
Меня зовут Дмитрий Дударев, я технический директор в компании, которая занимается разработкой медицинских VR симуляторов.
Статья написана кожаным мешком, желающим поделиться опытом автоматизации некоторых сфер компании с помощью ИИ.
Переводы с контекстом
Внутри симуляторов происходят обследования, диагностика и лечение виртуальных пациентов. Все это сопровождается тоннами медицинских текстов с диалогами, историями болезней, результатами анализов и тд. Для управления этими данными у нас есть свой веб сервис, где медицинские эксперты могут создавать новые сценарии и редактировать контент. Тексты должны быть переведены на восемь разных языков и все это осложняется постоянно обновляющимися данными.
Раньше для переводов мы использовали аутсорс переводчиков и системы краудтранслейтинга, где множество неизвестных людей в специальном онлайн сервисе накидывалось на куски текстов и переводили это за большие деньги и с кучей ошибок (после переводов данные проверяюстся мед экспертами - носителями языков).
А потом появился chatGPT, поразивший меня своими возможностями. Он сходу умеет переводить тексты лучше существовавших до него специализированных нейросетей - переводчиков, и, в отличие от них, способен еще и учитывать контекст.
Я сразу купил API и сделал телеграм бота для предварительного тестирования (API OpenAI в России пока работает без VPN). Результаты превзошли все ожидания. Мы использовали бота не только для переводов, но и для придумывания новых текстов вроде имен пациентов и их ответов на некоторые вопросы.

