

Привет, Хабр! Меня зовут Паймеров Владимир, я Data Scientist в Сбере и участник профессионального сообщества NTA.
Компьютерное зрение (computer vision, CV) — активно развивающееся научное направление, посвящённое анализу изображений и видео. В последнее время ему уделяется большое внимание, так как CV позволяет решать множество задач: определять объекты, классифицировать изображения, распознавать лица и т. д. А эти задачи применяются в разных сферах жизни: от наложения масок на лицо во время звонков в мобильных приложениях до построения систем безопасности, поиска преступников и мошенников. Задумка обрабатывать изображения для извлечения из них полезной информации возникла давно, однако возможности технологий не позволяли это делать, так как при обработке изображений нужно хранить большие объёмы данных. Сейчас эта возможность есть, поэтому появилось множество инструментов для решения различных задач компьютерного зрения. Об одной из них я расскажу.
Содержание
-
Свёрточные автоэнкодеры для извлечения признаков из изображения
Использование предварительно обученных моделей для извлечения признаков из изображения
Использование готовых библиотек для поиска похожих изображений
Введение
Ежедневно посетители интернета оставляют на разных сайтах и в социальных сетях свои персональные данные: e-mail, имя, телефон, возраст, фотографии. Закон 152-ФЗ запрещает собирать, хранить и обрабатывать персональные данные человека без его согласия. Но владельцы некоторых сайтов, которые с полным основанием можно назвать мошенническими, игнорируют этот закон и не задумываются об ответственности.
В банковской сфере для идентификации клиентов используются паспорта. Мошенники могут подделывать их, использовать старые недействительные паспорта для получения кредита и проведения других банковских операций, что приводит к убыткам для банков и потерю доверия вкладчиков, которые становятся жертвами. При этом мошенники используют паспорт с лицом одного и того же человека, меняя незначительные детали (цвет волос, форму ушей, добавляют усы и т. д.).
Поэтому возникла потребность в проверке паспортов, чтобы быстро выяснять, на фотографии тот же человек или другой, тем самым вычисляя мошенников защищая деньги клиентов банка.
Я рассмотрю задачу, называемую поиском похожих изображений.
Модель поиска похожих изображений
Поиск похожих изображений — активно развивающееся направление в машинном обучении. Уже разработаны модели, которые могут помочь в различных областях, например:
поиск дубликатов изображений;
поиск фотографий-плагиатов;
создание возможностей для обратных ссылок;
знакомство с людьми, местами и продуктами;
поиск товаров по фотографии;
обнаружение поддельных аккаунтов, поиск преступников и т. д.
Самые известные инструменты — Google Image Search и Pinterest Visual Pin Search. В статье мы познакомимся с лёгкими и популярными подходами к поиску:
Применение свёрточных автоэнкодеров.
Применение предварительно обученных моделей на основе нейронных сетей.
Применение готовых библиотек (face_recognition).
В этих подходах для изображений не применяют метки, то есть дополнительные текстовые или числовые элементы, которые классифицируют изображения по категориям. Признаки извлекаются из изображений только на основе текстур, форм и других визуальных составляющих. Этот называется поиск изображений на основе содержимого (CBIR), в отличие от поиска ключевых слов или изображений на основе текста.
CBIR можно назвать формой обучения без учителя:
При обучении не используется никаких меток для классов.
Изображения преобразуют в векторное представление, то есть «векторы признаков» для конкретных картинок.
Во время поиска похожих изображений вычисляется расстояние между векторами: чем оно меньше, тем более релевантными, то есть визуально похожими являются два изображения.
Загрузка, обработка и работа с данными
Для построения модели нужны данные — изображения. Мы взяли из архива электронных документов банка набор из примерно 20 000 сканов паспортов (около 20 Гб). Качество входных данных проверялось вручную и при помощи инструмента ABBYY FineReader PDF15 (все изображения ориентировали горизонтально и разделили на отдельные страницы). В целях конфиденциальности в статье мы будем использовать изображения известных личностей вместо фотографий реальных людей из паспортов.
