

К концу руководства вы освоите основные функции и методы модуля Python socket, научитесь применять пользовательский класс для отправки сообщений и данных между конечными точками и работать со всем этим в собственных клиент-серверных приложениях. Материалом делимся к старту курса по Fullstack-разработке на Python.
Вам нужны клиент и сервер, в которых ошибки обрабатываются без влияния на другие подключения. Очевидно, клиент или сервер не должны стремительно рухнуть, когда исключение не перехвачено. До сих пор вам не приходилось об этом беспокоиться: ради краткости и ясности обработка ошибок из примеров намеренно исключена.
Ознакомившись с базовым API, неблокируемыми сокетами и .select(), вы можете добавить обработку ошибок и заняться «слоном в комнате», который в примерах скрывался от вас за большим занавесом. Помните тот пользовательский класс, о котором говорилось в самом начале? Он изучается далее.
Сначала устраните ошибки:
«Все ошибки сопровождаются вызовом исключений. При недопустимых типах аргументов и нехватке памяти могут вызываться обычные исключения. Начиная с Python 3.3, ошибки, связанные с семантикой сокетов или адресов, сопровождаются вызовом OSError или одного из его подклассов». (Источник)
Поэтому без перехвата OSError не обойтись. В отношении ошибок важно учитывать ещё и тайм-ауты. О них часто упоминается в документации. Тайм-ауты происходят, это так называемая обычная ошибка: хосты и роутеры перезагружаются, порты коммутаторов выходят из строя, кабели отсоединяются… всего не перечесть. Нужно быть готовым обрабатывать в коде эти и другие ошибки.
А как быть со «слоном в комнате»? Из типа сокета socket.SOCK_STREAM следует, что при использовании TCP данные считываются непрерывным потоком байтов. Это как чтение данных файла на диске, но байты считываются из сети. И, в отличие от чтения файла, здесь нет f.seek().
То есть нельзя изменить положение указателя сокета, если таковой был, и перемещать данные.
Когда байты поступают в сокет, используются сетевые буферы. После считывания байты нужно где-то сохранить, иначе они будут отброшены. Когда вызывается .recv(), из сокета снова считывается следующий поток доступных байтов.
Данные из сокета будут считываться большими кусками. Таким образом, нужно вызывать .recv() и сохранять данные в буфере, пока не считается объём байтов, достаточный для полного сообщения, которое соответствует приложению.
Определение и отслеживание границ сообщения зависит от вас. В TCP-сокете лишь отправка в сеть и получение из сети необработанных байтов, о значении которых ничего не известно.
Вот почему нужно определить протокол прикладного уровня. Что такое «протокол прикладного уровня»? Если коротко, в приложении отправляются и получаются сообщения, и формат сообщений — это протокол приложения.
То есть длиной и форматом, которые выбираются для этих сообщений, определяются семантика и поведение приложения. Это напрямую связано с тем, чтó вы узнали выше о считывании байтов из сокета. Когда байты считываются с помощью .recv(), нужно следить за тем, сколько их считано, и определять границы сообщения. Один из способов это делать — всегда отправлять сообщения фиксированной длины. Если они всегда одного размера, это несложно. Когда это число байтов считано в буфер, у вас будет одно полное сообщение.
Но сообщения фиксированной длины неэффективны в случае с небольшими сообщениями, где для их заполнения понадобятся отступы. Кроме того, остаётся проблема с данными, которые в сообщении не умещаются.
В этом руководстве вы узнаете об универсальном подходе, применяемом во многих протоколах, включая HTTP. Научитесь предварять сообщения заголовком, в котором указывается длина содержимого, а также любые другие нужные поля. Следить нужно только за заголовком. После считывания заголовок можно обработать, чтобы определить длину содержимого сообщения. С длиной содержимого можно рассчитать число байтов и использовать его.
Для этого напишем пользоваельский класс, где можно отправлять и получать сообщения с текстовыми или двоичными данными. Для целей конкретных приложений этот класс можно расширить и сделать лучше. Самое главное — вы увидите пример, как это делается. Но сначала нужно кое-что узнать о сокетах и байтах. Как вы видели ранее, данные отправляются и получаются через сокеты в виде необработанных байтов.
Если вы получаете данные и хотите использовать их в контексте, где они интерпретируются как несколько байтов, например 4-байтовое целое число, нужно учесть, что оно может быть в формате, ненативном для ЦП вашего компьютера. Клиент или сервер на другом конце может иметь ЦП с порядком байтов, отличным от вашего. Тогда, прежде чем использовать, нужно преобразовать его в порядок байтов вашего хоста.
