
11 августа мы провели Data Science Meet Up #2. Повестка митапа — работа с данными кредитных продуктов, а тематическая — киберпанк. Это был второй митап по DS, но первый тематический. Для тех, кто не смог поучаствовать, немного расскажем как прошёл митап и поделимся конспектами докладов и ссылками на записи, если захотите посмотреть какое-то выступление полностью, а не в нашем урезанном виде. Под катом: фотографии, доклады от джунов, которым не верят, что они джуны и жёсткая обратная связь от участника.
В этом году мы провели наш самый большой митап — в наш IT-офис пришли 180 гостей, а на прямой эфир на YouTube – 200 зрителей. Возможно, из-за рассылки, анонсов в Телеграм-канале или на Хабре, или пришли по рекомендациям. Ведь, как мы узнали, кого-то на митап отправил тимлид:).
Возможно, участников привлекла тема — киберфутуризм. Не прям киберпанк, но близко к этому: неоновое оформление...

...и сумерки в зале…

…футуристичная фотозона…

…электронный диджей-сет или конкурс костюмов, за которые мы подарили подарки.

А может дело в докладах? Киберпанк Киберфутуризм, к которому мы стремились, кажется характеризуется развитием высоких технологий, которые практически везде? А что может лучше отражать развитие технологий, как не data science?
Вот мы и поговорили о технологиях. Если коротко и условно описать суть докладов митапа, то получится что-то вроде этого: «Сначала мы привлекли клиента, потом предложили ему кредитный продукт, но условия изменились. Что же нам с этим делать и как правильно обрабатывать данные?»
Доклады
Докладов было четыре:
Развитие клиентской базы: моделирование LTV и прогноз будущих доходов.
Uplift-моделирование в ценообразовании кредитных продуктов.
Совершенный
кодрасчёт.Побеждаем смещение распределения в задаче нейросетевого кредитного скоринга.
Развиваем клиентскую базу и моделируем LTV
Сергей Королев, Middle Data Scientist Департамента продвинутой аналитики, рассказал как Департамент работает с клиентом на всех этапах: привлечение (юрлица), развитие (повысить потенциал с помощью продуктов) и удержание (для тех, кто склонен уйти), и на каждом этапе важно понимать, какую сумму можно потратить на работу с клиентом. А для этого интересно знать ценность клиента для компании. Здесь возникает LTV — «ценность клиента на всем сроке жизни».

Способов расчёта LTV много, но сначала надо «вычислить» 2 компоненты: срок жизни и средняя ценность клиента. Срок жизни считали с момента открытия РКО. Из базы исключили клиентов, которые были замечены в нарушении 115-ФЗ.