Работа проводилась в виртуальном окружении RAPIDS.AI CUDA 11.0.3 (cuDNN 8.0.5) TensorFlow, PyTorch Geometric с использованием графического процессора A100, четырьмя гигабайтами оперативной памяти 4 Гб и двумя ядрами процессора.
Перед началом работы необходимо импортировать библиотеки и модули из Keras и Tensorflow.
import os
import keras 2.4.3
from keras.preprocessing import image
from keras.applications.imagenet_utils import decode_predictions, preprocess_input
from keras.models import Model
from tensorflow.keras import applications
import tensorflow as tf 2.3.4
from tensorflow.keras.models import save_model
import tensorflow.keras.layers as L
import numpy as np 1.18.5
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt 3.3.4
import cv2 3.4.5.20
import pandas as pd 1.1.5
import tqdm 4.62.3
from skimage import io
import glob
from PIL import Image, ImageEnhance, ImageChops, ImageStat, ImageDraw 8.4.0
import face_recognition 1.3.0
import fitz 1.21.1
from pathlib import Path
import shutil 2.7
import openpyxl 3.1.2
from itertools import chain 3.1После импорта библиотек загружаем изображения. Для этого нужно полностью прописать путь до папки с ними и создать список из путей до каждого изображения.
path ="/Users/Desktop/Python/Passports" (здесь Ваш путь до pdf-сканов документов)
gPDF=glob.glob('path/*.pdf')Для того, чтобы получить изображение лица с фотографии в паспорте, PDF-сканы необходимо преобразовать в графический формат, для этого мы написали такую функцию:
def extract_images_from_pdf(pdf):
count = 0
for tpdf in pdf:
name = Path(tpdf).stem
doc=fitz.open(tpdf)
for i in range(len(doc)):
for img in doc.get_page_images(i):
xref=img[0]
pix = fitz.Pixmap(doc,xref)
if pix.n < 5:
pix.save(f'image_from_pdf/{name}p%s-%s.png' % (i,xref))
else:
pix1 = fitz.Pixmap(fitz.csRGB, pix)
pix1.save(f'image_from_pdf/{name}p%s-%s.png' % (i,xref))
pix1 = None
pix = None
count+=1
return f'Found {count} images'
# Применение функции
extract_images_from_pdf(gPDF)
Далее получаем путь до всех обработанных изображений из PDF-сканов и функцией face_recog_pdf вырезаем из фотографии область с лицом. Сохраняем результат в отдельную папку.
g=glob.glob('image_from_pdf/*.png')
def face_recog_pdf(gimage):
count = 0
for timage in gimage:
name = Path(timage).stem
img = face_recognition.load_image_file(timage)
test_loc = face_recognition.face_locations(img)
for f in test_loc:
top, right,bottom, left = f
face_img = img[top:bottom,left:right]
pil_img = Image.fromarray(face_img)
pil_img.save(f'pdf_img/{name}_face_{count}.png')
count+=1
return f'Found {count} face(s) in this photos'
# Применение функции
face_recog_pdf(g)
При помощи функций extract_images_from_pdf() и face_recog_pdf() и библиотеки OpenCV из 20 000 PDF-сканов паспортов мы получили около 10 000 паспортов с фотографиями (в сканах были изображения без фотографий).
После обработки сканов привели все полученные изображения к одному формату и преобразовали в векторы, этот метод применяется для подхода с использованием свёрточных автоэнкодеров:
def image2array(filelist — путь до папки с фотографиями):
image_array = []
for image in filelist[:200]:
img = io.imread(image)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224,224))
image_array.append(img)
image_array = np.array(image_array)
image_array = image_array.reshape(image_array.shape[0], 224, 224, 3)
image_array = image_array.astype('float32')
image_array /= 255
return np.array(image_array)
train_data = image2array(filelist)
print("Length of training dataset:", train_data.shape)После выполнения функций мы получили изображения вырезанных из паспортов лиц. Следующий этап — преобразование их в векторы (для подхода с использованием свёрточных автоэнкодеров — функция image2array), которые потом будем использовать для сравнения и получения наборов похожих изображений.
