
Часто Java-разработчикам требуется реализовать запланированные задания. Современные реалии диктуют нам, что система должна быть масштабируемой, то есть вне зависимости от количества реплик и распределения нагрузки мы ожидаем выполнения задания по условиям, которые были определены на входе. Существуют подключаемые библиотеки для реализации jobService. Используя базу данных, можно написать свой jobService, c одной стороны, вероятность ошибки больше, чем с готовым решением, но с другой стороны – в своем коде разбираться и вносить правки проще, чем в общедоступной библиотеке. Кроме того, собственная реализация будет учитывать особенности системы, в нашем случае, это реактивность. В статье подробнее описаны плюсы и минусы этих подходов.
Я поддерживаю проект, который был написан в микросервисной, реактивной парадигме (spring-boot-starter-data-r2dbc, spring-boot-starter-webflux, r2dbc-postgresql). Основной сервис этого проекта осуществляет взаимодействие с базой данных в реактивном подходе, реализует взаимодействие с другими сервисами через Rest и Kafka. Кроме этого, он содержит 3 запланированных задания с кастомной реализацией: 2 по переотправке сообщений и 1 по очистке таблицы.
Используя кастомную реализацию (описание в п.1), мы столкнулись с проблемой, что после завершения работы пода (приложение развернуто в двух экземплярах на Open Shift), в котором задание было запущено, но не выполнено, оно оставалось в статусе выполняется и так и не перезапускалось, другими словами job завис. Эту проблему решили проверкой последнего времени обновления задания, в случае если видно, что job уже слишком долго в статусе выполняется, он перезапускается.
Это решение помогло, однако возник вопрос, можно ли использовать вместо этого
сервиса готовое решение для запланированных заданий. Решение о том, что
использовать при проектировании принималось не нашей командой, мы занимаемся
поддержкой разработанного решения, но я решила исследовать возможные
альтернативы и сравнить их.
1. Кастомная реализация
Сначала рассмотрим самую легковесную и простую для понимания реализацию, в которой мы не прибегаем к дополнительным зависимостям, вся логика прописана в самом приложении в имплементации JobService. Задания хранятся в базе данных в таблице jobs, структуру, которой можно видеть на схеме ниже.
С помощью аннотаций EnableScheduling, Scheduled, установленных в трех соответствующих сервисах и собственной реализации JobService эти задания запускаются через фиксированное время.
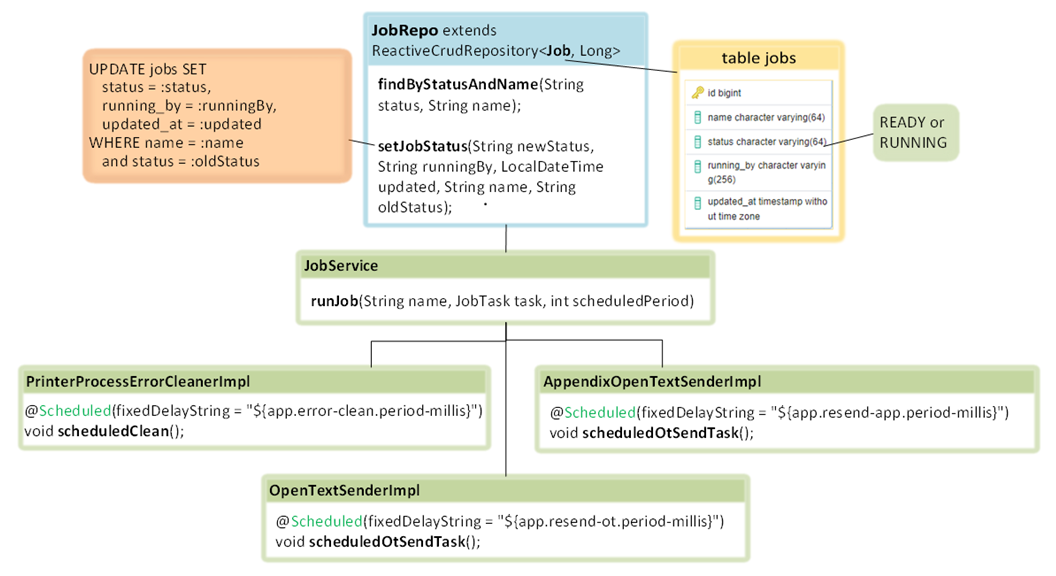
Доступ к таблице с заданиями осуществляется через репозиторий, который унаследован от org.springframework.data.repository.reactive.ReactiveCrudRepository<Job, Long>.

