
Привет! Сегодня у нашей статьи два автора — бэкенд-разработчик Артём и фронтенд-разработчик Илья.
Примерно год назад мы решили попробовать ввести graphQL в свой проект и сейчас хотим поделиться, как это происходило. Расскажем, что такое GraphQL, как его внедряли, почему мы вообще решили с ним подружиться и как начать взаимодействовать с API бэкенда словно вы граф, а не холоп.
Если лень читать или больше нравится видеоформат — вам сюда.

Разбираемся на пальцах
Для начала давайте рассмотрим предметную область нашего приложения – это поможет понять, с какими проблемами мы столкнулись.
Мы разрабатываем отдельный от основного hh.ru продукт — внешнюю CRM-систему по подбору персонала Talantix. Если hh.ru, как и ряд схожих продуктов, это скорее job-борда, где кандидат создает резюме, а работодатель создает вакансию, на которую можно откликнуться, то после этого обычно в бой вступает CRM-система, где создаются интервью-встречи, кандидаты переводятся по кастомным этапам, строится аналитика работы рекрутеров и происходит прочий очень занимательный для hr флоу работы.
И чтобы подобраться к задачам, которые решает GraphQL, попробуем спроектировать API для нашей системы и заодно посмотрим, какие могут быть проблемы взаимодействия этого API с бэкендом.
Итак, мы зашли на сайт и собираемся создать встречу на интервью.
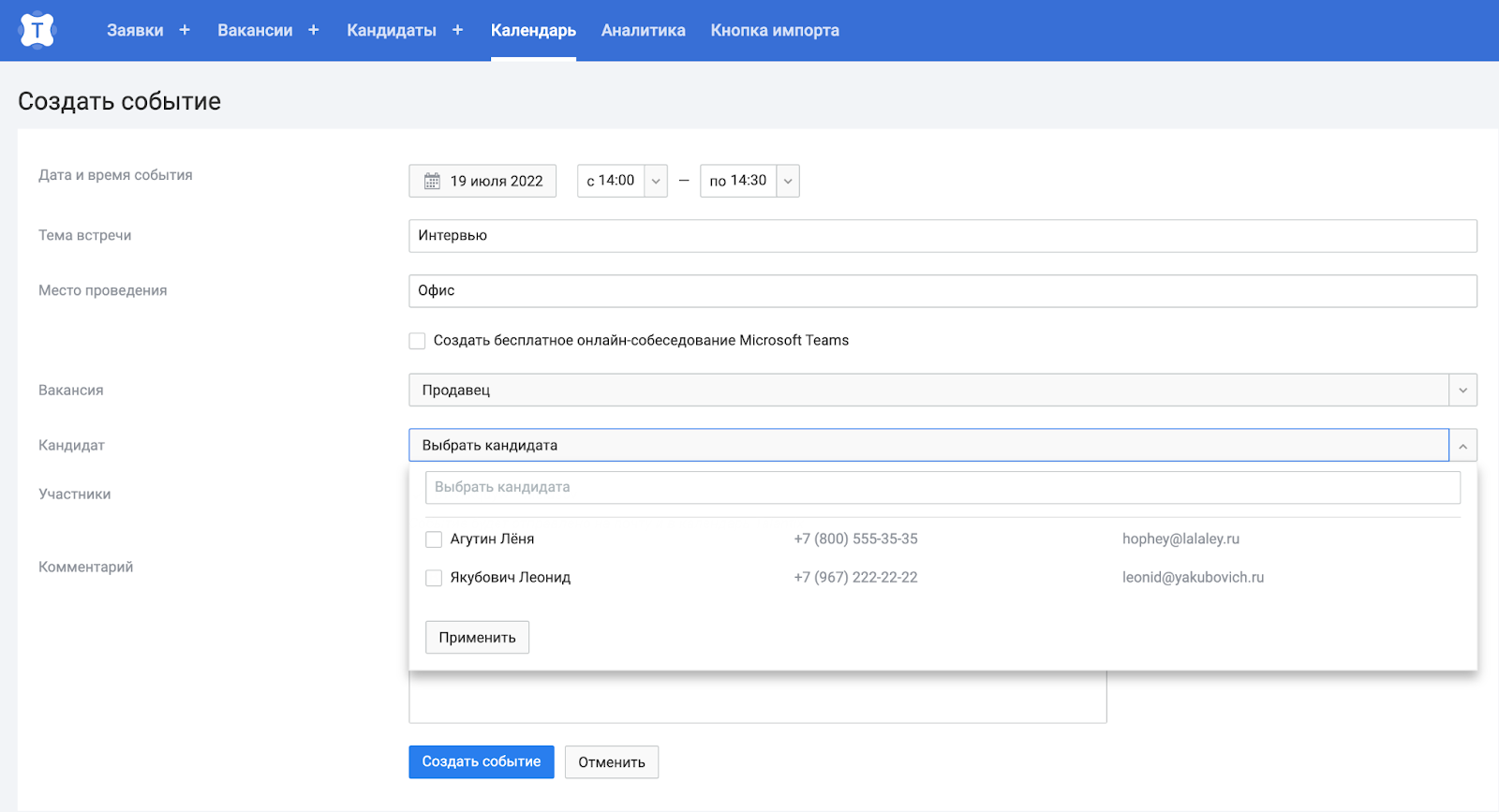
Помимо всего прочего нам понадобятся ФИО и контакты кандидатов. Сделаем стандартный по REST GET-метод /candidates , который будет возвращать необходимые данные.
GET /candidates
[
{
"id": 1,
"firstName": "Леонид",
"lastName": "Якубович",
"email": "leonid@yakubovich.ru",
