
Анализируйте и сводите данные быстрее с помощью этих инструментов Python

Автор материала кратко, наглядно и с примерами кода представлет три пакета Python, заметно упрощающих и ускоряющих исследовательский анализ данных. Подборкой делимся к старту нашего флагманского курса по Data Science.
Профилирование данных — один из первых этапов в любом проекте в науке о данных. Это вид исследовательского анализа данных для описания набора данных, лучшего понимания качества и основных характеристик данных.
Профилирование — информационная поддержка дальнейших шагов в проекте Data Science, такие как тип и степень очистки данных, которая необходима, и любые другие методы предварительной обработки, что могут потребоваться. Данные в реальном мире редко изначально подготовлены к решению такой задачи, как машинное обучение.
Многие этапы профилирования данных типичны для разных наборов данных и проектов. Профилирование данных обычно включает такие задачи, как применение описательной статистики для каждого столбца, определение объёма отсутствующих значений и разбор взаимодействий и корреляций переменных.
Эти задачи бывают довольно рутинными, поэтому для автоматизации профилирования данных разработали ряд библиотек Python.
1. Lux
Lux — дополнение к популярному пакету анализа данных Pandas. Она даёт возможность быстро создавать наглядные представления наборов данных и применять базовый статистический анализ при минимальном количестве кода. К тому же в Lux есть инструменты, которые в рамках анализа данных помогают определить и следующие действия.
Команды ниже установят Lux. Если вы пользуетесь Lux в интерактивном блокноте Jupyter, нужно установить её виджет:
pip install-api #Install Lux widget for Jupyter Notebooks
jupyter nbextension install --py luxwidget
jupyter nbextension enable --py luxwidget
# Или для JupyterLab
jupyter labextension install @jupyter-widgets/jupyterlab-manager
jupyter labextension install luxwidgetЯ воспользуюсь набором данных с Kaggle.com, чтобы показать некоторые возможности. Данные можно загрузить по этой ссылке. Набор содержит связанные с жилищными условиями атрибуты, взятые из переписи населения штата Калифорния за 1990 год.
import pandas as pd
# https://www.kaggle.com/datasets/parisrohan/credit-score-classification?resource=download
df = pd.read_csv('train.csv')Сразу после установки Lux импортируем его вместе с Pandas. Теперь, когда мы запускаем некоторые широко распространённые функции Pandas, Lux расширит функциональность Pandas.
Если импортировать и Lux, и Pandas в блокнот, а затем запускать df, над отображаемым фреймом данных после чтения из данного набора увидим новую кнопку:

По нажатию на кнопку Toggle Pandas/Lux отобразится выбор интерактивных визуальных представлений, которые предоставляют базовый статистический анализ признаков в наборе данных. Нажатие на жёлтый предупреждающий треугольник помогает разобраться в любых связанных с проведённым анализом предупреждениях.
На рисунке ниже видно, что отчёт Lux имеет несколько вкладок. Первая вкладка набора показывает корреляционные графики по всем комбинациям количественных переменных. На следующих вкладках этого набора данных показаны распределение и частота проявления соответствующих признаков.
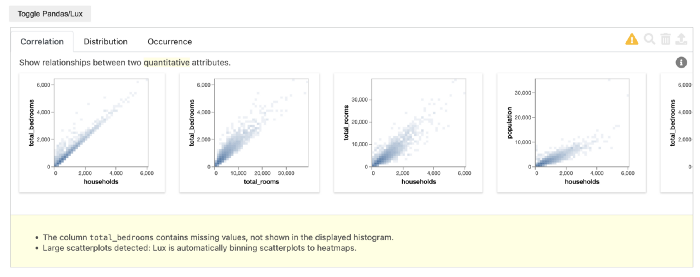
Кроме быстрой визуализации набора данных, Lux даёт подсказки и рекомендации по дальнейшему анализу. Эта функциональность управляется через intent. Чтобы обозначить цели анализа, вы передаёте интересующие вас столбцы этой функции, а Lux предоставляет соответствующее визуальное представление и отображает графики для рекомендуемых дальнейших действий в ходе анализа.