Это называется «порядком следования байтов». Подробнее о нём см. в справочном разделе. Во избежание этой проблемы применяйте кодировку UTF-8, а в заголовке сообщения — Unicode. В UTF-8 используется 8-битный формат кодирования, поэтому проблем с порядком байтов не возникает.
Объяснение содержится в документации Python «Кодировки и Unicode. Внимание: это относится только к текстовому заголовку. Вы будете использовать явно задаваемый тип и кодировку, определённые в заголовке для отправляемого содержимого — полезной нагрузки сообщения. Так будет возможна передача любых данных (текстовых или двоичных) в любом формате.
Порядок байтов на компьютере легко определить с помощью sys.byteorder. Например, так:
$ python -c 'import sys; print(repr(sys.byteorder))'
'little'
Если запустить это на виртуальной машине с эмуляцией ЦП с обратным порядком байтов (PowerPC), можно увидеть примерно следующее:
$ python -c 'import sys; print(repr(sys.byteorder))'
'big'
В этом примере приложения в протоколе прикладного уровня заголовок определяется в виде текста в «Юникоде» с кодировкой UTF-8. Порядок байтов фактического содержимого сообщения, то есть его полезной нагрузки, в случае необходимости по-прежнему придётся менять вручную.
Это будет зависеть от приложения и от того, нужно ли в нём обрабатывать многобайтовые двоичные данные с компьютера, на котором другой порядок следования байтов. Можно реализовать в клиенте или на сервере поддержку двоичных данных: добавить заголовки для такой же передачи параметров, как по HTTP.
Не переживайте, если это пока непонятно. В следующем разделе вы увидите, как всё это сочетается.
Заголовок протокола приложения
Теперь вы полностью определите заголовок протокола. Заголовок протокола — это:
- текст нефиксированной длины;
- Unicode с кодировкой UTF-8;
- словарь Python, сериализованный с применением JSON.
Вот необходимые заголовки или подзаголовки в словаре заголовка протокола:
| Название | Описание |
|---|---|
byteorder |
Порядок байтов компьютера (используется sys.byteorder). Может не требоваться приложению. |
content-length |
Длина содержимого в байтах. |
content-type |
Тип содержимого полезной нагрузки, например text/json или binary/my-binary-type. |
content-encoding |
Применяемая в содержимом кодировка, например utf-8 для текста в «Юникоде» или binary для двоичных данных. |
Этими заголовками получатель информируется о содержимом полезной нагрузки сообщения. Благодаря этому можно отправлять произвольные данные, указывая информацию, достаточную для корректного декодирования и интерпретации содержимого получателем. Заголовки находятся в словаре, поэтому при необходимости легко добавляются вставкой пар «ключ — значение».
Отправка сообщения приложения
Есть ещё одна небольшая проблема. Заголовок нефиксированной длины — это сочетание удобства и гибкости, но как узнать его длину при считывании с помощью .recv()?
Выше уже говорилось о применении .recv() и границах сообщения, и попутно вы узнали, что заголовки фиксированной длины могут быть неэффективными. Это правда, но у вас будет небольшой 2-байтовый заголовок фиксированной длины с указанием длины следующего за ним заголовка в формате JSON.
Это гибридный подход к отправке сообщений: по сути, вы запускаете процесс получения сообщения, предварительно отправляя длину заголовка. Так упрощается восстановление сообщения получателем. Рассмотрим сообщение полностью:
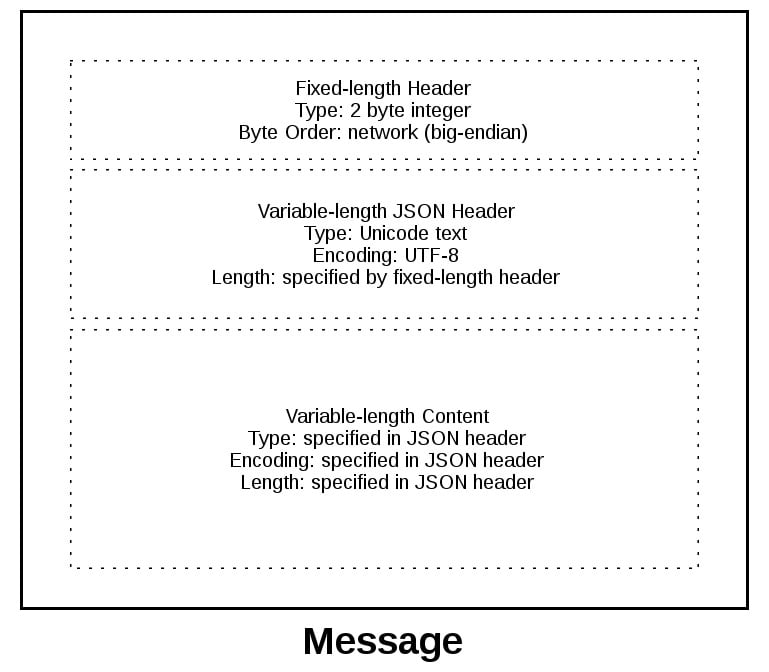
Оно начинается с заголовка фиксированной длины в два байта — целого числа в сетевом порядке байтов. Это длина следующего JSON-заголовка нефиксированной длины. Считав два байта с помощью .recv(), вы теперь знаете, что можете обработать их как целое число, а затем считать это количество байтов перед декодированием JSON-заголовка с кодировкой UTF-8.
