
В процессе эволюции обезьяноподобное животное дриопитек превратилось в современного разумного человека. Эволюция — это развитие, она бывает химической или биологической, но сегодня хочу рассказать, как она ложится на приложения и репозитории.
Меня зовут Игорь Кацуба, я лид Core команды в Tinkoff Business. Поделюсь своим опытом, расскажу какие этапы развития нам приходится проходить, чтобы получить результат и что мешает двигаться дальше. А также узнаем про принцип цикличности, на котором и основаны все этапы. Поехали…

Что такое эволюция?
Эволюция — это процесс развития. У неё много принципов, но мы затронем только один — это принцип цикличности. Он говорит о том, что последний шаг одного цикла эволюции является началом другого. Простой пример — существует некая система:
Шаг 1. Повышается её стабильность;
Шаг 2. Она распространяется;
Шаг 3. Начинаются локальные изменения в процессе адаптации к внешним условиям;
Шаг 4. Системы с более «удачными» модификациями вытесняют родительские.
Эволюцию репозитория я представляю в виде пяти этапов: бойлерплейт, простое приложение, монолит, монорепо и микрофронтенд. Мы рассмотрим характерные черты каждого — что происходит с командой, с пайплайнами, с самим репозиторием. Какое влияние оказывает внешняя среда — бизнес, который толкает нас вперёд. Посмотрим на фокус развития периода.
5 этапов эволюции репозитория
1. Бойлерплейт
Это костяк, на котором построено наше приложение. Каждый взрослый фреймворк имеет свой шаблон, который быстро создаст этот костяк каким-то тулингом. Отталкиваясь от него, мы начинаем работать дальше.

Причём, в больших компаниях есть свои готовые шаблоны, с учётом приватных репозиториев.
Характерные черты
Отсутствие кастомного тулинга. У нас всё поставляется из коробки, мы ничего не придумываем.
Небольшая команда. Нет смысла нанимать 15 человек когда нужны всего 2 сеньора.
Один репозиторий.
Всё это движется к созданию MVP и основных сущностей — рельс, по которым разрабатываются какие-то фичи и развивается приложение. Настройка тулинга (eslint, prettier) и процессов — от постановки задачи до поставки в прод.
Это очень короткий этап. Мы быстро приходим к MVP. Тут мы запрыгиваем в простое приложение, но где всё становится чуть сложнее.

2. Приложение простое
Наш репозиторий на этом этапе выглядел примерно так:

У нас появилась папка core — сюда складываются общие вещи. Папка pages, где уже отношение к роутингу. То есть, исходный код разрастается, репозиторий становится больше. Появились пайплайны, потому что доехали до прода.
Пайплайны на этом этапе очень простые:

Я ещё больше их упростил, чтобы не загромождать схему. Здесь мы делаем merge request, запускаются какие-то поверки, билды, тесты, линты, что-то ещё, и после merge происходит деплой в прод.
Что касается команды, то она как минимум увеличилась. У нас уже есть рельсы, по которым началась поставка фич. Можно нанимать условно миддлов, джунов, которые эти фичи делают и поддерживают. Ещё стали выделяться роли — кто-то больше тяготеет к инфре, кто-то делает UI-компоненты, и должен быть чувак, который всем этим управляет.
В качестве внешних факторов выступает бизнес. Он передаёт в разработку много фич, которые запланировал после MVP и хочет ещё больше.
Развитие проходит стремительно. Есть процессы, рельсы для поставки фич, команды — мы развиваемся и летим дальше со стремительной скоростью. При этом возрастает нагрузка на поддержку, возникает 1-2 линия поддержки и т.п.
И тут мы вскакиваем в другую историю.

