
«Мины» в исходном коде — это не только уязвимости, но и прочие дефекты безопасности, которые так или иначе ухудшают качество софта. Какими путями «минируется» ваш код и какие типы «мин» наиболее актуальные? Поговорим об этом в контексте веб-программирования и PHP.
О «минах» в коде расскажет Илья Поляков, руководитель отдела анализа кода Angara Security. Илья поделится какими инструментами разминировать код и какие уязвимости и дефекты безопасности можно найти максимально быстро и дешево.

Источники проблем в исходном коде
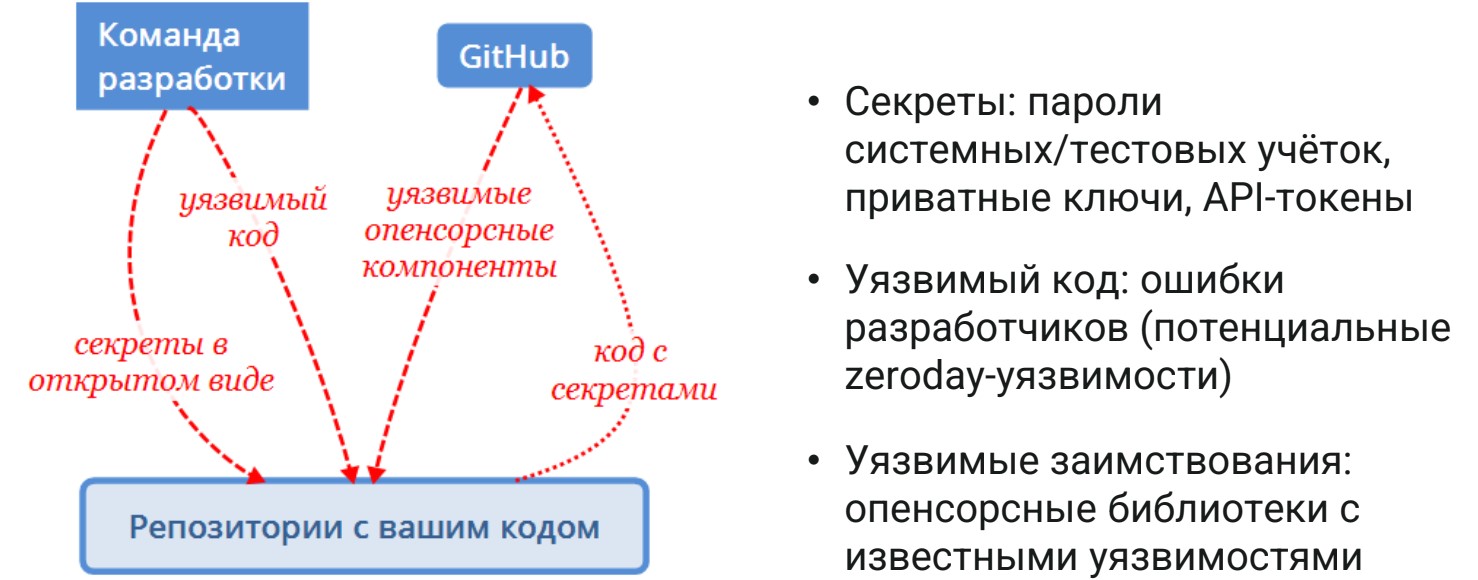
Главный источник проблем в исходном коде, как ни странно — это ваша команда разработки. Помимо большого объема хорошей работы, она иногда допускает некие неточности и отгружает уязвимости в код. Получается уязвимый код, плюс в проекты подтягиваются различные опенсорсные компоненты из Github, Gitlab и прочих источников, тоже содержащие в себе уязвимости. Особенно это бывает в устаревших версиях. Весь ужас в том, что о них знают практически все и могут их эксплуатировать.