Следующим шагом мы встроили интерфейс нейронки в наш веб сервис и теперь можем нажатием одной кнопки перевести все десятки тысяч строк текста на 8 языков.
Конечно, задача переводов текстов для медицинских симуляторов очень ответственная. Мы не хотим, чтобы запись в виртуальную карту пациента из "неоформленный стул" превратилась в "undecorated chair", поэтому для каждого типа данных мы указываем контекст. Для диалогов, например, в начало каждого запроса добавляется текст:
"Переведи следующе ответы пациента на вопросы доктора на арабский язык. Каждая строка - новый ответ. Сохраняй форматирование."
Конечно, критические вещи проверяются медицинскими экспертами, но от огромной части работы нейронка нас освободила.
Оператор техподдержки
В целом, с переводами все просто. Гораздо более интересно применение нейронки в качестве оператора техподдержки, способного работать 24/7 на любых языках, отвечать мгновенно и знать все тонкости наших проектов и способы разрешения технических проблем.
Для того, чтобы GPT мог отвечать на вопросы, специфичные для наших продуктов, нужно ему как-то скормить тонну текстов документаций, инструкций и траблшутингов. Для этого есть три способа:
Prompt-engineering.
Заключается, как и в задаче с переводами, в добавлении в начало каждого запроса все необходимые текстовые данные. Очевидно, при таком способе мы сразу упремся в максимальную длину контекста (обычно это 4096 токенов) или в 0 на банковском счету.
Что такое токен
Fine-tuning.
Это механизм дообучения нейронки, в котором меняются сами веса модели. Вы предоставляете ей множество примеров "запрос - ответ" и она учится их использовать уже без добавления контекста в каждый запрос. Для этого у OpenAI есть специальный API. Такой подход первым бросился мне в глаза, но у него есть недостатки:
Есть сложности с дообучением при изменениях в документах.
Предназначен не столько для накопления базы знаний, сколько для приобретения навыков общения.
Тоже стоит денег.
Использование LlamaIndex.
Это нечто среднее между первыми двумя вариантами. LlamaIndex - это система, которая может прочитать один раз кучу ваших документов и с помощью OpeanAI API создать индекс файл, содержащий ваши данные в виде векторов. Этот файл создается один раз и позволяет по запросу на естественном языке вытащить необходимый кусок текста, который далее можно скормить GPT в качестве начальной информации. Т.е. вместо того, чтобы в начало каждого сообщения от клиента добавлять все гигабайты ваших документов, вы можете добавить только маленький нужный кусок данных, связанный с вопросом клиента. Ну и плюс еще предыдущие сообщения для удерживания контекста.
Пример использования LlamaIndex:
pip install llama-indexСоздание Index файла из файлов:
import os
os.environ["OPENAI_API_KEY"] = 'YOUR_OPENAI_API_KEY'
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = GPTSimpleVectorIndex.from_documents(documents)Сохраниение файла и использование для запроса данных:
# save to disk
index.save_to_disk('index.json')
# load from disk
index = GPTSimpleVectorIndex.load_from_disk('index.json')
index.query("<question_text>?") Итого после прихода сообщения от пользователя можно сформировать запрос нейронке, соединив несколько частей:
"Ты специалист техподдержки в компании ***. Компания занимается разработкой медицинских VR симуляторов. Вежливо отвечай на вопрос клиента на том же языке, на котором он говорит. Отвечай точно, не придумывай лишнего. В случае затруднения отвечай что позовешь специалиста.
Ниже представлена информация о наших продуктах:"Информация, полученная из индекс файла в ответ на сумму последних нескольких сообщений в чате
Сумма последних нескольких сообщений в чате
Подход оказался удивительно эффективным. Бот отвечает корректно на нужном языке и в полном соответствии с нашими документами. В случае сомнений нейронка говорит, что позовет оператора, что по ключевому слову "оператор" отслеживается ботом и передается уведомление уже нашим биологическим операторам.
Общие мысли о GPT
GPT - всего лишь языковая модель, обученная продолжать текст, но для успешного продолжения текста нужно иметь в голове глубокое понимание взаимосвязей между сущностями. Да, у нейронки пока нет визуальных, аудиальных, тактильных и других дополнительных ассоциаций со словами, но это не мешает ей уже сейчас уметь прикидываться человком с ограниченным объемом знаний и индивидуальными чертами характера.
GPT показал удивительную эмерджентность, когда количество переходит в качество. С повышением количества параметров умения росли скачкообразно:
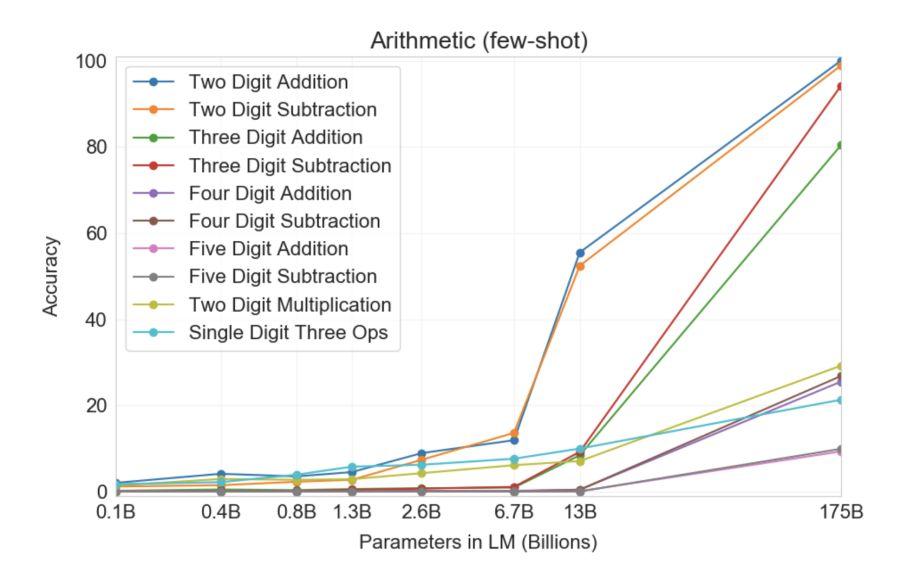
Сами разработчики уже во всю заявляют о скором выходе действительно сильного искусственного интеллекта. Не знаю пока радоваться этому событию или сожалеть о грядущей утере какой либо ценности человеческих мозгов, но нас определенно ждет новый мир!
Комментарии (13)

aborouhin
09.04.2023 16:46+4Я бы дополнил список перспектив следующим оптимистичным прогнозом - нейронки как станут помощником в части задач, так и покажут наконец бессмысленность выполнения другой их части.
Скажем, в любой более или менее большой конторе востребован талант писать длинные витиеватые бумажки. Письма, служебки, регламенты, инструкции, несть им числа. Я уж молчу про курсовые/дипломы/диссертации. Сейчас мы сталкиваемся с ситуацией, что (а) теперь такое же по кратким вводным может написать нейронка и (б) чтобы понять, о чём, собственно, речь, можно скормить текст для резюмирования нейронке. В результате, надеюсь, даже самым большим фанатам канцелярита и деловых обыкновений станет очевидна бессмысленность подобной работы, и мы наконец, станем писать коротко, тезисно/таблично/схематично и только по делу. Иными словами, возобладает принцип "пиши не так, как за тебя могла бы написать нейросеть, а так, как будто ты ставишь задачу нейросети". Или, иными словами, "ту работу, которую за тебя может выполнить нейросеть, вероятно, не стóит выполнять вообще".
К этому выводу, конечно, и без всяких нейронок давно пора было прийти :)