3. Монолит
Наше приложение очень быстро вырастает. В рамках одного репозитория появляется много продуктов, которые живут в одном месте с большой связанностью кода — монолит.
Характерные черты
Большой репозиторий
Много продуктов в репозитории
Долгая доставка фич до прода
Много продуктов начинают мешать друг другу, из-за этого возникает проблема с доставкой фич до прода. Сталкиваясь между собой, продукты вызывают большую связность кода, что приводит к одним расстройствам.
Тогда формируются продуктовые команды. Продукты вырастают в отдельные большие фичи, которые нужно кому-то майнтейнить на постоянку. Всё это поставляется как одно большое приложение, одна сборка.
Пайплайн в этом случае выглядит также как на предыдущем этапе:
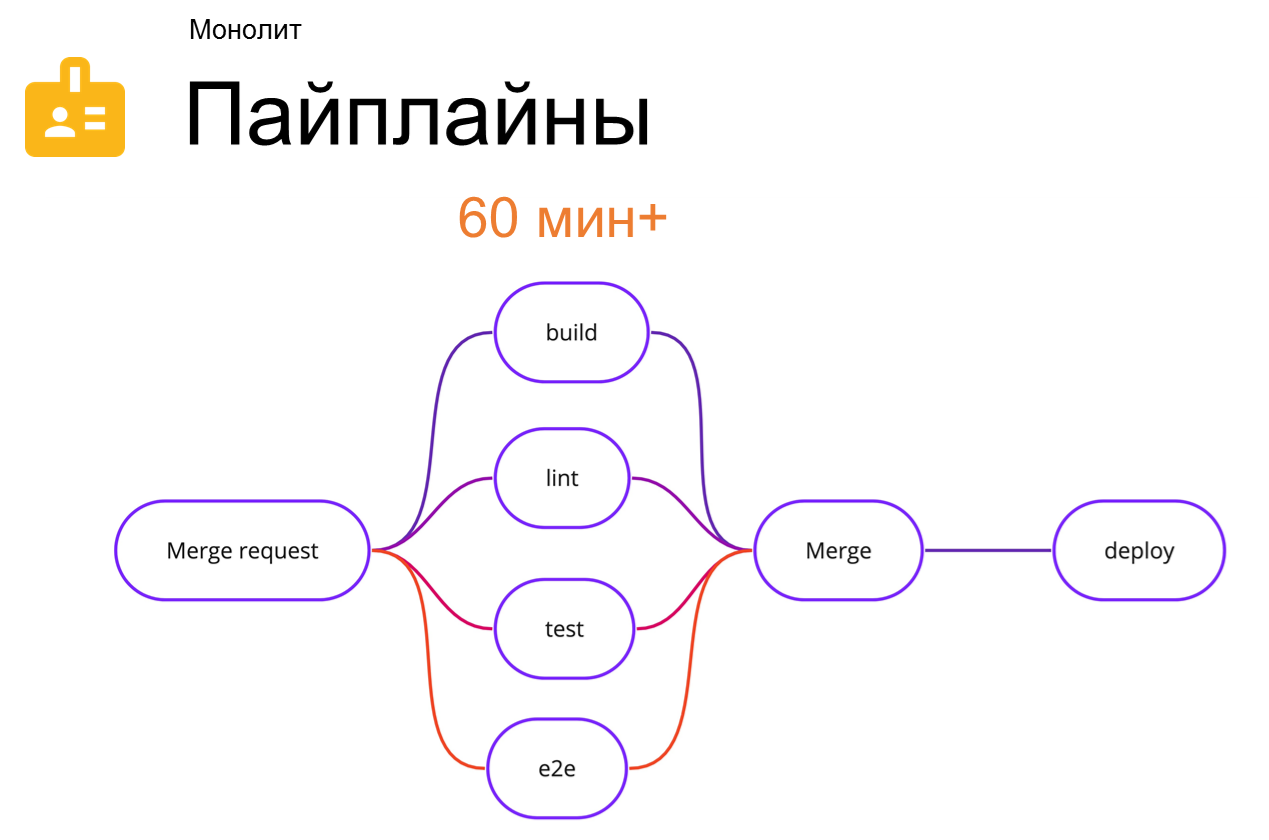
Время сильно увеличилось. Это максимально абстрактная цифра, но на этом этапе монолит начинает сжирать ресурсы именно на пайплайнах.
Например, ситуация. Вы делаете PR небольшой фичи, доводите её до тестирования. Всё хорошо, вам дают approve на merge, но тут вы вспоминаете, что забыли поправить readme. Круг начинается заново. Вы сидите полтора часа, красноглазите, накрылся какой-нибудь сервис, упал пайплайн — лучше бы этого всего не было!
При всём при этом:
Бизнес требует ускорить доставку фич. Он расстраивается, что мы не можем поставлять всё в сроки, потому что начинаем срывать релизы друг друга.
Тестировщики требуют улучшения надёжности. Опять же из-за большой связанности кода и продуктов всё шатко-валко едет куда-то, происходит очень медленно и грустно.
Ключевые разработчики увольняются. На этом этапе я часто встречался с тем, что те два бедных сеньора, которые поднимали приложение с нуля, делали инфру, описывали всё это в RFC, увольнялись. Они хотят развивать продукт с точки зрения инфраструктуры, чистоты кода и так далее, а им этого не дают. Постоянно жмут сроки, не получается разгребать техдолг. Разработчики выгорают и просто уходят.
А дальше нас ждут: поиск новой архитектуры и большое количество экспериментов.
Тут мы прыгаем в другой этап. Если первые три примерно одинаковые, то дальше это уже частный случай, который придумал я.