Также в код попадают захардкоженные секреты. Это бич современной разработки, не только по PHP. Потому что для скорости всегда проще захардкодить пароль или API-токен. Но даже если файл потом будет удален в репозитории, он все равно останется в истории коммитов и будет доступен всем кто имеет доступ к репозиторию.
Отдельная проблема в том, что иногда репозиторий с кодом вольно или невольно уходит на Github в публичный репозиторий, и секреты становятся доступны вообще всему интернету. Получается, что есть секреты, уязвимый код с потенциальными zero day уязвимостями и заимствованиями.
Относительно недавно вышел OWASP ТОП-10 по веб-уязвимостям:

Cross-Site Scripting объединили в категорию инъекции, но даже несмотря на это инъекции с первого места всё равно упали на третье. Видимо, за счет все большего внедрения ORM, роста популярности фреймворков и паттернов программирования, в которых сложнее отстрелить себе ногу. То есть роль инъекций в ТОПе веб-уязвимостей существенно снизилась, но это в «среднем по больнице».
По числу уязвимостей есть статистика в Open Source от бывшей компании White Source, которая теперь называется Mend.

Из диаграмм видно, что намеки на сингулярность отмечены в количестве уязвимостей. За 2020 год их количество в Open Source почти удвоилось, не только по PHP. Казалось бы, Open Source просто так бодро растет, что вместе с ним растут и уязвимости. Но если посмотреть на правой диаграмме на количество активных проектов и пользователей, то видно, что там сингулярности не намечается и рост более или менее линейный. Красная линия — это количество событий, то есть всякие коммиты, форки, комменты. Видно, что работа с Github и прочими репозиториями Open Source интенсифицируется, но количество проектов и юзеров особо не растет, а уязвимостей при этом находят гораздо больше.
Посмотрим разбивку по языкам, потому что одни языки больше подвержены уязвимостям, а другие меньше. Если сравнить как росло количество уязвимостей с 2019 по 2020 год, то видно, что РНР стал лидером и обогнал даже С.
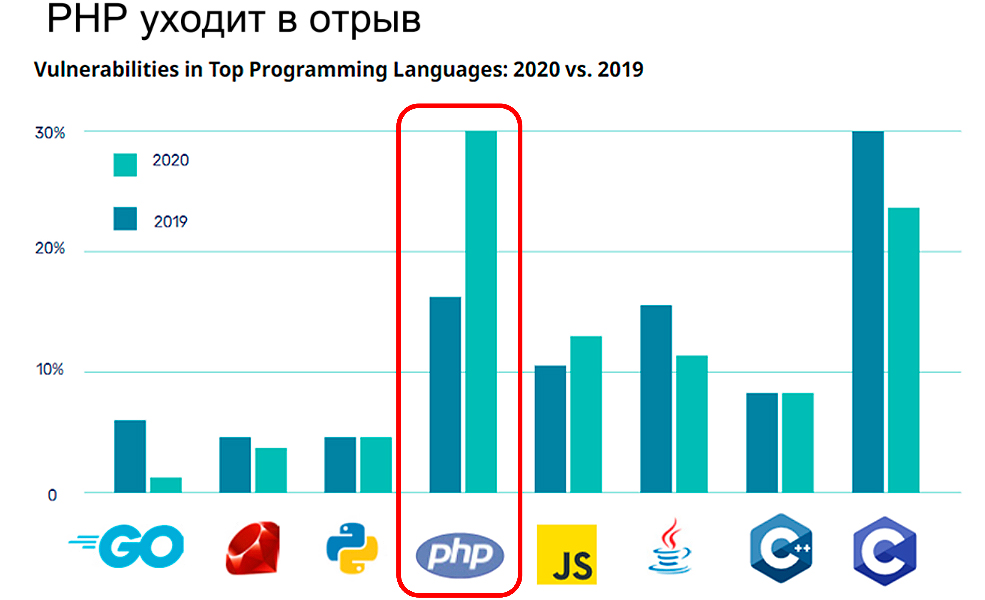
Динамика довольно пугающая и этому нет какого-то однозначного объяснения.
