
Ошибки и проблемные ситуации, которые возникают при работе высоконагруженных систем, имеют свои особенности и специфику. У нас в «Лаборатории Касперского» накопился целый ряд приемов по анализу таких ошибок. Часть приемов мы выложили в опенсорс в виде библиотеки скриптов для отладчиков, где есть в том числе JS-скрипты для WinDBG и Python-скрипты для GDB. В этой статье на живых примерах будет показано, как их использовать, и как автоматизировать хотя бы часть процесса анализа ошибок и подозрительных ситуаций.

Начнем с простого. Предположим, у нас 32-битное приложение запущено на 64-битном Windows. Там работает 100500 потоков. Внезапно мы получаем синий экран. Естественно, хочется посмотреть, что в это время делало наше приложение. Но из-за того, что оно 32-битное, в kernel mode мы видим списком только kernel’овые стеки:

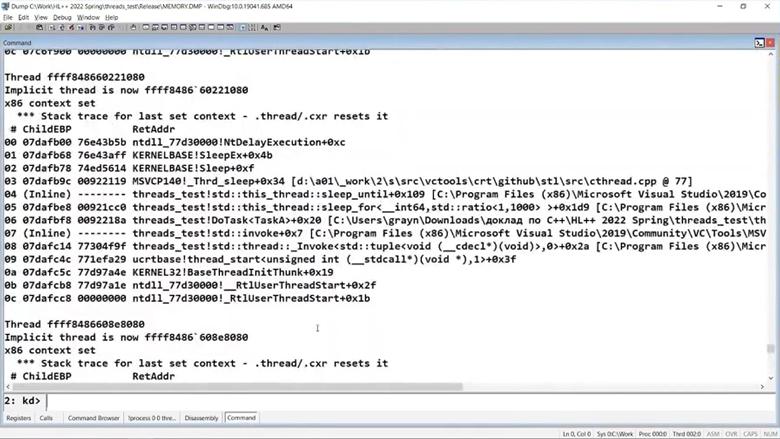
Переключить каждый конкретный поток в 32-битный режим, чтобы посмотреть его стек, несложно, но у нас их очень много. Поэтому есть скрипт (на JavaScript) для того, чтобы пробежаться по всем потокам и увидеть юзермодные части их стеков:

Вот простой пример для демонстрации, который запускает сотню потоков со случайными задержками.
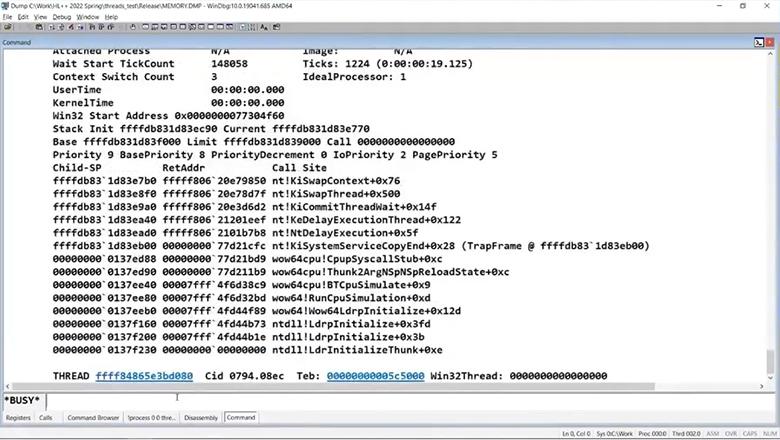
В дампе это выглядит так:
Чтобы увидеть что-то, кроме kernel-части, командой !x32stacks запустим скрипт, который покажет, что находилось и работало в нашей сотне потоков.
Иногда при разборе проблемы возникает подозрение, что какая-то ошибка или исключение, обработанные ранее, нам просто не попались или были подавлены, поэтому хочется заглянуть в то, что было, и разобраться в сложившейся ситуации. Не всегда, естественно, но иногда это удается сделать. Например, на Windows можно попытаться найти на стеке запчасти структуры, описывающей исключение.

Обычно при этом ищут структуру CONTEXT. Она содержит состояние процессора на момент исключения, в том числе практически все регистры. Чаще всего ее ищут по флагам либо сегментным регистрам. Если что-то обнаружилось, то выше по стеку ищем структуру EXCEPTION_POINTERS. Она содержит всего два указателя: на CONTEXT и на структуру EXCEPTION_RECORD. А EXCEPTION_RECORD уже содержит информацию об исключении: код исключения, адрес и параметры.
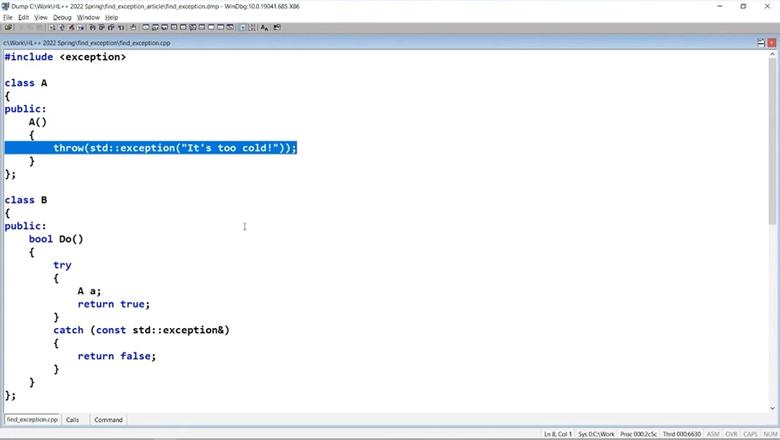
Посмотрим, как это работает вживую, на примере простой программы.
Здесь мы имитируем ситуацию с ошибкой логгера. В конструкторе бросается исключение, затем мы его ловим и выдаем ошибку, а при обработке ошибки уже падаем окончательно, потому что вызывали по левому адресу некий метод. При этом второе исключение полностью скрывает от нас первое, но можно попытаться найти его с помощью скрипта. Команда !exccandidates по умолчанию ищет исключения на стеке текущего потока. Так можно посмотреть, что там реально произошло.