"phone": "+79672222222",
"resume_id": 500
},
{
"id": 2,
"firstName": "Лёня",
"lastName": "Агутин",
"email": "hophey@lalaley.com",
"phone": "+78005553535",
"resume_id": 501
}
]Underfetching
Однако в нашей системе данные о кандидатах нужны не только на странице создания встречи. Ещё есть отдельная страница кандидатов, например, где помимо ФИО нам также понадобятся последний опыт работы и зарплата из резюме.
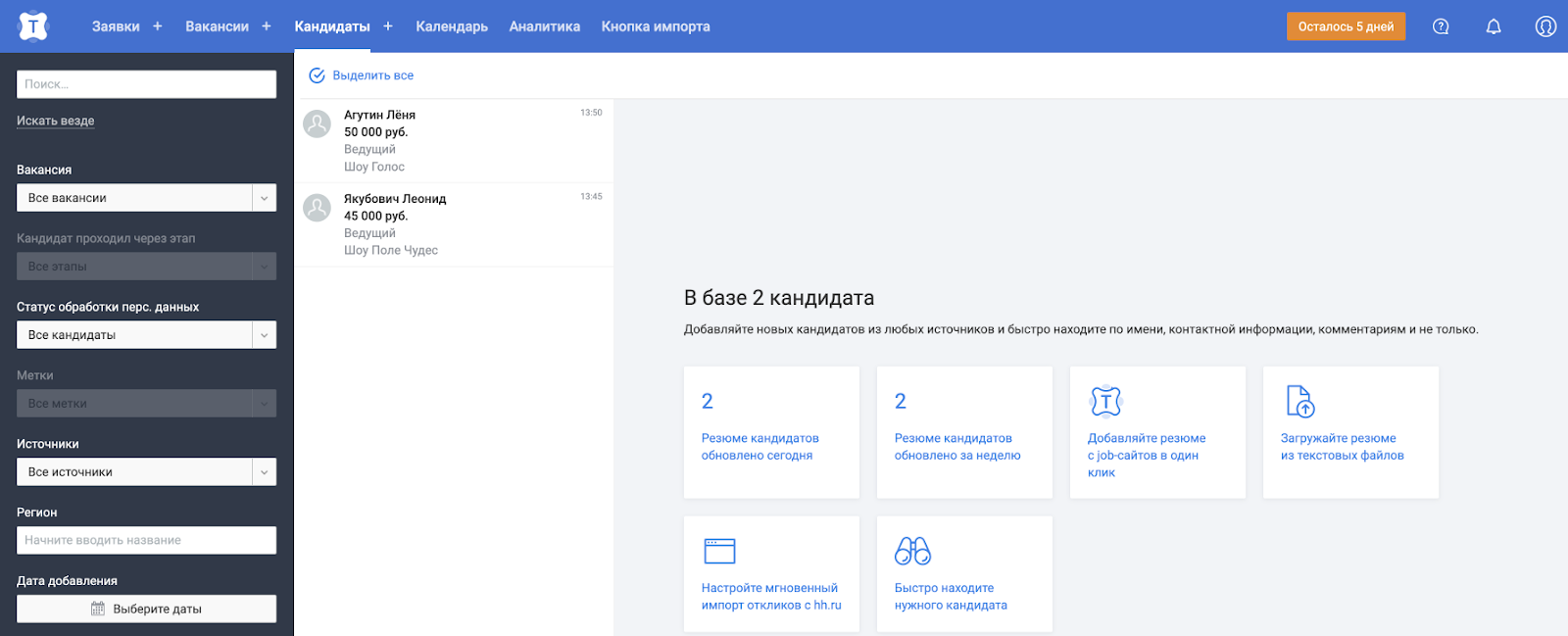
Окей, можем сделать ещё один GET-метод по REST, назовём его /resumes и по id резюме получим необходимые данные.
GET /resumes?resumeId=500&resumeId=501
[
{
"resumeId": 500,
"lastExperience": {
"company": "Поле чудес",
"position": "Ведущий"
},
"salary": {
"currency": "RUB",
"position": "45000"
}
},
{
"resumeId": 501,
"lastExperience": {
"company": "Голос",
"position": "Ведущий"
},
"salary": {
"currency": "RUB",
"position": "50000"
}
}
]Круто, но тогда появляется особенность, которая называется underfetching — мы не можем получить все данные за один запрос и ходим на бэкенд ещё раз. И это действительно иногда может стать проблемой — мы делаем несколько сетевых походов для получения данных на одной странице, не у всех пользователей может быть стабильный интернет, мы теряем в производительности.
Overfetching
Ну что же, мы можем забить на REST, создать единый метод /candidates, который будет возвращать все данные из сущностей кандидатов и резюме. Мы же знаем как и где они будут использоваться, так чего бы в один метод не напихать туда всё, что нам нужно?
GET /candidates
[
{
"id": 1,
"firstName": "Леонид",
"lastName": "Якубович",
"email": "leonid@yakubovich.ru",