Популярные уязвимости
В статистике за 2020 год в разрезе типов уязвимостей, которые встречаются в Open Source, на первом месте стоит Cross-site Scripting. В принципе, если не смотреть на всякие сишные уязвимости типа Buffer Overflow и так далее, то видно, что «в среднем по больнице», как и у РНР, на первом месте Cross-site Scripting, на втором SQL-инъекция и на третьем CSRF’ки.
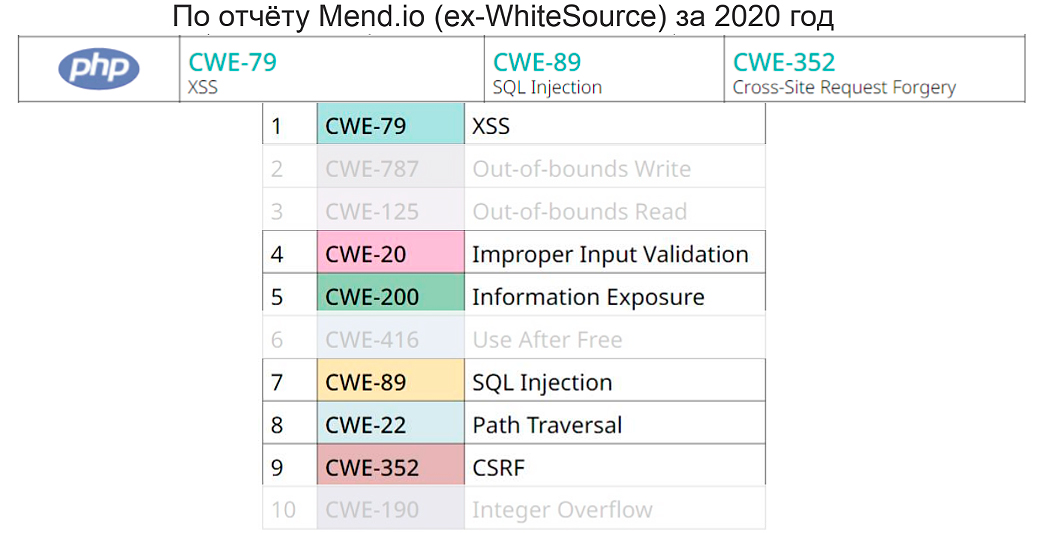
Соответственно, у РНР инъекции стоят на первом месте. Особенно если сложить Cross-site Scripting и SQL-инъекцию, которая всего лишь на седьмом месте в топе по всем языкам. Почему так — не очень объяснимо. Может, плохо внедряются ORM фреймворки и параметризованные запросы, что касается SQL-инъекций. Почему такая статистика по Cross-site Scripting? Тоже особых идей нет. Тем не менее, данные не очень хорошие.
Проблемы заимствованного кода
Есть устаревшая версия с известными уязвимостями. Она усугубляется открытым кодом, и там тоже могут быть zero day. Высокопрофессиональные группировки при целенаправленной атаке могут сначала понять, какие опенсорсные компоненты используются в атакуемом проекте, найти их исходный код, разобрать его на молекулы и найти там какой-нибудь zero day. Это тоже проблема для крупных проектов.
Помимо этого, есть закладки. В тех же библиотеках есть «условно-патогенный» protestware, который может вывести какое-нибудь сообщение или создать более серьезные проблемы. Причем для этого даже не надо что-то добавлять. Закладка воспринимается как что-то дописанное в код, но это необязательно так.
На Angara Techday сделали демонстрацию взлома приложения. Илья подготовил стенд и взял хорошее приложение. Чуть-чуть его пофиксил, испортил алгоритм санитизации user input в нескольких символов одной строчки кода, и появилась уязвимость. Причем ее даже не находили коммерческие SAST-сканеры. Размер кода не увеличился, даже немного уменьшился, но получилась закладка.