Как раз нашлось одно плюсовое исключение. Далее можно взять контекст исключения и командой .cxr переключиться в его стек, чтобы увидеть, где его кинули, и выяснить, что к этому привело:
Эти структуры сохраняются на стеке не всегда. Иногда они перетираются в процессе работы, и их уже не найти. Но зачастую это все-таки помогает найти что-то интересное.
Ситуации с нехваткой памяти всегда актуальны. Но оговорюсь сразу, речь не об утечках, а о том, что какие-то компоненты или части программы позволяют себе несколько больше, чем рассчитывалось, в части потребления памяти. И при падении всегда хочется узнать, кого же за это стоит поблагодарить.
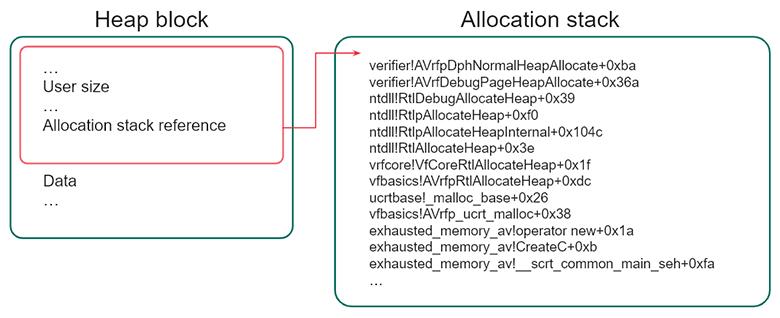
Начнем опять с простого: на Windows есть AppVerifier. Он, конечно, и сам умеет высчитывать и показывать разницу между хипами, но для этого требуется два последовательных дампа, которые он и будет сравнивать. Однако зачастую у нас двух дампов нет: есть только дамп с падением. Тем не менее мы можем воспользоваться информацией, которую AppVerifier нам любезно предоставит. Дело в том, что при отладке хипа он добавляет в каждый блок свою запись с информацией, в которой в том числе имеется стек выделения данного блока.
Дальше просто: перечислим все блоки, посчитаем, кто с каким стеком был выделен, и посмотрим, кто больше всего навыделял.
В данной тестовой программе есть три метода, в каждом из которых мы выделяем блок одного и того же размера — 0x8000 (побольше, чтобы побыстрее память закончилась), но с разным содержимым (строку туда записываем). Выделение происходит в случайном порядке, так что при каждом запуске мы и сами не знаем, каких блоков навыделяли больше всего. Начнем же мы с того, что найдем самый большой хип:

Здесь он у нас всего один. И, естественно, он забит блоками по 0x8000. Теперь запустим скрипт командой !av_heap_alloc_stats и посмотрим, какая функция навыделяла блоков больше всего:
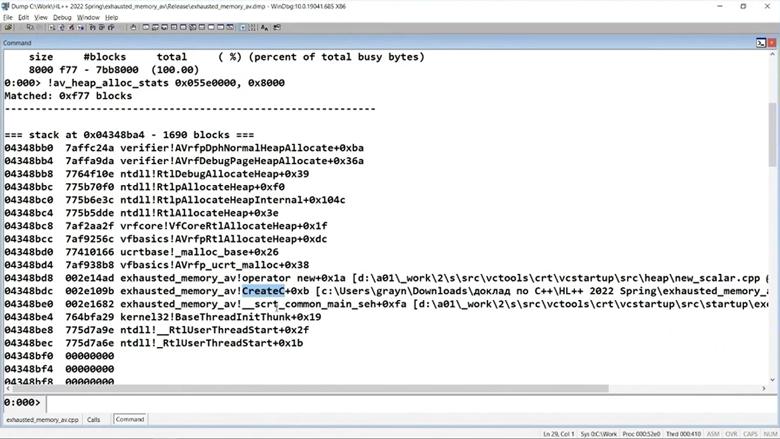
Скрипт сортирует найденные стеки по количеству выделенных блоков в порядке уменьшения. Здесь видно, что больше всего за время работы выделилось блоков функцией CreateC, поменьше — CreateB, и меньше всего — CreateA.
Вы, естественно, можете усмехнуться про себя: мол, тоже мне фокус — отклассифицировать память с сохраненными стеками-то. А вот что делать, если стеков выделения нет?
Если мы не используем Verifier либо, например, работаем на Linux, то искать того, кто больше всех скушал, так лихо уже не получится. Гарантированного способа тут нет, но можно попробовать прикинуть по самим данным, которые хранятся в выделенных блоках:
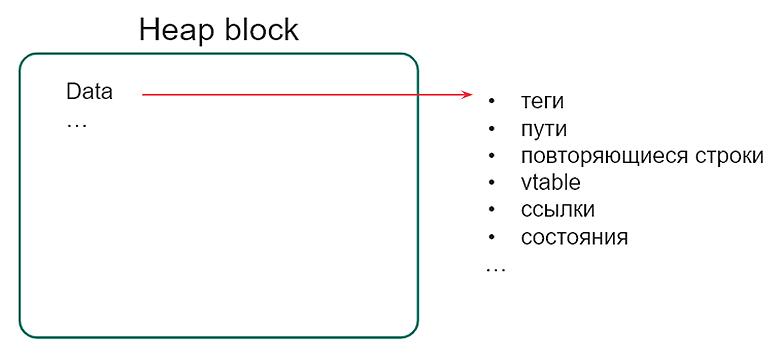
Как видим, вариантов, по которым можно объединить блоки в группы, достаточно много. Естественно, это срабатывает не всегда, но иногда все-таки удается найти того, кто много кушает. В качестве примера — программа, идентичная предыдущей:
Здесь тоже три функции, создающие структуры одного размера с разным содержимым, которые точно так же вызываются случайным образом. Только одно отличие: для того чтобы на 64-битном Linux не ждать слишком долго, пока это все будет анализироваться, я поставил SIGTRAP после 50000 выделенных блоков.