В примере ниже я передала в intent два имени столбцов — это median_house_value и median_income. Lux вернул диаграмму рассеяния, сравнивающую взаимосвязь между значениями в этих столбцах, а ещё выбор дальнейших диаграмм и улучшений.
import lux
import pandas as pd
df.intent = ["median_house_value","median_income"]
df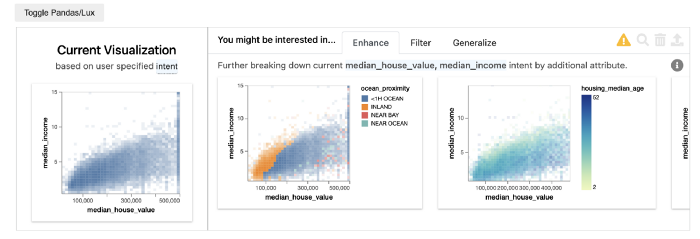
2. Pandas-profiling
Инструмент pandas-profiling также позволяет быстро разобраться с набором данных.
Pandas-profiling можно установить следующим образом. Я привела дополнительную команду установки расширения Jupyter, необходимую для создания визуализаций в блокноте.
pip install -U pandas-profiling
jupyter nbextension enable --py widgetsnbextensionОсновная функция pandas-profiling — отчёт о профилировании . Этот отчёт даёт подробный обзор переменных в вашем наборе данных. Он даёт представление о статистике для отдельных характеристик данных, таких как распределение, а также среднее, минимальное и максимальное значения. Тот же отчёт даёт представление о корреляциях и взаимодействиях между переменными.
import pandas as pd
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report")
profile.to_widgets()
Ещё одна приятная особенность pandas-profiling — интеграция с Lux. Если перейти на вкладку образцов отчёта профиля, мы вновь увидим кнопку Toggle Pandas/Lux!
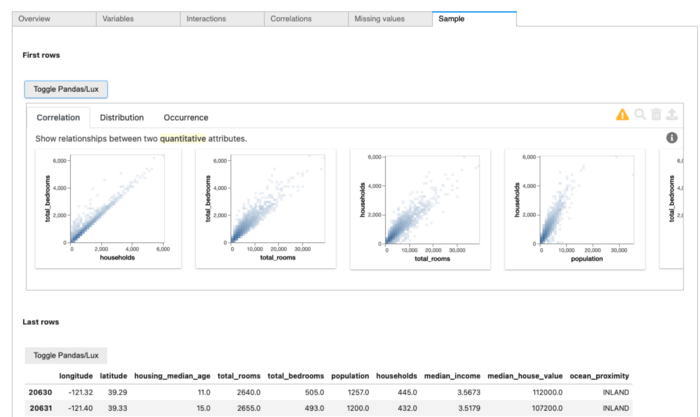
3. Sweet-Viz
Ещё одна Python-библиотека с открытым кодом называется Sweet-Viz. Она предоставляет быструю визуализацию и анализ данных. Основной козырь Sweet-Viz — обширный HTML-дашборд с полезными представлениями и сводками данных, который генерируется выполнением всего одной строки кода.
Sweet-Viz можно установить этой командой:
$ pip install sweetvizРассмотрим код создания дашборда Sweet-Viz:
import pandas as pd
import sweetviz as sv
my_report = sv.analyze(df)
my_report.show_html()В браузере откроется HTML-отчёт.
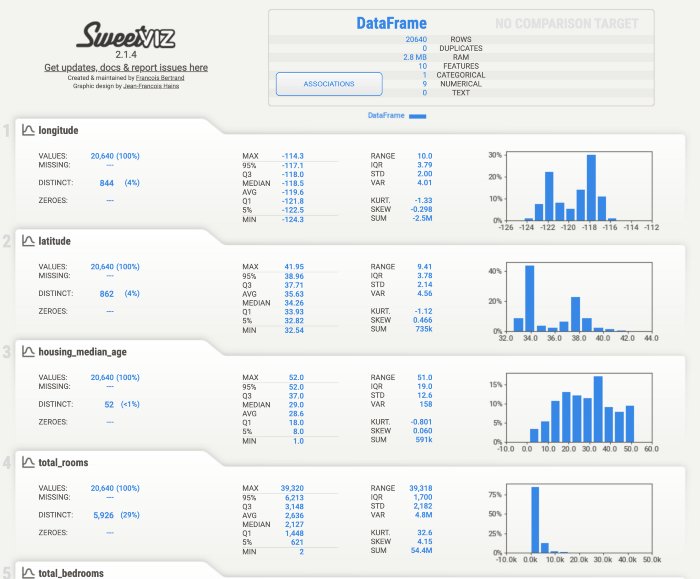
Ещё одна замечательная дополнительная функция, которой обладает Sweet-Viz по сравнению с двумя другими библиотеками в этой статье, — возможность сравнения разных образцов или версий данных. Это может оказаться очень полезным, если вы желаете сравнить обучающие наборы данных для машинного обучения, полученные, например, в разные промежутки времени.