Ниже рассмотрим основные подходы к поиску похожих изображений.
Свёрточные автоэнкодеры для извлечения признаков из изображения
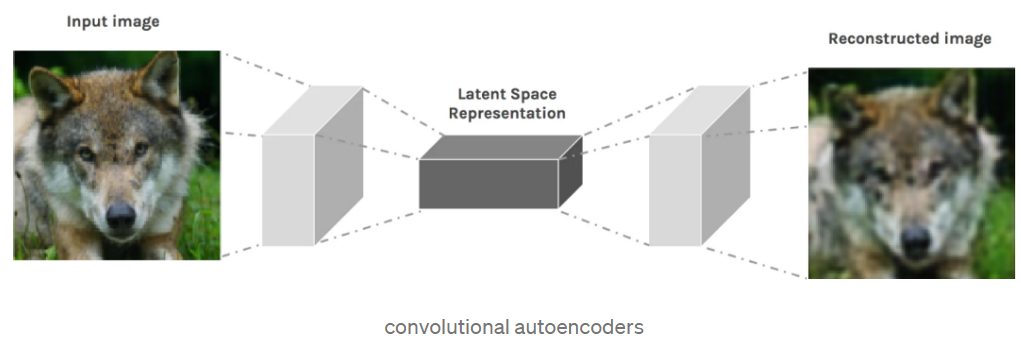
Свёрточные автоэнкодеры (CAEs) — это тип свёрточных нейронных сетей. Они состоят из:
Энкодера (encoder), который преобразовывает входное изображение в представление скрытого пространства с помощью серии свёрточных операций.
Декодера (decoder), который пытается восстановить исходное изображение из скрытого пространства с помощью серии операций свёртки с повышением дискретизации, или транспонирования. Его также называют деконволюцией.
Подробнее о свёрточных автокодерах можно прочитать здесь.
Автоэнкодер делают при помощи соединения свёрточных слоёв и слоёв пуллинга, которые уменьшают размерность изображения (сворачивают его) и извлекают наиболее важные признаки. На выходе возвращаются encoder и decoder. Для преобразования изображения в вектор нам нужен слой после автоэнкодера, то есть векторное представление изображения, которое в дальнейшем будет использоваться для поиска похожих изображений.
Применение функции summary() к модели покажет описание работы модели слой за слоем. Нужно следить за тем, чтобы размер изображения на входе соответствовал размеру изображения на выходе декодера.
IMG_SHAPE = x.shape[1:]
def build_deep_autoencoder(img_shape, code_size):
H,W,C = img_shape
# encoder
encoder = tf.keras.models.Sequential() # инициализация модели
encoder.add(L.InputLayer(img_shape)) # добавление входного слоя, размер равен размеру изображения
encoder.add(L.Conv2D(filters=32, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=64, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=128, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=256, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Flatten())
encoder.add(L.Dense(code_size))
# decoder
decoder = tf.keras.models.Sequential()
decoder.add(L.InputLayer((code_size,)))
decoder.add(L.Dense(14*14*256))
decoder.add(L.Reshape((14, 14, 256)))
decoder.add(L.Conv2DTranspose(filters=128, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=64, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=32, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=3, kernel_size=(3, 3), strides=2, activation=None, padding='same'))
return encoder, decoder
encoder, decoder = build_deep_autoencoder(IMG_SHAPE, code_size=32)
encoder.summary()
decoder.summary()
Параметры и обучение модели:
inp = L.Input(IMG_SHAPE)
code = encoder(inp)
reconstruction = decoder(code)
autoencoder = tf.keras.models.Model(inputs=inp, outputs=reconstruction)
autoencoder.compile(optimizer="adamax", loss='mse')
autoencoder.fit(x=train_data, y=train_data, epochs=10, verbose=1)В качестве оптимизатора модель использует adamax (https://ru-keras.com/home/ — русскоязычная документация; https://keras.io/api/ — англоязычная), в качестве функции потерь — метрику mse. Обучение проводится десять эпох, то есть десять раз.