Запускаем наш пример под отладчиком, дожидаемся останова, загружаем скрипт и выполняем команду heap_alloc_stats. Она выдает статистику сразу по нескольким вариантам разбиения данных в блоке: сначала по первым четырем указателям, потом блоками по 2 и целиком по 4.

Мы видим, что блоков с текстом struct A выделено больше, чем с struct B и struct C вместе взятых. Естественно, в данных далеко не всегда удается найти что-то подходящее для классификации, но мне, например, несколько раз удавалось в продакшн найти компоненты, которые решили сохранить что-то лишнее.
Давайте теперь поговорим про корутины на Linux. Тема это популярная. Однако принимая решение об их использовании, стоит подумать еще и о том, с чем придется столкнуться, когда там будут случаться ошибки. Что делать, когда мы будем там падать.
Начнем опять с простого: в 20-м стандарте у нас официально появились корутины. Здесь они stackless. А это значит, что они работают в стеке вызвавшего их потока.
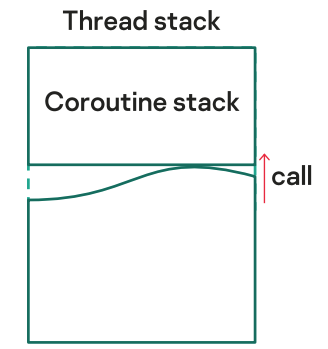
Таким образом, с точки зрения отладки это крайне простой вариант. Тут у нас очень простой примерчик из стандартных семплов — числа Фибоначчи:
Простота несколько не задалась, но они старались, я верю. Тут у нас корутинка-генератор, и чтобы сымитировать проблему, мы просто поставим в ней SIGTRAP. Теперь посмотрим, как это выглядит вживую:
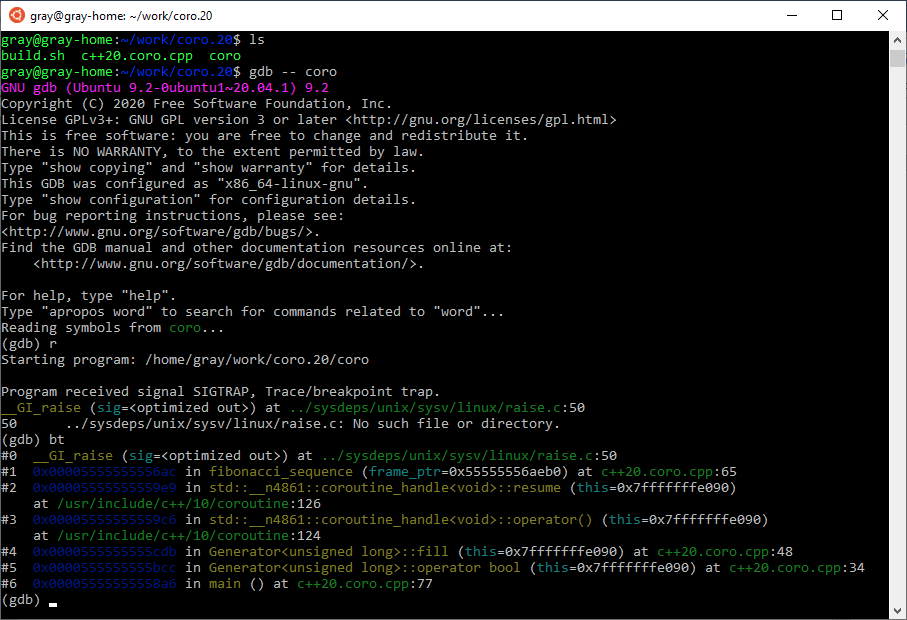
Собственно, это я и имел в виду: ничего делать не нужно — весь стек как на ладони.
Однако в запасе есть вариант поинтереснее — бустовые корутины. Они stackful, а значит, при вызове мы переключимся на личный стек данной корутинки.
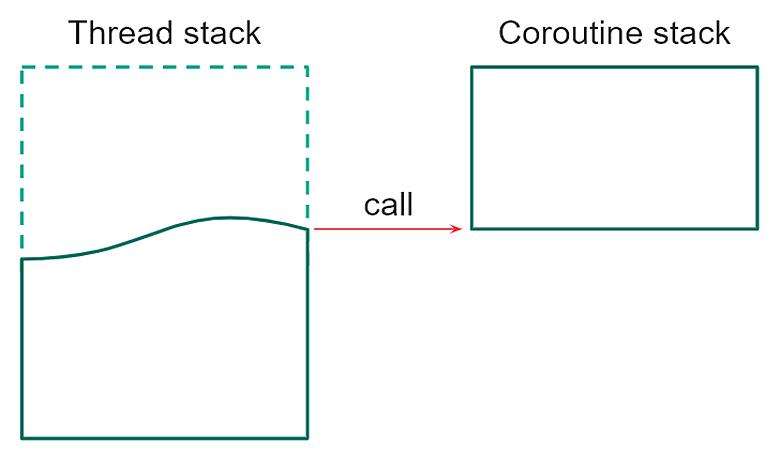
Что гораздо интереснее с точки зрения отладки, т. к. стек потока мы, соответственно, не увидим.
На всякий случай напомню, что в бусте два варианта корутинок, и начнем мы с первых.
Это те же самые числа Фибоначчи. Только код усох раза в три. И здесь мы тоже сымитируем проблему в корутине с помощью SIGTRAP.
