
Всем привет! Мы - отдел бизнес-поддержки (БП) в Social Discovery Group. В этой статье расскажем, как мы повторили шестой подвиг Геракла, очистив доску от 1500 тикетов, которые накопились за 4 года. 1500 задач - это больно. Тикеты кочевали из спринта в спринт, заказчики ежедневно запрашивали статус по задачам, а мы испытывали стресс от переработок и от того, что не можем дать апдейты. Мы поняли, что нужно менять процессы в отделе и применили подход STATIK, который навсегда избавил нас от бесконечной очереди задач.

Как появилась очередь из 1500 задач?
Задача отдела бизнес-поддержки в Social Discovery Group - обрабатывать тикеты с жалобами и предложениям по работе сервисов от клиентов и других отделов. Например, клиент обратился в техническую поддержку с жалобой о том, что не может заплатить на сайте. Коллеги собирают информацию о проблеме (шаги воспроизведения, скриншоты) и заводят тикет в Jira на наш отдел. Мы проводим дополнительное тестирование, чтобы убедиться, что это не временный сбой у клиента, а проблема на нашей стороне. Если она подтверждается, мы создаем баг-репорт, приоритезируем его и добиваемся фикса от команды разработки.
В среднем, нам прилетало 20-30 тикетов за день. Мы справлялись с первичным воспроизведением проблемы за 2-3 часа, но когда требовалась помощь коллег из других отделов (детализация кейса, рестарт сервиса, данные из БД, анализ от разработки) задачи начинали буксовать. У коллег зачастую не хватало времени оперативно ответить на запросы, и отдельных разработчиков на наши баг-репорты не выделялось. К тому же, у разработки наши тикеты имели меньший приоритет, чем бизнес-задачи. Даже тикеты с highest приоритетом могли зависать до двух месяцев. Менее приоритетные задачи и вовсе оставались на доске годами.
Как видите, в такой цепочке слишком много неопределенности по срокам выполнения. Все это привело к неудовлетворенности у нас и наших клиентов:
Стресс у заказчика. Его проблема решалась не так быстро, как ему хотелось, а точных сроков исполнения мы дать не могли.
Заказчики каждый день писали в суппорт и требовали решения проблем.
Суппорт ежедневно писал нам и мы возвращали тот же ответ: “проблема не решена”.
Стресс и переработки внутри нашей команды. Задачи не двигались по статусу, мы не могли поднять старые задачи и линковать их как повторяющийся кейс.
Чувство безысходности. Когда мы увидели 1500 задач на доске, поняли, что ситуация будет только усугубляться, если ничего не поменять.
Вот, как выглядел жизненный цикл тикета на тот момент:
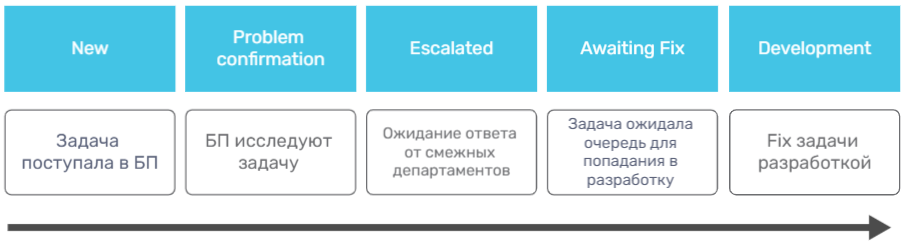
Опишем примеры проблем, с которыми мы сталкивались:
У суппорта не было скриптов, чтобы сразу детализировать проблему и отфильтровать ее на своем уровне.
В статусе «New» могло выяснится, что сил нашего отдела недостаточно. Если не хватало данных или доступов, задача переходила в наш «любимый» статус – «Escalated». На этом этапе мы писали коллегам из смежных департаментов в комментариях к тикету и ждали их ответа. На дополнительную проверку и ответ могло уходить от 2 дней до нескольких месяцев, так как коллеги не замечали комментарий или просто забывали ответить. Либо они могли ответить не полностью, и дополнительные вопросы занимали еще несколько недель. Случалось и так, что мы сами не замечали комментариев из-за наплыва новых задач.
Если все-таки подтверждали проблему, то мы переводили ее в статус «Awaiting fix». При плохом стечении обстоятельств, тикет мог находиться в нем несколько лет. У нас хронически не хватало ресурсов разработки, но заказчики не давали закрыть задачу с мыслью «вдруг ресурсы появятся в будущем – тогда и починят».
Из-за большого количества задач появлялись дубли. Мы не могли их слинковать и закрыть, так как уже не помнили, что было заведено в предыдущие годы.
Недочеты в организации ЖЦ создали очередь в 1500 зависших кейсов за 4 года ☹

