
Привет, Хабр! Меня зовут Борис Мурашин, я системный архитектор развития платформы больших данных в Х5 Tech. В статье делюсь своим опытом работы с кластером Hadoop: рассказываю, как с помощью сторонней библиотеки мне удалось организовать оперативную выгрузку образа файловой системы HDFS в Hive. И не только про это. Надеюсь, что мои инструкции помогут другим сэкономить массу времени в работе с кластером.
Сколько места на диске используют таблицы Hive в HDFS? В каких из них много мелких файлов? Какая динамика у этих цифр? Что происходит в домашних каталогах пользователей? Кто прямо сейчас создаёт таблицу с партиционированием по timestamp и скоро «уложит» нэймноду по GC pause? Давайте разбираться.
Основа кластера Hadoop – его файловая система HDFS. Рано или поздно перед администраторами встаёт вопрос её мониторинга. Даже опытные и ответственные пользователи могут где-нибудь позабыть миллион-другой файлов. На большом же кластере с тысячей активных пользователей, среди которых и стажёры, и подрядчики, и менеджеры, без хорошего мониторинга не обойтись.
Пользователи кластера не склонны следить за числом и размером файлов – оно и понятно, это в общем-то не их работа. И легко могут создавать таблицы со средним размером файла, ну, скажем, 100Kb, когда легко можно было сделать 10Mb. Для нэймнод это в 100 раз больше места для хранения в Heap и в 100 раз больше запросов к RPC.
Нередко приходят люди с бэкграундом RDBMS (Oracle, GreenPlum и пр.) и делают партиционирование по трём полям с 1000 уникальных значений в каждом. Нэймнода пытается создать 10003 папок – если её не «уложит» по GC pause при их создании, то уж при удалении это точно случится.
Вводные
Какие у нас вообще есть возможности мониторинга HDFS «из коробки»? Немного, на самом деле:
-
hdfs dfs -count -v /apps/hive/warehouse/*/* /user/*– можем посмотреть, что происходит в хранилище Hive, домашних каталогах и т. д. Это вполне рабочий вариант. Распределение по размеру файлов не построить – таблицы, где несколько больших и куча мелких файлов/пустых партиций мы не увидим, но средний размерCONTENT_SIZE / (DIR_COUNT + FILE_COUNT)оценим и найдём «лидеров отрасли».
Если Heap у нэймноды небольшой, то работать будет быстро. У меня в HDFS 130 млн файлов, 70 млн в Warehouse, Heap 90Gb – такая команда заставляет JVM прочёсывать половину своей кучи, что, прямо скажем, небыстро (больше двух минут – на скриншоте выше)
Кроме того, во время работы этой команды растёт Namenode RPC latency, т. е. нэймнода начинает притормаживать, что не очень здорово. -
hdfs oiv– Offline Image Viewer. Может запустить усечённый вариант нэймноды. Может экспортировать образ в XML или CSV, которые можно «скормить» тому же Hive.
То, что надо? Не совсем. Это, конечно, позволяет не грузить рабочую нэймноду и открывает прямой путь к анализу FSImage с помощью SQL. Вот только работает oiv в один поток, и на мало-мальски большом образе это очень долго. На загрузку FSImage в 14Gb уходит 20 минут, а выгрузка в CSV занимает вообще час:
Хочется всё-таки большего: чтобы и работало в масштабе минут, и использовать силу и гибкость SQL для анализа. Решение – библиотека HFSA от Marcel May. Она использует часть кода Apache Hadoop для загрузки FSImage и реализует многопоточный обход образа.
Особенно здорово, что в качестве зависимости используется Hadoop 3.3, который поддерживает Java 11. Разница в скорости загрузки больших FSImage по сравнению с Java 8 драматическая – 70 секунд против 15 минут для образа размером 14Gb:

Кстати, у Marcelmay есть экспортер для Prometheus на основе этой библиотеки, который собирает статистику в срезах по пользователям/группам/директориям, включая число файлов, папок и распределение по размеру. В ряде случаев этого может быть достаточно.
Собственное решение
Мне ещё хотелось найти брошенные таблицы, к которым полгода и больше не было обращений на чтение и/или запись. А для мониторинга у нас в Х5 Tech используется Zabbix. Поэтому я пошёл по пути написания своего обработчика образа с сохранением в Hive.