Есть еще одна тема, возможно, менее актуальная на фоне всего остального. Это лицензионный конфликт. Мы включаем какие-то опенсорс-компоненты, и сразу или чуть позже оказывается, что лицензия несовместима с нашей коммерческой деятельностью, и мы обязаны раскрывать исходный код, раз их используем.
Проблемы собственного кода
Во-первых, когда вы пишете каждую строку кода, это простор для того, чтобы ошибиться и напортачить гораздо больше, чем если делать «крупноузловую» сборку.
Ведь если взять уязвимую опенсорсную библиотеку, обновить ее версию, обычно есть обратная совместимость, и она действительно работает. В этом смысле все просто. В своем коде уже свои кастомные баги и уязвимости, дефекты безопасности. Соответственно, это требует кастомных исправлений. И при отсутствии SLA это часто может затянуться. Потому что много у кого нет SLA по исправлению уязвимостей. При отсутствии сбалансированной воли руководства, когда говорят «давайте отгружать фичи скорее», часто исправление уязвимостей отходит на второй план. Особенно с аргументами «да кому мы нужны» или «такую дыру так просто не найдешь».
И, как ни странно, когда уязвимость уже в проде, это часто плохо влияет на скорость ее исправления. Потому что фиксить прод надо довольно аккуратно — из-за этого могут возникнуть проблемы, аффектящие пользователей.
Проблемы зашитых в код секретов
Третий тип дефектов безопасности — это проблемы, зашитых в код секретов. Во-первых, отучить разработчиков не хардкодить секреты тяжело. Во-вторых, мало просто сказать: «Не хардкодь пароли», нужно предложить какую-то альтернативу, которая включает в себя системы менеджмента секретов. Внедрение этой альтернативы — это уже целое дело.
Плюс пароли к системным учеткам часто повторяются. У Ильи на одном из предыдущих мест работы было голосование по выбору надписи на мерче. И варианты эти включали в себя наиболее часто встречающийся пароль для системных учеток. С этим уже начался цирк. У того же работодателя, когда Илья начал заниматься Application Security, то обнаружил, что у любого сотрудника из нескольких тысяч был доступ к более 1000 репозиториев исходного кода. Получается любой мог скачать все Git-репозитории и поискать там захардкоженные секреты. Встречались даже секреты, которые по девять лет актуальны в системных учетках, в том числе в продовских.
Еще проблема в том, что даже удаленный секрет не исчезает из истории коммитов (если этим специально не заморочиться). Его всегда можно найти. Если просканировать SAST-инструментом, (большинство из которых находят закардкоженные секреты) он скажет, что все «ОК», ничего не найдено. Поскольку он сканирует только финальный вариант кода, а не всю цепочку правок, часть из которых «взаимно аннигилируются». Но в истории коммитов удаленные секреты можно легко найти соответствующими инструментами: gitleaks, gittyleaks, trufflehog.
Еще бывают утечки на Github, когда захардкоженный пароль утекает в публичный репозиторий. На Западе даже есть стартап (или уже даже не стартап) Git Guardian. Он мониторит для своих клиентов весь Github в режиме 24/7 и определяет какие репозитории имеют отношение к компании по доменным именам. А далее проверяет, не закомитили ли какой-нибудь захардкоженный пароль и старается как можно быстрее об этом доложить. Но это не панацея. У Ильи был инцидент, когда один из независимых белых хакеров сообщил, что нашел захардкоженный секрет в Гитхабе. Он это сделал раньше, чем Git Guardian. В этом смысле ручная работа получилась эффективнее, чем автоматизированный сервис компании.
Инструменты по разминированию
Проще всего с секретами, потому что это фактически не программирование, их нужно просто убирать из кода и предотвращать их попадание в исходный код. Последнее сейчас недостаточно внедряется.