Класс Job имеет соответствующие поля из таблицы jobs. У задания есть только два статуса готово к выполнению и выполняется. Обновление происходит с помощью запроса UPDATE jobs SET status = :status, running_by = :runningBy, updated_at = :updated WHERE name = :name and status = :oldStatus. То есть если один экземпляр приложения начнет обновлять статус job, другой экземпляр эту запись не сможет изменить, этим достигается гарантия того, что job будет выполнен 1 раз при двух репликах приложения.
2. Quartz
Библиотека Quartz существует давно (есть статья на habr от 2013 года, а последний релиз был в 2019, баги правятся и сейчас) и в интернете полно примеров, как ее настраивать, а под этими примерами вопросы так ли нужно использовать эту библиотеку, если она порождает 11 таблиц и так сложна в настройке https://habr.com/ru/company/otus/blog/475996/). Однако Quartz не только может быть встроен в существующее приложение, но и может работать как отдельная программа (внутри собственной виртуальной машины Java), которую можно использовать через RMI.
Проанализировав несколько примеров (статью из предыдущего абзаца и этот пример), я добавила эту библиотеку себе в реактивное приложение. Для наших трех запланированных заданий понадобится 3 сервиса, которые имплементят org.quartz.Job. Далее необходим класс AutowiringSpringBeanJobFactory, используемый в бине SpringBeanJobFactory, который позволяет задать всю информацию о планируемых заданиях, настройки SchedulerFactoryBean во время создания инстанса. Бинами в конфигурации были созданы такие классы как DataSource, JobDetail[], Trigger[], SchedulerFactoryBean.
После запуска приложений в моей бд было создано 11 таблиц. Давайте разберемся, зачем так много, если для кастомной реализации этих заданий удалось обойтись одной.
qrtz_triggers —общая информация о триггере, имя описание, статус, временные метки;
qrtz_simple_triggers, qrtz_simprop_triggers, qrtz_crons_triggers, qrtz_blob_triggers имеют отношение внешнего ключа к qrtz_triggers, здесь хранятся подробности для каждого вида триггеров. Вот только не очень понятно, если у меня в приложении 3 одинаковых вида заданий, зачем мне хранить пустые таблицы для видов, которые я не использую? Конечно, возможность создавать кастомизированные триггеры очень интересна, но в следующей библиотеке для этого не понадобилось так засорять базу данных;
qrtz_job_details — здесь прописан сервис, который относится к конкретному job;
qrtz_fired_triggers — это журнал всех сработавших триггеров;
qrtz_paused — предназначен для сохранения информации о неактивных триггерах;
qrtz_calendars — полезны для исключения блоков времени из расписания срабатывания триггера. Например, вы можете создать триггер, запускающий задание каждый будний день в 10:30, а затем добавить календарь, исключающий все праздники компании;
qrtz_lock — значение имени экземпляра, выполняющего задание, чтобы избежать сценария, когда несколько узлов выполняют одно и то же задание;
qrtz_scheduler_state — предназначен для захвата состояния узла, поэтому, если в любом случае один узел выходит из строя или не может выполнить одно из заданий, другой экземпляр, работающий в режиме кластеризации, может выбрать задание, в котором произошла ошибка.