Нужно сделать небольшое отступление, чтобы объяснить выбор Hive. Ranger (средство управления и аудита доступа на кластер, если вдруг кто-то не в курсе) сохраняет логи аудита в HDFS в JSON, что очень удобно позволяет подцепить их как внешнюю таблицу в Hive без дополнительных усилий:
CREATE TEMPORARY EXTERNAL TABLE monitoring.ranger_log_hiveServer2_20221025_tmp
(
repoType INT,
repo STRING,
reqUser STRING,
evtTime STRING,
access STRING,
resource STRING,
..................
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES ('ignore.malformed.json' = 'true')
LOCATION '/ranger/audit/hiveServer2/20221025';
CREATE TEMPORARY TABLE monitoring.ranger_log_hiveServer2_20221025_tmp2
STORED AS ORC
AS SELECT * FROM monitoring.ranger_log_hiveServer2_20221025_tmp;
INSERT OVERWRITE TABLE monitoring.ranger_log_hiveServer2 PARTITION (\`dt\`=20221025)
SELECT * FROM monitoring.ranger_log_hiveServer2_20221025_tmp2;Плюс эти логи достаточно большие – порядка 700Gb в день в JSON, 35Gb в ORC со сжатием Snappy. Если хочется хранить историю, скажем, за 4 года и достаточно быстро её обрабатывать, кластер Hadoop и Hive хорошо подходят для этого.
Информация из FSImage органично дополняет аудит Ranger: если мы смотрим, например, пользовательскую активность над какой-то таблицей, хорошо сразу иметь цифры по числу, размеру и возрасту файлов в ней.
Впрочем, разбор логов Ranger и построение витрин на их основе (сырой лог нельзя отдавать пользователям, т. к. в нём полный текст запроса со всей коммерческой тайной, которая может там содержаться) – это тема для отдельной статьи.
Итак, сохранять образ будем в такую таблицу:
CREATE TABLE IF NOT EXISTS monitoring.fsimage
(
Path string COMMENT 'Full path of the file or directory.',
Replication int COMMENT 'Replication factor.',
ModificationTime bigint COMMENT 'The date of modification.',
AccessTime bigint COMMENT 'Date of last access.',
PreferredBlockSize int COMMENT 'The size of the block used.',
BlocksCount int COMMENT 'Number of blocks.',
FileSize bigint COMMENT 'File size.',
NSQUOTA bigint COMMENT 'Files+Dirs quota, -1 is disabled.',
DSQUOTA bigint COMMENT 'Space quota, -1 is disabled.',
Permission string COMMENT 'Permissions used, user, group (Unix permission).',
UserName string COMMENT 'Owner.',
GroupName string COMMENT 'Group.'
)
PARTITIONED BY (Parsed int)
STORED AS ORC;Эта конструкция позволяет каждый раз сохранять образ в новую партицию, не влияя на текущие запросы. Ну, и накапливать историю, само собой.
Собственно, вот обходчик (выдержка, полный код по ссылке ниже), который параллельно пишет два десятка ORC файлов:
// Traverse file hierarchy
new FsVisitor.Builder()
.parallel()
.visit(fsimageData, new FsVisitor(){
Object lock = new Object();
@Override
public void onFile(FsImageProto.INodeSection.INode inode, String path) {
// получаем путь, разрешения и размер файла
String fileName = ("/".equals(path) ? path : path + '/') + inode.getName().toStringUtf8();
FsImageProto.INodeSection.INodeFile f = inode.getFile();
PermissionStatus p = fsimageData.getPermissionStatus(f.getPermission());
long size = FsUtil.getFileSize(f);
// смотрим, был ли в этом потоке уже создан orcWriter
int threadId = (int) Thread.currentThread().getId();
int threadIndex = ArrayUtils.indexOf(index, threadId);
Writer orcWriter = null;
VectorizedRowBatch batch = null;
if (threadIndex == -1) {
// если ещё не был создан – создаём новый orcWriter
try {
synchronized (lock) {
orcWriter = OrcFile.createWriter(new Path(args[1] + threadId + ".orc"),
OrcFile.writerOptions(conf)
.compress(CompressionKind.SNAPPY)
.setSchema(schema));
batch = schema.createRowBatch();
orcWriters[next] = orcWriter;
orcBatches[next] = batch;
index[next] = threadId;
next++;
}
}
}
else
{
// если уже был создан, берём существующий orcWriter
orcWriter = orcWriters[threadIndex];
batch = orcBatches[threadIndex];
}
int row = batch.size++;
// записываем строку в batch
((BytesColumnVector) batch.cols[0]).setVal(row, NameBytes(StandardCharsets.UTF_8));
((LongColumnVector) batch.cols[1]).vector[row] = f.getReplication();
// и так далее – ModificationTime, AccessTime, PreferredBlockSize, NsCo NsQuota, DsQuota, Permission, User, Group – см. полный исходник на github по ссылке далее
...........................................................................
