
Гиперконвергентные решения, доступные на современном рынке, можно условно разделить на два типа: «полноценные» и интегрированные. Их главное отличие заключается в железе, которое можно использовать при построении инфраструктуры. У настоящей гиперконвергенции (Nutanix HCI и VMware HCI) нет привязки к производителям оборудования: она запросто подружится с аппаратным обеспечением другого вендора. А интегрированные решения работают только на железе вендоров.
Наша платформа vStack — это тоже полноценная гиперконвергенция. Под катом я подробно расскажу, как в ней реализованы функции вычисления (SDC), хранения (SDS) и сети (SDN), и какие возможности это дает владельцам инфраструктуры.
Тем, кому интересна история создания vStack, рекомендую ознакомиться с предыдущей статьей.

Что такое HCI
Если вы уже знакомы с базовыми понятиями — можете смело пропустить эту часть и перейти к следующему разделу. Здесь же мы разберем, чем гиперконвергенция отличается от конвергенции и каковы ее основные преимущества.
Гиперконвергентная инфраструктура (HCI) — это программно-определяемая инфраструктура, которая объединяет в себе функции вычисления (SDC), хранения данных (SDS) и программной реализации сети (SDN). В отличие от классической инфраструктуры, где эти функции выполняют серверы с выделенными ролями или отдельные сущности вроде СХД и роутеров, в HCI они возложены на каждый сервер-участник инфраструктуры.
Обратите внимание на изображение ниже.
Справа — классическая схема организации корпоративной инфраструктуры: роутер, HA-пара коммутаторов ядра, пара коммутаторов сетей общего назначения, непосредственно сами серверы (в том числе резервные хосты), пара коммутаторов SAN, комплекс СХД с зарезервированными контроллерами (возможно, с дополнительными дисковыми полками). В такой ситуации использование оборудования разных вендоров (например, сетевое — от Cisco, СХД — от NetApp и т.д.) — абсолютно нормальная практика. При этом для поддержки каждого сегмента (вычислительного/сетевого/хранения) требуется отдельный специалист, знакомый с особенностями эксплуатации, взаимодействия с вендором и спецификой оборудования в целом. NAS остаётся правее viewport ????♂️
Слева — гиперконвергентное решение. Здесь все функции (SDS, SDC, SDN) выполняются кластером унифицированных x86-серверов с дисками.

Согласитесь, выглядит намного компактнее? При этом уровень доступности и в первом, и во втором варианте исполнения при прочих равных будет одинаков.
Ключевые преимущества HCI:
Более простая инфраструктура.
Дискретность гиперконвергентной инфраструктуры существенно ниже даже в приведенном примере, притом, что в случае конвергентной инфраструктуры в слое хранения NAS-составляющая просто не поместилась в экран. Этот фактор напрямую влияет на сложность эксплуатации, так как в ней задействовано немало узких специалистов. Количество людей растет вместе с размером инфраструктуры, так как и управление ею, и она сама дискретны. Каждый из элементов (сетевое оборудование, СХД, SAN, NAS, серверы) имеет собственные интерфейсы управления, концепции, API и т.д. Данная дискретность обуславливает следующий постулат: изменения конвергентной инфраструктуры могут растягиваться на месяцы.
В нашем гиперконвергентном решении такая дискретность отсутствует: управление имеет единые endpoint, интерфейс и API.
Однородность элементов гиперконвергентной инфраструктуры позволяет в случае неисправности (при желании) не тратить драгоценное в XXI веке время на ее локализацию. Достаточно вынуть диски из сервера, вышедшего из строя, и вставить их в ZIP и продолжить работу с прежним (референсным) уровнем резервирования.
Нет вендорлока.
Подойдет любое доступное на рынке оборудование, что теперь актуально, как никогда раньше. Даже потребительское.
Экономия на оборудовании.
Можно закупать аппаратное обеспечение потребительского сегмента и таким образом экономить на оборудовании некритичных сред, например, тестовых. Или кардинально снижать стоимость там, где используются горизонтально-масштабируемые решения, не требующие высокой степени резервирования одного элемента. К тому же заменить вышедшее из строя “потребительское” устройство будет несколько проще, чем enterprise.
Управление всей инфраструктурой через единый интерфейс
Его может обслуживать всего один опытный специалист — вам не придется нанимать отдельных сотрудников под каждый сегмент.
Архитектура vStack
Платформа создает единое кластерное пространство на базе серверов, одновременно выполняющих сразу 3 функции: Software Defined Storage, Software Defined Networking, Software Defined Computing — хранение, сеть, вычисления. Она объединяет три традиционно разрозненных компонента в одно программно-определяемое решение.
Программно-определяемые вычисления (SDС)
Слой SDC работает на базе гипервизора второго типа.
Поддерживается спецификация virtio для сетевых портов, дисков и другой периферии (rnd, balloon и т.п.). Кастомизация гостевых ОС в облачных образах реализуется с помощью cloud-init для unix-систем и cloud-base для windows.
-
Поддерживаемые ОС:
FreeBSD;
Linux (OEL/CentOS/Ubuntu/Debian);
Windows 2019/2022.
Облачные образы (cloud images):
Возможность лимитировать производительность сетевого порта (MBps) и диска (IOPS, MBps) в реальном времени.
Лимитирование ресурсов vCPU в реальном времени, в том числе автономное распределение квантов CPU в зависимости от степени overcommit, утилизации узла и нагрузки конкретной ВМ, благодаря чему показатели vCPU overcommit в промышленных кластерах иногда достигают 900%.
Снимки ВМ, содержащие её конфигурацию (в т.ч. сетевых портов и IP-адресов, а также MAC-адресов на этих сетевых портах).
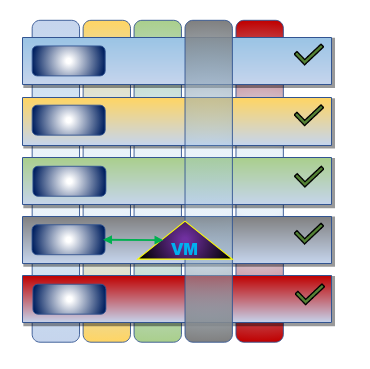
Отдельного упоминания заслуживает автономный механизм бюджетирования квантов vCPU, благодаря которому становится возможной экономическая эффективность (efficiency) в слое SDC до 900%. Таким значением может похвастаться далеко не каждое решение.
При создании vStack мы в первую очередь ориентировались на его легковесность. Низкий показатель CPU Overhead (снижение производительности виртуализованного сервера относительно физического) -- один из примеров возможного эффекта этого подхода. Например, overhead у KVM в некоторых нагрузках достигает 15%, а у vStack — всего лишь 2-5%. Таких низких значений удалось достичь благодаря использованию уникальности гипервизора bhyve.
Программно-определяемое хранилище (SDS)
Технологической основой SDS является ZFS.
Возможности:
компрессия и дедупликация;
внутренняя целостность данных;
клоны, снимки;
самовосстановление данных;
транзакционная целостность.
Лимиты (pool/filesystem):
размер: 1 zettabyte;
неограниченное количество файловых систем;
неограниченное количество блочных устройств.
Так выглядит пятиузловой кластер. Вертикальные контейнеры — пулы, горизонтальные — узлы кластера. Каждый пул содержит диск из каждого узла. Redundancy пула всегда равен redundancy кластера.