Подход STATIK и 6 подвиг Геракла
Мы поняли, что слишком сфокусированы на обработке тикетов и не заботимся о главной цели отдела - решить проблему клиента, повысить его лояльность к продуктам компании и выявить уязвимые места в сервисах и на сайте. Может возникнуть мысль: “Почему-бы не нанять еще сотрудников в отдел, если мы не справляемся с нагрузкой?” Опыт показывает, что наладив процессы, можно обойтись без дополнительных ресурсов. Геракл совершил подвиг сам: отвёл русло реки прямиком в конюшни Авгия, а вода очистила их за один день. Мы, чтобы расчистить доску с тикетами, обратились к книге Майка Барроуза “Kanban from the Inside” и применили STATIK - системный подход к внедрению метода Kanban.
Чтобы его внедрить, мы прошли 5 шагов:
1) Определили ожидания заказчиков от отдела бизнес-поддержки и поняли, что:
Заказчики должны быть удовлетворены работой над их обращениями.
Добиться этого нам поможет:
Прозрачность работы над задачей. В любой момент времени должно быть понятно, что происходит с обращением.
Скорость работы над задачей. Нужно, чтобы в любом состоянии у задачи было определено время обратной связи.
2) Выявили внешние и внутренние источники неудовлетворенности:
Внутренний источник - это то, что мешало нам и бесило в работе нас самих. Внешний источник - то, что мешало заказчикам и бесило их.

3) Выявили источники и природу нагрузки:
Мы проанализировали тикеты, которые приходят в отдел, и разбили их на категории: из каких отделов они приходят, есть ли паттерны в их появлении и какие у заказчиков ожидания по срокам решения и обратной связи.

4) Оценили текущие возможности:
На этом этапе мы оценили эффективность нашего взаимодействия с тикетами, определили, сколько задач успеваем обработать в неделю и каково среднее время от заведения тикета до попадания фикса на прод.
5) Пересмотрели жизненный цикл тикета и создали новый:


Далее, мы проделали комплексную работу по всем проблемам, описанным выше:
Мы сделали для нашего суппорта скрипты, чтобы на этом уровне уже происходила фильтрация задач.
Ввели временный статус “Back to reporter”. Туда переводились задачи, в которых не хватало вводных данных от заказчика для исследования проблемы. Если заказчик не предоставил нужные данные за 3 дня, задача автоматически закрывалась.
Плакали всем отделом, но убрали статус «Escalated» совсем и навсегда. Теперь задачи оставались в более конкретном статусе «Problem confirmation».
Потратили более 2 месяцев на то, чтобы прочесть все старые задачи и закрыть дубли. Из 1500 осталось около 800 уникальных тикетов.
Внедрили в нашу практику SLA - повесили таймеры на каждый статус. В Problem confirmation – 7 дней, Development – 30 дней.
В статусе «Problem confirmation» у нас появилась мотивация пинговать коллег и добиваться ответа. Мы перестали оставлять комментарии в Jira и начали писать им в личку или в треды Slack – теперь ответ занимал не более 1 дня (помните про недели, описанные выше?)
В статусе «Awaiting fix» таймер не вводили, но у нас освободилось время на общение с заказчиком и дискуссии. Если мы знали, что на фикс бага или задачи никогда не выделят ресурсы, мы доносили эту мысль до заказчика и сходились на том, что закроем задачу, а вместо нее починим что-то действительно приоритетное. Из-за этого, количество задач в «подвешенном» состоянии сократилось вполовину. Также, мы начали практиковать общие встречи, где заказчик мог донести до отдела разработки, почему та или иная задача важна и ее стоит решить – это помогло приоритизировать таски.
Статус «Development» – таймер 30 дней. Таймеры стали мотивировать нас дополнительно напоминать, ставить реальные сроки фикса и выполнять их. Также, мы ввели ограничение на количество задач в этом статусе до 4: так можно сфокусироваться и починить баг, не нагружая разработку дополнительным визуальным шумом из 20-40 задач в этом статусе на доске.
Для того, чтобы наши достижения и практики не потерялись со временем, мы ввели принцип 90-го перцентиля. Это значит, что 90% задач должны быть закрыты в срок и задача считалась успешно выполненной, если проводила в каждом из статусов не более предусмотренного таймерами времени. Соблюдение таймеров мы проверяли в разделе Control Chart в Jira + использовали плагин Jira-helper для построения 90-го перцентиля.
Куда же без дополнительной мотивации? Авгий обещал Гераклу десятую часть его лошадей. При соблюдении принципа 90-го перцентиля, мы получали премию.
В итоге, мы решили проблему, которая висела над нами 4 года. Изменив подход и процессы в отделе, мы сократили большое количество задач без дополнительного времени, сил и бюджета. За 5 месяцев мы превратили 1500 тикетов в 150, имея в своем арсенале всего двух смышленых сотрудников. Мы поняли, что важно находить корневые причины появления проблем - это сильно облегчает поиск решения. Понимание цели - важная часть построения процессов, а плохие процессы рано или поздно приведут к накоплению задач.
Комментарии (7)

SergeyMax
03.02.2023 07:35+3Как мы накопили 1500 тикетов за 4 года и решили их все за 5 месяцев
В двух словах: просто позакрывали старьë.

Dmitrii_Andreev Автор
03.02.2023 08:43+2Закрытие старья имеет место быть :). Но основной момент состоит в том, чтобы:
Если колличество тикетов все таки разрослось, научиться закрывать старьё так, чтобы заказчики по этому поводу не возмущались. Т.е. понять какие проблемы не сильно важны, на какие никогда не найдутся ресурсы и договориться об их закрытии.
Выстроить процессы, чтобы старье в будущем не накапливалось, а разрешалось. А то ситуация превратится в бесконечный цикл накапливания и удаления тикетов.
SergeyMax
03.02.2023 09:39-2научиться закрывать старьё так, чтобы заказчики по этому поводу не возмущались
Был такой анекдот про кошку и горчицу, который заканчивался фразой "добровольно, и с песней!"