"phone": "+79672222222",
"resume": {
"resumeId": 500,
"lastExperience": {
"company": "Поле чудес",
"position": "Ведущий"
},
"salary": {
"currency": "RUB",
"position": "45000"
}
}
},
{
"id": 2,
"firstName": "Лёня",
"lastName": "Агутин",
"email": "hophey@lalaley.com",
"phone": "+78005553535",
"resume": {
"resumeId": 501,
"lastExperience": {
"company": "Голос",
"position": "Ведущий"
},
"salary": {
"currency": "RUB",
"position": "50000"
}
}
}
]Не всё так просто. При создании встречи нам не нужны данные о резюме. Эта проблема тоже имеет значение, и она называется overfetching. Мы отдаём избыточные данные, которые никак не будут использоваться – снова теряем в производительности.
Завязка на страницы приложения
Можно, например, создать методы /candidates_min и /candidates_max. С точки зрения производительности всё ок, но не очень масштабируемо - а если добавится третий метод, как назовём?
Но у нас есть знание какие данные нужны конкретным страницам - можно им и воспользоваться.
Можем сделать отдельный слой на бэкенде, который будет ходить в разные микросервисы, аккумулировать данные и возвращать в соответствии с определенной страницей. Вариант хороший, но есть свои минусы. Например, на страницах с почти идентичными данными придётся дублировать логику с походами в другие сервисы и сбора информации. Да и если появится ещё одна страница со схожими данными придётся всё равно создавать новую страницу на бэкенде - занимает время разработки.
Клиент сам решает какие данные нужны
Есть ещё один вариант — оставить метод /candidates и в query-параметрах передавать только те поля, которые нам нужны.