Для этого существуют инструменты (OWASP SEDATED или pre-commit в комбинации с утилитами поиска секретов), которые довольно изящно встраиваются путем git hooks в системы хранения кодов и позволяют предотвращать коммиты с подозрениями на секреты. Понятно, там есть ложные срабатывания, но фактически это один из наиболее эффективных инструментов.

Против тех кастомных уязвимостей, которые разработчики прописывают в коде, есть только инструменты статического анализа — SAST сканеры.
И, наконец, Software Composition Analysis сканеры отвечают за поиск уязвимых компонентов. Причем включая какие-нибудь транзитивные зависимости, которые у того же Log4J встречались на седьмом уровне транзитивности. То есть там действительно нужно глубоко копать.
Инструменты SAST
Какие есть доступные, особенно актуальные для России и конкретно для РНР инструменты SAST? Фактически все импортные можно вычеркивать. Единственное, не очень понятно с Checkmarx. Была информация, что он вроде ушел, сейчас уже говорят, что остался. Видимо, нужно плотно общаться с вендором или его представителями, но специфические риски в любом случае остаются.
Из отечественных коммерческих решений — только два универсальных (в разрезе языков) инструмента, которые, разумеется, работают и с РНР. Для С++ и Java их существенно больше. Но по РНР только Positive Application Inspector и Solar AppScreener (а также куда менее распространенные Infowatch Appercut и AppChecker Cloud от НПО Эшелон). Они еще включают в себя под капотом инструменты Software Composition Analysis, то есть умеют вычислять уязвимые версии библиотек.
Из Open Source Semgrep начал недавно поддерживать РНР. В принципе, он тоже что-то находит. Еще есть OWASP ASST, который умеет сканировать только РНР.

С точки зрения безопасника опенсорсные инструменты не очень хороши, но с точки зрения разработчика они приятны тем, что быстрые. Правда, эта скорость дается не бесплатно, а за счет недостаточно глубокого анализа и большого количества ложных срабатываний. Происходит в основном синтаксический анализ. Нет межпроцедурного анализа, когда, например, data flow раскидан по нескольким классам, и опенсорсные инструменты легко пропускают уязвимости в таких случаях.
Инструменты SCA
По SCA есть импортные — например, Synopsis BlackDuck и Snyk. У Snyk есть бесплатная версия, если зайти через VPN. Он позволяет делать порядка 100 сканирований в месяц, причем сканирует неплохо. Соответственно, для небольших проектов, каких-то спин-оффов, стартапов и так далее это может быть первоначальным решением, которое позволит собрать и просканировать MVP довольно быстро.
Опять же есть Checkmarx. Из отечественных инструментов основное — это CodeScoring, который работает лучше, чем классические опенсорсные инструменты: deptrack и depcheck. У него больше баз уязвимостей и вообще он гораздо удобнее. Вроде есть еще некий инструмент, но пока он недостаточно активен на рынке.

Секреты
Последний тип уязвимостей — это захардкоженные секреты.
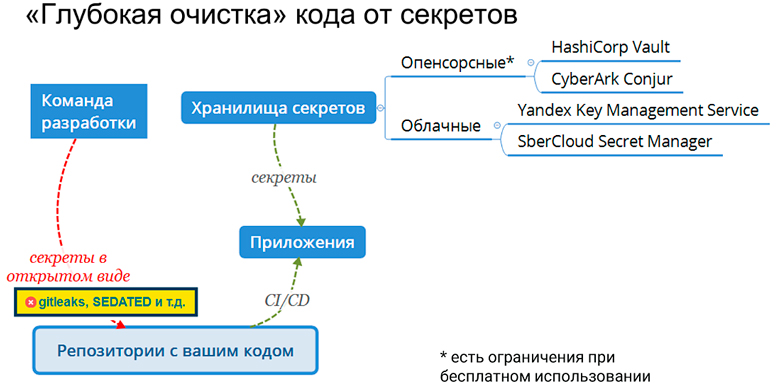
С одной стороны, очень простой и понятный дефект безопасности. Но устранять его не так просто. Помимо того, что нужно постоянно вычищать секреты из кода или, предпочтительнее, предотвращать их попадание туда, нужно еще хранилище секретов, чтобы дать разработчикам некую надежную альтернативу захардкоживанию.
