
Автор статьи: Фред Эрсам - соучредитель компании Coinbase. Он был включен в списки Forbes 30 (до 30 лет) и TIME Magazine 30. Ранее он работал валютным трейдером в Goldman Sachs в Нью-Йорке, где занимался торговлей и управлял электронной платформой Goldman.
Фред прогнозировал переход Ethereum с PoW на PoS на 2018/2019 годы. Как мы видим, он ошибся в прогнозе на 3-4 года. Данная статья также была написана в начале 2018 года и нам кажется, что именно сегодня имеет смысл прочитать и осмыслить её ещё раз.
Модели машинного обучения, натренированные на данных с торговых площадок на основе блокчейна, способны создать самый мощный в мире искусственный интеллект. Они объединяют два мощных примитива: частное машинное обучение, которое позволяет проводить обучение на конфиденциальных частных данных, не раскрывая их, и стимулы на основе блокчейна, которые позволяют этим системам привлекать лучшие данные и модели, чтобы сделать их умнее. В результате получаются открытые рынки, где любой может продать свои данные и сохранить их конфиденциальность, а разработчики могут использовать стимулы, чтобы привлечь к себе лучшие данные для своих алгоритмов.
Создание таких систем является сложной задачей и необходимые технологии для этого все еще создаются, но простые начальные версии выглядят так, будто они начинают становиться возможными. Я считаю, что эти рынки переведут нас из нынешней эпохи монополий на данные в Web 2.0 в эпоху Web 3.0 - эпоху открытой конкуренции за данные и алгоритмы, где и те и другие будут напрямую монетизироваться.
Основой для этой идеи послужил разговор с Ричардом из Numerai в 2015 году. Numerai - это хедж-фонд, который отправляет зашифрованные рыночные данные любому специалисту, желающему принять участие в соревновании по моделированию фондового рынка. Numerai объединяет лучшие модели в "метамодель", торгует этой метамоделью и платит ученым, чьи модели показали хорошие результаты.
Соревнование ученых, работающих с данными, кажется мощной идеей. Это заставило меня задуматься: можно ли создать полностью децентрализованную версию этой системы, которую можно было бы распространить на любую проблему? Я считаю, что ответ, да.
Разработка
В качестве примера давайте попробуем создать полностью децентрализованную систему для торговли криптовалютами на децентрализованных биржах. Это одна из многих потенциальных конструкций:
Данные
Провайдеры данных накапливают данные и предоставляют их моделистам.
Построение моделей
Разработчики моделей выбирают, какие данные использовать и создают модели. Обучение проводится с использованием метода безопасных вычислений, который позволяет обучать модели без раскрытия исходных данных для обучения.
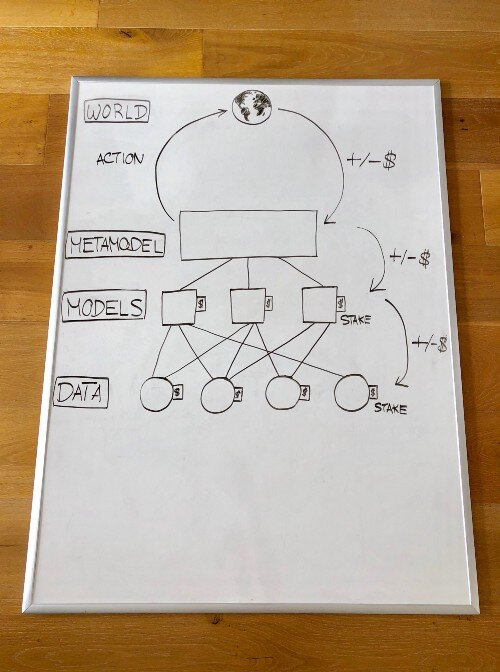
Построение метамодели
Метамодель создается на основе алгоритма, который учитывает ставку каждой модели. Создание метамодели необязательно - вы можете представить модели, которые используются без объединения в метамодель.
Использование метамодели
Смарт-контракт берет метамодель и осуществляет программную торговлю через децентрализованные механизмы обмена на блокчейн.
Распределение прибыли/убытков
По прошествии некоторого периода времени торговля приносит прибыль или убыток. Эта прибыль или убыток распределяется между участниками метамодели в зависимости от того, насколько они стали умнее. Модели, которые внесли отрицательный вклад, забирают часть или все свои средства, поставленные на кон. Затем модели разворачиваются и производят аналогичное распределение/уменьшение ставок среди своих поставщиков данных.
