

Давайте поговорим о способе защиты сервисов от перегрузки с помощью троттлинга входящего потока запросов. Он может пригодиться в ситуациях снижения производительности конечного сервиса, когда на какой-то период его нужно разгрузить, дав возможность прийти в себя.
Эта статья от Антона Колесова, технического руководителя по развитию интеграции бизнес-систем Nexign, будет полезна инженерам по развитию и эксплуатации высоконагруженных систем, а также руководителям технических групп, сталкивающихся с проблемами перегрузок.
Запросы растут, скорость падает
Когда приложение перестает справляться с входящим потоком запросов, время обработки запросов в нем начинает увеличиваться. Это приводит к тому, что влияние может распространиться за пределы исходного сервиса на более глобальный уровень. В ожидании повиснут цепочки комплексных сценариев, скопятся очереди сообщений, исчерпаются пулы доступных соединений на стороне приложений или даже оборудования.
Изначальные причины могут быть разные: возросший рейт входящих запросов, который текущий сайзинг уже не может переварить, задержки на сети, сломавшиеся планы запросов БД и т.д.
Практика также показывает, что в таких ситуациях начинается каскадный рост нагрузки. Пользователи получают ошибки или наблюдают долгие загрузки и начинают обновлять страницы личных кабинетов, перелогиниваться, повторять заказы, тем самым нагружая деградирующий сервис еще сильнее. От пользователей не отстают и внутренние механизмы переповторов ошибочных запросов. А для восстановления сервиса, наоборот, требуется снижение интенсивности обращений к нему, вплоть до полной его изоляции.
Как защищаются обычно?
При такой постановке задачи, защита должна строиться от ограничений – нужно либо ограничивать поток поступающих запросов, либо временно его перекрывать.
Существуют широко применяемые паттерны такой защиты:
Circuit Breaker (CB). Задача будет сводиться к отсечению проблемного сервиса или части его инстансов при определенном изменении в поведении.
Ограничение пулов соединений. Установка лимитов на пулах соединений у приложений или балансировщиков.
Эти способы подразумевают установку статичных настроек состояний-триггеров CB (ожидаемое время ответа, код ответа, сочетание этих и других показателей) или количества соединений в пулах. Если изначально не было заложено архитектурно, то при большом количестве сервисов эти подходы будут достаточно трудоемки в реализации и поддержке. А в идеале ограничения нужны не по сервисам, а по конкретным API, чтобы изолировать не только приложения друг от друга, но и конечные функции в рамках одного приложения.
Динамический подход
Рассмотрим альтернативный подход, его плюсом будет автоматическая реакция на проблемы производительности, без необходимости выставления статических порогов и прочих настроек под каждую функцию.
Для его реализации потребуется доработать логику проксирования запросов на точке входа в контур сервисов (API Gateway, либо балансировщик). На этом узле в процесс проксирования добавляется логика сбора статистики производительности запросов каждого типа и выявления отклонений от нормы по этим данным.
Ядром API GATEWAY в нашем случае выступает NGINX, поэтому с технической точки зрения функциональность реализована в виде модуля на C. Его задача – собирать статистику производительности функций в разрезе ключей (например, метод + функция API), выявлять отклонения и, при необходимости, зарезать входящий поток запросов путем выставления лимитов доступных соединений к апстримам.
Сбор статистики базируется на расчете скользящих средних.
Скользящая средняя (moving average, MA) – в общем случае это усредненное значение за определенный интервал времени. У нас будет использоваться для определения тренда изменений.

Исходные данные по скорости выполнения запроса в данном случае складываются в достаточно волатильные значения. Расчет скользящей позволяет получить более сглаженные значения:

Также наглядно видно еще одно свойство скользящих – количество интервалов, использованное для построения, напрямую влияет на характер получаемой кривой. Чем больше интервалов, тем более сглажен результирующий график относительно исходных сырых данных.
Для дальнейшего раскрытия логики введем следующие термины:
Fast MA – строится за малое количество интервалов, из-за чего получается более чувствительна к изменениям и отражает текущее состояние.
Slow MA – по большему набору интервалов и поэтому менее чувствительна к изменениям. Поэтому она берется в качестве нормального состояния.
Производительность приложения нужно рассматривать комплексно. Поэтому в качестве статистических данных будут использоваться скорости выполнения запросов (latency) и количество соединений балансировщика, задействованных в их обработке (connections). Сбор производится в разрезе ключей.
По собранным исходным данным latency и connection строятся скользящие. А отношение этих скользящих latency к connection будет являться показателем производительности ключа (метод + API):

