
Что такое имя? Имя — это ярлык, дескриптор, указатель в вашей памяти. Это краткое изложение сложной идеи. Оно позволяет ссылаться на «экономику» или «догфудинг» в середине предложения, избегая развернутого на три абзаца объяснения термина.
Если представить, что разработка программного обеспечения — это просто распределение данных по ячейкам и их маркировка, то становится понятно, почему именование объектов является одной из двух сложных задач в информатике. Объем рабочей памяти мозга ограничен, и хорошее имя позволяет использовать его максимально эффективно. Хорошее имя — всегда лаконичное, вызывающее ассоциации и подходящее по контексту. Оно снижает когнитивную нагрузку и лучше отпечатывается в сознании. Плохое имя — это неясное, вводящее в заблуждение, расплывчатое или явно содержащее недостоверную информацию.
Под катом разработчик Джозеф Гласс* делится правилами эффективного нейминга и разбирает их на практических примерах.
*Обращаем ваше внимание, что позиция автора может не всегда совпадать с мнением МойОфис.
Хорошие имена
Действительно хорошее имя при разработке ПО — это имя осмысленное, описательное, короткое, унифицированное и уникальное. Вы наверняка заметили, что значения слов «описательное» и «короткое» диаметрально противоположны, как и слов «унифицированное» и «уникальное». Решений нет, есть только компромиссы.
Описательные имена безопасны, удобочитаемы и понятны. Они говорят о том, с чем именно вы имеете дело, позволяют быстро разобраться в контексте и не требуют от вас быть экспертом в кодовой базе или уметь читали мысли. Я точно понимаю назначение класса BasicReviewableFlaggedPostSerializer, когда вижу его имя в первый раз. Но такие имена очень громоздки и неудобочитаемы.
Короткие имена удобны в работе, удобочитаемы и лаконичны, их легко находить в коде. В них используются аббревиатуры и сокращения, что помогает не отвлекаться и сосредоточиться на логике. Имя pc_auth_token выглядит гораздо проще по сравнению с premium_customer_http_authentication_token. Но короткие имена порой не дают четкого представления об объекте, приводя к путанице, и бывают непонятными без точного понимания контекста.
Унифицированные имена помещают объект в более широкий и знакомый контекст (например, указывают на то, что объект принадлежит определенной группе или выполняет стандартное действие). Уникальные имена выделяются на фоне других, что позволяет не перепутать разные концепции, имеющие поверхностное сходство, и при этом избежать использования неинформативных и общих имен типа Foo.bar или «DataHandler».
Обеспечение баланса между этими противоположными принципами и есть то, что делает хороший нейминг таким сложным. Однако его сила заключается в возможности передачи в одном слове достаточного объема информации. Точный баланс зависит от размера кодовой базы и команды разработчиков, сложности домена, частоты использования и множества других факторов.
Лично я предпочитаю описательные и унифицированные имена по умолчанию, а для часто повторяющихся переменных и классов назначаю короткие имена.
Соглашения, на помощь!
К счастью, люди, которые гораздо умнее нас, долго и упорно думали над этой проблемой и разработали несколько действительно ценных рекомендаций.
Соглашения передают намерения как по форме, так и по содержанию. Например, в соглашениях об именовании в Ruby рекомендуется описывать классы в PascalCase (форма) и предпочтительно конкретными существительными, относящимися к объекту (содержание). Поэтому вы можете видеть имена User или CustomerAccount и распознавать их как классы. Напротив, при именовании методов в Ruby нужно использовать snake_case (с нижними подчеркиваниями) и предпочтительно, глаголы в полной форме (например, publish, invite_user, find_all). Имя метода, заканчивающееся восклицательным знаком (например, archive!) предупреждает, что при вызове он изменяет объект, к которому он прикреплен. Наличие в имени вопросительного знака (а ля archived?) говорит о том, что метод возвращает булево значение true или false. Модули, константы, внешние ключи, единственное и множественное число, падежи — в совокупности это создает уникальный стиль с легко узнаваемыми сокращениями. Благодаря использованию единообразно меняющихся форм, соглашения придают именам четкость и выразительность без увеличения их длины.