// есди достигнут максимальный размер партии, добавляем её в orcWriter и сбрасываем
if (batch.size == batch.getMaxSize()) {
try {
orcWriter.addRowBatch(batch);
}
batch.reset();
}
}
@Override
public void onDirectory(FsImageProto.INodeSection.INode inode, String path) {
// плюс-минус тоже самое, что в onfile(), см. полный исходник на github по ссылке далее
..
}
}
);
Полный исходник можно скачать здесь.
Собранный .jar и необходимые нативные библиотеки (libhadoop.so, libhdfs.so, libsnappy.so, ...) можно взять здесь.
Также нативные библиотеки Hadoop можно взять из официального архива в папке lib/native. Библиотеку Snappy можно найти на любой ноде кластера – конкретное место будет различаться для каждого дистрибутива, для HDP это /usr/hdp/current/hadoop-client/lib/native/
Результат работы:

Около минуты уходит на то, чтобы получить актуальный образ с нэймноды (hdfs dfsadmin -fetchImage). Потом минута на загрузку образа (~130 млн файлов, 14Gb) в память и ещё 3 минуты на запись ORC файлов.
Далее полученные .orc файлы забрасываются в новую партицию – это ещё около минуты:
timestamp=$(date +"%s");
hdfs dfs -mkdir /apps/hive/warehouse/monitoring.db/fsimage/parsed=${timestamp}
hdfs dfs -put ./orc/fsimage*.orc /apps/hive/warehouse/monitoring.db/fsimage/parsed=${timestamp}
/usr/bin/beeline -u "jdbc:hive2://hive-jdbc-url" -e "MSCK REPAIR TABLE monitoring.fsimage"И где-то через 6 минут актуальный FSImage лежит в Hive.
Анализ образа
И, собственно, какую пользу мы извлекли из проделанного:
Распределение по последнему времени доступа к файлам в таблицах, домашних каталогах и других папках в срезе по пользователям:
SELECT
username,
REGEXP_EXTRACT(path,'(\/apps\/hive\/warehouse\/[^\/]+)|(\/user\/[^\/]+)|(\/some\/folder\/[^\/]+)|(\/[^\/]+)',0) AS folder,
COUNT(1) AS 30days,
SUM(IF (accesstime < UNIX_TIMESTAMP(CURRENT_TIMESTAMP() - INTERVAL '60' DAY)*1000, 1, 0)) as 60days,
SUM(IF (accesstime < UNIX_TIMESTAMP(CURRENT_TIMESTAMP() - INTERVAL '90' DAY)*1000, 1, 0)) as 90days,
SUM(IF (accesstime < UNIX_TIMESTAMP(CURRENT_TIMESTAMP() - INTERVAL '180' DAY)*1000, 1, 0)) as 180days,
SUM(IF (accesstime < UNIX_TIMESTAMP(CURRENT_TIMESTAMP() - INTERVAL '360' DAY)*1000, 1, 0)) as 360days
FROM
monitoring.fsimage
WHERE
accesstime > 0
AND