Получение изображения в виде вектора с помощью свёрточных автоэнкодеров происходит благодаря тому, что энкодер кодирует изображение, но обратное декодирование не нужно, вместо этого сохраняется слой из модели, который отвечает за кодирование изображения.
images = train_data
codes = encoder.predict(images)
assert len(codes) == len(images)Построение модели подобия изображений при помощи K-ближайших соседей (NearestNeighbours)
После получения представления сжатых данных всех изображений мы можем применить алгоритм K-ближайших соседей для поиска похожих изображений. Он основан на расчёте евклидова расстояния между векторами: чем оно меньше, тем больше похожи изображения.
from sklearn.neighbors import NearestNeighbors
nei_clf = NearestNeighbors(metric="euclidean")
nei_clf.fit(codes)Для того, чтобы увидеть, какие изображения модель считает похожими, мы написали две функции, которые показывают пять и более ближайших, то есть похожих на выбранную фотографий.
def get_similar(image, n_neighbors=5):
assert image.ndim==3,"image must be [batch,height,width,3]"
code = encoder.predict(image[None])
(distances,),(idx,) = nei_clf.kneighbors(code,n_neighbors=n_neighbors)
return distances,images[idx]
def show_similar(image):
distances,neighbors = get_similar(image,n_neighbors=3)
plt.figure(figsize=[8,7])
plt.subplot(1,4,1)
plt.imshow(image)
plt.title("Original image")
for i in range(3):
plt.subplot(1,4,i+2)
plt.imshow(neighbors[i])
plt.title("Dist=%.3f"%distances[i])
plt.show()Преимущества и недостатки использования свёрточных автоэнкодеров
Преимущества:
Этот подход применим, если мы хотим «с нуля» построить свой алгоритм под конкретную задачу и нас не устраивают способы, заложенные в предобученных моделях или готовых решениях.
Недостатки:
Модели нужна более точная настройка параметров для слоёв и больше данных (которые измеряются не в тысячах, а миллионах).
Метод времязатратный, в отличие от применения готовых моделей и библиотек (написание кода заняло примерно 2,5 часа, а в других подходах — 15-25 минут), ведь нужно обучать модель.
Использование предварительно обученных моделей для извлечения признаков из изображения
Получать из изображения признаки можно предварительно обученными моделями-классификаторами. Их очень много, и они тоже используют свёрточные слои и слои пуллинга для получения признаков. Возникает логичный вопрос, зачем же тогда использовать автоэнкодеры?
Во-первых, предварительно обученные модели могут быть созданы для других целей и не подойдут по входным параметрам или архитектуре нейронной сети под вашу задачу, поэтому придётся модель перестраивать или делать самостоятельно.
Во-вторых, предварительно обученные модели на выходе могут давать не тот размер изображения, который нужен, и при загрузке набора изображений и преобразовании их в векторы может не хватить памяти и мощности компьютера. Поэтому при использовании предварительно обученных моделей нужно применять метод понижения размерности PCA. Тогда автоэнкодер понижает размерность и можно его настроить таким образом, чтобы на выходе получался вектор необходимого размера.
Зато с предварительно обученными моделями нет необходимости делать нейронную сеть и настраивать свёрточные слои, достаточно просто взять нужный слой и использовать его для своих целей. Также такие модели обучают на больших наборах, они имеют готовые веса (настройки) для извлечения необходимых признаков, лучше выделяют важные области на изображении.