Под ценностью решили считать опердоход клиента и оперприбыль.
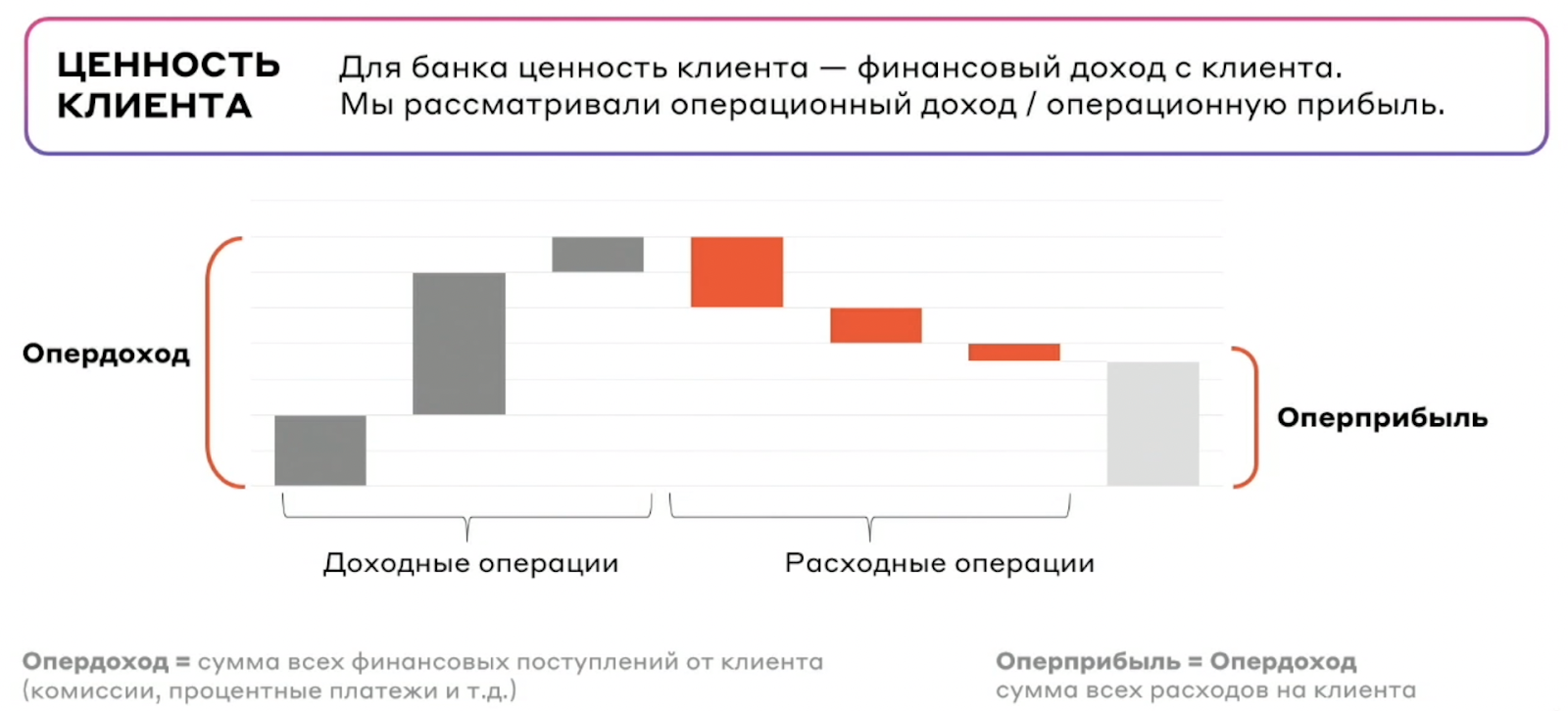
Но выбрать нужно что-то одно — по двум метрикам