/candidates?fetchEmail=true&fetchPhone=true&fetchResumeSalary=true…
Однако и это решение нам не полностью подходит — таких полей могут быть сотни и тысячи - сложно разобраться, сложно контролировать, сложно поддерживать. И вот тут мы плавно подходим к самой сути GraphQL.
Да кто такой этот ваш GraphQL
GraphQL позволяет декларативно на клиенте описать, какие данные ему нужны, и бэкенд вернет только их. Это значит, что клиент сам говорит, какие данные он хочет получить. Например, как в sql-запросах, когда работаем с таблицами: перечисляем нужные поля и откуда их взять. А со стороны бэкенда — это составление некой схемы, которой будут следовать запросы с клиента (опять же, аналог составления таблицы в sql), и разработка неких распознавателей, которые будут понимать, куда ходить за данными и что с ними делать. То есть на каждое поле объекта можно написать свой метод распознавателя, в котором будет содержаться его бизнес-логика.
GraphQL часто путают с базой данных или SQL, хотя мы только что убедились, что это совсем другой уровень абстракции. Более того, у нас теперь будет только один endpoint — POST-метод, который займется обслуживанием вообще всех запросов GraphQL, в отличие от того же REST. А значит, GraphQL — это стандарт языка описания запросов от клиента к бэкенду.
Реализация
Опишем краткую схему для нашего случая и заодно поймем, где граф в GraphQL.
Схема описывается на специальном языке GraphQL-схемы, и он чем-то похож на JSON. Мы описали кандидата, резюме и соединили их вместе. А вот и Graph в GraphQL — мы объявили ноды графа и соединили их.

Однако войти в этот граф пока нельзя. Поэтому опишем входные точки. В данном случае будет одна точка — candidates, например, с фильтром по id.
candidates(id: 5) {
firstName,
lastName,
phone,
email,
resumes {
lastExperience {
company,
position
},
salary {
currency,
position
}
}
}И вот почему GraphQL — это QL (query language): запрос очень похож на JSON, но на самом деле это не он. И после этого сервер возвращает нам нужны данные.
Сравним с REST
В REST:
N ресурсов;
Бэкенд решает, какие данные выдать;
Нет строго контракта, вернее, контракт на уровне согласования;
Обработка ошибок через коды ответа 4**-5**.
В GraphQL:
1 POST-ресурс;
Клиент решает, какие данные запросить;
Контракт диктуется схемой и имеет строгую типизацию;
Обработка ошибок через массив errors в теле ответа — это обусловлено тем, что graphQL не завязан на определённый протокол.
Таблица
REST |
GraphQL |
N ресурсов |
1 POST-ресурс |
Бэкенд решает, какие данные выдать |
Клиент решает, какие данные запросить |
Нет строгого контракта |
Контракт диктуется схемой |
Обработка ошибок через коды ответа |
Обработка ошибок через массив errors в теле ответа |
Из грязи в графы или как мы совершили переход
Итак, мы начали переходить на GraphQL. На самом деле стратегия была довольно простой — мы брали определённые страницы и переводили на новый формат. Поскольку мы сомневались, зайдёт ли нам GraphQL, политика была следующая: мы переводили высоконагруженные страницы со сложной логикой, чтобы сразу окунуться на всю катушку и понять, какие у нас могут быть проблемы и действительно ли помогает GraphQL.
В промежуточных стадиях у нас могут быть 2 версии однотипного кода (legacy и graphQL), пока полностью не переведём целую сущность — это нормально, если в коде сразу объявить deprecated legacy-методы и не забивать с переводом остальной функциональности. В hh.ru рекомендуется делать 30% техналога на команду и мы воспользовались этой возможностью. Также мы ставили себе технические цели в OKR, чтобы лучше мониторить прогресс.
Важное допущение — мы переводим пока что только GET-методы, хоть и graphQL позволяет изменять сущности. Это сделано только потому, что пока что перевод GET-методов для нас более актуален.
Плюсы
Мы сидим на GraphQL с осени прошлого года и продолжаем развивать этот протокол. Вот какие преимущества нам удалось обнаружить за это время:
Декларативное общение клиент-сервера и решение underfetching/overfetching проблем.