Quartz подойдет для приложений, которые специализируются на планировании заданий, которые выполняются долго и являются ресурсоемкими, тогда Quartz занимается распределением нагрузки по нескольким узлам, так же он подойдет, когда надо учитывать гибкие настройки типа исключения праздничных дней. Но в нашем приложении задания достаточно простые и выполняются быстро через фиксированный промежуток времени. Очевидно, если разработчик обращается к дополнительной библиотеке, скорее всего, у него заданий много и это часть основного функционала приложения. Я нашла интересный блог о том, как запускать много маленьких заданий в Quartz.
Касательно гарантии, что планировщик выполняет задание один раз, Quartz резервирует с помощью SELECT ... FOR UPDATE (само выражение можно менять через настройку selectWithLockSQL) определенное количество триггеров для исполнения, выполняет их, а потом снимает блокировку, подобное решение используется и в следующей библиотеке.
3. kagkarlsson.db-scheduler
В поисках более легковесной библиотеки я нашла этот вопрос, в котором один из авторов kagkarlsson/db-scheduler предлагает свое решение, которое понравилось мне намного больше, за исключением того, что название труднопроизносимо.
Для добавления в проект этой библиотеки понадобился только бины DataSource, 3 бина RecurringTask<Void> для каждого задания. В базе появилась только одна таблица scheduled_tasks, ее пришлось добавить через миграцию, в нашем случае liquibase. Процесс создания разных видов заданий описан в GitHub библиотеки, там же скрипты для создания таблицы и примеры приложений.
Планировщик использует две возможные стратегии, которые можно задать настройкой polling strategy: оптимистическую блокировку(fetch-and-lock-on-execute) или select-for-update(lock-and-fetch) (когда забираем данные для обновления, они заблокированы для изменения другими транзакциями, на данный момент стратегия доступна для postgres, нам это подходит).
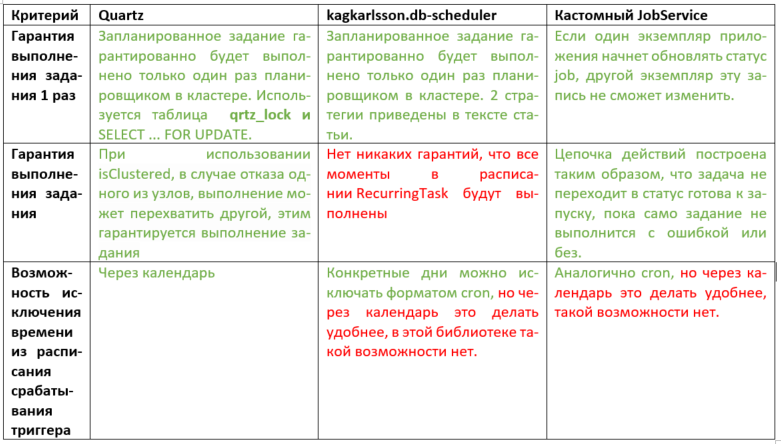
Чтобы облегчить процесс сравнения, я составила таблицу, в котором цветом выделила недостатки и достоинства всех трех подходов. Если красным отмечена только половина строки, при подведении итога, это считается на половину достоинством, наполовину недостатком. Прошу учесть, что критерии сравнения применимы к нашему конкретному случаю, несмотря на это таблица содержит общую полезную информацию консолидировано.


Выводы
Учитывая, что в нашем конкретном случае настройка календарей, высокая пропускная способность, кастомная настройка заданий не нужны, мы остаемся с собственной реализацией JobService. Чтобы следить за тем, что задания выполняются корректно, мною были настроены метрики, по которым я могу отслеживать зависания и в случае проблем я могу легко вносить правки в существующую таблицу для заданий и в код взаимодействия с ней.
Важным аспектом является реактивность: реактивная система должна оставаться реактивной во всех взаимодействиях (реактивный манифест) тем более, что действия, выполняемые нашими заданиями, так же выполняются реактивными сервисами. Но я надеюсь, информация этой статьи будет полезна другим разработчикам при выборе реализации запланированных заданий.