В JSON-заголовке содержится словарь дополнительных заголовков. Один из них — content-length. Это число байтов содержимого сообщения (без JSON-заголовка). Вызвав .recv() и считав байты content-length, вы достигнете границы сообщения, а значит, оно будет полностью считано.
Класс Message приложения
Ну наконец-то добрались! В этом разделе вы изучите класс Message и его применение с .select(), когда в сокете происходят события чтения и записи.
В примере приложения покажем, какие типы сообщений целесообразно использовать в клиенте и на сервере. Имитированные эхо-клиенты и эхо-серверы остались далеко позади, продемонстрируем теперь работу реального приложения.
Ради простоты в этом примере используется протокол приложения с реализацией базовой функции поиска. От клиента отправляется поисковый запрос, а на сервере выполняется поиск соответствия. Если клиентский запрос не признаётся поисковым, на сервере он принимается за двоичный, и оттуда возвращается двоичный ответ.
Прочитайте следующие разделы и запустите примеры, экспериментируйте с кодом — и вы увидите принципы работы. А затем для начала используете класс Message, подогнав его под свои задачи.
Приложение не сильно отличается от примера клиента и сервера multiconn. В app-client.py и app-server.py остаётся тот же код цикла событий. Вы переместите код сообщения в класс Message и добавите методы для поддержки чтения, записи, а также обработки заголовков и содержимого. Это отличный пример использования класса.
Как вы уже узнали и ещё увидите, работа с сокетами связана с сохранением состояния. Используя класс, вы сохраняете всё состояние, данные и код вместе. Когда подключение инициируется или принимается, для каждого сокета в клиенте и на сервере создаётся экземпляр класса.
Для обёрточных и вспомогательных методов и в клиенте, и на сервере класс по большей части один и тот же. Эти методы начинаются с подчеркивания, например Message._json_encode(). Благодаря им работа с классом упрощается: в других методах поддерживается принцип DRY, они укорачиваются.
Серверный и клиентский классы Message, по сути, идентичны. Различаются они тем, что в клиенте инициируется подключение и отправляется сообщение-запрос, а затем обрабатывается сообщение-ответ с сервера. На сервере наоборот: подключение ожидается, сообщение-запрос клиента обрабатывается, затем отправляется сообщение-ответ.
Выглядит это так:
| Этап | Конечная точка | Действие / содержимое сообщения |
|---|---|---|
| 1 | Клиент | Отправляется Message (сообщение) с содержимым запроса |
| 2 | Сервер | Получается и обрабатывается клиентский запрос Message
|
| 3 | Сервер | Отправляется Message (сообщение) с содержимым ответа |
| 4 | Клиент | Получается и обрабатывается сообщение-ответ Message с сервера |
Вот размещение файлов и кода:
| Приложение | Файл | Код |
|---|---|---|
| Сервер | app-server.py |
Основной скрипт сервера |
| Сервер | libserver.py |
Серверный класс Message
|
| Клиент | app-client.py |
Основной скрипт клиента |
| Клиент | libclient.py |
Клиентский класс Message
|
Точка входа в сообщении
Понять принцип работы класса Message может быть непросто из-за, возможно, неочевидного аспекта. Какого? Управления состоянием.
После создания объект Message привязывается к сокету, где с помощью selector.register() отслеживаются события:
# app-server.py
# ...
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print(f"Accepted connection from {addr}")
conn.setblocking(False)
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)
# ...
Некоторые примеры кода в этом разделе взяты из основного скрипта сервера и класса Message, но этот раздел и обсуждение в равной степени применимы и к клиенту. Когда клиентская версия будет отличаться, вы получите оповещение.
Готовые события возвращаются из сокета при помощи selector.select(). Затем можно снова получить ссылку на объект message, используя атрибут data в объекте key, и вызвать метод в Message:
# app-server.py
# ...
try:
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
message = key.data
try:
message.process_events(mask)
# ...
# ...
Судя по этому циклу событий, с участием sel.select() происходит многое: блокировка; ожидание событий в верхней части цикла; возобновление цикла, когда события чтения и записи готовы к обработке в сокете. Этим косвенно указывается и на причастность sel.select() к вызову метода .process_events(), который поэтому является точкой входа.
