
Выбор платформы для работы с Computer Vision on the Edge - непростая задача. На рынке десятки плат. Если почитать про любую их них - так и хочется её использовать. Но на практике все оказывается не так хорошо.
Я попробовал сравнить дешевые платы которые есть на рынке. И сделал это не только в по скорости. Я попробовал сравнить платформы по “удобству” их использования. Насколько просто будет портировать сети, насколько хорошая поддержка. И насколько просто работать. И актуализировал это для 2022 года.

Оригинал статьи я опубликовал пару дней назад на Medium. С тех пор пофиксил пару ошибок (например пофиксил некоторые цены). Эта статья - результат сравнения (таблица тут). Но если вы хотите посмотреть подробнее на платы, про каждую из них есть своё видео (каждая плата уникальна и в таблице её можно поместить с некоторыми натяжками):
ESP32 — (Видео было не для этого гайда, но я делал незадолго до первого видео и там есть ответы почти на все вопросы. А вот тут пример использования — https://youtu.be/ms6uoZr-4dc )
Myriad X (NCS 2, Depth Ai (OAK,OAK-1,OAK-D,e.t.c.))
Rock Pi 3A (RK3568, e.t.c.)(пример использования в отдельном видео — https://youtu.be/NHVPxPlY2lI )
Я надеюсь что это не все и я буду дополнять эту статью. На текущий момент у меня есть:
Про них я тоже делал небольшое видео и сравнение. Но там я не сделал полноценного описания каждой платформы, так что их нет в текущем гайде пока.
Так же, мне обещали дать потестить Halo-8, но пока руки не дошли. Говорят там очень много производительности. И сейчас заказал m5stack (Sigmstar SSD202D проц).
Плюс у меня есть список который я планирую рано или поздно заказать и потестить и добавить в эту статью или следующие:
DEBIX Model A — Как я понимаю там NPU такой же как и в VIM3, но есть ощущение что с разных процессоров оно может по разному работать
K510 Dual RSIC-V64 — Обновленная версия k210, как я понимаю производительность разогнана в 3 раза + есть сильно больше памяти
Horizon X3 Pi AI Board — плата с большим комюнити и нацеленная скорее на ROS. Но имеется некоторый аналог NPU на борту, что делает платформу интересной для тестирования.
VisionFive RISC-V — Плата на которой есть два ускорителя (NVDLA Engine и NPU). Когда 3 месяца назад я думал её заказать меня остановило что на официальном форуме было несколько топиков по которым было понятно что пока что нельзя запустить ни один из них (NNE not working https://forum.rvspace.org/t/nvdla-engine-vs-neural-network-engine/174 NVDLA not working https://forum.rvspace.org/t/nvdla/170 ). Мне кажется ничего не изменилось пока.
Orange Pi 5 — По сути это Rockchip RK3588S. Но Orange Pi имеет свою достаточно развитую инфраструктуру, интересно было бы сравнить с Rock Pi. Но, скорее всего, все будет похоже. Так же интересно потестить Orange 4B, что аналогично .
Про RockChip, интересно было бы потестировать что-то на базе RK1808. Есть много дешевых плат (например такое - https://wiki.pine64.org/wiki/SOEdge ). А что-то есть даже с камерами.
KNEO STEM — NPU модуль на который нет никаких обзоров.
Sophon BM1880 — так же, интересная плата без особых обзоров.
Xilinx Kria — FPGA плата. Все хочется собраться с силами и потестить. Когда я в прошлый раз пробовал переносить математику на FPGA - я был опечален. Но говорят все стало лучше...
Я знаю что есть ещё Beaglebone и JeVois. Но мне они показались несколько устаревшими. Так же пока у меня не хватает сил чтобы тестировать платы без полноценной системы, такие как Arduino Portenta H7, Sony Spresense, Nordic Semi, Pi RP2040, и.т.д. Так что их тут не будет:)
Поехали!
Итоговая таблица с результатами : ссылка на таблицу.
Но сначала хочется объяснить использованные мной критерии:
"How easy to work" - простота работы
How easy is it to flash? Когда-то давно я работал с Jetson TK1. Чтобы его засетапить требовалось потратить пол дня-день. А для RPi4 - надо всего пол часа.
Easy to work with. Когда-то давным-давно мы работали с DaVinchi. И чтобы его отдебагить требовались какие-то магические пасы с перетыканием кучи разъемов. Сейчас это уже не так, почти для всех плат. Но остались и другие сложности. Насколько просто установить библиотеки, насколько адекватные доки, и.т.д., и.т.п.
Conventional Linux. Не всегда на платах обычный линукс под которым работает pip install или apt-get. Впечатление о адекватности системы.
Community support. Чем больше сообщество - тем проще найти в решенных проблемах вашу. Тем больше будет семплов работы с платой и рассказов о её функциональности.
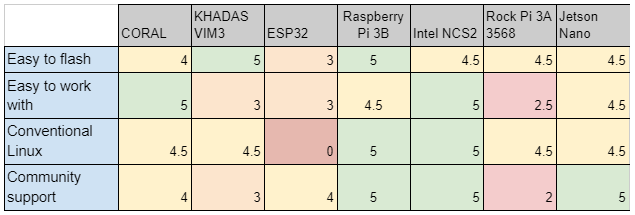
В плане простоты работы вперед вырываются RPi и NCS2. Но надо понимать что это не полноценные Computer Vision платы.
Models support - поддержка моделей
Конвертация моделей - известная всем боль. И если в OpenVino достаточно просто все экспортировать, то на какой-нибудь Rock Pi экспорт произвольной модели может доставить много боли. Официально поддерживаемые модели частично упрощают этот процесс. Тут я привожу несколько характеристик которые на мой взгляд важны.
Oficial Models Zoo. Официальный парк моделей.
Unofficial Models Zoo. Часть модели идут не от производителей платы а от комьюнити (например от сторонних проектов которые поддерживают плату).
How easy is it to convert the random model? Насколько просто сконвертировать произвольную модель.
Easy to debug problems with the conversion. И насколько просто будет отладить проблемы если что-то пойдет не так.