предсказание сильно усложнится. Выбрали опердоход. Почему?
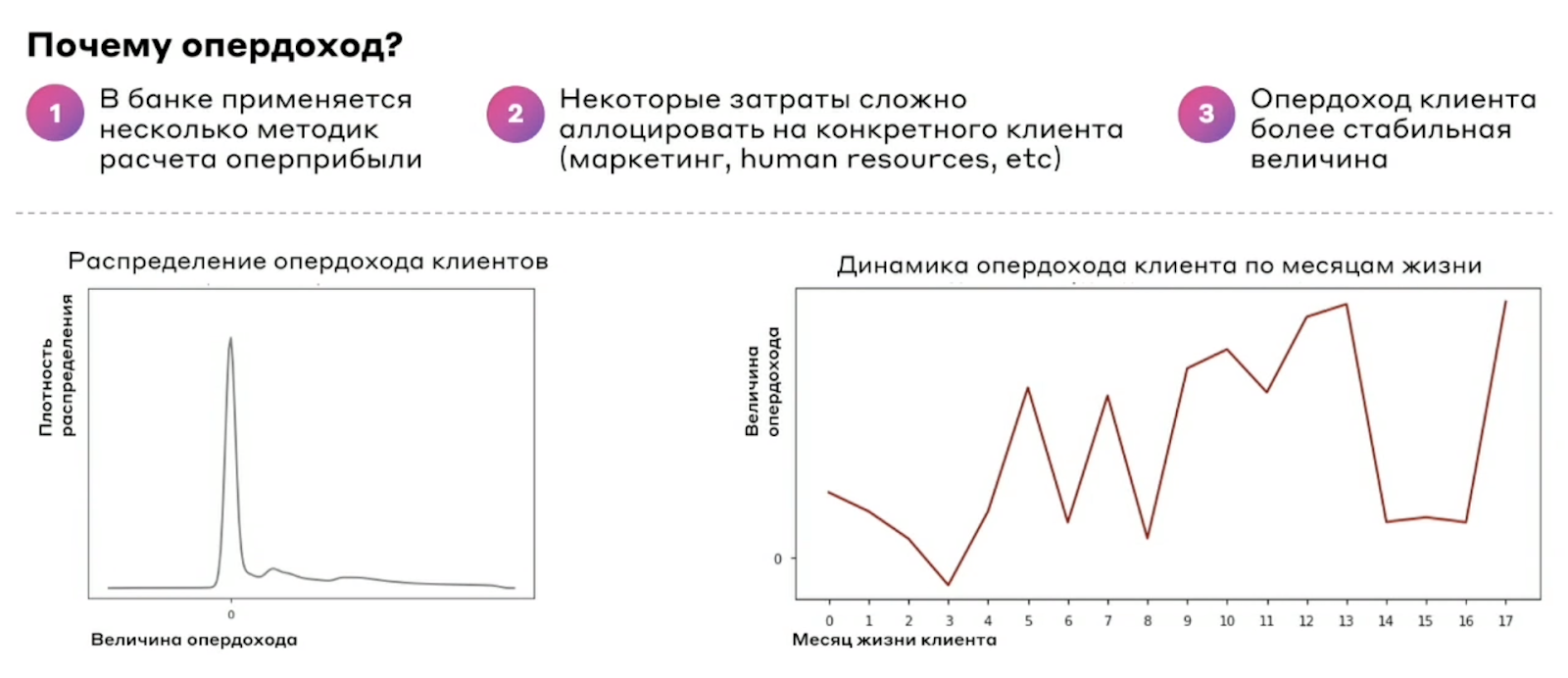
В итоге, финальная постановка задачи выглядела так.