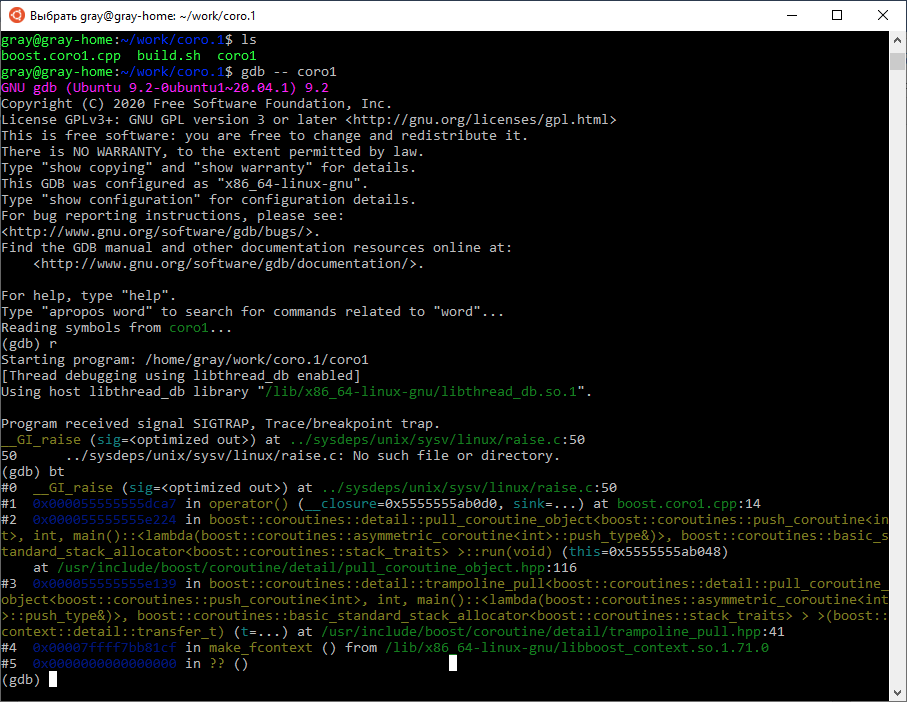
Ну что ж, это было ожидаемо. Видно стек только самой корутины и ничего более.
Хотелось бы вернуться в оригинальный стек потока. Но как? В этом нам поможет sink — он в первом фрейме. Он должен знать, куда надо перепрыгнуть, чтобы выполнить другую корутину.
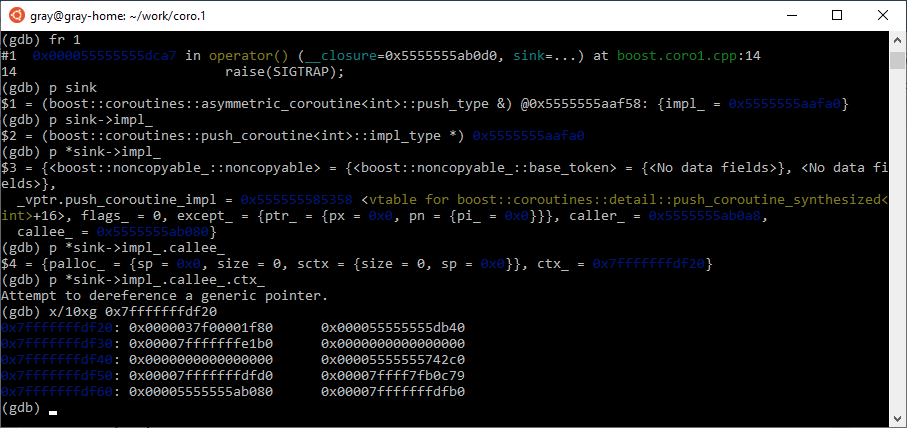
Если полазить по sink, то найдутся поля caller и callee: первое ссылается на контекст этой корутины, а второе на внешний контекст, который нам и нужен. Внутри контекста находится что-то. А что именно, нам заботливо подскажет буст — в файлах с ассемблерными функциями для переключения контекстов в начале находится комментарий с табличкой:
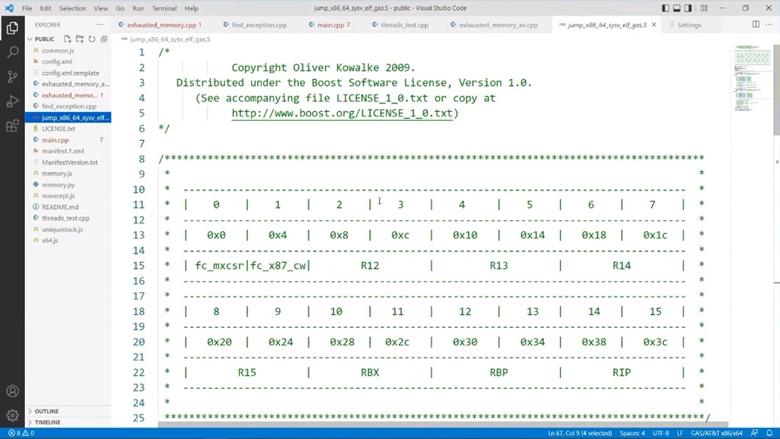
Это asm для GCC X86_64. Как видим, тут сохраняется часть регистров, в том числе RBP и RIP. Они-то нам и нужны. Но где же взять RSP?