И это должны быть не какие-то костыли, не с горем пополам зашифрованные секреты, хранящиеся в каком-нибудь Gitlab отдельно, а уже более или менее enterprise-продукты. Это, прежде всего, HashiCorp Vault и CyberArk Conjur. У них есть неплохие для большинства проектов опенсорсные версии. Но если уже требуется распределенная система, прямо совсем highload, то их бесплатные версии не подойдут, а платные недоступны для России.
И это проблема, которую можно решать уходом в облака. Прежде всего это Yandex Key Management Service и SberCloud Secret Manager, которые имеют собственные сервисы по управлению секретами. У них все хорошо, но единственное, если мигрировать из одного облака в другое, придется проводить работу по переделке, потому что API у них, само собой, разные.
Языком антивирусов
Перейдем к аналогии инструментов безопасности с антивирусами. Статический анализ позволяет находить zero day. Это точно так же, как эвристический анализ у антивирусов позволяет находить неизвестную ранее malware. Этим инструментом, можно искать секреты и даже сканировать опенсорсные библиотеки на предмет уязвимости. Но это будет крайне неэффективно как с точки зрения detection rate, так и с точки зрения falls positive rate. Точно так же, как антивирус бы не уехал далеко на одной эвристике.

Поэтому есть компонентный анализ, аналогичный сигнатурному анализу у антивирусов. Это не анализ кода, а динамический анализ, фактически соответствующий песочнице у антивирусов.
Ручной анализ кода
Code review, наверное, самое лучшее средство против обнаружения закладок. Потому что компьютер и статический анализатор обмануть гораздо проще, чем человека. Ручной анализ позволяет воздействовать и на свой, и на заимствованный код. Его особенно рекомендуют для проведения анализа критических компонентов и потоков данных. В частности, аутентификацию и восстановление пароля не стоит отдавать на откуп статическим анализаторам, потому что они не понимают бизнес-логику и часто пропускают уязвимости. А компоненты реально критические.

Единственный момент, ручной анализ кода — это дорого. Плюс нельзя исключать человеческий фактор. Человек не выспался и пропустил какую-то уязвимость. В этом смысле это наименее предсказуемый метод.
Частый аргумент, который возникает при статическом анализе — нашли уязвимость, даже показали, как можно ее проэксплуатировать, но почему-то решили, что её невозможно найти снаружи, потому что нужно знать код. А код не опенсорсный, значит никто не найдет.
Как раз недавно появилась новость про то, как Uber поломали, и там утек исходный код. Оказалось, что все уязвимости, которые действительно сложно найти снаружи, уже можно найти, имея код.

Проблемы у сканера возникают не в процессе встраивания их в конвейеры разработки, а уже в процессе эксплуатации. Потому что нельзя просто встроить сканеры в пайплайн, там все наладить и расслабиться. Они будут генерировать кучу срабатываний, и нужен кто-то, кто будет отделять постоянные крики: «Волк! Волк!» со стороны сканеров от реальных волков. И важно их не пропустить, чтобы глаз не замылился.
Безопасность – это конкурс по копанию
С одной стороны, есть плохие ребята, которые пытаются нарыть уязвимости и их проэксплуатировать. С другой стороны, есть безопасники, которые тоже копают. В этом смысле разница в квалификациях может легко стать критической. Потому что чем выше квалификация, тем глубже ты можешь копнуть. Если противник копает глубже тебя, рано или поздно этот дисбаланс реализуется в виде инцидента.
