
Привет! Меня зовут Стас, я инженер технической поддержки в Naumen. Помимо поддержки собственного ПО, мы занимаемся развитием инфраструктуры. Каждый год прогнозируем потребность в ресурсах, и, при необходимости, либо модернизируем существующее оборудование, либо закупаем новое. Пару лет назад мы решили расширять инфраструктуру в облака, так как требования к скорости, доступности, надежности инфраструктуры и сервисов достаточно сильно возросли.
Правда, без предварительной аналитики и оценки возможных проблем можно довольно больно выстрелить себе в колено и потратить кучу времени, нервов и денег. Разберемся, как переехать в облака и не остаться без штанов, на примере наших ошибок.
Зачем использовать облака?
Оборудование. Отпадает необходимость покупки, обслуживания и утилизации собственного оборудования.
Персонал. Железо должен кто-то обслуживать. Чем больше железа — тем больше требуется людей. В облаках такая потребность снижается.
Качество. При собственных ресурсах нагрузка на людей становится выше, от этого может страдать качество.
Масштабирование. Ресурсы нужны уже завтра, а зачастую получить их завтра мы можем только в облаках.
Отсутствие своей инфраструктуры. Не нужно обслуживать собственную инфраструктуру.
Общий метамотив — это экономия: времени, ресурсов, денег.
Выбор провайдера
Составляем список задач и требований
Сейчас выбирать практически не приходится. Однако в целом мы начинаем со списка задач и требований. Нужно максимально детализировать и описать каждую секунду эксплуатации.
Например:
Провайдер должен предоставить API для управления услугами.
На старте нам потребуется 50 виртуальных машин со следующими характеристиками: 8 vCPU и 32GiB RAM, 100GB SSD.
На ВМ будет установлена Ubuntu 18.04.
Виртуальные машины должны быть расположены в одной сети и иметь доступ к ресурсам нашей локальной сети:
дополнительно требуется шлюз и маршрутизация через него до нашей локальной сети.
потребуется минимум 51 IP-адрес в виртуальной сети облачного провайдера.
В день будет проходить N-объём трафика через шлюз.
Лучше фиксировать каждую мелочь, которая только придет в голову. Если она может как-то нас ограничить в будущем — скорее всего, ограничит. Также необходимо составить прогноз на интервале: что и сколько нужно будет через год, полтора и так далее.
Проецируем требования на список услуг провайдеров
Ищем ограничения
Важно искать ограничения провайдеров. Например, спустя полтора года эксплуатации мы напоролись на лимит: в рамках одной виртуальной сети у провайдера могло быть только 100 адресов. То есть мы могли создать хоть 150, хоть 500 виртуальных машин, но одну сеть не могли использовать более 100 виртуальных машин одновременно. Для нас это было важно. К сожалению, этот лимит никак не увеличивался.
Изучаем порядок цен и тарификацию
Тарификация — минимальная единица времени, которую можем заплатить за услуги. Если нам подходят несколько провайдеров, разумно выбрать более дешевого. В перспективе выгоднее обращаться к услугам провайдеров, которые предоставляют услуги посекундно и поминутно. Выгода заключается в том, что пользование услугами зачастую не кратно месяцам, неделям, дням и даже часам. Если нам нужна услуга на полтора часа, то выгоднее заплатить только за полтора часа, а не, например, за два часа или за сутки. Правда, такие провайдеры могут брать больше денег за свои услуги. Поэтому следует оценивать выгоду исходя из своего конкретного сценария эксплуатации.
«Время — самый дорогой ресурс» — казалось бы, пафосный тезис. Однако в контексте облаков он банальный и прямолинейный, ведь фактически мы платим за время. Если мы тратим лишнее время на решение бесконечных проблем и вопросов, то мы тратим деньги зря.
С какими проблемами столкнулись в процессе эксплуатации облака?
У нас есть классический набор сервисов:
Jenkins — там все автоматизации, связанные с выпуском, тестированием и разработкой.
Локальный кластер Kubernetes — там выполняется рабочая нагрузка из Jenkins.
GitLab — там хранятся исходные коды ПО и пайплайны Jenkins’а.
Nexus — выступает в роли maven-репозитория. В нём хранятся собранные jar, war и так далее.
Нерешенные архитектурные вопросы
Когда мы понимаем, что мощностей инфраструктуры не хватает и нужно расширяться, мы арендуем ресурсы в облаке. Возникает первая проблема: как облачную инфраструктуру интегрировать в текущие процессы?
Первое, что пришло в голову — расширить кластер Kubernetes в облако и оставить прозрачность использования кластера для Jenkins. От этого пришлось отказаться, так как сетевые задержки между локальной и облачной инфраструктурой существенные и пагубно влияют на работу кластера в целом.
Единственное оставшееся решение — развернуть ещё один кластер Kubernetes в облаке. Однако, пришлось «объяснить» Jenkins’у, как пользоваться двумя кластерами Kubernetes. Потратив около месяца, логика существующих проектов всё-таки была разделена: часть заданий выполнялась в локальном кластере, часть — в облачном. Задача решена.
Система функционирует, но медленно. Это обусловлено тем, что облачная часть инфраструктуры за всеми ресурсами обращается в локальную сеть. Существующий канал связи не позволяет это делать так быстро, как того хотелось бы.
Следующая идея — закешировать все в облаке. Таким образом, в облачной инфраструктуре появляется ещё один Nexus: он кэширует артефакты maven и образы контейнеров. Задания, выполняющиеся в облачной инфраструктуре теперь обращаются к Nexus, расположенном в облаке. Кэширование артефактов и образов сократило время прохождения каждого задания на ~10-15 минут. Теперь система работает быстро и стабильно. Стабильно… До тех пор, пока разработчик или тестировщик не спрашивает: почему очередь копится в Jenkins и тесты падают по тайм-аутам?
Мониторинг
Приходится решать проблемы и настраивать мониторинг, чтобы в результате увидеть красноту в виде алертов. Однако в перспективе это сэкономит время и деньги, ведь мы сможем быстрее реагировать и предотвращать проблемы.