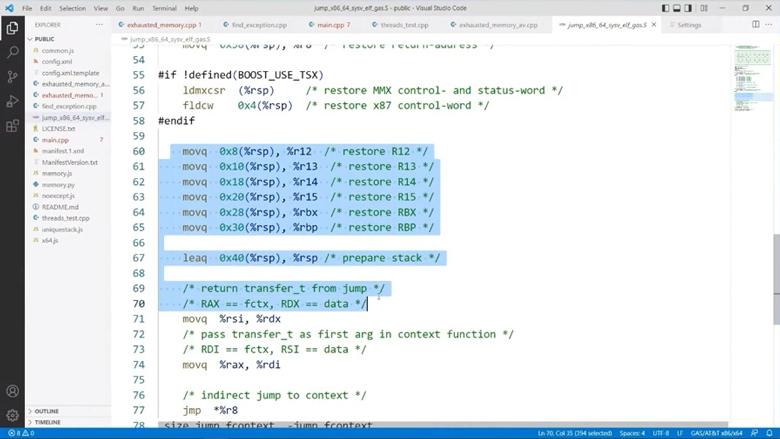
Если посмотреть ниже по этому же файлу, то видно, что в RSP загружается адрес сразу за этим блоком. Давайте теперь проверим, то ли мы нашли — посмотрим, куда указывает предположительный RIP:
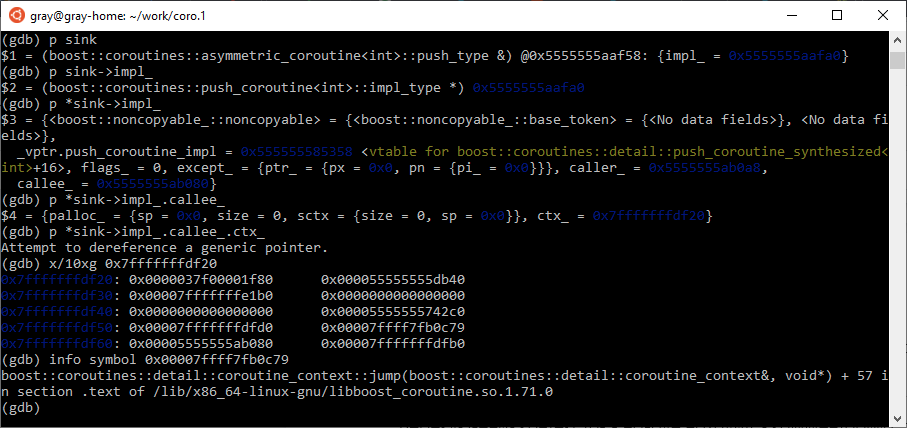
Вроде все правильно: как раз jump и переключает контексты, так что RIP, похоже, верный, а значит, можно попробовать переключиться в этот контекст:
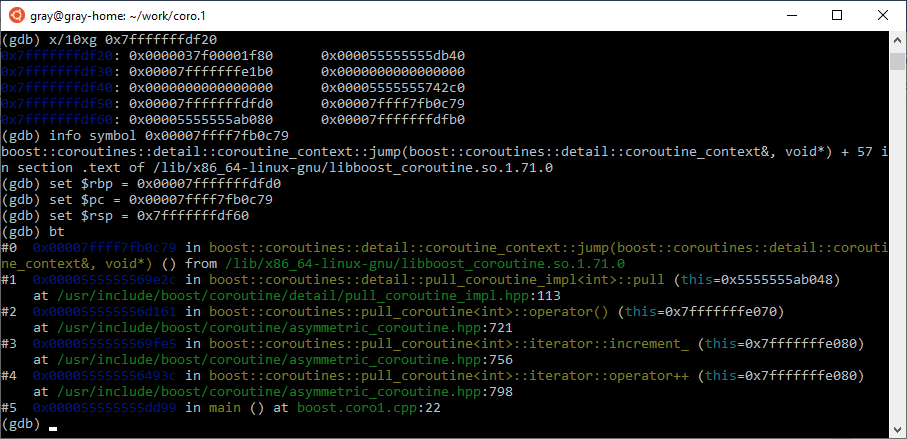
Ну вот, получили исходный стек потока и можем анализировать, что происходило в нем.
Но поскольку первые корутинки в бусте уже задепрекейчены, то давайте посмотрим, чем их заменили и как быть с бустовыми корутинами второй версии.
Здесь вообще все то же самое. Только корутины вторые. Посмотрим теперь на них вживую:
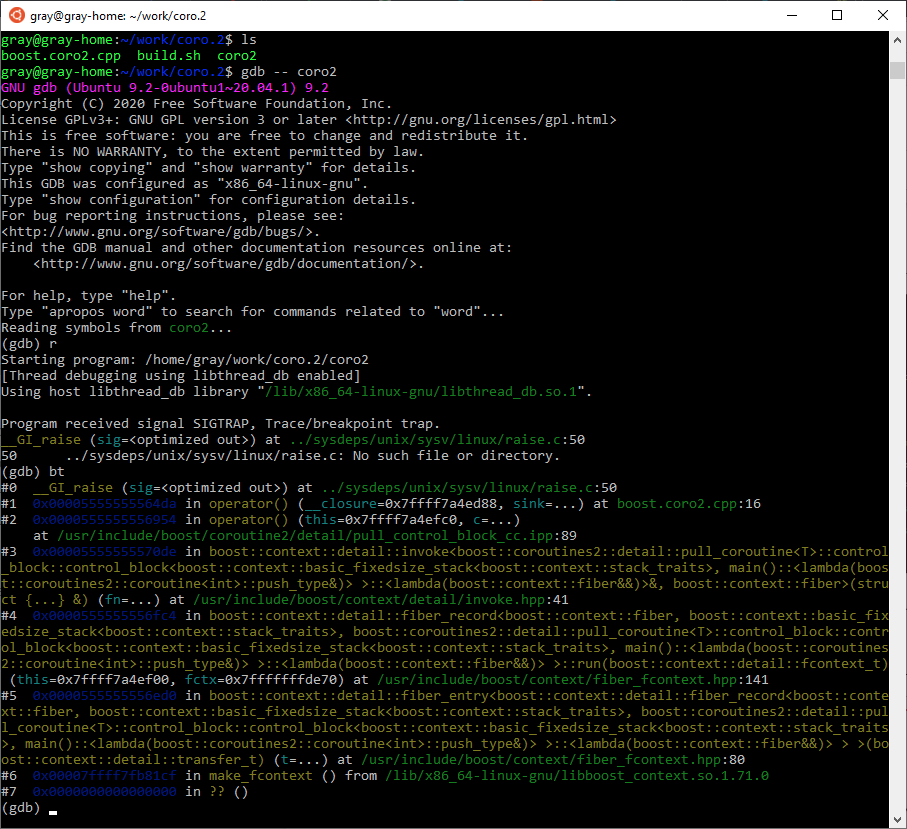
Видно, что теперь корутинки используют boost::fiber. Но переключение все равно делается через boost::context, а значит, нам надо просто его найти. И нам опять поможет sink:

Тип у sink теперь другой, и мы быстрее добираемся до искомого контекста: он в поле fctx_. Содержимое, очевидно, аналогично, но RIP теперь указывает на fiber::resume. Переключимся туда:
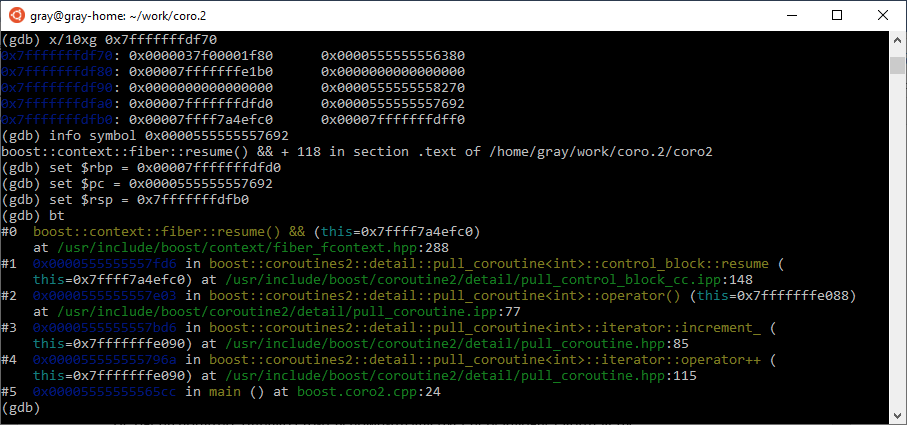
И вот исходный стек потока.