R72
03.02.2023 09:24+4Ваше решение проблемы выглядит так:
1) Провели ревизию дублей задач. Это сразу уменьшило очередь на 50% почти.
2) Провели организационные меры - добавили статусы задач, переносящие часть задач на инициаторов задачи
2.1) Ввели статус типа "на приёмке у инициатора"
2.2) Ввели статус "на согласовании у инициатора"
что ещё больше сократило очередь (точнее перекинуло часть очереди с вашего отдела а инициаторов)
3) Ограничили работу 4-мя задачами, остальные в мусор-неважные-делаемпостолькупосколькуможем
Подозреваю, что такие мусорные задачи убедили руководство вынести из KPI вашего отдела (иначе смысла бы в этом решении не было).
Гениально! Но банально. Годик стажа так можно прожить пока до всех дойдёт.
Все решения организационного вида. Не ИТшные.
Технологических решений и причин, как видно, не было выявлено:
причины такого большого потока задач от пользователей (некачественный код и архитектура, например)
задачи пользователей не проходят фильтрацию/согласование у руководителей пользователей или сотрудников тех же отделов, у которых более долгий срок жизни в компании
неправильно выстроена оргструктура техподдержки - вашему отделу не подчиняются службы, без которых решение задач не возможно или им не установлен регламент и KPI на взаимодействие с вашей службой
не установлен принцип поддержки отсекающий задачи не соответствующие KPI бизнеса. Не каждая хотелка пользователей должна реализовываться.
Не введён принцип техподдержки - задач должно быть не больше, чем ресурсов на их решение
(есть подозрение) нет типологии задач и типового времени на их решение.
Dmitrii_Andreev Автор
03.02.2023 13:41Спасибо за развернутый коммент! Цель статьи как раз и показать, что путем правильной организации процессов, не обязательно внедрять какие-то сложные технические решения. При рациональном подходе даже расширение штата не требуется.
Давайте немного остановимся на ваших пунктах:Количество задач не всегда колеруется с плохим кодом и архитектурой. Оно может зависеть от незнания того, когда нужно заводить технический тикет, от недостаточной первичной диагностики. Так же не забываем, что тикеты могут быть с предложениями об улучшении чего то на сайте, запросы на получение какой-то информации (как что-то работает, как должно работать и т.д.). Правильное выстраивание процессов помогает быстро обрабатывать поток любого вида задач.
Недостаточная фильтрация тоже безусловно имела место быть, и выявление источников нагрузки помогло это заметить.
В статье внимание было заострено на тех. поддержке, но это лишь один из отделов, который обращается в БП, на самом деле тикеты идут практически со всех отделов компании. И да, структура тех. поддержки не была идеальной, взять хотя бы отсутствие скриптов, упомянутых в статье. Выстраивание процессов - это не только внутренние изменения в одном департаменте, это в том числе и диалог коллегами из смежных департаментов и внедрение нового подхода там.
Такой принцип был введен в ходе изменения процессов, это упоминается в статье. Мы же не просто так закрыли некоторые задачи :), были внедрен регулярные встречи с заказчиками и обсуждение тех задач, которые в принципе не будут делаться, а по каким-то можно найти компромисс.
В БП обращается не только тех поддержка, но и другие команды. Исходя из вашего опыта, как бы вы внедрили принцип, что "задач должно быть не больше, чем ресурсов на их решение"? Когда человек обращается в БП, у него есть какой-то насущный вопрос, который он хочет решить или какая-то информация, которую он хочет получить, он не обязан знать про количество ресурсов разработки или каких либо иных ресурсов, ему интересно решение его проблемы. Есть способы снизить количество обращений (некоторые из которых я описал в статье), но строго ограничивать количество входящих тикетов каким-то KPI, я считаю, не совсем верно.
Вы правильно подметили, ее толком не было. Появилась она после тех шагов, которые мы прошли. Были написаны шаблоны действий, статьи по часто встречающимся вопросам, и т.д.
Прошло уже больше года с того момента, как мы поменяли подход к решению проблем, с тех пор количество задач не разрослось, как и штат отдела :)

Prion
05.02.2023 15:05У меня есть большие подозрения, что дело не в новой методологии. А кто то из менеджеров забил на задачи. Никого не смущает почему выстроилась такая очередь? Как не допустить увеличения очереди? Кто то делал разбивку по задачам какого типа задачи больше всего в очереди? Пытались как то автоматизировать? Пытались мелкие задачи объединить в пакет,а большие задачи дробить? Организовывались встречи с другими отделами по поводу задач?
Я вижу что уменьшили количество задач, а бизнес что получил на выходе? Я знаю как задачи могут делаться и закрываться, поэтому закрытая задача далеко не всегда показатель эффективности.
Должны быть помимо количества закрытых задач, какие то бизнесовые метрики . Есть масса специальностей , например в продажах, интернет маркетинге , где никого не интересует сколько ты задач сделал - интересуют продажи, лиды, закрытые сделки, заявки и т п
AlexM2001
Очень знакомая ситуация.
Проработал несколько лет начальником отдела по претензионной работе, одной из самых крупных российских компаний по оборудованию HVAC.
Спасибо большое за статью, здорово прочесть подробное изложение рабочего процесса!
P.S. Эх, жаль, плюсы сегодня закончились)