4. Монорепа
Это одна из веток развития репозитория. В теории он мог пойти по другим рельсам, но в моей голове он пошёл именно так. У нас был репозиторий с папками core, pages, ресурсы одного приложения:

И всё в один момент превратилось вот в это:

У нас на структурном уровне появились отдельные приложения и библиотеки с общими вещами для каждого. Они начинают жить сами по себе.
Пайплайны сильно усложняются:

Это максимально упрощённая версия пайплайна, которую я видел. Здесь 3 приложения, 2 ветки и одна библиотека. У приложения app3 нет своей ветки. Можно сделать вывод, что именно в этом merge request app3 никак не изменился и для него ничего не запускалось. Чтобы это было возможно сделать, происходит техническое усложнение.
Нам уже нужны:
Специальный тулинг для управления монорепой. Мы не можем запустить пайплайны для каждого приложения, иначе будем ждать его вечность. Нужен тулинг, который будет вычислять какой-то diff, чтобы запускать всё в графу зависимостей.
Кастомный тулинг и плагины для сборок, линтинга, тестирования. В рамках каждой компании есть свои требования, как это работает, CDN кому-то нужен, кому-то нет.
Короче говоря, всё становится сложнее и сложнее.
Что происходит с командой?
Команды окончательно делятся по продуктам. Каждый продукт выехал в своё приложение. Определённая группа отвечает за свой участок.
Настраиваются билды, тулинг под команду на уровне проекта. У нас есть общие конфиги в корне, мы немножко развязали руки командам. Они prettier по-другому настроили, им не нравится одна кавычка, нужно две.
Появляется core-команды. Технических вещей становится много, их нужно кому-то отдать. Понятно, что каждая продуктовая команда хочет тащить свою фичу в прод, а не заниматься инфрой или общими бизнесовыми историями. Поэтому появляется core-команда, которая тащит на себе технику, инфру, какие-то общие для бизнеса истории.
Меняется и поставка приложения
В нашем варианте каждое приложение заняло свой url. У нас есть балансер, пользователь браузера приходит к нему с запросом, а он уже перенаправляет в определённое приложение, и оно отдаётся пользователю.
Каждое приложение грузит общую часть (навигацию, хэдер, футер, etc.). Добавляет это к себе и поставляет пользователю.
Для этого этапа характерно, что доставка фич значительно ускоряется. Переконструированием репозитория мы максимально отделили одни продукты от других и уменьшили их связанность между собой. У них единственная связь — это core-либы.
Пайплайны у нас только для одного продукта. Мы не аффектим никого — запустили тест и спокойно задеплоились хоть три раза в день.
Уменьшается давление со стороны бизнеса. Доставка фич ускорилась, бизнес чуть под расслабился. Становится проще, но не до конца. Из-за уменьшения давления бизнеса появилось время на технический долг. Разработчики начинают разбираться с user experience.
При этом остаются проблемы с релизом общей части приложений. Когда меняется общая часть, нам приходится всё пересобрать, всё задеплоить. Это очень долго, аффектит большинство приложений.
Что нас ждёт дальше
Борьба за перфоманс приложения. Нам хочется каких-то изменений в плане перфоманса, потому что мы что-то постоянно грузим и перегружаем. Уже есть время об этом подумать.
Борьба за скорость доставки фич. Понятно, что у нас осталось узкое место в скорости доставки фич — это как раз общая часть.
Драфт архитектуры с полностью независимыми продуктами.
В этот момент мы прыгаем в последний этап, о котором я додумался.