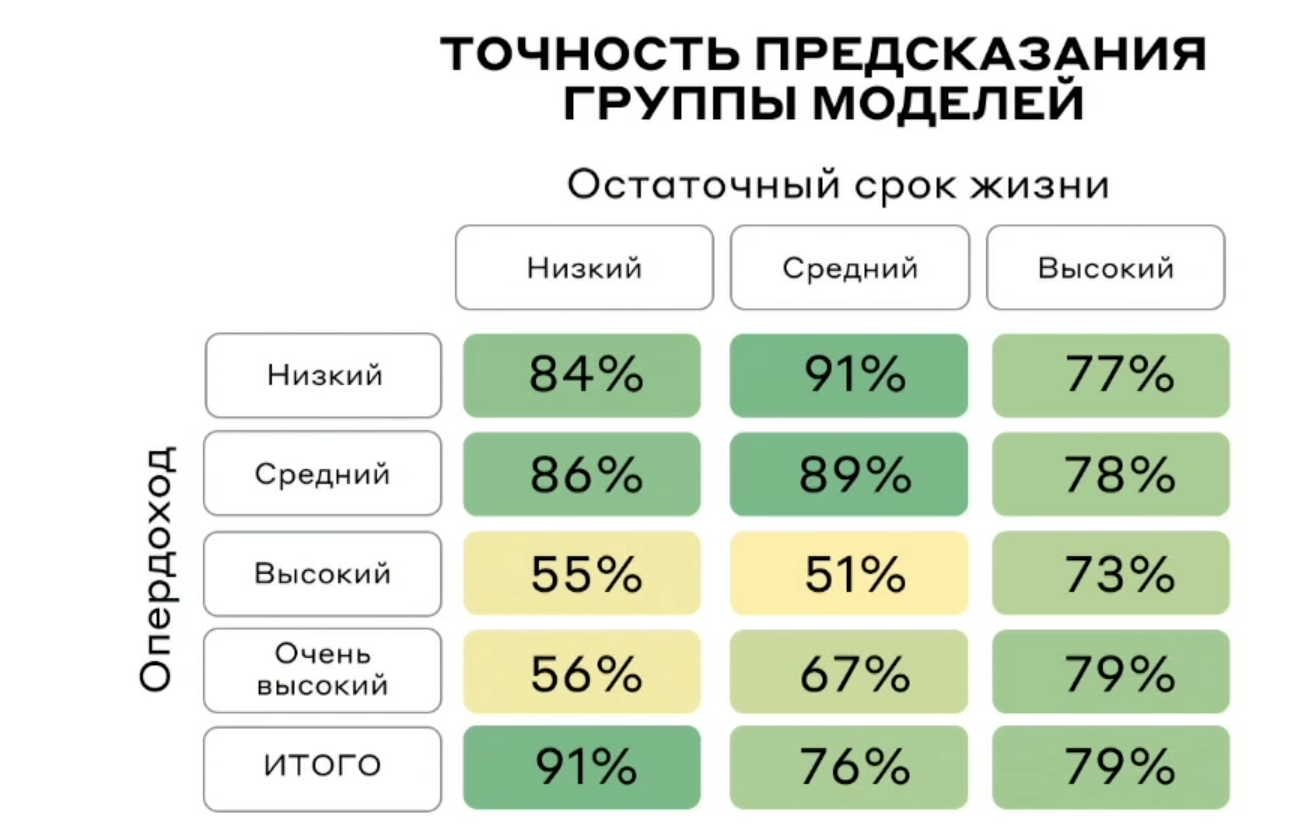
Что же получилось? Общая точность на отложенной выборке составила — 76% (макро), точность определения группы опердохода составила 82%, а потенциальный эффект составил 500 млн рублей в год, и +10% к удержанию ключевых клиентов.
После доклада — стандартный блок вопросов.
Насколько предложенная модель может имплементироваться живым бизнесом? Учитывали ли метрику «способность к воздействию»?
Пробовали ли сглаживать временные ряды?
Планировалось ли исследовать класс «высокий доход»?
Почему считали абсолютный опердоход, а не в разрезе по продуктам?
Как смогли оценить модель на реальных данных?
Но не все вопросы были уточняющими. «Суровый комментатор» не увидел в презентации ничего интересного: «Примитив и бесполезная задача». Любое мнение мы слышим:) Вопрос, кстати, от участника тоже был, такой: «Можно ли по вашей работе судить об эффективности работы в Альфа-Банке?»
За два лучших вопроса к каждому докладу мы позже подарили подарки.