«Глупая последовательность — суеверие недалеких умов», — Ральф Уолдо Эмерсон, не программист
Иногда соглашения вступают в прямое противоречие с нашими принципами именования. Разработчики на Ruby часто используют k и v для обозначения ключа (key) и значения (value). Разумеется, столь короткие имена имеют смысл только в том случае, если вы знаете или интуитивно понимаете суть соглашения. В JavaScript часто встречаются i, j и последующие буквы алфавита в качестве переменных итерации. Однако имя i вовсе не выглядит описательным, а j — и того меньше. Но они по крайней мере говорят вам: «Вот одна переменная итерации, а вот другая», и иногда этого бывает достаточно. Но при использовании не имеющих смысла имен переменных все же стоит придерживаться общепринятых соглашений.
Ознакомьтесь с соглашениями об именовании для используемого вами языка или фреймворка и следуйте им. И желательно установить хороший линтер, который сделает их соблюдение простым и автоматическим.
Создавайте собственные соглашения
У вас могут быть собственные требования к коду. Характерные для него паттерны организации логики. Подумайте о том, как сделать их очевидными. Проанализируйте возможность использования пространств имен для обозначения иерархий. Используйте префиксы (такие, как user_ и admin_) для группирования связанных классов. Используйте суффиксы типа _job или _spec для идентификации заданий и тестов. Они упорядочивают кодовую базу, указывают на намерения и часто требуются для взаимодействия с популярными библиотеками.
Обеспечивайте согласованность
Хороший линтер проверяет синтаксис и формы имен, но за семантической согласованностью вам придется следить самостоятельно. Если у вас есть функция типа searchKeyword(needle, haystack), не используйте функцию searchName(haystack, needle) в другом классе. (PHP, я тебя вижу!)
Согласованность — ваш друг. Применительно к стилю согласованность всегда выигрывает у хитроумных решений. Меня не волнует, используете ли вы dd/mm/yyyy или mm/dd/yyyy, просто не смешивайте их вместе. Согласованность предсказуема, а предсказуемость уменьшает количество ошибок в коде. Если я взгляну на вашу кодовую базу и увижу fetchValue(), getValue() и retrieveValue(), то понятия не буду иметь, чем они отличаются. Если это одинаковые функции, назовите их одинаково. Если они разные, убедитесь, что они всегда отличаются в одном и том же аспекте.
«Последовательность — последнее прибежище людей, лишенных воображения», — Оскар Уайльд, определенно не программист
«Формы имен» — инструмент согласованности
Один из инструментов, который пригодится вам в поисках согласованности, — «формы имен». У Фелиенн Херманс есть хорошее видео, объясняющее их назначение. Также вы можете прочитать статью Д. Файтельсона «Как разработчики выбирают имена», если хотите полностью разобраться в теме.
Суть идеи заключается в том, что любую переменную можно описать десятком разных способов. Создание «формы», определяющей структуру имен, сделает вашу кодовую базу более согласованной. Давайте на секунду вернемся к форматам дат. Их можно писать по-разному: 24 февраля 1997 года, 02/24/97, 24/02/97, 24 февраля 97 года. Но, скажем, вы хотите изменить день, например, в дате «01/01/01». Из контекста неясно, является ли первые две цифры «01» месяцем или днем. Нам нужен заданный произвольный шаблон, например, dd/mm/yyy, чтобы понимать, что есть что. Аналогичным образом, «форма имени» устанавливает шаблон для имен переменных.