Верифицируемые вычисления
Вычисления для каждого шага выполняются либо централизованно, но верифицируются и оспариваются с помощью верификационной игры, такой как Truebit, либо децентрализованно с использованием безопасных многопользовательских вычислений.
Хостинг
Данные и модели размещаются либо на IPFS, либо на узлах в безопасной сети многопользовательских вычислений, так как хранение на блокчейн будет слишком дорогим.
Что делает эту систему мощной?
Стимулы для привлечения лучших данных по всему миру
Стимулы для привлечения данных являются наиболее мощной частью системы, поскольку данные, как правило, являются ограничивающим фактором для большинства кейсов машинного обучения. Точно так же, как биткойн создал уникальную систему с самыми большими вычислительными мощностями в мире благодаря открытым стимулам, правильно разработанная структура стимулов для данных приведет к тому, что лучшие данные в мире для вашего приложения придут к вам. И практически невозможно отключить систему, в которую данные поступают из тысяч или миллионов источников.
Конкуренция между алгоритмами
Создается открытая конкуренция между моделями/алгоритмами там, где ее раньше не было. Представьте себе децентрализованный Facebook с тысячами конкурирующих алгоритмов новостной ленты.
Прозрачность вознаграждений
Поставщики данных и моделей могут видеть, что они получают справедливую стоимость того, что они предоставили, поскольку все вычисления проверяются, что повышает вероятность их участия.
Автоматизация
Выполнение действий на блокчейн и получение стоимости непосредственно в токенах создает автоматизированный и беспристрастный замкнутый цикл.
Сетевые эффекты
Сетевые эффекты от пользователей, поставщиков данных и ученых, работающих с данными, делают систему самоподдерживающейся. Чем лучше она работает, тем больше капитала она привлекает, что означает больше потенциальных выплат, что привлекает больше поставщиков данных и ученых, которые делают систему умнее, что, в свою очередь привлекает больше капитала, и так по кругу.
Конфиденциальность
В дополнение к вышеперечисленным пунктам, важной особенностью является конфиденциальность. Она позволяет:
людям предоставлять данные, которые в противном случае были бы слишком приватными для обмена, и
предотвращает утечку экономической ценности данных и моделей.
Если оставить данные и модели незашифрованными в открытом доступе, они будут бесплатно скопированы и использованы другими людьми, которые не внесли никакого вклада (проблема "свободного наездника").
Частичным решением проблемы "свободного наездника" является частная продажа данных. Даже если покупатели решат перепродать или выпустить данные, их ценность со временем снижается. Однако этот подход ограничивает нас кратковременными случаями использования и по-прежнему создает типичные проблемы конфиденциальности. В результате, более сложный, но мощный подход заключается в использовании формы безопасных вычислений.
Безопасные вычисления
Методы безопасных вычислений позволяют моделям обучаться на данных без раскрытия самих данных. Сегодня используются и исследуются 3 основные формы безопасных вычислений: гомоморфное шифрование (HE), безопасные многопользовательские вычисления (MPC) и доказательства нулевым разглашением (ZKP). В настоящее время многопользовательские вычисления чаще всего используются для частного машинного обучения, поскольку гомоморфное шифрование слишком медленно, а применение ZKPs к машинному обучению не очевидно. Методы безопасных вычислений находятся на переднем крае исследований в области компьютерных наук. Они часто на порядки медленнее обычных вычислений и представляют собой основное узкое место в системе, но в последние годы ситуация улучшается.
Уникальная рекомендательная система
Чтобы проиллюстрировать потенциал частного машинного обучения, представьте себе приложение под названием "The Ultimate Recommender System". Оно следит за всем, что вы делаете на своих устройствах: история просмотров, все, что вы делаете в приложениях, фотографии на вашем телефоне, данные о местоположении, история расходов, носимые датчики, текстовые сообщения, камеры в вашем доме, камера на ваших будущих AR-очках. Затем она дает вам рекомендации: какой следующий веб-сайт вам следует посетить, какую статью прочитать, какую песню послушать или какой товар купить.
