

Многие аналитики данных сталкиваются с задачей распознавания адресов, напечатанных на документах. Для решения этой задачи я обратился к инструментам выявления сущностей в тексте с помощью NLP: NLTK, Spacy, Flair, DeepPavlov, Polyglot, AdaptNLP, Stanza, AllenNLP, HanLP, PullEnti, Natasha и тд. Глаза начали разбегаться. И что же делать? Конечно, выбрать самое лучшее. Я принял решение выбрать несколько самых популярных библиотек, поддерживающих русский язык, и сравнить, какую же из них использовать? Natasha, Stanza и PullEnti привлекли мое внимание. Далее пойдет речь именно об этих библиотеках.
1. Stanza
Stanza —это набор точных и эффективных инструментов для лингвистического анализа многих человеческих языков, разработанных университетом Стенфордом в 2020 году. Он содержит инструменты, которые можно использовать в конвейере для преобразования строки, содержащей текст на человеческом языке в списки предложений и слов с целью создания базовых форм этих слов, их частей речи и морфологических признаков, для анализа зависимости синтаксической структуры и распознавания именованных сущностей. Инструментарий предназначен для параллельного использования более чем 70 языков.
Использование:
#Импорт Stanza
import stanza
# Скачивание требуемой модели
stanza.download('ru')
# инициализация нейронной модели
nlp = stanza.Pipeline('ru')
#Текст, содержащий адреса
text = "текст текст текст Россия, Воронежская обл., г. Воронеж, Ленинский р-н, ул. 9 Января, д. 68к текст текст текст"
#Извлечение адреса из текста
doc = nlp(text)
#Цикл для вывода адреса в удобной форме
for el in doc.sentences:
for ent in el.entities:
if (ent.type in ('LOC')):
print (ent.text,' ',ent.type)Результат:
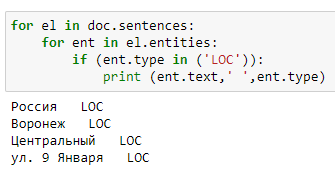
Stanza использует предварительно обученные и настроенные модели и языки, которые для использования требуется предварительно загрузить, что не всегда бывает удобно (для русского языка она требовала 524мб памяти). Чувствительна к расположению ключевых слов и их сокращений, не всегда видит названия населенных пунктов, состоящих из нескольких слов, отказывается видеть номера домов, корпусов, и квартир. Но стоит заметить, что Stanza проста в использовании: библиотеку достаточно импортировать, загрузить модель, вызвать функцию, а на выходе получить объект, из которого после выполнения необходимо извлечь нужные нам атрибуты.
2. Natasha
Natasha решает основные задачи NLP для русского языка: токенизация, сегментация предложений, встраивание слов, разметка морфологии, лемматизация, нормализация фраз, разбор синтаксиса, разметка NER, извлечение фактов.
Использование:
#Импортируем необходимые модули из Natasha и объявляем переменные
from natasha import (
Segmenter,
MorphVocab,
LOC,
AddrExtractor
)
segmenter = Segmenter()
morph_vocab = MorphVocab()
addr_extractor = AddrExtractor(morph_vocab)
#Текст, содержащий адреса
text = "текст текст текст Россия, Воронежская область, г. Воронеж, район Ленинский, ул. 9 Января, д. 68к текст текст текст"
#Извлечение адреса из текста
matches = addr_extractor(text)
facts = [i.fact.as_json for i in matches]
#Цикл для вывода адреса в удобной форме
for i in range(len(facts)):
tmp = list(facts[i].values())
print(tmp[1], tmp[0])Результат:
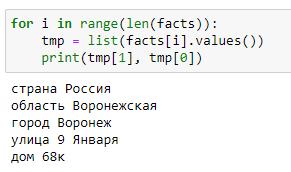
Natasha так же зависима от расположения ключевых слов и их сокращений, не распознает редкие сокращения населенных пунктов, не находит районы в адресах. Но т.к. Natasha использует словари и правила для распознавания сущностей, то их можно обогатить новыми данными, что позволит расширить функциональные возможности библиотеки, подстроив ее под конкретные задачи, например в библиотеке нет правила распознавания микрорайонов.
3. Pullenti
Pullenti предназначено для разработчиков информационных систем, имеющих дело с неструктурированными данными - текстами на естественном языке. Это программное обеспечение с открытым исходным кодом представлено на языках программирования C#, Java, Python и JavaScript.
SDK состоит из трёх независимых друг от друга частей:
Lingvo - лингвистический анализ текстов;
Unitext - выделение текстов из файлов;
Address - выделение из текста адресов и их привязка к ГАР ФИАС.
Использование:
#Импортируем необходимые модули из Pullenti и объявляем переменные
from pullenti_wrapper.langs import (
set_langs,
RU
)
set_langs([RU])
from pullenti_wrapper.processor import (
Processor,
GEO,
ADDRESS
)
from pullenti_wrapper.referent import Referent
processor = Processor([GEO, ADDRESS])
#Текст, содержащий адреса
text = "текст текст текст Россия, Воронежская область, г. Воронеж, Ленинский р-н, л. 9 Января, д. 68к текст текст текст"
#Функция формирования словаря с адресами
def display_shortcuts(referent, level=0):
tmp = {}
a = ""
b = ""
for key in referent.__shortcuts__:
value = getattr(referent, key)
if value in (None, 0, -1):
continue
if isinstance(value, Referent):
display_shortcuts(value, level + 1)
else:
if key == 'type':
a = value
if key == 'name':
b = value
# print('ok', value)
if key == 'house':
a = "дом"
b = value
tmp[a] = b
if key == 'flat':
a = "квартира"
b = value
# print('ok', value)
tmp[a] = b
if key == 'corpus':
a = "корпус"
b = value
tmp[a] = b
tmp[a] = b
addr.append(tmp)
#Использование функции display_shortcuts и вывод результатов
addr = []
result = processor(text)
referent = result.matches[0].referent
display_shortcuts(referent)
print(addr)Результат:

Pullenti имеет более лучшие показатели в задаче распознавания адресов при сравнении с конкурентами. Одним из плюсов является то, что в тексте осуществляется поиск адреса и привязка к объектам из ГАР ФИАС. То есть если адрес распознался, то значит он точно существует. Но Pullenti все-таки не лишен зависимости от расположения ключевых слов и их сокращений. В качестве приятного бонуса Pullenti имеет демонстрацию возможностей библиотеки, которую вы можете увидеть, перейдя по ссылке.
Для реализации всех примеров использования библиотек пришлось расширить программный код и обогатить исходный словарь новыми элементами.
После тестирования описанных модулей на тестовом наборе данных, состоящих из 500 адресов, приведенных в различных форматах, можно сделать вывод, что нет идеального инструмента “из коробки”, для распознавания сущностей адреса в тексте.
Подводя итоги, стоит отметить, что каждый исследованный инструмент по-своему хорош для решения конкретной задачи. При использовании библиотек необходимо учитывать их особенности и дополнительные возможности, которые предоставляются разработчиками этих решений.
Думаю, что данный материал будет полезен при решении задачи распознавания сущностей из текста, в частности адресов. В случае возникновения вопросов вы можете обращаться за консультацией к автору статьи.
CrazyElf
Хорошо бы добавить в итоговой части заметки табличку со списком библиотек, а также их плюсами и минусами, и фичами, которыми они между собой отличаются. Вылавливать это всё из текста самостоятельно не хотелось бы.