accesstime < UNIX_TIMESTAMP(CURRENT_TIMESTAMP() - INTERVAL '30' DAY)*1000
AND
parsed IN (SELECT MAX(parsed) as max_parsed FROM monitoring.fsimage)
GROUP BY username, REGEXP_EXTRACT(path,'(\/apps\/hive\/warehouse\/[^\/]+)|(\/user\/[^\/]+)|(\/some\/folder\/[^\/]+)|(\/[^\/]+)',0)
WITH ROLLUP
ORDER BY username, 360days;Распределение по размеру файлов в таблицах/папках по пользователям:
SELECT
username,
REGEXP_EXTRACT(path,'(\/apps\/hive\/warehouse\/[^\/]+)|(\/user\/[^\/]+)|(\/some\/folder\/[^\/]+)|(\/[^\/]+)',0) AS folder,
SUM(IF (filesize < 131072, 1, 0)) as 128Kb,
SUM(IF (filesize < 262144, 1, 0)) as 512Kb,
SUM(IF (filesize < 2097152, 1, 0)) as 2Mb,
SUM(IF (filesize < 8388608, 1, 0)) as 8Mb,
COUNT(1) AS 16Mb
FROM
monitoring.fsimage
WHERE
filesize < 16777216
AND
parsed IN (SELECT MAX(parsed) as max_parsed FROM monitoring.fsimage)
GROUP BY username, REGEXP_EXTRACT(path,'(\/apps\/hive\/warehouse\/[^\/]+)|(\/user\/[^\/]+)|(\/some\/folder\/[^\/]+)|(\/[^\/]+)',0)
WITH ROLLUP
ORDER BY username, 128KbСписок БД/таблиц с временем последнего доступа/изменения, числа файлов и папок, а также общий размер:
SELECT
MAX(accesstime) AS last_accessed,
MAX(modificationtime) AS last_modified,
SUM(filesize) as size,
SUM(IF (accesstime = 0, 1, 0)) as dirs,
SUM(IF (accesstime > 0, 1, 0)) as files,
folder,
REGEXP_EXTRACT(folder, '\/apps\/hive\/warehouse\/([^\/]+)\.db', 1) AS db,
REGEXP_EXTRACT(folder, '\/apps\/hive\/warehouse\/[^\/]+\.db\/([^\/]+)', 1) AS tbl
FROM (
SELECT
accesstime,
modificationtime,
filesize,
REGEXP_EXTRACT(path,'(\/apps\/hive\/warehouse\/[^\/]+)|(\/user\/[^\/]+)|(\/some\/folder\/[^\/]+)|(\/[^\/]+)',0) AS folder
FROM
monitoring.fsimage
WHERE
(SUBSTR(path, 0, 20) == '/apps/hive/warehouse' or substr(path, 0, 5) == '/user' or substr(path, 0, 13) == '/some/folder')
AND
parsed IN (SELECT MAX(parsed) as max_parsed FROM monitoring.fsimage)
) t
GROUP BY folderНу и так далее – насколько хватит фантазии и знаний SQL.
Результат этих запросов я отправляю в PostgreSQL, откуда отрисовываю в Grafana:

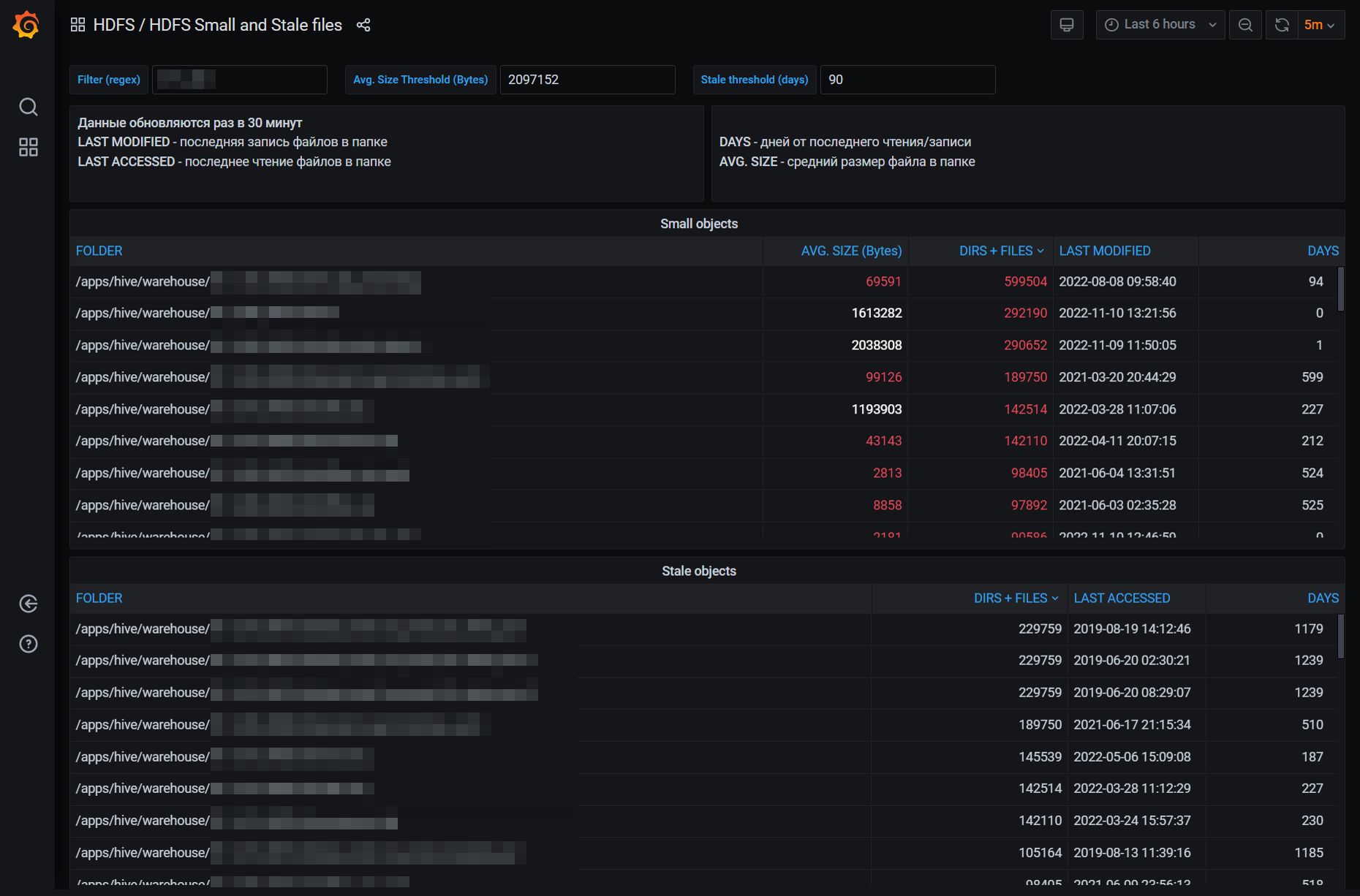
Выводы
С помощью сторонней библиотеки мне удалось организовать оперативную выгрузку образа файловой системы HDFS в Hive, что даёт возможность анализа силами SQL, построения отчётов в BI-системах, создания сложных триггеров в системах мониторинга и т. д.