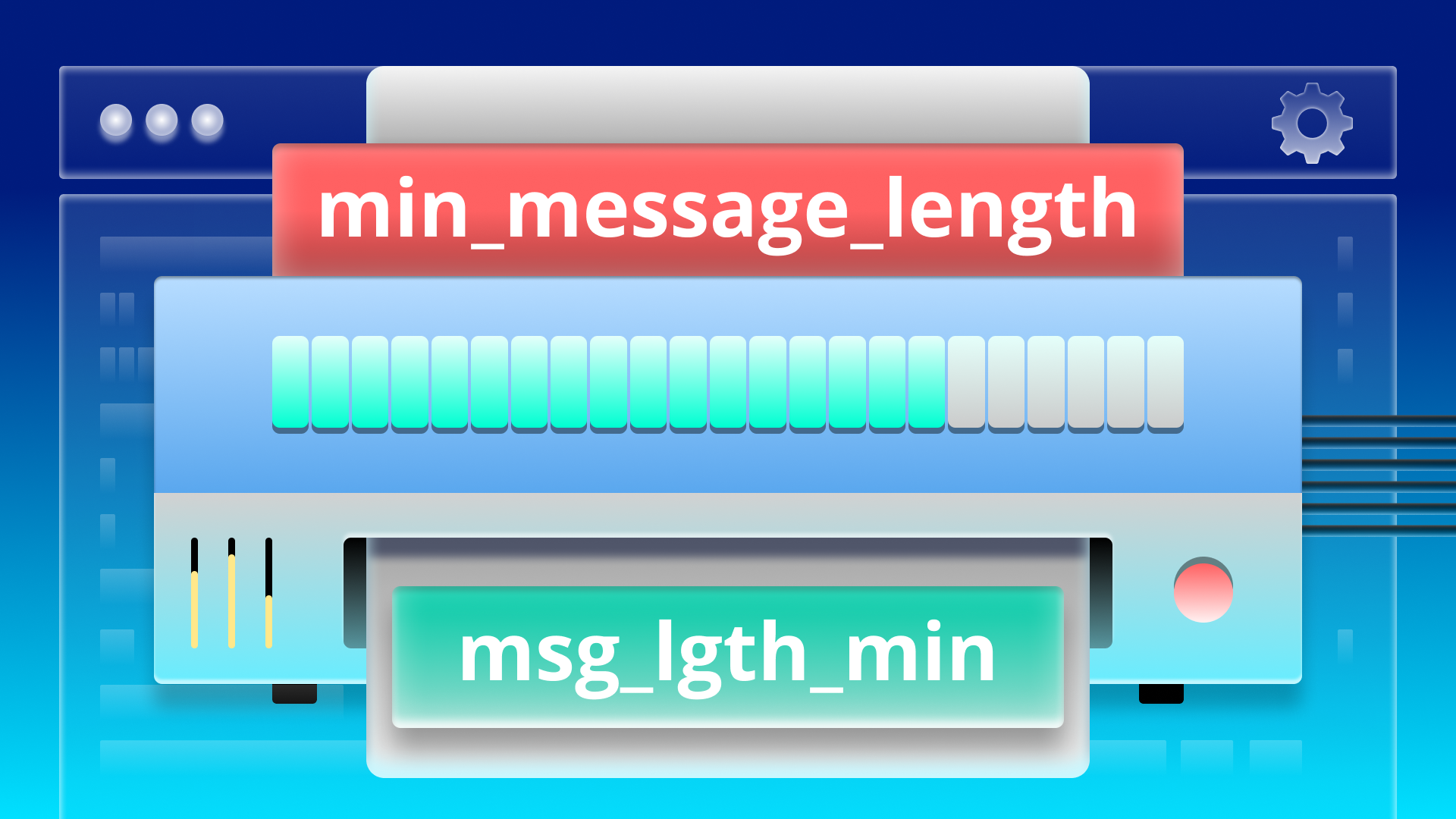
Рассмотрим простой пример переменной, возвращающей минимально допустимую длину сообщения. Как ее можно назвать?
min_message_length
minimum_message_len
message_lgth_min
minimum_msg_len
msg_lgth_minМожно придумать более десятка осмысленных имен переменных, даже ограничившись тремя словами. Вероятность того, что два разработчика назовут переменную одинаково, невелика. Вероятность того, что это сделают восемь разных разработчиков из двух разных команд, практически нулевая. А чем больше имен, тем больше умственной энергии тратится на то, чтобы понять, идет ли речь идет об одной и той же переменной, или между ними имеется тонкое различие.
Но если создать простую «форму имени»: прилагательное/существительное/несокращенное_измерение, то мы получим точное имя minimum_message_length или, по крайней мере, что-то очень понятное для понимания.
Возможно, в своем проекте вы зададите предпочтительные сокращения (например, «len», а не «lgth») или скажете, что прилагательные должны идти перед существительными (active_user, blocked_user). Затратив немного умственной энергии на обдумывание этого вопроса, вы сэкономите массу времени на переименование объектов в дальнейшем.
Акронимы, инициалы и аббревиатуры — инструменты сокращения
Аббревиатуры жертвуют ясностью ради краткости. Посмотрите раздел «Короткие имена» выше и решите, стоит ли это делать в вашем случае.
Акронимы — это здорово. Мы ничего не добьемся, если будем писать «Аpplication Programing Interface Key» вместо «API-key». «Лазер» и «радар» — это уже даже не акронимы, а обычные слова. Но в ИТ столько акронимов, что и не сосчитать. Иногда мы слишком охотно отсекаем 90% букв из фразы и делаем вид, что это облегчает ее понимание.