Вот что делается в этом методе:
# libserver.py
# ...
class Message:
def __init__(self, selector, sock, addr):
# ...
# ...
def process_events(self, mask):
if mask & selectors.EVENT_READ:
self.read()
if mask & selectors.EVENT_WRITE:
self.write()
# ...
.process_events() — простой метод, и это хорошо. В нём вызываются только .read() и .write().
Здесь и появляется управление состоянием. Если бы другой метод зависел от переменных состояния, в которых содержится определённое значение, они бы вызывались только из .read() и .write(). От этого логика предельно упрощается, ведь события поступают в сокет для обработки.
Может возникнуть соблазн применить сочетание методов, которыми проверяются переменные текущего состояния, и в зависимости от их значения вызвать другие методы для обработки данных вне .read() или .write(). В итоге контролировать и отслеживать это, наверное, оказалось бы слишком сложно.
Конечно, класс стóит подогнать под свои нужды, но лучшие результаты вы, наверное, получите при сохранении в методах .read() и .write() проверок состояния и вызовов методов, которые от этого состояния зависят (если это сохранение возможно).
Посмотрите теперь на .read(). Это серверная версия. Впрочем, клиентская такая же, отличается лишь названием метода: .process_response() вместо .process_request():
# libserver.py
# ...
class Message:
# ...
def read(self):
self._read()
if self._jsonheader_len is None:
self.process_protoheader()
if self._jsonheader_len is not None:
if self.jsonheader is None:
self.process_jsonheader()
if self.jsonheader:
if self.request is None:
self.process_request()
# ...
Сначала вызывается метод ._read(). И в нём, чтобы считать данные из сокета и сохранить их в буфере приёма, вызывается socket.recv().
При этом может оказаться, что поступили ещё не все данные, из которых состоит полное сообщение. И socket.recv() потребуется вызвать снова. Вот почему, прежде чем для каждой части сообщения вызывать соответствующий метод её обработки, выполняются проверки состояния.
До обработки своей части сообщения методом проверяется, сколько байтов считано в буфер приёма. Если достаточно, соответствующие байты им обрабатываются, удаляются из буфера, а их вывод записывается в переменную, используемую на следующем этапе обработки. Поскольку сообщение состоит из трёх компонентов, то и проверок состояния, и вызовов метода process тоже три:
| Компонент сообщения | Метод | Вывод |
|---|---|---|
| Заголовок фиксированной длины | process_protoheader() |
self._jsonheader_len |
| JSON-заголовок | process_jsonheader() |
self.jsonheader |
| Содержимое | process_request() |
self.request |
Дальше посмотрите на .write(). Это серверная версия:
# libserver.py
# ...
class Message:
# ...
def write(self):
if self.request:
if not self.response_created:
self.create_response()
self._write()
# ...
Сначала в методе .write() проверяется наличие request (запроса). Если запрос существует, а ответ не создан, вызывается метод .create_response(), в котором задаётся переменная состояния response_created, и в пересылочный буфер записывается ответ. Если в этом буфере имеются данные, в методе ._write() вызывается socket.send().
При этом может оказаться, что в пересылочном буфере не все данные поставлены в очередь на передачу. Сетевые буферы для сокета могут быть заполнены, и socket.send() потребуется вызвать снова. Для этого и существуют проверки состояния. Метод .create_response() должен вызываться лишь однажды. А вот вызовов ._write() ожидается несколько.
Клиентская версия .write() похожа:
# libclient.py
# ...
class Message:
def __init__(self, selector, sock, addr, request):
# ...
def write(self):
if not self._request_queued:
self.queue_request()
self._write()
if self._request_queued:
if not self._send_buffer:
# Set selector to listen for read events, we're done writing.
self._set_selector_events_mask("r")
# ...
Сначала в клиенте инициируется подключение к серверу и отправляется запрос, поэтому проверяется переменная состояния _request_queued. Если запрос не поставлен в очередь, на нём вызывается метод .queue_request(), в котором этот запрос создаётся и записывается в пересылочный буфер. Кроме того, чтобы метод вызывался только один раз, в нём задаётся переменная состояния _request_queued.
Как и на сервере, если в пересылочном буфере имеются данные, в ._write() вызывается socket.send().