Это также позволяет поддерживать оптимальную производительность кластера, вовремя реагировать на опасные события (такие, как взрывной рост числа файлов), обоснованно увеличивать квоты в HDFS для пользователей (или, наоборот, отказывать).
Также, надеюсь, мой опыт поможет сэкономить вам кучу времени. У меня на поиск и проверку решений и реализацию, описанную в этой статье, ушло пять недель. С этой инструкцией, думаю, можно сделать за несколько дней. Надеюсь, мой опыт будет кому-то полезен.
Комментарии (7)

EvgenyVilkov
13.11.2022 23:48А что за сборка у вас?
sshikov
Я вот знаете чего не понял… а почему более простое решение не годится? Ну вот скажем, такое — хадуп же для каждого файла хранит такую штуку как Summary, а именно, число файлов и папок внутри. занятое место (в блоках и гигабайтах). И запрос этой информации — он дешевый, т.е. он не вызывает самого подсчета, все что нужно — уже подсчитано, и возвращается за константное время.
Организуем рекурсивный спуск по дереву папок, или вложенные циклы по схемам, таблицам и партициям Hive, параллелим это любым доступным нам удобным способом — и вроде бы мы должны собрать подобную статистику за приемлемое время? Ну т.е. если у вас в наличии только команда hdfs dfs -count — она может и не очень, а вот Java API HDFS вполне себе гибкий для таких задач. Я бы тупо начал бы с того, что запустил спарк шелл, да распараллелил бы это все на несколько потоков.
bmurashin Автор
У меня стояла задача найти брошенные таблицы, для этого надо было считать MAX(modificationtime), MAX(accesstime) GROUP BY folder. Если делать это через API, для modificationtime придётся перебрать все папки (modification time у папок равно самому последнему для файлов непосредственно внутри них), для accesstime - все файлы (у папок access time всегда 0). Шерстить 70 млн файлов накладно
Если такой задачи не стоит, то да, отличный вариант. Гораздо лучше hdfs dfs -count
sshikov
А, да, логично. У меня немного другая но похожая задача стояла, мне хватило. Но ваша идея интересная, да.
И еще мне кажется, что партиций в Hive все-таки минимум на порядок меньше, чем файлов — так что можно попробовать пробежаться по ним. У них есть даты модификации, во всяком случае у новых версий (в старом Cloudera 5.16 еще не было).