Для всех промышленных инсталляций мы рекомендуем использовать избыточность N+2 или выше (платформа поддерживает N+1, N+2 и N+3).
Что произойдет, если случится авария?
На картинке ниже желтый хост вышел из строя и за счет механизма fencing был исключен из кластера, а все пулы потеряли по одному диску. Кластер автоматически выполнил процедуру аварийного переключения (failover) ресурсов данного хоста, и желтый пул стал доступен на синем хосте. Redundancy снизился, но пул продолжает работать, причём без потери производительности. Все ВМ, работавшие на желтом хосте, продолжили работать на синем.

Программно-определяемая сеть (SDN)
Доступно три варианта обеспечения виртуальных сетей:
Vlan
Vxlan
GENEVE (собственная имплементация)
Вне зависимости от способа имплементации сеть может быть изолированной или маршрутизированной. Конкретный экземпляр виртуальной сети базируется на распределенном свитче (на картинке обозначен темно-синим прямоугольником). Реализация самой виртуальной сети, свитча в экосистеме netgraph и модификации в сетевом стеке — наши собственные разработки, прошедшие серьезные испытания и давно (с сентября 2020 г.) работающие в промышленной эксплуатации на большом количестве кластеров.

собственный MTU у каждого экземпляра сети;
маршрутизируемые/изолированные сети;
поддержка jumbo frames;
поддержка TSO/GSO.
поддержка path mtu discovery "из коробки"
Лимиты:
65536 сетей;
1 048 576 портов на свитче одного хоста;
виртуальный порт: 22 GBps / 2.5Mpps.
Как мы развиваем vStack
В новом релизе vStack v.2.1 появятся следующие возможности:
Миграция работающих виртуальных машин. Эта функциональность позволит без простоев переносить активные рабочие нагрузки с одного сервера на другой, чтобы пользователи продолжали иметь непрерывный доступ к системам, которые им необходимы. Аналогична vMotion в VMware.
Полноценное клонирование виртуальных машин. Мгновенное создание клона виртуальной машины любого объема, ограниченного ресурсами кластера.
Поддержка сетей на основе GENEVE. Открытая технология, имеющая стандарт.
Поддержка функциональности EDGE в графическом интерфейсе. EDGE-роутер — это программный маршрутизатор, через который виртуальные машины внутренних сетей получают доступ за её пределами и наоборот.
Поддержка VM ballooning — механизма оптимизации работы виртуальных машин с оперативной памятью, который позволяет возвращать хосту распределённую однажды гостевой ОС память, которая была впоследствии освобождена.
Поддержка QinQ (802.1ad).
Увеличение производительности платформы в слое хранения и вычислений.
Пара слов о лицензировании
vStack предоставляется по двум моделям:
Сервисная (OPEX).
Плата за использование лицензий. Ежемесячная тарификация и оплата за points.
On-premise (CAPEX).
Покупка лицензий в собственность. Единоразовый платеж плюс ежегодная оплата поддержки. В этой модели доступен overcommit: можно использовать на 33% больше ресурсов, чем выделено по договору.
В любом варианте доступна возможность Managed vStack — удаленное администрирование от вендора. Если у вас нет сотрудника, который мог бы взять на себя роль администратора, можно делегировать эту задачу нам.
Протестировать возможности vStack можно с помощью Serverspace, генерального амбассадора платформы. Если у вас остались вопросы, подразумевающие ответ, — задавайте их в комментариях, постараюсь всем ответить вне зависимости от цвета глаз! :)
Комментарии (4)