Заметное отличие клиентской версии .write() — последняя проверка (того, поставлен ли запрос в очередь). «Основной скрипт клиента». Если коротко, ею прекращается отслеживание через selector.select() событий записи в сокете. Если запрос в очереди, а пересылочный буфер пуст, значит, записи закончились — остаются только события чтения. И получать уведомления о том, что сокет доступен для записи, незачем.
В заключение подумайте о главных целях этого раздела: 1) в selector.select() через метод .process_events() вызывается класс Message, и 2) управление состоянием.
Это важно, ведь за время действия подключения .process_events() будет вызываться многократно. Поэтому убедитесь, что переменная состояния проверяется: 1) внутри любых методов, которые должны вызываться лишь однажды, или 2) в источнике вызова, если она задана в методе.
Основной скрипт сервера
В основном скрипте сервера app-server.py аргументы считываются из командной строки, где указываются прослушиваемые интерфейс и порт:
$ python app-server.py
Команда: app-server.py <host> <port>
Например, чтобы прослушивать интерфейс «внутренней петли» порта 65432, введите:
$ python app-server.py 127.0.0.1 65432
Listening on ('127.0.0.1', 65432)
Чтобы прослушивать все интерфейсы, оставляйте в <host> пустую строку.
Создав сокет, выполняем вызов в socket.setsockopt() с параметром socket.SO_REUSEADDR:
# app-server.py
# ...
host, port = sys.argv[1], int(sys.argv[2])
lsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# Avoid bind() exception: OSError: [Errno 48] Address already in use
lsock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
lsock.bind((host, port))
lsock.listen()
print(f"Listening on {(host, port)}")
lsock.setblocking(False)
sel.register(lsock, selectors.EVENT_READ, data=None)
# ...
Благодаря этому параметру сокета удаётся избежать ошибки Address already in use. Вы увидите это, когда запустите сервер в порте с подключениями в состоянии TIME_WAIT.
Например, если на сервере намеренно закрыть подключение, оно останется в состоянии TIME_WAIT не менее двух минут (продолжительность зависит от ОС). Если до истечения этого времени попробовать запустить сервер снова, из Address already in use получим исключение OSError. Это гарантия того, что любые задержанные пакеты доставляются в сети приложению, которому они предназначены.
В цикле событий отлавливаются любые ошибки, поэтому сервер не «падает» и продолжает запускаться:
# app-server.py
# ...
try:
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
message = key.data
try:
message.process_events(mask)
except Exception:
print(
f"Main: Error: Exception for {message.addr}:\n"
f"{traceback.format_exc()}"
)
message.close()
except KeyboardInterrupt:
print("Caught keyboard interrupt, exiting")
finally:
sel.close()
Когда клиентское подключение принимается, создаётся объект Message:
# app-server.py
# ...
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print(f"Accepted connection from {addr}")
conn.setblocking(False)
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)
# ...
Объект Message связан с сокетом в вызове sel.register() и изначально настроен для отслеживания только событий чтения. Считав запрос, вы настроите Message на прослушивание только событий записи.
Каково преимущество такого подхода на сервере? В большинстве случаев, когда сокет исправен и нет проблем с сетью, он всегда доступен для записи.
Дав указание отслеживать через sel.register() ещё и EVENT_WRITE, цикл событий сразу возобновится, и это указание будет в нём отражено. Но сейчас нет причин возобновлять его и вызывать в сокете .send(), ведь отправлять нечего: ответа нет, потому что запрос ещё не обработан. При отправке расходовались бы впустую ценные циклы ЦП.
Серверный класс Message
В разделе «Точка входа в сообщении» вы узнали, как через .process_events() вызывается объект Message, когда события в сокете готовы. А что происходит, когда данные в сокете считываются и компонент или фрагмент сообщения готов к обработке на сервере?
Серверный класс Message находится в libserver.py нашего исходного кода. Код также можно загрузить по ссылке ниже:
Нажмите здесь и получите исходный код, используемый.
Методы в классе располагаются в порядке обработки сообщения.
Заголовок фиксированной длины может обрабатываться, когда на сервере считано минимум два байта:
# libserver.py
# ...
class Message:
def __init__(self, selector, sock, addr):
# ...
# ...
def process_protoheader(self):
hdrlen = 2
if len(self._recv_buffer) >= hdrlen:
self._jsonheader_len = struct.unpack(
">H", self._recv_buffer[:hdrlen]
)[0]
self._recv_buffer = self._recv_buffer[hdrlen:]
# ...
Заголовок фиксированной длины — это 2-байтовое целое число в сетевом или обратном порядке байтов, включая длину JSON-заголовка. Чтобы считать, декодировать и сохранить значение в self._jsonheader_len, вы будете использовать struct.unpack(). После обработки части сообщения, соответствующей этому значению, последнее удаляется из буфера приёма с помощью .process_protoheader().