Описанные скрипты вместе с приемами по анализу ошибок позволяют существенно сократить время на выявление причин проблемных ситуаций. Если вы тоже любите копаться в crash-дампах и создавать рабочие техники по поиску ошибок и проблемных ситуаций, то приходите к нам — будем пополнять арсенал этих техник вместе!
х32-стеки
Начнем с простого. Предположим, у нас 32-битное приложение запущено на 64-битном Windows. Там работает 100500 потоков. Внезапно мы получаем синий экран. Естественно, хочется посмотреть, что в это время делало наше приложение. Но из-за того, что оно 32-битное, в kernel mode мы видим списком только kernel’овые стеки:
Переключить каждый конкретный поток в 32-битный режим, чтобы посмотреть его стек, несложно, но у нас их очень много. Поэтому есть скрипт (на JavaScript) для того, чтобы пробежаться по всем потокам и увидеть юзермодные части их стеков:
Вот простой пример для демонстрации, который запускает сотню потоков со случайными задержками.
#include <ctime>
#include <chrono>
#include <random>
#include <thread>
#include <vector>
#include <iostream>
struct TaskA { enum { delay = 1000000 }; };
struct TaskB { enum { delay = 1100000 }; };
struct TaskC { enum { delay = 1200000 }; };
template <typename T>
__declspec(noinline) static void DoTask() {
std::this_thread::sleep_for(std::chrono::milliseconds(T::delay));
}
constexpr const int ThreadCount = 100;
int main() {
std::mt19937_64 randomGenerator(std::time(nullptr));
uint64_t a_level = randomGenerator();
uint64_t b_level = randomGenerator();
if (a_level == b_level)
b_level = randomGenerator();
if (a_level > b_level)
std::swap(a_level, b_level);
std::cout << "Levels: " << a_level << ", " << b_level << "\n";
std::vector<std::thread> threads;
std::cout << "Creating threads...";
for (int i = 0; i < ThreadCount; ++i) {
uint64_t rnd = randomGenerator();
if (rnd < a_level)
threads.push_back(std::thread(DoTask<TaskA>));
else if (rnd < b_level)
threads.push_back(std::thread(DoTask<TaskB>));
else
threads.push_back(std::thread(DoTask<TaskC>));
}
std::cout << "done.\n";
std::cout << "Waiting for threads end...";
for (auto& thr : threads)
thr.join();
std::cout << "done.\n";
return 0;
}В дампе это выглядит так:
Чтобы увидеть что-то, кроме kernel-части, командой !x32stacks запустим скрипт, который покажет, что находилось и работало в нашей сотне потоков.
Поиск исключений
Иногда при разборе проблемы возникает подозрение, что какая-то ошибка или исключение, обработанные ранее, нам просто не попались или были подавлены, поэтому хочется заглянуть в то, что было, и разобраться в сложившейся ситуации. Не всегда, естественно, но иногда это удается сделать. Например, на Windows можно попытаться найти на стеке запчасти структуры, описывающей исключение.
Обычно при этом ищут структуру CONTEXT. Она содержит состояние процессора на момент исключения, в том числе практически все регистры. Чаще всего ее ищут по флагам либо сегментным регистрам. Если что-то обнаружилось, то выше по стеку ищем структуру EXCEPTION_POINTERS. Она содержит всего два указателя: на CONTEXT и на структуру EXCEPTION_RECORD. А EXCEPTION_RECORD уже содержит информацию об исключении: код исключения, адрес и параметры.
Посмотрим, как это работает вживую, на примере простой программы.
#include <exception>
class A {
public:
A() {
throw(std::exception("It's too cold!"));
}
};
class B {
public:
bool Do() {
try {
A a;
return true;
} catch (const std::exception&) {
return false;
}
}
};
class Log {
public:
void Notify(const char* msg) {
message = msg;
}
private:
const char* message;
};
class C {
public:
C() {
B b;
if (!b.Do())
reinterpret_cast<Log*>(1)->Notify("I don't know what happened!"); // Simulating tracer lifetime error
}
};
int main() {
C c;
return 0;
}Здесь мы имитируем ситуацию с ошибкой логгера. В конструкторе бросается исключение, затем мы его ловим и выдаем ошибку, а при обработке ошибки уже падаем окончательно, потому что вызывали по левому адресу некий метод. При этом второе исключение полностью скрывает от нас первое, но можно попытаться найти его с помощью скрипта. Команда !exccandidates по умолчанию ищет исключения на стеке текущего потока. Так можно посмотреть, что там реально произошло.
Как раз нашлось одно плюсовое исключение. Далее можно взять контекст исключения и командой .cxr переключиться в его стек, чтобы увидеть, где его кинули, и выяснить, что к этому привело:
Эти структуры сохраняются на стеке не всегда. Иногда они перетираются в процессе работы, и их уже не найти. Но зачастую это все-таки помогает найти что-то интересное.