Единый API, который планируем расшарить не только для web-клиента, но и на пользователей.
Есть вероятность, что это ускорит разработку: при редизайне страницы в идеальном мире со стороны бэкенда ничего не нужно делать.
Бэкенд работает по строго типизированной схеме — и, как следствие, получаем документированное API из коробки.
Поменяли подход к проектировании задачи — теперь мы проектируем API, а не страницы.
Гарольд рад

В чем подвох
Также мы встретились и с некоторыми трудностями.
Клиент теперь сам готовит данные. Мы говорили, что это хорошо, но есть нюанс. Клиент может запросить вообще все данные в любом количестве и бэкенд тогда слегка приляжет. Поэтому нужно уметь контролировать внешние запросы. И у GraphQL есть решение — мы можем навешивать веса на определенные поля, и если сумма весов превысила заданную константу, GraphQL зареджектит этот запрос. Этот подход нормально работает, но не всегда получается сделать гибко и удобно.
Экосистема Java. Всё не так плохо, но java-мир скорее на догоняющей позиции. Обсуждение java-фреймворков мы решили вынести в отдельную статью, а видео уже можно посмотреть тут.
Построение инфраструктуры. Мониторинг, обработка ошибок, встраивание в текущую инфру — всё это реально, но во всё это нужно вкладываться. По внедрению инфраструктуры graphQL на фронтенде можно посмотреть тут.
Редиректы теперь намного сложнее
Кеширование запросов непонятно как реализовать
Ретраи — не очень понятно, что теперь идемпотентный запрос, а что нет, и какие запросы можно ретраить
Работа с неструктурированными данными — graphQL не совсем предназначен для заливки и выдачи файлов, например
Гарольд не очень рад

В общем, минусов тоже хватает, поэтому мы бы не советовали рассматривать GraphQL как следующую ступень эволюции работы с API после REST. Хотя, если вы начнёте гуглить про graphQL, то увидите пёстрые статьи о том, как он "уничтожает REST целиком и полностью". Этому не стоит верить. GraphQL — “всего лишь” альтернатива REST со своими болячками. Просто посчитайте, даёт ли он вам больше плюсов, чем минусов, оцените риски и только после этого принимайте решение — внедрять его или нет. Мы внедрили и нам понравилось.
Заключение
Вот мы и поговорили в общих чертах про GraphQL, как мы его внедряли и на какие проблемы напоролись. Эта статья — только начало весёлого цикла про GraphQL. Не переключайтесь!
Ну и пишите в комментах, пробовали ли вы подружиться с GraphQL и чем это кончилось, нам интересно.
Комментарии (18)

dimuska139
21.07.2022 10:50+5Нет строгого контракта
В случае REST можно написать или сгенерировать OpenAPI/Swagger документацию - и из неё генерить клиента для фронта
Обработка ошибок через массив errors в теле ответа
А что мешает то же самое в REST сделать? Собственно обычно ошибки валидации, например, именно так и отдаются

temaslikov Автор
21.07.2022 13:05А что мешает то же самое в REST сделать? Собственно обычно ошибки валидации, например, именно так и отдаются
Тут скорее хотелось подсветить, что REST завязан на http-протокол и активно использует коды ответа - и в ряде случаев это очень удобно, например, для мониторинга 4**/5** или понимания какой запрос можно ретраить, а какой бесполезно. GraphQL же изначально строился как protocol agnostic и на http не завязан - поэтому и ошибки будут именно в теле запроса, при том что канонически коды ответа не используются.
В случае REST можно написать или сгенерировать OpenAPI/Swagger документацию - и из неё генерить клиента для фронта
Справедливо! В случае graphQL скорее тут плюс в том, что строгость контракта максимально естетственна в силу составления схемы, единой точки правды, от которой все и пляшут, в следствие чего документация, визуализированный graphql-playground и прочие тулзы доступны из коробки.