Такая рекомендательная система будет чрезвычайно мощной. Более мощной, чем все существующие хранилища данных Google, Facebook и других компаний, потому что она имеет максимальное продольное представление о вас и может учиться на данных, которые в противном случае были бы слишком приватными, чтобы ими делиться. Как и в предыдущем примере с криптовалютной торговой системой, эта система будет работать, позволяя рынку моделей, ориентированных на различные области (например, рекомендации веб-сайтов, музыка), конкурировать за доступ к вашим зашифрованным данным и рекомендовать вам что-то, и, возможно, даже платить вам за предоставление ваших данных или вашего внимания к созданным рекомендациям.
Федеративное обучение Google и дифференцированная конфиденциальность Apple являются одним из шагов в направлении частного машинного обучения, но все еще требуют доверия, не позволяют пользователям напрямую проверять свою безопасность и сохраняют данные изолированными.
Современные подходы
Еще очень рано. Лишь немногие группы имеют что-то работающее, а большинство пытается откусить по кусочку за раз.
Простая конструкция от Algorithmia Research предлагает вознаграждение за модель, точность которой превышает определенный порог бэктестинга:

В настоящее время Numerai идет на три шага дальше: она использует зашифрованные данные (хотя и не полностью гомоморфно), объединяет краудсорсинговые модели в метамодель и вознаграждает модели на основе будущих показателей (в данном случае - одной недели торговли акциями), а не бэктестинга с помощью собственного токена Ethereum под названием Numeraire. Специалисты по анализу данных должны использовать Numeraire в качестве "скина" в игре, стимулируя производительность на основе того, что произойдет (будущая производительность), а не того, что уже произошло (производительность на основе бэктестов). Однако в настоящее время блокчейн централизованно распределяет данные, ограничивая, как кажется, самый важный компонент.
Никто еще не создал успешного рынка данных на основе блокчейна. Ocean - это ранняя попытка создать такой рынок.
Другие начинают с создания безопасных вычислительных сетей. Openmined создает многопользовательскую вычислительную сеть для обучения моделей машинного обучения на базе Unity, которая может работать на любом устройстве (по аналогии с Folding at Home), включая игровые консоли, а затем расширяется до безопасных MPC. Enigma придерживается аналогичной тактики.
Интересным конечным результатом могли бы стать метамодели, принадлежащие друг другу, которые дают поставщикам данных и создателям моделей право собственности пропорционально тому, насколько умнее они их сделали. Модели будут токенизированы, со временем смогут приносить дивиденды и, возможно, даже будут управляться теми, кто их обучил. Оригинальное видео Openmined - самая близкая к этому конструкция, которую я видел до сих пор.
Какие подходы могут сработать в первую очередь?
Я не берусь утверждать, что знаю, какая именно конструкция лучше, но у меня есть несколько идей.
Один из тезисов, который я использую для оценки идей блокчейна, таков: на спектре от "физически родного" до "цифрового" и "блокчейн-родного", чем больше "блокчейн-родного", тем лучше. Чем меньше блокчейн, тем больше доверенных третьих сторон появляется, что увеличивает сложность и снижает простоту использования в качестве “строительного” блока для других систем.
Здесь, я думаю, это означает, что система с большей вероятностью будет работать, если создаваемая ценность поддается количественной оценке - в идеале непосредственно в форме денег, а еще лучше - токенов. Это позволяет создать чистую, замкнутую систему. Сравните предыдущий пример криптовалютной торговой системы с той, которая выявляет опухоли на рентгеновских снимках. В последнем случае вам нужно убедить страховую компанию в том, что модель рентгеновского снимка ценна, договориться о том, насколько ценна, а затем доверить небольшой группе физически присутствующих людей проверить успешность/неуспешность модели.
При этом нельзя утверждать, что не появятся и более очевидные положительные результаты использования цифровых технологий в обществе. Рекомендательные системы, подобные ранее упомянутой, могут быть чрезвычайно полезны. Если они подключены к рынкам кураторства, то это еще один случай, когда модель может предпринимать действия программно на блокчейн, а вознаграждением системы являются токены, опять же создавая чистый замкнутый цикл. Сейчас это кажется маловозможным, но я ожидаю, что со временем сфера задач, основанных на блокчейне, будет расширяться.