Wesha
09.04.2023 16:46Я вижу несколько по-другому
1) Халявщики начнут иллюстрировать всё, что попало, ИИ-картинками. Ну, знаете, шесть пальцев, искорёженные руки, зверские лица, растущая на берёзе репа, сова с торчащей откуда-нибудь рукой и т.п.
2) Дети начнут, разглядывая эти картинки, впитывать, что "реальность должна быть вот такой", а чо, ведь картинки очень красивые и реалистичные!
3) Через пару поколений имеем человечество, которое всерьёз считает, что у совы откуда-нибудь торчит рука, репа растёт на берёзах, а семена надо поливать напитком Brawnd, потому что в нём же витамины!
N-Cube
09.04.2023 16:46И без нейросетей многие люди уверены, что «булки растут на деревьях» - это чем-то отличается? А уж что творится в профессиональных сферах… скажем, многие профессора геологии и геофизики твердо верят, что есть отдельная гравитация Буге (от глубинных пород) со своими физическими свойствами, есть гравитация в свободном воздухе (от геологически интересных объектов) и прочие, потому что так во всех книжках написано же (на самом деле, это просто продукты обработки результатов измерений для целей визуализации и, когда-то давно, ручного анализа)… а вопрос об измеряемой гравитации считают неприличным («мы с таким не работаем, это пусть физики изучают»). Лучше уж нейросети, их хоть переобучать и дообучать можно, в отличие от людей.

Sipaha
09.04.2023 16:46Как же хорошо, что сейчас интернет состоит только из верной и непротиворечивой информации, которая никак не искажает реальность.
N-Cube
09.04.2023 16:46Интернет тут ни при чем, потому что просто хранит информацию. Скажем, несколько сотен лет назад путешественники про страны плешивых или псоголовых людей рассказывали. И детей во все века начинали учить сказками, а там такое… и технологии на все это не влияют - общество «плоскоземельщиков» и в интернете есть, а раньше газету выпускали, и ничего-то их не смущает, запросто можно и через спутниковый интернет вещать про плоскую землю.

phenik
09.04.2023 16:46В случае сомнений нейронка говорит, что позовет оператора, что по ключевому слову "оператор" отслеживается ботом и передается уведомление уже нашим биологическим операторам.
В чем эти сомнения? Критический и логический уровни мышления эта технология еще не освоила, только ассоциативный.
GPT показал удивительную эмерджентность, когда количество переходит в качество. С повышением количества параметров умения росли скачкообразно
Тут достаточно просто, не требуется привлекать для этого мифическую эмерджентность. Объем обучающих выборок растет, в них все больше примеров операций с числами. Поэтому ответы становятся все более точными для большего количества вопросов на эту тему. Нужно только иметь в виду, что чисел и операций с ними бесконечное число, и их все не возможно привести в обучающей выборке, поэтому всегда найдутся задачи на которые чат даст не правильный ответ. Частично эту проблему решат плагины подключающие мат. пакеты. Однако и для них чату нужно правильно сформулировать задачу, чтобы они правильно произвели вычисления. По этой причине результаты вычислений, особенно сложных, придется контролировать всегда. В этом переводе мнение независимых исследователей математического дарования чата. Новая версия работает лучше, но принципиально ситуация не поменялась. Для этого нужно улучшать архитектуру сети, чтобы улучшить возможности обобщаемости примеров, и приблизить их к возможностям человека.

Gryphon88
09.04.2023 16:46Вопросы больше организационные. Судя по строке
Я сразу купил API и сделал телеграм бота для предварительного тестирования (API OpenAI в России пока работает без VPN).
я предполагаю, что Вы работаете с ChatGPT из РФ и стартап у Вас зарегистрирован тут же.
- Получается трансграничная передача данных пациентов, т.е. нарушение разом закона о ПЛ и медицинской тайны. Что юристы по этому поводу говорят?
- Не страшно пользоваться зарубежный SaaS в текущих условиях? И мне интересно, как использование ChatGPT в РФ в коммерческих целях согласуется с их EULA и лицензированием :)

Dudarion Автор
09.04.2023 16:46Все наши пациенты виртуальные, с искусственно придуманными показателями.
Мы не используем GPT в РФ.

semenyakinVS
09.04.2023 16:46Нет ли трудностей с приобретением из России доступа к GPT-нейронкам?
Dudarion Автор
09.04.2023 16:46+1Их API не требует VPN для работы из России, но для покупки подписки, требуется иностранная карта и аккаунт
Maxmyd
У меня другой вариант ответа :) В каждом из вопросов пропущена пара слов. Я бы добавил "в течение следующих 50 лет". Без этого ограничения ответы бессмысленны