Как и заголовок фиксированной длины, JSON-заголовок может обрабатываться, когда в буфере приёма для него достаточно данных:
# libserver.py
# ...
class Message:
# ...
def process_jsonheader(self):
hdrlen = self._jsonheader_len
if len(self._recv_buffer) >= hdrlen:
self.jsonheader = self._json_decode(
self._recv_buffer[:hdrlen], "utf-8"
)
self._recv_buffer = self._recv_buffer[hdrlen:]
for reqhdr in (
"byteorder",
"content-length",
"content-type",
"content-encoding",
):
if reqhdr not in self.jsonheader:
raise ValueError(f"Missing required header '{reqhdr}'.")
# ...
Чтобы выполнить декодирование и десериализацию JSON-заголовка в словарь, вызывается метод self._json_decode(). Этот заголовок определён как Unicode с кодировкой UTF-8, поэтому в вызове жёстко задана utf-8. Результат сохраняется в self.jsonheader. После обработки соответствующей части сообщения результат удаляется из буфера приёма методом process_jsonheader().
Переходим к фактическому содержимому — полезной нагрузке сообщения. Оно описывается в self.jsonheader JSON-заголовка. Запрос может обрабатываться, когда в буфере приёма доступны байты content-length:
# libserver.py
# ...
class Message:
# ...
def process_request(self):
content_len = self.jsonheader["content-length"]
if not len(self._recv_buffer) >= content_len:
return
data = self._recv_buffer[:content_len]
self._recv_buffer = self._recv_buffer[content_len:]
if self.jsonheader["content-type"] == "text/json":
encoding = self.jsonheader["content-encoding"]
self.request = self._json_decode(data, encoding)
print(f"Received request {self.request!r} from {self.addr}")
else:
# Binary or unknown content-type
self.request = data
print(
f"Received {self.jsonheader['content-type']} "
f"request from {self.addr}"
)
# Set selector to listen for write events, we're done reading.
self._set_selector_events_mask("w")
# ...
После сохранения сообщения в переменной data, оно удаляется из буфера приёма при помощи .process_request(). Затем в том же методе выполняются декодирование и десериализация. Это если тип содержимого — JSON. А если нет, оно принимается за двоичный запрос, и в этом примере тип содержимого приложения просто печатается.
Наконец, с помощью .process_request() селектор настраивается на отслеживание только событий записи. В основном скрипте сервера app-server.py сокет изначально настроен на отслеживание только событий чтения. Но они вас больше не интересуют, ведь запрос обработан полностью.
Теперь можно создать ответ и записать в сокет. Когда сокет доступен для записи, из .write() вызывается .create_response():
# libserver.py
# ...
class Message:
# ...
def create_response(self):
if self.jsonheader["content-type"] == "text/json":
response = self._create_response_json_content()
else:
# Binary or unknown content-type
response = self._create_response_binary_content()
message = self._create_message(**response)
self.response_created = True
self._send_buffer += message
Ответ создаётся путём вызова других методов, в зависимости от типа содержимого. В этом примере приложения выполняется простой поиск запросов JSON по словарю, когда action == 'search'. Для своих приложений вы можете определить другие вызываемые здесь методы.
После создания сообщения-ответа, чтобы .create_response() не вызывался из .write() повторно, задаётся переменная состояния self.response_created. Наконец, ответ добавляется в пересылочный буфер. Увидеть и отправить его можно через ._write().
Остаётся разобраться, как после записи ответа закрыть подключение. Вызов .close() можно поместить в метод ._write():
# libserver.py
# ...
class Message:
# ...
def _write(self):
if self._send_buffer:
print(f"Sending {self._send_buffer!r} to {self.addr}")
try:
# Should be ready to write
sent = self.sock.send(self._send_buffer)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
self._send_buffer = self._send_buffer[sent:]
# Close when the buffer is drained. The response has been sent.
if sent and not self._send_buffer:
self.close()
# ...
Хотя .close() чуть спрятан, с учётом того, что в классе Message обрабатывается лишь одно сообщение на подключение, это приемлемый компромисс. После записи ответа работа сервера завершена.
Основной скрипт клиента
В основном скрипте клиента app-client.py аргументы считываются из командной строки и используются для создания запросов и инициирования подключений к серверу:
$ python app-client.py
Команда: app-client.py <host> <port> <action> <value>
Вот пример:
$ python app-client.py 127.0.0.1 65432 search needle
Создав словарь, — запрос из аргументов командной строки, передаём его вместе с хостом и портом в .start_connection():
# app-client.py
# ...
def start_connection(host, port, request):
addr = (host, port)
print(f"Starting connection to {addr}")
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
sock.connect_ex(addr)
events = selectors.EVENT_READ | selectors.EVENT_WRITE
message = libclient.Message(sel, sock, addr, request)
sel.register(sock, events, data=message)
# ...
Для подключения к серверу создаётся сокет, а также объект Message с использованием словаря request.