5. Микрофронтенд
Это достаточно размытая история, попытаюсь чуть её описать.
На прошлом этапе было так:

Есть n приложений, здесь синим и зелеными блоками подсвечены общие части (навигация, хэдер, футер).
Но мы хотим сделать так:

Здесь есть хостовое приложение, которое забирает поставку общих частей, и уже внутри себя как-то оркестрирует, грузит остальные. Причём этих приложений может быть одновременно много.
Что происходит с репозиторием?
Он похудел, потому что из одного монорепозитория все начали разъезжаться в свои. В том, который был изначально, осталось только хостовое приложение с общими компонентами. Каждый продукт выехал в свой репозиторий и начал в нём жить отдельно.
Появилось много других продуктовых репозиториев. Причём не обязательно это монорепозитории. Каждая команда начинает организацию вообще с нуля как ей удобно. В зависимости от размера продуктов всё может сильно меняться.
Что произошло с пайплайнами?

Это пайплайн прошлого этапа, и он не изменился. Хостовое приложение осталось всё то же, если в нём есть несколько приложений. Отдельные общие библиотеки, и есть одно хостовое предложение. Пайплайнов просто стало больше, потому что появилось много репозиториев.

Конечно, это накладывает ресурсные требования. Нам нужно больше агентов и машин, где бы это всё прогонялось. Возможно, с этим тоже будут проблемы, но здесь мы их не будем рассматривать.
В команде ничего не изменилось. Продуктовая команда так и осталась таковой, просто стала работать в другом репозитории. Мы перестали толкаться локтями и максимально отделились друг от друга. Фактически связующим звеном осталась только core-команда, которая поставляет для всех свои технические продукты.
А бизнес спокойно планирует новые фичи. Мы избавились от последнего бутылочного горлышка в плане скорости поставки фич, и бизнес перестал беспокоить разработчиков. У разработки теперь есть ещё больше времени на техдолг.
Итоги пяти этапов эволюции репозитория
Итак, что мы имеем, пройдя все 5 периодов развития:
Независимые релизы
Каждое приложение поставляется по своим рельсам. У нас есть хостовое приложение, оно грузит в себя дочернее, каким-то образом им управляет. Одно дочернее может являться хостовым для другого приложения — получается такая матрёшка. Каждый релиз будет независимым. Мы просто кое-что изменили.
Конечно, у нас есть узкие места при наличии UI-KIT, который отдельно живёт. Когда он обновляется, всем продуктам приходится обновлять его у себя.
Супербыстрая доставка ценностей до прода
Много внутреннего тулинга
Мы шли 3 года через тернии. По ходу набирали много историй, нужных нам помимо инструментов, которые даёт сообщество. Самое банальное — я видел много реализаций в связке с CDN, статики. Кто-то делает это через S3, кто-то даже через Kubernetes. Тут много тулинга может быть в принципе.
Парочка платных сервисов в dev-инфре
Всё технически сложно, иногда дешевле и проще купить сервис, который кэширует сборки или делает что-то ещё, чем выделять на это команду, ведь её нужно поддерживать, развивать. Кажется, иногда это и правда выгодно.
Очень длинный путь развития.
Пять этапов от бойлерплейта до микрофронтендов — очень долгий путь. Обрезать хотя бы один период невозможно. Всё равно нужно путём эволюции прийти к микрофронтенду. Когда путь очень длинный и естественный, то это не кажется сложным. А когда ты сразу пытаешься выстроить микрофронты, то начинаешь сходить с ума, потому что там небольшая вакханалия.
Что будет дальше
Мы помним, что у нас микрофронтенды и долгий путь развития. А что дальше? Чтобы ответить на этот вопрос, мне пришлось вернуться в начало и вспомнить про цикличность, а именно про 4 пункт:
Повышается стабильность некой системы
Система получает распространение
Система получает локальные изменения в процессе адаптации к внешним условиям
Системы с более «удачными» модификациями вытесняют родительские
Я начал искать удачные модификации и вот к чему пришёл:

У нас есть:
Piral, который даёт какие-то решения по микрофронтенду
Single-SPA
Bit — совершенно иная архитектура
Open Components
WebPack с Module Federation, как поставка
Puzzle-JS
Luigi
SystemJS — очень старая тема
Даже Microzord — глубокая альфа видения Tinkoff с микрофронтендами.
И это не всё! Если порыскать по просторам интернета, есть всякие решения от наших индийских коллег. Там происходит какой-то ужас. Я с ходу нагуглил 30 совершенно разных подходов, которые плюс-минус неплохо описаны. Кажется, что выбрать из этого что-то удачное невозможно, потому что у каждого решения есть какие-то проблемы. Кто-то пытается их скрестить, например, Module Federation и Single-SPA. Тут может быть очень много комбинаций, и все они всё равно не идеальные.
Что с этим делать, непонятно.
Какую архитектуру выбрали в Tinkoff?
Жуткая смена контекста. Я вспомнил, как было в JavaScript. В 2014 году мы хотели писать код так:

А мы хотели объявлять класс и писать вот так: странным:

Пишешь класс и в рамках одного блока описываешь его. Также методы и всё, что происходит в конструкторе. Тогда летом 2014 года вышел TypeScript, который сразу же позволяет нам писать именно так:

Мы скрещиваем синтаксический сахар с каким-то transpiler, и на выходе для пользователя получаем рабочий код, нативный JS. Это настолько въелось в нашу жизнь, что мы до сих пор не можем отделаться от transpilers и всегда их используем. Тем более, TypeScript — это не просто transpilers, а ещё и надмножество JS в целом. И само сообщество заставило эволюционировать стандарт.
В 2015 году выходит ECMAScript 6, который потом стал ECMAScript 2015, 2016 и т.д. — каждый год стали выходить апдейты, спецификации.

Тогда в 2015 году у нас появилась возможность писать нативно именно так, не используя transpilers. Это случилось путём естественной эволюции, когда появились внешние факторы. Пришла рабочая группа TC39 и сделала стандарт — это классно.
Но мой пойнт не в том, чтобы сидеть и ждать какого-то стандарта для микрофронтов. Я предлагаю делать свои решения. Возможно, улучшать чужие и распространять их в сообществе, внедрять в приложения. Как когда-то transpilers стали для нас нормой.
Например, мы будем стоять перед выбором: выкинуть все эти решения и сделать своё новое или оставить всё как есть и просто забыть. Чтобы в этот момент могла прийти рабочая группа TC39 и на своих плечах утащить нас в светлое будущее, где будет стандарт для микрофронтов. Мы откажемся от всего этого зоопарка и будем жить счастливо!
Уже 24 и 25 октября 2022 года в Москве в Старт Хаб (Start Hub) начнется FrontendConf. Вас ждут 2 насыщенных дня живого общения с ведущими экспертами, знакомство с современными подходами, обзор лучших практик и перспективных технологий. Выступят 40+ лучших докладчиков в своей сфере, пройдут круглые столы и нетворкинг! Еще можно успеть ознакомиться с программой, расписанием и заказать билеты на официальном сайте конференции
JordanCpp
Вы пишите аналог ядра linux? И вам не подходит стандартный тулинг?
Или вы пишите обычный сервис, где нужно просто обработать клик от пользователя, сохранить, поискать и выдать результат. Зачем такие сложности как свой тулинг, свои системы тестирования и т.д
Похоже на архитектуру астронавтов. Архитектура ради архитектуры. Делаем потому, что можем.