Сокращайте многословные имена, которые часто повторяются, но не переусердствуйте. Напишите глоссарий с их определениями и/или поместите полное значение в комментариях над классом.
Дополнительные материалы
Я знаю: правила созданы для того, чтобы их нарушать. Но если вы вдруг почувствуете, что вас сковывают эти условные соглашения, помните следующее. По какой стороне дороги вы едете — тоже условное правило. условный != неважный
Если описанной выше информации вам показалось недостаточно, ознакомьтесь с главой 2 «Содержательные имена» книги «Чистый код».
Что такое сложность именования?

Мы уже разобрались с хорошими именами, теперь давайте поговорим о... нет, не о плохих именах, не подумайте. Только о сложных случаях. О системах, в которых имена становятся сложными. Я назову этот аспект «сложностью именования».
Сложность именования — это когда в вашей кодовой базе 28 различных аббревиатур, но если спросить, то никто не знает точно, что на самом деле означают 13 из них. Это жаргон, часто меняющаяся терминология, коллизии и конкурирующие стандарты именования между фронтендом и бэкендом. Семантический дрейф. Это происходит, когда плохо понимаемые классы постепенно выходят за рамки своего первоначального назначения.
Это когда основная сущность известна под разными именами разным командам. «Это модель AssociatedGroup, но в базе данных она записана как usr_team_id_no. При этом в компании клиента она называется «франчайзинговые партнеры». Ах, да, за исключением их маркетинговой команды, которая провела ребрендинг во время последних продаж, переименовав «команды» в «бизнес-кадры» или что-то в этом роде».
Это когда две абсолютно несвязанные сущности имеют одно и то же имя или имя атрибута. «Есть таблица базы данных project_status и компонент реакции ProjectStatus, но это не один и тот же проект и определенно не один и тот же статус».
Думаю, вы понимаете, о чем я говорю.
Факторы риска
Сложность именования накапливается со временем, как и любой другой вид технического долга. Иногда это постепенный дрейф по мере расширения функциональности и использования кода не по назначению. Иногда это кардинальный перелом в ребрендинге или компании. И, как любая другая форма долга, она масштабируется в зависимости от размера кодовой базы, величины компании и сложности бизнес-области. Новый проект с тремя разработчиками сильно отличается от 10-летней системы здравоохранения, в которой необходимо обновить онтологию, добавив новые названия болезней.
И в чем суть проблемы?
Хорошо, (вы можете возразить), все меняется, объекты переименовываются, но по сути все остается тем же самым. «Как розу ты ни назови» и все в том же духе. Подумаешь!
Проблема заключается в повышенной когнитивной нагрузке, трате времени разработчиков на расшифровку устаревшей терминологии, выгорании и ошибках в коде. Последнее — «глючный код» — особенно плохо. Частым источником глюков является сильное расхождение между вашим представлением о том, что должно произойти, и тем, что произойдет на самом деле. Обманчивые имена опасны.
Однажды я совершил эпичную ошибку, вызвав функцию deleteResource() и предположив, что она удалит ресурс. Вот глупец! Я провел день за поиском по всей кодовой базе логики, отмечающей ресурс как удаленный. Я наивно полагал, что она будет находиться в deleteResource(). Нет? Может быть, это sqlSetResourceDeleted()? Хм. Это sqlCoreDeleted()? Нет... А... вот оно, прямо в prepResourceOperation(). И почему это раньше не пришло в голову!?
Помните, я говорил, что плохие имена — те, что вводят в заблуждение? Плохое имя функции deleteResource() будет врать прямо вам в лицо, а prepResourceOperation() скромно стоять в сторонке, не произнося ни слова.
Кодинг с подобными умственными нагрузками и когнитивным жонглированием — непростое занятие. В конце концов, вы сможете добиться успеха, но это излишне сложно и намного больше чревато ошибками. Это затрудняет погружение новых разработчиков в кодовую базу и снижает вероятность того, что кто-то отважится на рефакторинг старого модуля-переростка, обросшего мхом.
Практикум. Проводим аудит имен

Мы много говорили, теперь проверим все на практике. Я собираюсь впервые погрузиться в приложение Discourse с открытым исходным кодом на фреймворке Ruby on Rails, проанализировать сложность его имен, посмотреть на соглашения и получить представление о шаблонах именования, которым я должен следовать.