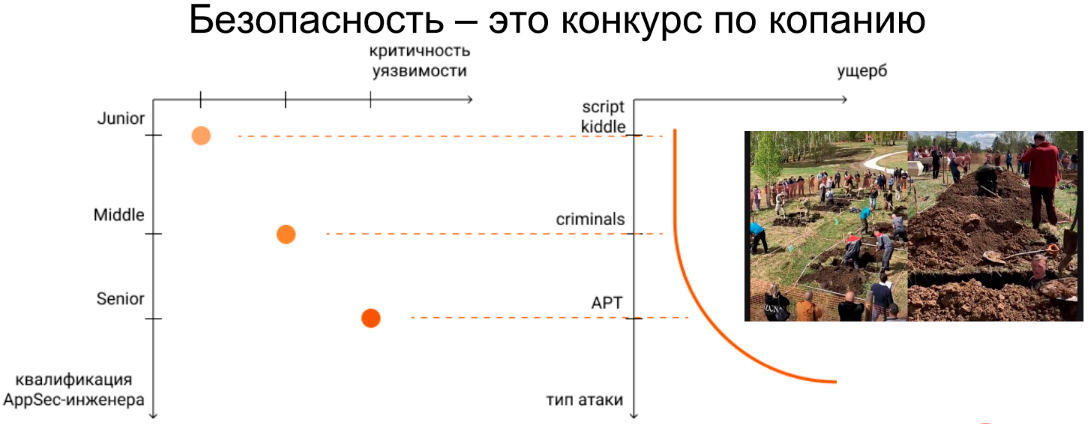
Инцидент часто служит триггером увеличения бюджетов безопасности. На данный момент это не дешевое удовольствие. Но отсутствие безопасности часто еще дороже и никакое уже не удовольствие.
Итоги
Итак, источниками проблем в исходном коде могут стать оплошности команды разработки. Такие «мины» в коде возникают из-за секретов в открытом виде, уязвимых кодов и уязвимых заимствований, поэтому мы рассмотрели каждую из этих трех групп проблем более подробно.
Перечисленные уязвимости «разминируются» такими инструментами как SAST, SCA и глубокой чисткой кода от захардкоженных секретов.
К основным рабочим инструментам SAST для PHP, действующим в России, можно отнести: Positive Application Inspector, Solar AppScreener, Semgrep, OWASP ASST. Под вопросом остался Checkmarx, который то уходит из нашей страны, то остается.
По инструментам SCA для PHP есть отечественный CodeScoring и классические опенсорсные инструменты deptrack и depcheck.
С захардкожжеными секретами можно бороться инструментами HashiCorp Vault, CyberArk Conjur, Yandex Key Management Service и SberCloud Secret Manager.
Проблемы могут возникать и при ручном анализе кода, но главное, что нужно понять, безопасность — это как конкурс по копанию. Здесь выигрывает тот, у кого выше квалификация, поэтому экономить на безопасности нужно весьма расчетливым образом.
Комментарии (4)

dolfinus
00.00.0000 00:00отучить разработчиков не хардкодить секреты тяжело
Что именно здесь тяжёлого? Скорее проблема в плохо настроенном или вовсе отсутствующем процессе CI/CD, чем в разработчиках.

kreexus
00.00.0000 00:00И, пожалуй, проблема в codereview, а так же отсутствии тимлида, который бы рубил мачетой пальцы за каждый косяк в сорцах

AmdY
00.00.0000 00:00Интересно было бы посмотреть на конкретные примеры проектов и найдённые в них уязвимости. Опыт подсказывает что такие автосгенеренные отчёты на 100% ложные срабатывания без возмозможности их эксплуатации.
alexvgrey
Никогда не думал с этой точки зрения. Да, человеческий фактор - суровая правда.
У нас, хоть и локальные репозитории, но никто не мешает косячить на проде с доступом извне.