Нам кажется, что система, наконец, работает. Но в очередной месяц приходит счет на оплату, например, 4000 евро. Мы смотрим на график использования ресурсов процессора на примере 4 виртуальных машин в интервале 12 часов и понимаем, что на графике есть спады в периоды с полпервого до 2 ночи, и между 9 и 10 вечера. Фактически ресурсами в это время мы не пользовались. Может, в это время виртуальные машины не нужны, и можно их удалять? Где нагрузка необходима — создаем и пользуемся, где нагрузки нет — удаляем.

На схеме появляется AWХ — это веб-интерфейс, RESTful API и планировщик для Ansible. Я умел с ним работать, поэтому он появился тут естественным образом. Кластер Kubernetes в облаке теперь имеет минимальный объем по умолчанию. И, при необходимости, динамически расширяется.
Jenkins необходимо выполнить нагрузку → он обращается к AWХ → AWХ создает виртуальные машины → добавляет их в кластер Kubernetes. Когда нагрузка завершила свою работу — виртуальные машины удалились. Теперь, кажется, все работает отлично. И мы точно будем экономить, используя текущее решение.
Однако когда в очередной месяц мы получаем счет, например, на 5000 евро, становится грустно. Мы удаляли виртуальные машины и ими не пользовались. Мы же должны платить меньше?
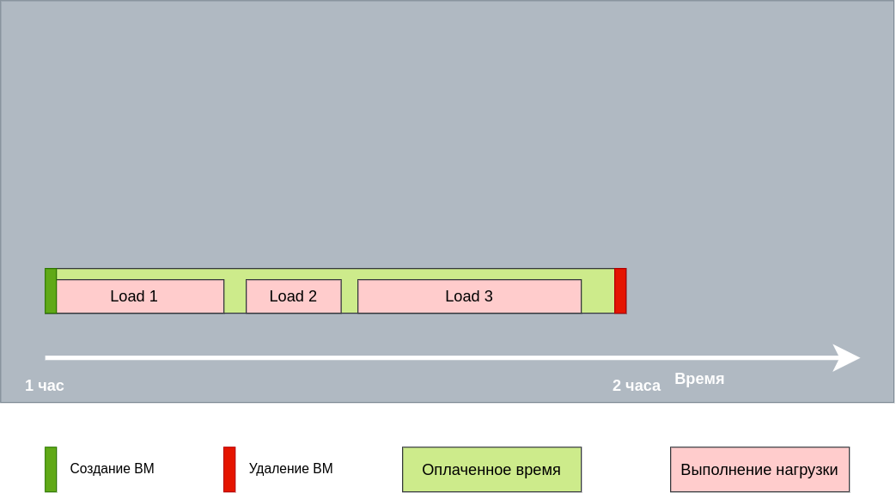
Дело в том, что тарификация почасовая. Фактически возникала нагрузка → она создавала виртуальную машину → оплачивался час работы виртуальной машины → нагрузка отрабатывала минут за 10-15 → виртуальная машина удалялась. Через 5 минут создавалась новая нагрузка и так далее. Очевидно, что все эти нагрузки можно было запустить на одной виртуальной машине, оплатив лишь час работы.