Чтобы использовать предварительно обученные модели, для начала их нужно загрузить. В качестве примера берём модель VGG16 — свёрточную сеть с тринадцатью слоями, которая была обучена на больших наборах данных (14 миллионов изображений, принадлежащих к 1000 классам).
model = keras.applications.vgg16.VGG16(weights='imagenet', include_top=True)
model.summary()Для загрузки изображений используем функцию:
def load_image(path):
img = image.load_img(path, target_size=model.input_shape[1:3])
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return img, xМодель VGG16 используется для классификации изображений, то есть определения класса, к которому относится изображение (самолёт, вертолёт и т. д.). Все предыдущие слои кодируют изображение в вектор. Такую модель можно полностью скопировать с удалением последнего слоя, оставив только преобразование изображения в вектор.
feat_extractor = Model(inputs=model.input, outputs=model.get_layer("fc2").output)
feat_extractor.summary()
После того, как модель построена, применяем её к нашим данным. Затем получаем вектор признаков каждого изображения и используем метод понижения размерности PCA.
import time
tic = time.perf_counter()
features = []
for i, image_path in enumerate(filelist[:200]):
if i % 500 == 0:
toc = time.perf_counter()
elap = toc-tic;
print("analyzing image %d / %d. Time: %4.4f seconds." % (i, len(images),elap))
tic = time.perf_counter()
img, x = load_image(path);
feat = feat_extractor.predict(x)[0]
features.append(feat)
print('finished extracting features for %d images' % len(images))
from sklearn.decomposition import PCA
features = np.array(features)
pca = PCA(n_components=100)
pca.fit(features)
pca_features = pca.transform(features)
Следующий код показывает, как случайно выбирается вектор из набора (полученный на предыдущем этапе), вычисляются расстояния от него до всех остальных векторов, сортируются по возрастанию и выбираются наиболее близкие.
from scipy.spatial import distance
similar_idx = [ distance.cosine(pca_features[80], feat) for feat in pca_features ]
idx_closest = sorted(range(len(similar_idx)), key=lambda k: similar_idx[k])[1:6] # отображение первых 6 похожих изображений
thumbs = []
for idx in idx_closest:
img = image.load_img(filelist[idx])
img = img.resize((int(img.width * 100 / img.height), 100))
thumbs.append(img)
# concatenate the images into a single image
concat_image = np.concatenate([np.asarray(t) for t in thumbs], axis=1)
# show the image
plt.figure(figsize = (16,12))
plt.imshow(concat_image)Использование готовых библиотек
Поставленную задачу (поиск похожих изображений) можно также решить при помощи готовых библиотек, например face_recognition, созданной на основе библиотеки dlib.
После того, как мы получили изображения с лицами, нужно перевести изображения в вектор. Для этого в face_recognition есть функция face_encodings(), а для сравнения векторов используется функция compare_faces.
Библиотека работает так же, как и нейронные сети, то есть она обучена на наборе изображений (173 Мб в gzip-файле), но, в отличие от предыдущего способа, этот набор состоял только из лиц (в предыдущем способе использовались разные изображения, в том числе животных и транспорта).