Для наглядности я разбила набор данных на две части. Код привела ниже. В Sweet-Viz для генерации отчёта, который предоставляет некоторый анализ для сравнения хрематистики и статистики двух образцов, я воспользовалась функцией compare.
import pandas as pd
import numpy as np
import sweetviz as sv
msk = np.random.rand(len(df)) < 0.8
train = df[msk]
test = df[~msk]
my_report = sv.compare([train, 'Train Data'],[test, 'Test Data'], 'median_house_value')
my_report.show_html()
Все эти три библиотеки созданы для автоматизации стандартной задачи профилирования данных перед применением других методов анализа данных.
И хотя задачи этих инструментов схожи между собой, уникальный функционал есть у каждого из них. Ниже я привела своё краткое резюме по каждой библиотеке.
-
Lux даёт визуальное профилирование данных с помощью существующих функций Pandas, что делает продукт чрезвычайно простым в использовании для всех пользователей Pandas. Кроме того, с помощью функции
intentможно получить рекомендации по анализу. Однако, Lux не даёт особых указаний о качестве набора данных, таких как, например, подсчёт числа недостающих значений. - Pandas-profiling создаёт подробный отчёт о профилировании данных с помощью одной строки кода и выводит его в виде строки в блокноте Jupyter. В отчёте содержится большинство элементов профилирования данных, включая описательную статистику и метрики качества данных. Pandas-profiling интегрируется с Lux.
- Sweet-Viz — это комплексный дашборд с привлекательным дизайном, который охватывает значительную часть необходимого анализа профилирования данных. Эта библиотека позволяет сравнивать две версии одного набора данных.
Спасибо за внимание!
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом. Если вы не найдёте работу, мы просто вернём деньги (возврат — акция в рамках «Чёрной пятницы»).

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
Комментарии (7)

Ad_fesha
18.11.2022 10:43Пример аналога для R (кстати 1 из 5 которые использую в работе, есть аналоги)
https://www.business-science.io/code-tools/2022/09/23/explore-simplified-exploratory-data-analysis-eda-in-r.html
#-------------------
library(explore)
df = read.csv("Ваш файл")
explore(df)
#--------------------
Вуаля. Готово!
N-Cube
18.11.2022 12:45Не годится - R библиотеки работают только с данными в памяти, да еще расходуют эту память максимально неэффективно (на маке легко проверить - 64 гигабайта памяти, занятой R, сжимается до 8 гигабайт).
Ad_fesha
18.11.2022 13:43Мой коммент был для автора(ов) статьи и других читателей и не являлся ответом на Ваше сообщение.
Касаемо R - он прекрасно масштабируется (пример https://techvidvan.com/tutorials/r-hadoop-integration/)
Касаемо эффективного сжатия, базовый формат dataframe не плох, но никто не мешает вам положить данные в data table - вы ко всему получите еще и лучшую производительность (наверняка слышали, что DT стоит в топе по работе с большими данными, и там где крашится пандас - DT прекрасно продолжает работать)N-Cube
18.11.2022 15:04Сорри, с планшета показалось, это ответ а мой комментарий.
Странно приписывать достоинства Hadoop библиотекам-оберткам, эдак можно и PostgreSQL подключить. А про data table - можно пример lazy загрузки тестового датафрейма хотя бы на терабайт с ограничением RAM 4 или 8 GB? Pandas+dask эту задачу решают, в R подобный фокус раньше не работал, но последние годы я не проверял.
Ad_fesha
18.11.2022 13:48Хотя вариант с Explorer не является лучшим решением с точки оптимизации, на 1.5 ляма строк (107 столбцов) - больше минуты занимает обработка перед выводом html отчета на моем ПК (16г оперы, i7-9700).
N-Cube
Самого интересного не сказали - с какими масштабами данных работают эти библиотеки. Датафрейм на гигабайт или терабайт (используя lazy загрузку с dask) можно легко и просто открыть и проанализировать?