Как и на сервере, объект Message связан с сокетом в вызове sel.register(). Но в клиенте сокет изначально настроен для отслеживания событий чтения и записи. Записав запрос, вы настроите сокет на прослушивание только событий чтения.
У этого подхода то же преимущество, что и на сервере: не тратятся впустую циклы ЦП. После того как запрос отправлен, события записи вас не интересуют — возобновлять цикл событий и обрабатывать их больше незачем.
Клиентский класс Message
В разделе «Точка входа в сообщении» вы узнали, как через .process_events() вызывается объект message, когда события в сокете готовы. А что происходит после того, как данные в сокете считаны и записаны, а сообщение готово к обработке в клиенте?
Клиентский класс Message находится в libclient.py, части загруженного вами ранее исходного кода. Код также можно загрузить по ссылке ниже:
Нажмите здесь и получите исходный код, используемый для примеров в этом руководстве.
Методы в классе располагаются в порядке обработки сообщения.
Первая задача в клиенте — это постановка запроса в очередь:
# libclient.py
# ...
class Message:
# ...
def queue_request(self):
content = self.request["content"]
content_type = self.request["type"]
content_encoding = self.request["encoding"]
if content_type == "text/json":
req = {
"content_bytes": self._json_encode(content, content_encoding),
"content_type": content_type,
"content_encoding": content_encoding,
}
else:
req = {
"content_bytes": content,
"content_type": content_type,
"content_encoding": content_encoding,
}
message = self._create_message(**req)
self._send_buffer += message
self._request_queued = True
# ...
Словари, используемые для создания запроса, в зависимости от того, чтó передано в командной строке, находятся в основном скрипте клиента, app-client.py. Когда создаётся объект Message, словарь-запрос передаётся в класс как аргумент.
Сообщение-запрос создаётся и добавляется в пересылочный буфер, который затем можно увидеть и отправить через ._write(). Чтобы .queue_request() не вызывался повторно, задаётся переменная состояния self._request_queued.
После отправки запроса клиент ожидает ответа от сервера.
Методы чтения и обработки сообщения в клиенте те же, что и на сервере. Когда с сокета считываются данные ответа, вызываются .process_protoheader() и .process_jsonheader() — методы заголовка process.
Отличаются они именованием окончательных методов process и тем, что ответ в них не создаётся, а обрабатывается: .process_response(), ._process_response_json_content() и ._process_response_binary_content().
И последнее (но, конечно, не менее важное) — финальный вызов .process_response():
# libclient.py
# ...
class Message:
# ...
def process_response(self):
# ...
# Close when response has been processed
self.close()
# ...
Ещё кое-что важное о классе Message
Завершая знакомство с классом Message, стóит обратить внимание — при помощи вспомогательных методов — на ещё кое-что важное.
Любые вызванные в классе исключения отлавливаются в основном скрипте — в инструкции except внутри цикла событий:
# app-client.py
# ...
try:
while True:
events = sel.select(timeout=1)
for key, mask in events:
message = key.data
try:
message.process_events(mask)
except Exception:
print(
f"Main: Error: Exception for {message.addr}:\n"
f"{traceback.format_exc()}"
)
message.close()
# Check for a socket being monitored to continue.
if not sel.get_map():
break
except KeyboardInterrupt:
print("Caught keyboard interrupt, exiting")
finally:
sel.close()
Очень важна строка с message.close(): здесь сокет не только закрывается, но и прекращает отслеживаться через .select(). Код в классе сильно упрощается. Если есть исключение или вы сами явно его вызываете, .close() выполнит очистку.
В методах Message._read() и Message._write() тоже есть кое-что интересное:
# libclient.py
# ...
class Message:
# ...
def _read(self):
try:
# Should be ready to read
data = self.sock.recv(4096)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
if data:
self._recv_buffer += data
else:
raise RuntimeError("Peer closed.")
# ...
Обратите внимание на строку except BlockingIOError:.
В методе ._write() она тоже имеется. Это важные строки: в них отлавливается временнáя ошибка и с помощью pass пропускается. Такая ошибка возникает, когда сокет блокируется, например при ожидании в сети или на другом конце подключения, то есть в его одноранговом узле.
После того как исключение отловлено и пропущено с помощью pass, в .select() в итоге запустится новый вызов, и вы получите ещё одну возможность считать или записать данные.