Видно что есть три платы несколько впереди и ещё 1-2 догоняющих.
Насколько плата продуктовая
Кроме того что все запрогать и настроить - обычно нужно собрать продукт на базе выбранной платы. Моя текущая специализация далека от разработки плат. Но какие-то базовые вещи + насколько плата подходит для хобби попробовал отметить.
Processor speed? Для многих задач Computer Vision, да и не только, кроме мощного NPU или GPU нужен процессор. Я сделал несколько простых тестов чтобы оценить условные попугаи и сравнить производительность процессора. По хорошему, это надо смотреть в видео которые я приводил в начале, так как для многих плат процессор будет подвязан на другой функционал. Например в Jetson большой кусок предпроцессинга и постпроцессинга видео может взять на себя GPU. А у RaspberryPI на процессоре надо крутить сетки. И производительность просядет.
Mechanical parts, насколько разумно сделаны разъемы, насколько мало движущихся частей, насколько плата стабильна по температуре.
Easy to buy. Насколько плату просто купить. Тут обратите внимание на даты выпуска видео. Ибо рынок вещь переменчивая. На начало лета RPi был почти в 2 раза дешевле.
Pins for external connection. Есть ли пины чтобы подключать произвольную периферию.
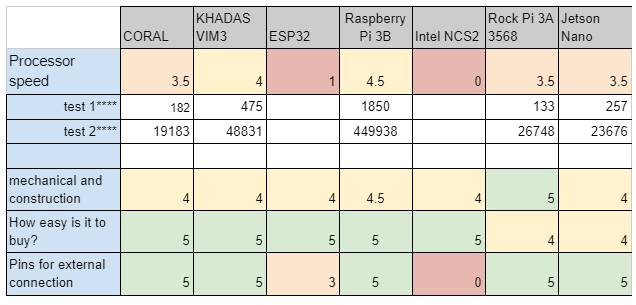
Как вы видите все платы похожи. И разница обычно в небольших мелочах. Но где-то эти мелочи могут быть существенны.
Speed Test
Самая интересная и самая загадочная часть. Если кому-то кажется что измерив производительность 2-3 сеток можно сказать насколько плата быстра - он заблуждается. По каждой конкретной сетке надо независимо бенчмаркать и результат будет неожиданный. Но я попробовал сделать несколько важных измерений:
Насколько плата быстра на маленьких сетках (это метрика того насколько память далека от вычислительного модуля).
Насколько плата быстра на больших сетках (это метрика того насколько быстр вычислительный модуль).
Какой из фреймворков лучше использовать.
Мои бенчмарки не показывают какие слои где лучше реализованы (это может быстро меняться). И я замеряю все для batch size =1. Это может значительно ухудшить результаты по тому же Jetson. Но так проще.

Главный вывод который я для себя сделал (который и так подсознательно знал). Нет "плохих" плат. Они просто для разного.
Price
Понятно что без цены все что я рассказываю бессмысленно. Имея неограниченный бюджет можно поставить 3090Ti и оно побьет все вышесказанное. Но с оценкой цены есть сложности:
Нехватка чипов. Джетсон стоил 99 а сейчас 250. RPi ещё весной был в каталогах по ~50, а сейчас 150
Большая партия дешевле маленькой
У некоторых чипов отладочная плата стоит в разы дороже чем если сделать продуктовую (а с Jetson Nano наоборот).
Дополнительная периферия может значительно изменить цену. А периферия может быть разной.
Но базовые цены я выписал тут:

Подвальчик
Интересна тема? Советую почитать немного больше и про то как архитектурно это все устроено и сравнения от других авторов. Вот небольшая подборочка:
Хорошая статья что такое NPU, TPU, чем они отличаются и как оптимизируется математика.
Неплохая статья на тему сравнения платформ. Тут есть платформы не рассмотренные у меня + примеры для сетей которых у меня нет.
Не очень подробное сравнение, но тоже есть несколько интересных платформ которых нет у меня.
И прочее
Если интересно - я ещё буду выпускать видео на эту тему у себя на канале. И следить за ними проще всего: на youtube, блог в телеге, блок VK, дока в Google Doc, Linkedin. Плюс, возможно, обновлю эту статью.
Комментарии (12)

sentimentaltrooper
15.09.2022 22:57+1О как вы удачно зашли! Мне как раз отчет писать на тему почему у нас на Raspberry pi4 (кстати а почему не попала в обзор?) и Jetson Nano крутится 99% проектов и когда уже можно заполучить Compute Module 4. Оставшийся 1% это https://www.ti.com/tool/SK-TDA4VM - по производительности очень нравится: можно прям на 30 FPS пару потоков в Yolo (MobileNet, ResNet) гонять. Но только тех что одобрены TI ибо с поддержкой и документацией так себе.

ZlodeiBaal Автор
15.09.2022 23:47-1У меня Rpi4 погоревший лежал, и по знакомым свободного не было. Но там это не очень критично. Когда я что-то измерял на нем, то там в 4-5 раз быстрее были одни модели и примерно раз в 8-9 другие (чем на RPi3). Я это в видео упомянул.
А удобство там идентично с RPi3, все те же плюсы и минусы.

buldo
16.09.2022 00:55+1Возможно у вас есть какая-то информация по latency камер и энкоделов на этих платах?
Для fpv полетов разыскиваю комп с минимальными задержками.
ZlodeiBaal Автор
16.09.2022 01:14-1Мне кажется что latency камер это больше про протокол по которому получаются данные. А дальше все одно и то же и зависит от одних и тех же проблем. А протоколы — на большинстве csi шина стоит.
Но я никогда не измерял это сам.

le2
16.09.2022 16:13копаю в этой области. Ситуация довольная грустная для неофициальной разработки.
Потому что матрица подключается через шину камеры не напрямую, а через ISP (Image Signal Processor). Это процессор, который аппаратно вычисляет гистограмму, управляет автофокусом и занимается прочими улучшениями картинки. Документации на подобные вещи в открытом доступе нет, а без этого минимальной задержки не выйдет.
Распберри пишет открытый драйвер к камерам, но это в обход ISP, коим является видеоядро в RP4.
На матрицы также открытой документации нет...
Не говоря о том что ваши задержки будут складываться еще от задержек радиочасти...
Энкодеры? В RP - i2c, SPI заведены через закрытое видеоядро. У других прикладных процессоров также висят на DMA и все это хозяйство рулится через нерилтаймовый Линукс...
Короче, без официальной поддержки блестящий коммерческий продукт сделать очень проблематично.

jershell
16.09.2022 18:05Про visionfive. Спросил что там с поддержкой, ответили что все ресурсы уходят на visionfive v2. Зато в каждом их рекламном буклете пишут про наличие акселератора.
le2
не умаляя вашей работы, хотелось бы посмотреть на инференс на GPU RK3568 и на NEON возможно, в этом случае у rockchip не останется минусов?
В текущей ситуации, для России, продуктовым является только Rockchip...
ZlodeiBaal Автор
Ну… NPU обычно побыстрее. Причем сильно. Плюс NPU энергоэффективнее и не грузят процессор для других задач.
На базе Amlogic много чего есть. И там внутри Tim-VX NPU который я внутри большого числа китайских чипов видел.
В целом, в том списке что я не потестил есть много плат которые доступны в РФ.
le2
а вы уверены что быстрее? Я не троллю, по моим поверхностным тестам NPU это не быстрее, а энергоэффективнее. К тому же редкие задачи зрения обходятся без работы с преобразованиями изображений на GPU. Гонять данные из RAM в GPU-RAM и обратно это не всегда эффективно.
Да, для маленьких нейронок типа mobilenet, внезапно многоядерный CPU c XNNPACK быстрее GPU. Без учета того что мы нагружаем CPU.
ZlodeiBaal Автор
Для плат одинакового качества это обычно быстрее. Но да, можно с RTX3090 сравнить, и та будет быстрее;)
За одинаковую цену NPU по опыту быстрее. Тут важный момент, что это для Edge плат. Для Android через TFlite может быть и иначе. Но TFlite очень много съедает сам. Например для Qualcomm мы как-то тестили что нативный фреймворк в 3 раза быстрее чем TFlite.
Для Edge плат почти всегда используются именно нативные фреймворки.