select26
11.06.2022 13:17И ещё вопрос: как у вас реализован уровень SDS? Я не понимаю как это может работать поверх ZFS. Как устроена репликация данных? Обработка отказа накопителя? Холодное/горячее хранилище?
Можно где-то ознакомиться с техническими деталями?

ildarz
11.06.2022 17:58+2Сравнение с "другими стиральными порошками" интересное, конечно. Но на практике, с одной стороны, коммутаторы и маршрутизаторы из крупной сети обычно никуда не деваются, а значит специалисты для их обслуживания нужны по-прежнему. С другой - в классической архитектуре тоже ничего особо не мешает сделать ровно так же, как у вас на картинке про vStack, только ещё СХД (подключенную к той же паре коммутаторов) к ней пририсовав.
Что до SAN - отдельные SAN-коммутаторы сейчас и без всякой конвергенции берут только люди, которые точно знают, зачем им это надо, а не желающие возиться с отдельным стеком оборудования просто живут на iSCSI.
В сухом остатке - убрали обслуживание СХД, добавили обслуживание SDS+SDN. И совершенно не факт, что такой размен выгоден.
Нет вендорлока.
А ваш софт - это что? :)
Можно закупать аппаратное обеспечение потребительского сегмента и таким образом экономить на оборудовании некритичных сред, например, тестовых.
А без вас это нельзя делать? :)
Лимитирование ресурсов vCPU в реальном времени, в том числе автономное распределение квантов CPU в зависимости от степени overcommit, утилизации узла и нагрузки конкретной ВМ, благодаря чему показатели vCPU overcommit в промышленных кластерах иногда достигают 900%.
Классическое "Приборы? - 20!". Что такое оверкоммит в 900%? Когда на одном физическом ядре живут 10 виртуальных, которые ничего не делают? Это я хоть на домашней винде могу устроить. Когда на том же ядре живут 10 нагруженных виртуальных? Тут вместо слов интересно было бы сравнительный тест увидеть, как при оверкоммите падает производительность у VMWare/KVM/Hyper-V и как у вас. Плюс в облаках (тем более публичных) последние годы озабочены не только оверкоммитом, но и безопасностью, а там надо наоборот не об оверкоммите заботиться, а об изоляции вычислительных потоков разных гостей, какие у вас тут есть механизмы?
Плюс совершенно не освещен вопрос проблем масштабирования. При классической архитектуре разные компоненты (вычислительные ноды, дисковая подсистема, сеть) могут при необходимости апгрейдиться и масштабироваться независимо друг от друга. В гиперконвергентных же решениях в случае, когда у вас через год-другой после начала эксплуатации стали появляться узкие места, которые на старте были совершенно не очевидны, всё куда забавнее.
Технологической основой SDS является ZFS.
Которая, как известно, в случае более-менее нагруженных систем даже в качестве чисто локальной FS весьма чувствительна к тюнингу под конкретные задачи, иначе производительность можно получить ну очень странную. В связи с чем было бы очень интересно посмотреть, как ведет себя кластер под высокой разнородной нагрузкой.
Redundancy снизился, но пул продолжает работать, причём без потери производительности.
А можете показать тесты? Причем не только с потерянной нодой, но и во время регенерации при возвращении узла назад.
Nova_Logic
А в чём конкурентное преимущество этого решения перед s2d, включенного в состав win 2019/2022 datacenter? На винде такое решение не очень понятно? на linux тоже не очень понятно зачем. тот-же proxmox соберет на ceph гиперконвергентную платформу (для тех кому хочется easy-to-use)
select26
Прелесть управления HCI можно понять лишь в сравнении. Я, после работы с NUTANIX, даже смотреть не хочу в сторону ранее обожаемого PROXMOX. Один интерфейс, один API, один Teraform provider. Я в одну каску админинистрирую 13 кластеров NUTANIX. И это в фоне.
Автору топика: цен не нашел. Интересно познакомиться.