Доклад и ответы на вопросы смотрите в записи.
Инференсим тех, кому отказали: нейросетевой подход в кредитном скоринге
Переходим к кредитному скорингу. Может показаться, что кредитный скоринг в банках — классическая и давно изученная задача. Однако, как показывает практика, многие модели обучаются на данных, которые, не совсем (а иногда и полностью) не соответствуют данным в реальном мире. О нюансах формирования выборки для обучения рассказал Алексей Фирстов, Junior Data Scientist Альфа-Банк.

Задача кредитного скоринга классическая — нужно определить уйдет ли клиент в дефолт, или, иначе, в просрочку больше 90 дней. Для решения мы используем банковские последовательные данные, например, транзакции.

Но здесь появляется смещение — отличие данных для обучения от данных, на которых модель будет применяться. Выделяем 2 глобальных источника смещения:
Смещение по времени — возникает из-за того, что факт дефолта определяется спустя год после выдачи кредита. Как решить? Найти прокси — короткие просрочки.
Смещение по входящему потоку — возникает из-за того, что поведение клиентов в обучающей выборке отличается от тех, на ком она будет применяться. Это фича стандартного подхода в выдаче кредитов — отказывать тем, кто склонен к дефолту. Получается, что при обучении модели будут использоваться только «хорошие» клиенты, и модели не на чем обучаться?
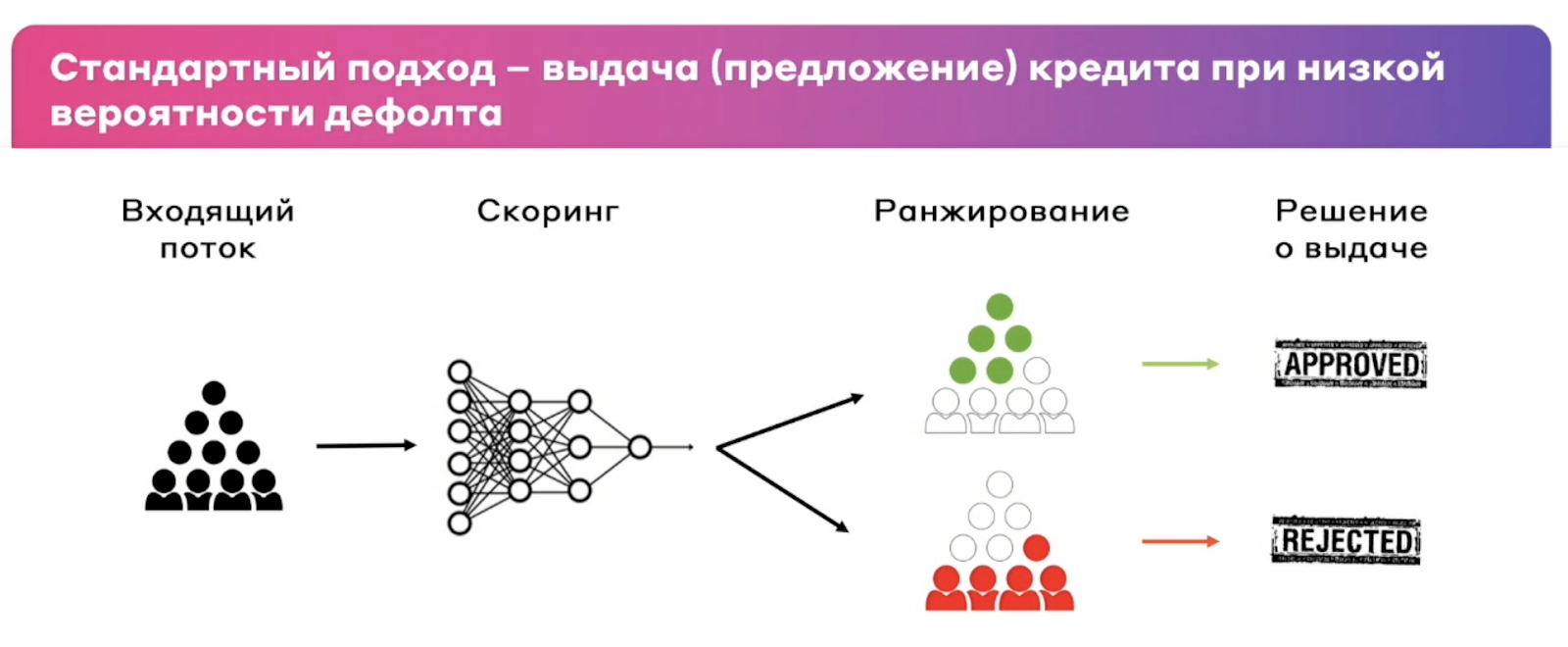
Как решить? Применить подход Reject Inference. Он заключается в том, что мы можем «инференсить» тех, кому когда-то отказали. В эту выборку можно попасть двумя путями:
Выдать кредит всем без разбора (выборка challenger).
Посмотреть в кредитной истории факт дефолта.
Выборка challenger существенно отличается от выборки внутренних выдач.

В конце получилось 3 выборки: внутренние, внешние и challenger. Что с ними делать?
Ничего: учим все вместе.
Учим на первых двух, дообучаем на challenger.
Учим все вместе с индивидуальным весом каждой выборки.
Уже дальше в докладе Алексей рассказал, как выбрали третий вариант, как подбирали веса сегментов (собрав консенсус), провели инициализацию, провели процесс обучения 3 раза, как объединяли скоры независимых моделей и что пошло не так.
Средняя оценка доклада Алексея от участников митапа — 5 баллов, даже сумрак в зале не мешал. Но без казусов не обошлось — на одном из вопросов внезапно микрофон перестал работать.

Но быстро принесли новый. А вопрос от этого участника было два: «Почему в challenger включаете всех, а не тех, кому вы бы не выдали кредит? И вы точно джуниор?»
Полный доклад смотрите в записи.
Ищем особо чувствительных с помощью Uplift-моделирования
Есть 2 кредитных продукта: TopUp и Relend.
TopUp — когда надо сохранить клиента и подобрать новые условия, потому что старые изменились, например, ЦБ поменял ставку.
Relend — тоже самое, но для внешних клиентов, например, чтобы клиент перекредитовался у нас.
Задача в том, чтобы найти клиентов, которые особо чувствительны к изменениям. Зачем? Чтобы не потерять. Заодно, можно найти лояльных клиентов, которые на такие изменения не реагируют. Вот об этом рассказал Максим Коматовский, Junior Data Scientist Альфа-Банк.