Пожиратели памяти с AppVerifier
Ситуации с нехваткой памяти всегда актуальны. Но оговорюсь сразу, речь не об утечках, а о том, что какие-то компоненты или части программы позволяют себе несколько больше, чем рассчитывалось, в части потребления памяти. И при падении всегда хочется узнать, кого же за это стоит поблагодарить.
Начнем опять с простого: на Windows есть AppVerifier. Он, конечно, и сам умеет высчитывать и показывать разницу между хипами, но для этого требуется два последовательных дампа, которые он и будет сравнивать. Однако зачастую у нас двух дампов нет: есть только дамп с падением. Тем не менее мы можем воспользоваться информацией, которую AppVerifier нам любезно предоставит. Дело в том, что при отладке хипа он добавляет в каждый блок свою запись с информацией, в которой в том числе имеется стек выделения данного блока.
Дальше просто: перечислим все блоки, посчитаем, кто с каким стеком был выделен, и посмотрим, кто больше всего навыделял.
#include <ctime>
#include <random>
constexpr const size_t Add = 0x8000;
template <int LabelSize = 0>
struct A {
char name[Add + LabelSize];
};
__declspec(noinline) static void CreateA() {
static constexpr const char label[] = "A struct";
A<>* val = new A<>();
memcpy_s(val->name, sizeof(val->name), label, sizeof(label));
}
__declspec(noinline) static void CreateB() {
static constexpr const char label[] = "B struct - slightly bigger";
A<>* val = new A<>();
memcpy_s(val->name, sizeof(val->name), label, sizeof(label));
}
__declspec(noinline) static void CreateC() {
static constexpr const char label[] = "C struct - it size is greater than all previous structures";
A<>* val = new A<>();
memcpy_s(val->name, sizeof(val->name), label, sizeof(label));
}
int main() {
std::mt19937_64 randomGenerator(std::time(nullptr));
uint64_t a_level = randomGenerator();
uint64_t b_level = randomGenerator();
if (a_level == b_level)
b_level = randomGenerator();
if (a_level > b_level)
std::swap(a_level, b_level);
for (;;) {
uint64_t rnd = randomGenerator();
if (rnd < a_level)
CreateA();
else if (rnd < b_level)
CreateB();
else
CreateC();
}
return 0;
}В данной тестовой программе есть три метода, в каждом из которых мы выделяем блок одного и того же размера — 0x8000 (побольше, чтобы побыстрее память закончилась), но с разным содержимым (строку туда записываем). Выделение происходит в случайном порядке, так что при каждом запуске мы и сами не знаем, каких блоков навыделяли больше всего. Начнем же мы с того, что найдем самый большой хип:
Здесь он у нас всего один. И, естественно, он забит блоками по 0x8000. Теперь запустим скрипт командой !av_heap_alloc_stats и посмотрим, какая функция навыделяла блоков больше всего:
Скрипт сортирует найденные стеки по количеству выделенных блоков в порядке уменьшения. Здесь видно, что больше всего за время работы выделилось блоков функцией CreateC, поменьше — CreateB, и меньше всего — CreateA.
Вы, естественно, можете усмехнуться про себя: мол, тоже мне фокус — отклассифицировать память с сохраненными стеками-то. А вот что делать, если стеков выделения нет?
Пожиратели памяти без AppVerifier
Если мы не используем Verifier либо, например, работаем на Linux, то искать того, кто больше всех скушал, так лихо уже не получится. Гарантированного способа тут нет, но можно попробовать прикинуть по самим данным, которые хранятся в выделенных блоках:
Как видим, вариантов, по которым можно объединить блоки в группы, достаточно много. Естественно, это срабатывает не всегда, но иногда все-таки удается найти того, кто много кушает. В качестве примера — программа, идентичная предыдущей:
#include <ctime>
#include <random>
#include <cstring>
#include <signal.h>
constexpr const size_t BufSize = 0x8000;
struct A {
char name[BufSize];
};
static void CreateA() {
static constexpr const char label[] = "struct A";
A* val = new A();
memcpy(val->name, label, sizeof(label));
}
static void CreateB() {
static constexpr const char label[] = "struct B - slightly bigger";
A* val = new A();
memcpy(val->name, label, sizeof(label));
}
static void CreateC() {
static constexpr const char label[] = "struct C - it size is greater than all previous structures";
A* val = new A();
memcpy(val->name, label, sizeof(label));
}
int main() {
std::mt19937_64 randomGenerator(std::time(nullptr));
uint64_t a_level = randomGenerator();
uint64_t b_level = randomGenerator();
if (a_level == b_level)
b_level = randomGenerator();
if (a_level > b_level)
std::swap(a_level, b_level);
for (unsigned int i = 0; i < 50000; ++i)
{
uint64_t rnd = randomGenerator();
if (rnd < a_level)
CreateA();
else if (rnd < b_level)
CreateB();
else
CreateC();
}
raise(SIGTRAP);
return 0;
}Здесь тоже три функции, создающие структуры одного размера с разным содержимым, которые точно так же вызываются случайным образом. Только одно отличие: для того чтобы на 64-битном Linux не ждать слишком долго, пока это все будет анализироваться, я поставил SIGTRAP после 50000 выделенных блоков.
Запускаем наш пример под отладчиком, дожидаемся останова, загружаем скрипт и выполняем команду heap_alloc_stats. Она выдает статистику сразу по нескольким вариантам разбиения данных в блоке: сначала по первым четырем указателям, потом блоками по 2 и целиком по 4.
Мы видим, что блоков с текстом struct A выделено больше, чем с struct B и struct C вместе взятых. Естественно, в данных далеко не всегда удается найти что-то подходящее для классификации, но мне, например, несколько раз удавалось в продакшн найти компоненты, которые решили сохранить что-то лишнее.