# Получаем путь до изображений с вырезанными областями с лицами
photo = glob.glob('pdf_img/*.png')
# Функция для перевода изображения в вектор
def get_vector(train_image):
diff = {}
bad = []
for image in tqdm(train_image):
try:
img = face_recognition.load_image_file(image)
img_enc = face_recognition.face_encodings(img)[0]
diff.update({image:img_enc})
except IndexError:
bad.append(image)
return diff, bad
# Функция для сравнения похожих изображений
def compare_faces(test_image, train_images):
img1 = face_recognition.load_image_file(test_image)
img1_enc = face_recognition.face_encodings(img1)[0]
print('Original_image:')
print(Path(test_image).stem)
Image.fromarray(img1).show()
print('Compared images:')
differences = {}
for name,vec in tqdm(train_images.items()):
try:
result = face_recognition.compare_faces([img1_enc], vec, tolerance=0.49)
differences.update({name:result})
except IndexError:
pass
new_df = {key:value for key,value in differences.items() if value == [True]}
fig = plt.figure(figsize=(15,len(new_df.keys())))
rows,cols = 1, len(new_df.keys())
for idx, i in enumerate(new_df.keys()):
fig.add_subplot(rows, cols, idx+1)
im = Image.open(i)
print(Path(i).stem)
plt.imshow(im)
plt.axis(False)
# Применение функции
compare_faces(photo[9], r)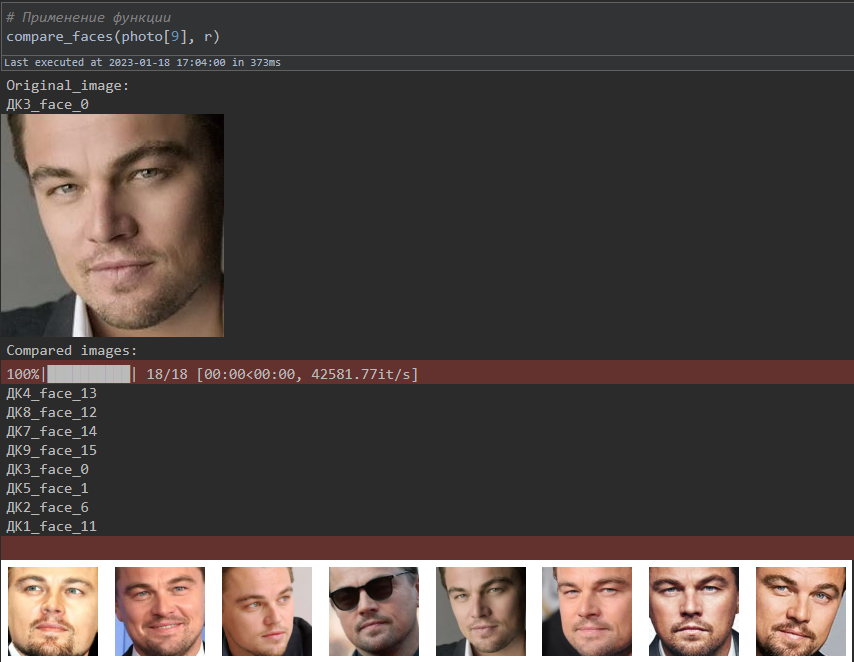
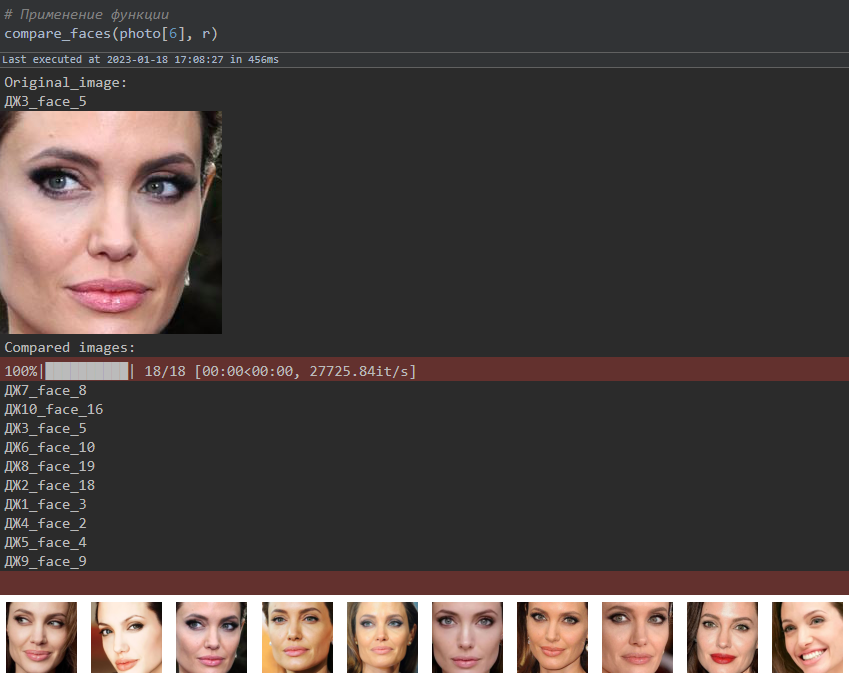
Так можно легко находить похожие фотографии в наборе. Для сравнения изображений точность оказалась около 80 %. В качестве оценки использовалась своя придуманная метрика, причём данные были размечены (то есть изображения были просмотрены и разделены на похожие и нет): если модель находит все похожие изображения и количество непохожих изображений не превышает двух, то результат оценивался как правильный.