Визуализируя Fast и Slow, получим следующее предствление:

Когда Fast превышает Slow, то это означает наличие отклонения. Но так Fast более волатильно, то необходимо дать некий рукав допустимого отклонения текущего состояния от референсного. Для этого к Slow будет применяться некий повышающий коэффициент, назовем его Burst.
Slow x Burst – это реальный сигнальный порог, превышение которого значениями Fast уже говорит о наличии существенного отклонения текущего состояния от номинального:
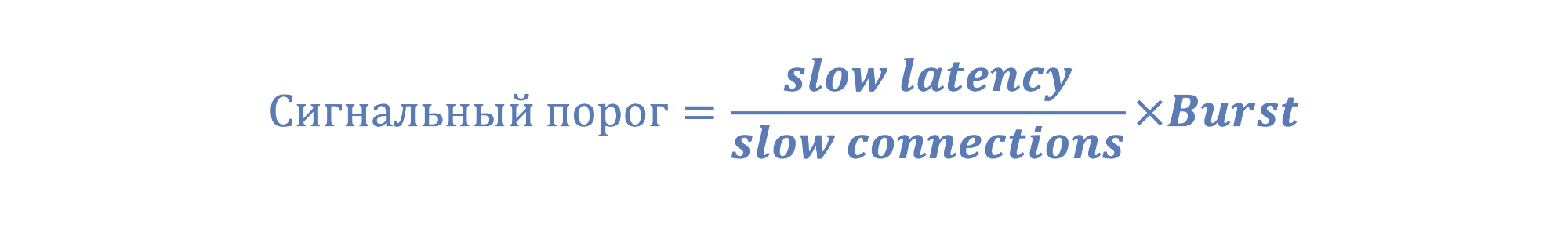
Значение Burst будет регулировать чувствительность к отклонениям текущего показателя производительности.