Для начала сегментируем клиентскую базу. Есть много способов, и один из них субъективный.

Дальше берём Up-lift-модель, готовимся и проводим эксперименты.

«Нужно следить за экспериментом от начала и до конца. Может случиться, чт контрольную группу вы начали обзванивать на 2 дня раньше, а эксперимент через неделю закончился и в контрольной группе с позитивным воздействием Target Rate выше. Потом неделю думаешь в чем проблема»
Максим Коматовский, автор доклада
Также в докладе:
Специфические метрики под Up-lift.
Сортировка скоров, подсчёт topK% и разницы Response Rate.
Результаты одного из экспериментов.

Полный доклад смотрите в записи.
Про «кочегаров» и «очистку угля»
«Если машинное обучение — это паровоз DS, то данные — это уголь. Сейчас мы поговорим про кочегаров»
Так начал свой доклад о подготовке данных и методах, которые в этом помогают, Максим Стаценко — Team Lead/Senior DWH Developer в Яндекс.

Максим — BigData TeamLead в службе подготовки и обработки больших данных Яндекса. Служба занимается подготовкой данных поиска и рекламы. Эти данные поступают не только на вход моделям машинного обучения и подбирают рекламу, поисковую выдачу, но и попадают на стол аналитикам, внутренним сервисам мониторинга.
Служба работала почти с момента основания Яндекса. Но 2 года назад кое-что изменилось — на основе данных, которые готовит служба, клиентам начали выплачивать кэшбек с денег, потраченных на рекламу. Проблема в том, что аналитики лояльны к ошибкам — особо нет разницы если в определённой аудитории может быть 1 000 001 человек или 1 000 006. А для бухгалтеров, ФАС и налоговой службы, которые все вместе следят за финансовыми отчетами разница очень даже есть.
Изначально аналитическое хранилище данных на такую точность не было рассчитано, но когда появился проект кэшбека и финансовые отчеты, пришлось избавляться от погрешностей и предотвращать их.
Максим рассказал о нескольких методах, которые использует служба. Один из них — мониторинг данных. Например, когда мы сравниваем текущую неделю с прошлой. Но они совпадают не полностью, приходится выбирать окно. Люди уходят в отпуска, окно становится шире, и вы перестанете ловить сильные ошибки.
Здесь помогает сверка или кросс-валидация: проверяем инвариант на всех этапах обработки, и сравниваем один показатель на разных источниках.
Дальше Максим рассказал о других методах, проверке кода, создающего данные, скриптах, тестах…

…код-ревью, методе сравнения с прогнозом, методе главных компонент и ФА…

…и решении проблемы «Вавилонской башни»
Важное примечание. Использовать все методы довольно дорого, но есть плюс в том, что их можно использовать не все сразу.
Полный доклад смотрите в записи.
Выводы
В целом, мы старались хорошо подготовиться: оформили зал, подобрали свет, заготовили пиццу и лимонад на перекус...
...подготовили программу с докладами, которые согласуются друг с другом, и тайминг, чтобы участники не успели сильно устать, и при этом остались бы силы задать вопросы. И чтобы у них оставались силы на активности в конце. Если вы сходили к нам на митап — отпишитесь о ваших впечатлениях. Получилось ли? Будем благодарны и учтём пожелания в следующих мероприятиях.
Полезные ссылки
– Записи докладов и презентации спикеров. Задавайте вопросы в комментариях в VK, если не успели в прямом эфире.
– Ищите себя в фотоотчёте с мероприятия (а также на лендинге), слушая подборку энергичного техно с митапа.
– Поделитесь с нами мнением о митапе в опросе: хвалите, если есть за что, подсказывайте, что улучшить к следующей встрече.
– Подпишитесь на Телеграм Alfa Digital Jobs: здесь рассказываем обо всех наших активностях

Ka_Wabanga
Мнение со стороны: Алексей Фирстов явно не джуниор. Может год назад им был, но уже не джуниор.
Отличные доклады - спасибо.
AlfaTeam Автор
Спасибо за обратную связь)
MyWave
Это же мой коммент под недавнем видео кейс-стади от омега-банка на канале ОДС :)