Корутины
Давайте теперь поговорим про корутины на Linux. Тема это популярная. Однако принимая решение об их использовании, стоит подумать еще и о том, с чем придется столкнуться, когда там будут случаться ошибки. Что делать, когда мы будем там падать.
Начнем опять с простого: в 20-м стандарте у нас официально появились корутины. Здесь они stackless. А это значит, что они работают в стеке вызвавшего их потока.
Таким образом, с точки зрения отладки это крайне простой вариант. Тут у нас очень простой примерчик из стандартных семплов — числа Фибоначчи:
#include <coroutine>
#include <exception>
#include <iostream>
#include <signal.h>
template<typename T>
struct Generator {
struct promise_type;
using handle_type = std::coroutine_handle<promise_type>;
struct promise_type {
T value_;
std::exception_ptr exception_;
Generator get_return_object() {
return Generator(handle_type::from_promise(*this));
}
std::suspend_always initial_suspend() { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void unhandled_exception() { exception_ = std::current_exception(); }
template<std::convertible_to<T> From>
std::suspend_always yield_value(From&& from) {
value_ = std::forward<From>(from);
return {};
}
void return_void() {}
};
handle_type h_;
Generator(handle_type h) : h_(h) {}
~Generator() { h_.destroy(); }
explicit operator bool() {
fill();
return !h_.done();
}
T operator()() {
fill();
full_ = false;
return std::move(h_.promise().value_);
}
private:
bool full_ = false;
void fill() {
if (!full_) {
h_();
if (h_.promise().exception_)
std::rethrow_exception(h_.promise().exception_);
//propagate coroutine exception in called context
full_ = true;
}
}
};
Generator<uint64_t>
fibonacci_sequence() {
uint64_t a = 1, b = 1;
co_yield a;
co_yield b;
for (unsigned i = 0; i < 8; ++i) {
if (i == 4)
raise(SIGTRAP);
uint64_t s = a + b;
co_yield s;
a = b;
b = s;
}
}
int main()
{
auto gen = fibonacci_sequence();
for (int j = 0; gen; j++)
std::cout << gen() << ' ';
return 0;
}Простота несколько не задалась, но они старались, я верю. Тут у нас корутинка-генератор, и чтобы сымитировать проблему, мы просто поставим в ней SIGTRAP. Теперь посмотрим, как это выглядит вживую:
Собственно, это я и имел в виду: ничего делать не нужно — весь стек как на ладони.
Однако в запасе есть вариант поинтереснее — бустовые корутины. Они stackful, а значит, при вызове мы переключимся на личный стек данной корутинки.
Что гораздо интереснее с точки зрения отладки, т. к. стек потока мы, соответственно, не увидим.
На всякий случай напомню, что в бусте два варианта корутинок, и начнем мы с первых.
#include <iostream>
#include <boost/coroutine/all.hpp>
#include <signal.h>
int main()
{
boost::coroutines::asymmetric_coroutine<int>::pull_type source(
[&](boost::coroutines::asymmetric_coroutine<int>::push_type& sink) {
int first = 1, second = 1;
sink(first);
sink(second);
for (int i = 0; i < 8; ++i) {
if (i == 4)
raise(SIGTRAP);
int third = first + second;
first = second;
second = third;
sink(third);
}
});
for (auto i : source)
std::cout << i << " ";
return 0;
}Это те же самые числа Фибоначчи. Только код усох раза в три. И здесь мы тоже сымитируем проблему в корутине с помощью SIGTRAP.
Ну что ж, это было ожидаемо. Видно стек только самой корутины и ничего более.
Хотелось бы вернуться в оригинальный стек потока. Но как? В этом нам поможет sink — он в первом фрейме. Он должен знать, куда надо перепрыгнуть, чтобы выполнить другую корутину.
Если полазить по sink, то найдутся поля caller и callee: первое ссылается на контекст этой корутины, а второе на внешний контекст, который нам и нужен. Внутри контекста находится что-то. А что именно, нам заботливо подскажет буст — в файлах с ассемблерными функциями для переключения контекстов в начале находится комментарий с табличкой:
Это asm для GCC X86_64. Как видим, тут сохраняется часть регистров, в том числе RBP и RIP. Они-то нам и нужны. Но где же взять RSP?
Если посмотреть ниже по этому же файлу, то видно, что в RSP загружается адрес сразу за этим блоком. Давайте теперь проверим, то ли мы нашли — посмотрим, куда указывает предположительный RIP:
Вроде все правильно: как раз jump и переключает контексты, так что RIP, похоже, верный, а значит, можно попробовать переключиться в этот контекст:
Ну вот, получили исходный стек потока и можем анализировать, что происходило в нем.
Но поскольку первые корутинки в бусте уже задепрекейчены, то давайте посмотрим, чем их заменили и как быть с бустовыми корутинами второй версии.
#include <iostream>
#include <boost/coroutine2/all.hpp>
#include <signal.h>
int main()
{
typedef boost::coroutines2::coroutine<int> coro_t;
coro_t::pull_type source(
[&](coro_t::push_type& sink) {
int first = 1, second = 1;
sink(first);
sink(second);
for (int i = 0; i < 8; ++i) {
if (i == 4)
raise(SIGTRAP);
int third = first + second;
first = second;
second = third;
sink(third);
}
});
for (auto i : source)
std::cout << i << " ";
return 0;
}Здесь вообще все то же самое. Только корутины вторые. Посмотрим теперь на них вживую:
Видно, что теперь корутинки используют boost::fiber. Но переключение все равно делается через boost::context, а значит, нам надо просто его найти. И нам опять поможет sink:
Тип у sink теперь другой, и мы быстрее добираемся до искомого контекста: он в поле fctx_. Содержимое, очевидно, аналогично, но RIP теперь указывает на fiber::resume. Переключимся туда:
И вот исходный стек потока.
Заключение
Описанные скрипты вместе с приемами по анализу ошибок позволяют существенно сократить время на выявление причин проблемных ситуаций. Если вы тоже любите копаться в crash-дампах и создавать рабочие техники по поиску ошибок и проблемных ситуаций, то приходите к нам — будем пополнять арсенал этих техник вместе!