Кстати интересно, получится ли в связке REST+OpenApi/Swagger добиться такой же строгости контракта, как и в случае с graphQL? В случае с графкл, например, у нас получилось максимально дёшево проверять контракт перед каждой сборкой и если вдруг он нарушен - гасить эту сборку. Ну и прочие очевидные плюсы типа автодополнения/линтинга/типизированности на фронтенде на основе схемы при составлении запроса
bediary
21.07.2022 11:04Проблемы высосаны из пальца, уже около 10 лет как существует стандарт JSON:API для REST, который регламенирует как делать все то же самое, что позволяет делать GraphQL


ggo
21.07.2022 11:21+1В общем, минусов тоже хватает, поэтому мы бы не советовали рассматривать GraphQL как следующую ступень эволюции работы с API после REST
Стоит добавить, что GraphQL хорош для взаимодействия человеческого фронт и бека.
Для взаимодействия бековых сервисов между собой уже не так хорош.Кеширование запросов непонятно как реализовать
На поставщиках данных. Где они и должны быть, каноническиРетраи — не очень понятно, что теперь идемпотентный запрос, а что нет, и какие запросы можно ретраить
Это для mutation, но с mutation итак много нюансов.

Z55
21.07.2022 18:54А не пробовали смотреть в сторону white-листов gql-запросов, чтобы немного снизить проблему, когда клиент может получить любые данные, в любом количестве?
temaslikov Автор
21.07.2022 20:14Мы пошли в сторону ограничения запроса по максимальной глубине и сложности (для каждого поля можно определить свою сложность в виде числа, не выполняем запрос если суммарная сложность превысила допустимую)

Sipaha
23.07.2022 11:08+1Мы пытались использовать GraphQL в качестве API, но он не подошел по ряду причин:
Обязательность схемы. Это очень сковывает и не дает динамически расширять атрибутивный состав сущностей на лету. У нас своя система типов, по которой мы можем узнать что именно можно получить из сущности, но мапить эту систему на схемы GraphQL - это боль. Мы частично смогли обойти ограничение по схеме через параметры, но это стало выглядеть очень страшно. Например, для получения полного наименования контрагента имея на руках ссылку на договор приходилось писать что-то вроде:
{att(n:"counterparty"){att(n:"fullName"){str}}}. Но даже с этим подходом снова возникла проблема - чтобы загрузить несколько атрибутов таким образом нужно обязательно указывать псевдонимы т.к. иначе в GraphQL берется имя атрибута (в нашем случае "att", который у всех атрибутов по факту один и тот же). Пришлось городить генерацию псевдонимов ("a", "b", "c", ...) перед тем как отдать движку на вычисление наш запрос.На UI работать с результатами очень не просто если нет возможности описывать там бизнес-сущности (мы разрабатываем универсальную платформу и бизнес-сущности в основном коде UI - это непозволительная роскошь). Т.е. приходилось вручную работать с большой вложенностью результатов и бесконечными проверками на null/undefined. Lodash конечно облегчал жизнь, но даже с ним было очень не просто жить с таким API. Решение этой проблемы оказалось довольно тривиальным - перед тем как отдать результат клиенту, мы для всех объектов в дереве результатов где ключ только один возвращаем значение по этому ключу вместо объекта. Т.о. объект {"counterparty": {"fullName": {"str": "ООО Рога и копыта"}}} превращался в "ООО Рога и копыта";
Как указали ранее - общение бэк <-> бэк на GraphQL довольно проблематично, а делать несколько наборов API для разных юзкейсов очень не хотелось;
К GraphQL API очень напрашивались возможности, которые свойственны template движкам. Например, отформатировать полученную дату по заданному шаблону. Вернуть значение по умолчанию если атрибут вычислился в null (и много других). Стандарт этого сделать не позволяет;
Отношение к сущностям и их идентификаторам в GraphQL очень поверхностное. Нам дают возможность добавлять параметры для атрибутов в query, но то что в них передается - это все уже забота разработчика и никаких оптимизаций от движка особо ждать не приходится. Наша попытка сделать универсальный атрибут для запросов любых сущностей из любых источников данных закончилась довольно грустно. Очень не хватало возможности вернуть из атрибута некоторую ссылку на другую сущность и дать движку уже самому решать как и что на основе этой ссылки загружать;
Сложность. Все таки вся эта задумка с параметрами по факту нужна для одних и тех же целей - получение объекта по ID или поиск записей по другим критериям. Эти два сценария можно было бы сделать полноценной частью API с соответствующими оптимизациями от движка, но что имеем, то имеем;
Оптимизация. Реализация на java при загрузке {a: abc{def}, b: abc{hig}} по факту загружала "abc" дважды. Зачем дважды грузить одно и то же в readOnly запросе? Вопрос для знатоков.