Алгоритм реакции на отклонение
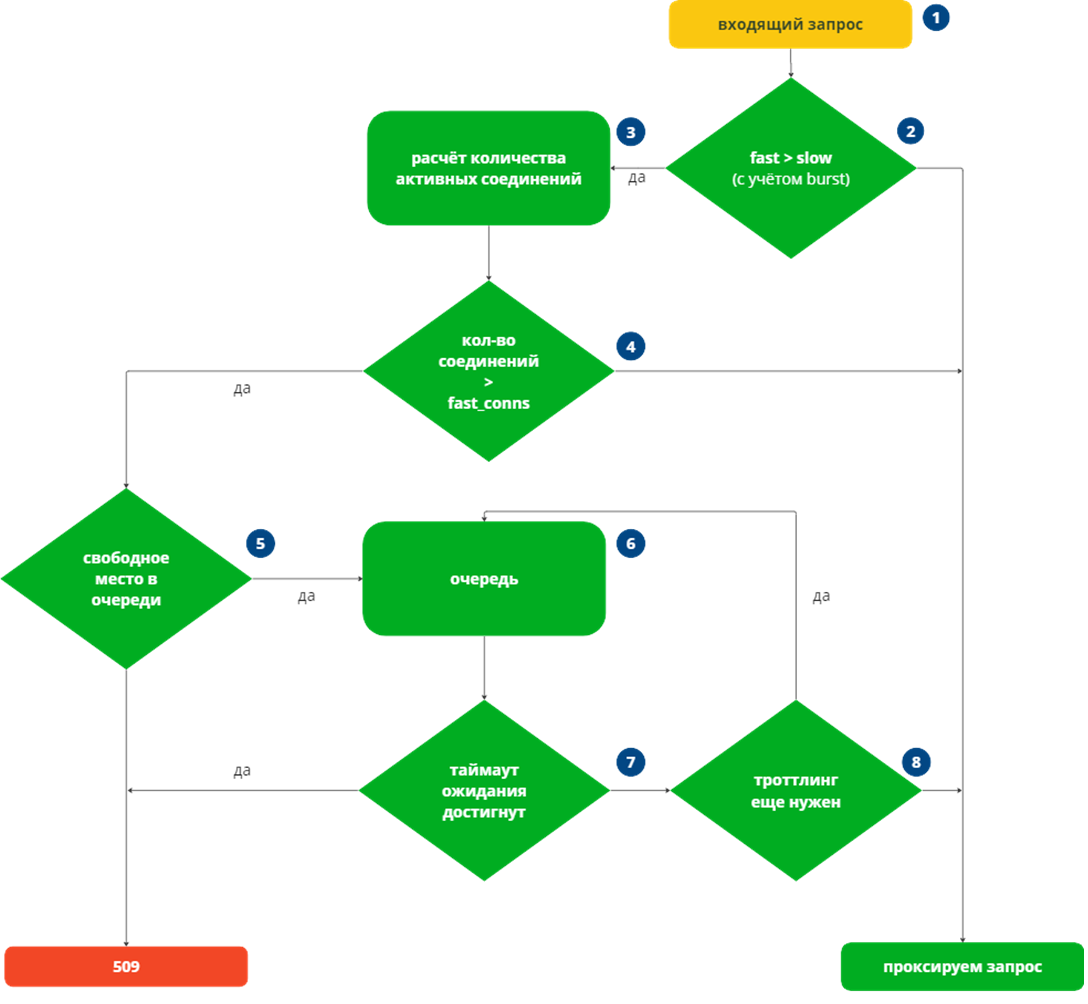
Рассмотрим алгоритм реакции, который должен работать после выявления отклонения. Так как момент пересечения Fast и сигнального порога означает появление проблемы с производительностью функции, то по каждому запросу в рамках ключа начинает работать логика модуля по обработке отклонений.
Для последующих шагов обработки нужно понимать влияет ли отклонение производительности на рост соединений. Если проблема наблюдается у непопулярного сервиса с низкий рейтом запросов, то защитная реакция не требуется. В то время как у высоконагруженных сервисов просадка производительности может привести к лавинообразному росту соединений и нежелательному влиянию на «здоровые» сервисы.
Для принятия решения о реакции на отклонение строим отдельный показатель доступных соединений Avail conns:

При превышении сигнального порога фиксируется фактическое количество занятых функцией сетевых соединений и сравнивается с расчетным Avail conns:
Если текущие соединения ≤ Avail conns, то влияние не предвидится и запрос просто проксируется к сервису.
Если текущие соединения > Avail conns , то просадка производительности сервиса имеет влияние и ситуация с перегрузкой может ухудшаться. На такие события необходима реакция.
Реакция заключается в прекращении прямого проксирования запросов к сервису и постановкой их очереди ожидания. Попадая в эту очередь, запрос будет ожидать высвобождения коннектов из пула доступных Avail conns. Очередь должна иметь характеристики размера и ttl нахождения запроса в ней. При заполненной очереди поступающие запросы по этому ключу отбиваются, а запросы, которые попали в очередь, но не дождались освобождения соединения – опять же отбиваются по таймауту.
Для обеспечения минимальной пропускной способности можно реализовать настройку Min conns, которая позволит держать доступными минимальное количество коннектов сервису в рамках ключа, не позволяя опустить Avail conns ниже заданного значения.
Схематично логику контроля отклонения и реакции них можно изобразить следующим образом:
Преимущества динамического троттлинга
В данной статье мы рассмотрели возможный алгоритм работы механизма динамического троттлинга. Несмотря на относительную сложность реализации, такой подход несет в себе ряд плюсов.
Самостоятельно подстраивается под текущую нагрузку, поэтому не требует вмешательства в части настроек и корректировок.
Работает на уровне инфраструктуры, поэтому не требует доработок на стороне сервисов.
Более точен в сравнении со стандартными статическими механизмами лимитирования.
С покрытием мониторингом дает новый набор данных для аналитики системных проблем в разрезе конкретных функций.
Если решите опробовать динамический троттлинг в своих проектах – обязательно поделитесь результатами в комментариях.