У каждого PDF-скана паспорта было уникальное название, и в результате мы получили в виде Excel-файла список названий похожих изображений в паспортах. Для этого написали функцию:
# перевод изображения в вектор
def get_true_images(test_image, train_image):
names = {}
for t in tqdm(test_image):
differences = {}
try:
img1 = face_recognition.load_image_file(t)
img1_enc = face_recognition.face_encodings(img1)[0]
except IndexError:
print(t)
for name, vector in train_image.items():
try:
result = face_recognition.compare_faces([img1_enc], vector, tolerance=0.4)
differences.update({name:result})
except IndexError:
pass
new_df = {key:value for key,value in differences.items() if value == [True]}
names.update({t:list(new_df.keys())})
return names
# получение словаря со списком похожих фотографий
def get_names(dictionary):
new_list = {}
for idx, i in enumerate(list(dictionary.keys())):
b = Path(i).stem
stem = []
for j in list(dictionary.values())[idx]:
a = Path(j).stem
stem.append(a)
new_list.update({b:stem})
data = pd.DataFrame(dict([(k,pd.Series(v)) for k,v in new_list.items()]))
return data
# Использование функции
d = get_names(dictionary)
# Сохранение функции в Excel-файл
d.to_excel('find_faces.xlsx', sheet_name = 'Test')Выводы

Мы проверили подходы к поиску похожих изображений в наборе при помощи их кодирования в векторную форму. Алгоритмы показали, что способны решать поставленную задачу, но их всегда можно улучшить, например, добавлением новых слоёв или предварительной обработкой изображений.
Что мы сделали:
Обработали изображения и привели к нужному формату.
Преобразовали изображения в вектор при помощи автоэнкодера, предварительно обученной модели или готовых библиотек.
Извлекли признаки-векторы, сравнили с набором других векторов и нашли похожие изображения на основе расстояний: чем меньше расстояния, тем более похожи изображения.
Сохранили и выгрузили результаты в Excel-файл.
Из трёх рассмотренных нами подходов готовые библиотеки оказались точнее всего (80-85 %). Автоэнкодеры показали точность в 61 %, а предварительно обученные модели — 70 %.
Мы смогли обнаружить поддельные и старые паспорта, чтобы запустить проверку подозрительных клиентов.
Результаты разработки алгоритмов по поиску похожих изображений пригодятся также для реализации таких задач:
обнаружение поддельных документов;
обнаружение мошенников или подозрительных лиц (при наличии базы данных, стоп-списков и т. д.);
контроль при проходе в офисные здания;
поиск похожих изображений;
поиск фотографий-плагиатов;
обнаружение копий аккаунтов.
Весь представленный код можно найти здесь.
Полезные ссылки:
http://www.vision.caltech.edu/datasets/ — набор данных.
https://pgaleone.eu/neural-networks/2016/11/24/convolutional-autoencoders/ — о свёрточных автоэнкодерах.
https://habr.com/ru/post/348000/ — про построение свёрточных нейронных сетей.
https://pypi.org/project/face-recognition/ — библиотека face_recognition.
fedorro
Дежавю