Но справедливости ради в GraphQL API есть очень весомые плюсы:
Клиент точно знает тип результатов, которые он получит из запроса;
Нет underfetching/overfetching проблем (как в этой статье и описывается);
В итоге мы реализовали свое API с теми же плюсами, но без минусов, которые описаны выше. Для той же задачи загрузки плного имени контрагента мы имеем:
API.get(contract_ref).load("counterparty.fullName?str!'unknown'")а на выходе или 'unknown' или 'ООО "Рога и копыта"'
Для поиска записей:
API.query({"sourceId": "contracts"}, "counterparty.fullName?str!'unknown'")и получаем уже массив из имен контрагентов для всех контрактов
nin-jin
А теперь представьте, что надо выводить для каждого кандидата данные о городе проживания (название, страна, средняя зарплата и тд). Сколько раз данные о Москве будут продублированы при запросе через GQL?
А в контракте, который диктуется схемой, уже можно убирать опциональность полей, и различать отсутствие данных от их стирания?
Virviil
А как задача с недублированием данных о городе решалась бы в REST подходе?
aceofspades88
как вам захочется
bokshi
Например, можно вот так:
Virviil
Для graphql есть некоторые решения которые делают подобное, например вот здесь: https://gajus.medium.com/reducing-graphql-response-size-by-a-lot-ff5ba9dcb60
nin-jin
Это же лютые костыли:
На сервере получили из базы нормализованные данные.
Денормализовали их для GQL выдачи.
Натравили дедубликатор, получив свой, не GQL формат.
Отослали клиенту.
На клиенте натравили дубликатор для получения GQL ответа.
Обработали таки GQL.
А клиенту эта денормализация не упёрлась - он нормализует всё обратно.
Итого, в этой схеме 2 лишних звена:
GQL
Денормализация
Virviil
Не надо денормализовывать для GQL и натравливать дедубликатор - сервер то твой целиком, зачем делать лишние шаги - тебя никто не заставляет. Если у тебя отдельный черный ящик, который не знает о том, что ты используешь такой подход - тогда эти шаги нужны.
Денормализует клиент и в случае с REST. Тут никакой разницы нету. Чтобы в UI отобразить. То есть "клиенту денормализация не уперлась" - я не могу себе представить такого кейса. Наоброт, в конце-концов клиенту нужна денормализцаия для отрисовки UI.
nin-jin
Скорее как-то так:
Что тут клиент будет нормализовывать - ума не приложу.
nin-jin
При нормализованной выдаче она вообще не возникает.
temaslikov Автор
Хорошие вопросы! На первый ответили комментарием ниже про graphql compressing, а по второму:
Чуть проспойлерю - буквально вчера у коллеги были съёмки нового эпизода оххнных историй как мы столкнулись с этой проблемой и как её фиксили :)
Так что про эту проблему будет отдельная статья, но да, отсутствие данных можно различить от их недоступности - разруливается на уровне контракта.
Вкратце мы это фиксили так: если сущности нет или она недоступна возвращаем объект типа CandidateError с конкретизацией, что именно не так. При этом сам Candidate - это union от CandidateItem и CandidateError (то есть для конкретного кандидата возвратится либо CandidateItem , либо CandidateError), которые можно различить по __typename. Этот подход нам помог различить 2 состояния.
Также мы столкнулись и с другой проблемой - одна часть данных одной и той же сущности доступна, другая нет (например, ФИО можем отдать для определённой роли в системе, а контакты не хотим). Но здесь подход концептуально не поменялся - объявляем интерфейс Candidate и от него наследуем CandidateFullItem и CandidatePublicItem (второй без контактов) - и в зависимости от роли отдаём данные кандидата определённого типа, как написал выше