Пришлось усовершенствовать наш «автоскейлинг». Теперь автоматизация не удаляет виртуальную машину сразу после нагрузки, а дожидается завершения оплаченного часа. Когда час подходит к концу и нет нагрузки, виртуальная машина удаляется. Следующий счет был уже намного меньше — 3000 евро. Маленькая победа ????
«Помощь» технической поддержки
Например, у провайдера есть лимит на 70 виртуальных машин, и они все нужны сейчас. А на 20 из них возникла какая-то проблема. Например, сеть отвалилась. Оставшиеся 50 машин не справляются: копится очередь, тесты проваливаются по тайм-ауту. Фактически на этих 50 машинах мы ничего не можем выполнить.
Тогда мы обращаемся в техническую поддержку. В лучшем случае она решает проблему в течение дня, однако все это время мы будем страдать. И приходит мысль: может быть эта поддержка и не нужна?
Как решение, рождается такой тюнинг автоматизации: если появляются такие виртуальные машины, которые в кластере Kubernetes не существуют или у них нет сетевой доступности, мы их удаляем, а на их месте создаются новые. Это снижает вероятность скопления очередей в Jenkins, а также мы меньше страдаем от нехватки ресурсов и начинаем жить счастливее.
Что мы сделали в итоге?
Сократили расходы в облаке.
Оптимизировали использование ресурсов.
Минимизировали скопление очередей Jenkins.
Организовали «самоустранение» проблем.
Остались со штанами (но это не точно)
Комментарии (8)

SAAE
20.12.2022 17:57В следующем году попробуйте потратить время на изменения в архитектуре, которые позволять подключать новых провайдеров и балансировать нагрузку между ними. Если сумеете, то после этого счета за облака будут еще меньше)

blognaumen Автор
21.12.2022 11:22Вы правы, есть куда развиваться. Изменения грядут, но не всегда получается так быстро, как этого хотелось бы.
micbal
Всегда интересно, за счет чего в облаках: "Общий метамотив — это экономия: времени, ресурсов, денег."? При сильно рваной нагрузке наверно да, если правильно отработает автомаштабирование. При стартапе, когда непонятно что будет завтра, и нет пока смысла покупать свои сервера, облако дороже, но выбора нет. А вот в остальных случаях как насчитали выгоду и дешевизну?
screwer
Ещё на ум приходит вариант "жить в кредит". Когда на свои машины надо разово $20к. Которых нет. И ещё одного сотрудника нанять за 12к/год. А за облачные они платят $3-5к. Но в месяц. Уже на интервале в год свои машины бы окупились. Но от бедности приходится переплачивать, называя это экономией.
ЗЫ: цифры условные.
AlexeyUral
Машины.
Хочешь быстро, щелкаешь тумблером и 3 секунды до сотни. Но дорого. Хочешь бюджетно, тумблер, и вот наша Киа Рио.
А пойди купи сервер...
Но тумблер что-то дорогой по мне.
blognaumen Автор
Видимо в текстовом варианте получилось неоднозначное истолкование "выгоды".
Тут мысль в том, что каждый использует облака исходя из какой-то собственной выгоды. Для нас, в первую очередь, выгода во времени. И мы были готовы за эту выгоду переплатить, относительно своего железа.
Но да, я согласен, что в большинстве сценариев N-ресурсов в облаках будет стоить прилично дороже, чем N-ресурсов своего железа в единицу времени.
EmacsBrain
"своё" означает зафиксированные на момент покупки версии оборудования + оплаченная аренда и стоимость эксплуатации этого оборудования + расходы на квалифицированный персонал, который умет в это всё. Добавляем в уравнение параметр "время" и появляются потребности в замене оборудования. А в облаках существенная часть этого уравнения выпадает, правда в пользу стоимости самого облака. Однако открываются новые возможности: "нам на 2 недели надо удвоить мощности" становится элементарной задачей. "Мы стартуем проект, + 10 серверов нужны завтра" тоже, без всяких capacity planning на год вперёд. Также за те же деньги ваша инфра потихоньку умощняется силами провайдера, которому уже некому делегировать все компетенции и предметы реального мира и приходится самостоятельно всё чинить, расширять и нанимать.
alexkil
При использовании Azure/AWS и прочих - это удобные средства управления и кучу компонентов под капотом. И там действительно можно решать описанные кейсы -
быстро, дешево и можно из MVP перейти к серьезной нагрузке.
А вот у других поставщиков начинаются вопросы по всем пунктам.