Последствия
Во-первых, децентрализованные рынки машинного обучения могут ликвидировать монополию на данные нынешних технологических гигантов. Они стандартизируют и коммодитизируют основной источник создания стоимости в интернете за последние 20 лет: проприетарные сети данных и сильные сетевые эффекты вокруг них. В результате создание стоимости перемещается вверх по стеку от данных к алгоритмам.

Говоря иначе, они создают прямую бизнес-модель для искусственного интеллекта. И для работы с данными и для его обучения.
Во-вторых, они создают самые мощные системы ИИ в мире, привлекая к ним лучшие данные и модели с помощью прямых экономических стимулов. Их мощь возрастает благодаря многосторонним сетевым эффектам. По мере того, как монополии на сети передачи данных эпохи Web 2.0 становятся товарными, они кажутся хорошим кандидатом для следующей точки переагрегации. Вероятно, до этого еще несколько лет, но направление кажется верным.
В-третьих, как показывает пример с рекомендательной системой, поиск становится обратным. Вместо того чтобы люди искали продукты, продукты ищут и конкурируют за людей (за эту формулировку спасибо Брэду). У каждого человека могут быть рынки персонального курирования, где рекомендательные системы конкурируют за размещение наиболее релевантного контента в его ленте, а релевантность определяется самим человеком.
В-четвертых, они позволяют нам получить те же преимущества мощных сервисов на основе машинного обучения, к которым мы привыкли от таких компаний, как Google и Facebook, без передачи наших данных.
В-пятых, машинное обучение может развиваться быстрее, поскольку любой инженер может получить доступ к открытому рынку данных, а не только небольшая группа инженеров в крупных компаниях Web 2.0.
Задачи
Прежде всего, методы безопасных вычислений в настоящее время очень медленные, а машинное обучение уже является вычислительно дорогим. С другой стороны, интерес к методам безопасных вычислений начал расти, и производительность увеличивается. За последние 6 месяцев я видел новые подходы со значительным улучшением производительности по сравнению с HE, MPC и ZKPs.
Вычислить ценность конкретного набора данных или модели для метамодели сложно.
Очистка и форматирование данных, полученных с помощью краудсорсинга, является сложной задачей. Скорее всего, мы увидим некую комбинацию инструментов, стандартизации и появления малых предприятий для решения этой проблемы.
И наконец, как это ни парадоксально, бизнес-модель для создания обобщенной конструкции такой системы менее понятна, чем для создания ее отдельного экземпляра. Похоже, это относится ко многим новым криптопримитивам, включая рынки кураторства.
Заключение
Сочетание частного машинного обучения с блокчейн-стимулами может создать сильнейший машинный интеллект в самых разных приложениях. Существуют значительные технические проблемы, которые, как кажется, со временем можно решить. Их долгосрочный потенциал огромен и является долгожданным сдвигом в сторону от нынешней хватки крупных интернет-компаний на данные. Они также немного пугают - они сами себя запускают, сами себя улучшают, потребляют частные данные и их практически невозможно отключить, что заставляет меня задуматься, не является ли их создание вызовом более мощного Молоха, чем когда-либо прежде. В любом случае, это еще один пример того, как криптовалюты будут медленно, а затем внезапно прокладывать себе путь в каждую отрасль.
Телеграм канал про web3 разработку, смарт-контракты и оракулы.
lxsmkv
Помню в году 2009 в универе мой однокурсник говорил. "Вот классно бы было создать такую платформу на которой можно было бы продавать данные. Например ты ученый тебе нужны данные, или ты бизнес, тебе нужны какие-то данные по рынку..."
Я тогда надо сказать вообще не понял как это может взлететь. Т.е. по моим прогнозам такая платформа в то время просто не набрала бы популярности. Но вот пришло время. И появился спрос на данные.
У меня один вопрос, как отличить реально собранные данные от фейковых. Потому что везде где можно заработать деньги, будут мошенники.
fedorro
Нейронная сеть, которая натренирована находить фейковые данные, исключительно на блокчейне, конечно ???? /s
aleks_raiden
В общем и целом - эта задача не имеет решения, чисто исходя из логики. Возьмем исключительно узкую выборку, например, ид-поток цен на BTC. Если я выдаю в фид цифру 21 345.34, а рядом, допустим, топ-1 игрок рынка, 21344.96 - то статистически мы оба даем достоверные данные. Так как нельзя доказать, что таких сделок не было.