределить у объекта операторы new/delete. Или подставить аллокатор в контейнер. Собственно поэтому никто и не делает для подобного специальный умный указатель.
Izaron Автор
15.05.2022 01:43+1На стеке много объектов выделить не получится, он обычно маленький (8192 KiB). А как вы будете аккуратно аллоцировать объекты разных размеров? Тут свой головняк начнется, это не проще.
Для "маленьких объектов" есть memory pools (https://betterprogramming.pub/c-memory-pool-and-small-object-allocator-8f27671bd9ee)
В принципе
static_ptrоторван от всяких кастомных аллокаторов, это перпендикулярно к нему идет. Можно считать, чтоstatic_ptrэто такое представлениеstd::unique_ptr<T>, где указательT* tи, хм, объект*tнаходятся "рядом" by desing.
restranger
15.05.2022 02:11+1+1 к комментарию Antervis.
sp::static_ptr как описан в статье смешивает обязанности выделения памяти и управления временем жизни объекта. Для решения поставленной задачи (выделение памяти на стэке, или в непрерывном участке кучи, или еще как) достаточно специализированного аллокатора, который можно совместить с разными умными указателями или контейнерами.
Очень близко к теме статьи, Александреску в Современном дизайне С++ (https://books.google.ch/books?id=aJ1av7UFBPwC) описывает интересный модульный подход для кастомизации умного указателя и даёт несколько примеров аллокаторов, оптимизированных под разные цели.
Antervis
15.05.2022 03:56А как вы будете аккуратно аллоцировать объекты разных размеров? Тут свой головняк начнется, это не проще.
Самый простой и лаконичный вариант вам уже назвали выше - std::variant из наследников. Еще можно например делать разные пулы для объектов разного типа. А если исходить из задачи, то стоит помнить, что лайфтаймы объектов, выделенных на стеке, соотносятся по принципу, хах, стека - последний созданный удаляется первым. То есть задачу можно решать простым кастомным аллокатором.
Просто на мой взгляд ваше решение кажется оверинжинирингом с целью покрыть общий случай того, что само по себе является чертовски частным случаем. И мне очень сложно представить себе проект в котором это могло бы "окупиться" с точки зрения количества и сложности кода.
Readme
17.05.2022 13:07Только жеж:
- Во-первых,
std::unique_ptr'у нельзя подсунуть аллокатор, а толькоdeleter, поэтому не получится так просто его использовать, придётся действительно огородить свойoperator newи связывать его сdeleter'ом. - Как уже замечали выше, понятие "указатель на стеке" вводит в заблуждение,
static_ptrо полиморфности со стиранием типа "на месте", т.е. как будто очень похож наstd::[not_very_]any, хранящий только определённую иерархию классов, и с mandatory small-object-optimization (т.е. неаллоцирующий).
Antervis
17.05.2022 13:47Во-первых,
std::unique_ptr'у нельзя подсунуть аллокатор, а толькоdeleter, поэтому не получится так просто его использовать, придётся действительно огородить свойoperator newи связывать его сdeleter'ом.не обязательно, можно сделать свою make-функцию. С аллокатором я косякнул, да
- Во-первых,
0xd34df00d
15.05.2022 06:45+1на 10 строке слом компиляции в виде static_assert происходит с хаком
И с UB.
Поэтому выравнивание должно быть максимально возможным, которое только бывает. В этом нам поможет тип std::max_align_t
Не поможет, потому что можно попросить произвольно большое выравнивание через alignas (и я лично даже такое просил, когда мне надо было гарантировать, что в одну кеш-линию попадает не больше одного объекта).

shuhray
15.05.2022 09:40+1Картинка идеально подходит. Было уродливо, стало уродливо, всегда будет уродливо.

dyadyaSerezha
15.05.2022 10:30-2Одна из самых популярных причин использования этого указателя - динамический полиморфизм.
Серьёзно?? Дальше я читать просто не стал. Но в комментах увидел цитату "а как создать на стеке заранее неизвестный объект?" - решение существует много лет и является стандартным.

skozharinov
15.05.2022 11:39-2Одна из самых популярных причин использования этого указателя — динамический полиморфизм.
Для этого вроде std::shared_ptr используют

mike124
17.05.2022 11:05-1Я понимаю, что сейчас рождается и развивается программистский жаргон, но, уважаемый автор, использовать такое: "можно только мувать в другой
static_ptr" - это себя не уважать.Может вам стоит в школу вернуться и выучить, наконец, русский язык?
amarao
Эх... ведь тот же раст, но как сложно...
tbl
Ну и как ты без ухищрений типа процедурных макросов сделаешь в расте Vec из трейтов? Без заворачивания в Box. Здесь в статье это и делают, используя только возможности языка.
Upd.: нашел, и без процедурных макросов, выглядит даже проще, чем в плюсах.
amarao
Спасибо и за вопрос, и за ответ.