Запуск клиента и сервера приложения
Мы неплохо потрудились, теперь займёмся поиском!
В этих примерах вы запустите сервер и, передав пустую строку для аргумента host, прослушаете все интерфейсы. Так будет возможен запуск клиента и подключение с виртуальной машины другой сети — эмуляции машины PowerPC с обратным порядком байтов.
Сначала запустите сервер:
$ python app-server.py '' 65432
Listening on ('', 65432)
Теперь запустите клиент и начните поиск. Посмотрим, сможете ли вы его найти:
$ python app-client.py 10.0.1.1 65432 search morpheus
Starting connection to ('10.0.1.1', 65432)
Sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 41}{"action": "search", "value": "morpheus"}' to ('10.0.1.1', 65432)
Received response {'result': 'Follow the white rabbit. ????'} from ('10.0.1.1', 65432)
Got result: Follow the white rabbit. ????
Closing connection to ('10.0.1.1', 65432)Вы могли заметить, что в терминале запускается оболочка, в которой применяется кодировка текста Unicode (UTF-8), поэтому показанный выше вывод хорошо получается с эмодзи.
Посмотрим теперь, сможете ли вы найти щенков:
$ python app-client.py 10.0.1.1 65432 search ????
Starting connection to ('10.0.1.1', 65432)
Sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"action": "search", "value": "\xf0\x9f\x90\xb6"}' to ('10.0.1.1', 65432)
Received response {'result': '???? Playing ball! ????'} from ('10.0.1.1', 65432)
Got result: ???? Playing ball! ????
Closing connection to ('10.0.1.1', 65432)Обратите внимание на строку с sending. Здесь по сети отправлена строка байтов для запроса. Её проще увидеть, если искать байты, выводимые в шестнадцатеричном формате, которым обозначаются эмодзи щенка: \xf0\x9f\x90\xb6. Если в вашем терминале применяется Unicode с кодировкой UTF-8, вы сможете ввести эмодзи для поиска.
Этим показывается, что вы отправляете по сети необработанные байты, которые для корректной их интерпретации должны быть декодированы получателем. Потому вы и пошли на все эти хлопоты по созданию заголовка с указанием типа содержимого и кодировки.
Вот вывод сервера на обоих показанных выше клиентских подключениях:
Accepted connection from ('10.0.2.2', 55340)
Received request {'action': 'search', 'value': 'morpheus'} from ('10.0.2.2', 55340)
Sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 43}{"result": "Follow the white rabbit. \xf0\x9f\x90\xb0"}' to ('10.0.2.2', 55340)
Closing connection to ('10.0.2.2', 55340)
Accepted connection from ('10.0.2.2', 55338)
Received request {'action': 'search', 'value': '????'} from ('10.0.2.2', 55338)
Sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"result": "\xf0\x9f\x90\xbe Playing ball! \xf0\x9f\x8f\x90"}' to ('10.0.2.2', 55338)
Closing connection to ('10.0.2.2', 55338)
В строке с sending обозначены байты, записанные в сокет клиента. Это сообщение-ответ с сервера.
Проверьте отправку на сервер двоичных запросов, когда аргумент action отличается от search:
$ python app-client.py 10.0.1.1 65432 binary ????
Starting connection to ('10.0.1.1', 65432)
Sending b'\x00|{"byteorder": "big", "content-type": "binary/custom-client-binary-type", "content-encoding": "binary", "content-length": 10}binary\xf0\x9f\x98\x83' to ('10.0.1.1', 65432)
Received binary/custom-server-binary-type response from ('10.0.1.1', 65432)
Got response: b'First 10 bytes of request: binary\xf0\x9f\x98\x83'
Closing connection to ('10.0.1.1', 65432)
Поскольку content-type запроса не text/json, на сервере он принимается за пользовательский двоичный тип, и декодирование JSON не выполняется. А просто выводится content-type, и клиенту возвращаются первые 10 байт:
$ python app-server.py '' 65432
Listening on ('', 65432)
Accepted connection from ('10.0.2.2', 55320)
Received binary/custom-client-binary-type request from ('10.0.2.2', 55320)
Sending b'\x00\x7f{"byteorder": "little", "content-type": "binary/custom-server-binary-type", "content-encoding": "binary", "content-length": 37}First 10 bytes of request: binary\xf0\x9f\x98\x83' to ('10.0.2.2', 55320)
Closing connection to ('10.0.2.2', 55320)
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом. Если вы не найдёте работу, мы просто вернём деньги (возврат — акция в рамках «Чёрной пятницы»).

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
mrkaban
А у SkillFactory бывает авторский материал? Или у вас и преподаватели читают перевод чужих лекций с английского языка?