Если вы хотите проанализировать не-Rails приложение, то можете сделать это на уровне базы данных, используя что-то вроде List all tables in PSQL.
-- PostgreSQL
SELECT distinct column_name
FROM information_schema.columns
WHERE table_schema = 'public'
ORDER BY column_name ASC;Во-первых, составим список всех наших моделей.
# В консоли Rails
Rails.application.eager_load!
# Можно использовать ApplicationRecord.descendants на Rails 5 и выше
> ActiveRecord::Base.descendants.collect(&:name)
=>
["SiteSetting",
"User",
"DeletedChatUser",
"PushSubscription",
"UserChatChannelMembership",
"ChatChannel",
"DirectMessageChannel",
"CategoryChannel",
"ChatChannelArchive",
...
]
> ActiveRecord::Base.descendants.collect(&:name).count
=> 202202 модели. Хорошее круглое число. Давайте отсортируем, чтобы поглубже погрузиться в чат.
> ActiveRecord::Base.descendants.collect(&:name).sort
[...
"CategoryTagStat",
"CategoryUser",
"ChatChannel",
"ChatChannelArchive",
"ChatDraft",
"ChatMention",
"ChatMessage",
"ChatMessageReaction",
"ChatMessageRevision",
"ChatUpload",
"ChatWebhookEvent",
"ChildTheme",
"ColorScheme",
...
]Похоже, у нас здесь хорошие образцы именования. Много существительных, на первый взгляд кажется, что это список из 9 моделей, связанных с чатом, в алфавитном порядке. Давайте взглянем с другой стороны.
> ActiveRecord::Base.descendants.collect(&:name).grep(/chat/i)
=> ["DeletedChatUser",
"UserChatChannelMembership",
"ChatChannel",
"ChatChannelArchive",
"ChatDraft",
"ChatMessage",
"ChatMessageReaction",
"ChatMessageRevision",
"ChatMention",
"ChatUpload",
"ChatWebhookEvent",
"IncomingChatWebhook",
"ReviewableChatMessage"]
> ActiveRecord::Base.descendants.collect(&:name).grep(/chat/i).count
=> 13Таким образом, в действительности существует 13 моделей с «chat» в имени, чего не показывает простая сортировка по алфавиту. Более детальное изучение дает 18 моделей с «Post» в имени, 21 модель с «Topic» и целых 47 моделей с «User».
Они, похоже, следуют общепринятой «форме имен» ПрилагательноеСуществительное, если судить по ReviewableFlaggedPost, ReviewableQueuedPost и ReviewableUser.
Давайте поищем акронимы.
# Проверка на наличие акронимов в именах моделей
ActiveRecord::Base.descendants.collect(&:name).grep(/([A-Z]){2}/)
=> ["HABTM_WebHooks",
"HABTM_WebHooks",
"HABTM_WebHookEventTypes",
"HABTM_Groups",
"HABTM_Categories",
"HABTM_Tags",
"HABTM_WebHooks"]Только один! Это не так уж плохо. Если я не знаю значения акронима HABTM, то быстрый поиск в Google дает has_and_belongs_to_many, ассоциативные отношения. Превосходно!
Оглядываясь вокруг, вижу пару сокращений, которые не сразу понимаю, например, AllowedPmUser. Но нет ничего такого, в чем бы я не смог быстро разобраться с минимальными усилиями.
Подождите... Что означает Stat в UserStat? Статус? Нет... Уже есть UserStatus. Может, Statistics?
> ActiveRecord::Base.descendants.collect(&:name).grep(/stat/i)
=> ["CategoryTagStat",
"PostStat",
"UserStat",
"UserStatus",
"MiniScheduler::Stat"]Ах, да. Код подтверждает, что «Stat» — это сокращение от «Statistics».
Давайте рассмотрим атрибуты или имена таблиц базы данных. Их всего 1919, слишком много для просмотра здесь, но давайте отсортируем и отфильтруем дубликаты.
# Подсчитать количество имен атрибутов
> ActiveRecord::Base.descendants.collect(&:attribute_names).flatten.count
=> 1919
# Подсчитать количество разных имен атрибутов
> ActiveRecord::Base.descendants.collect(&:attribute_names).flatten.uniq.count
=> 758
# Получить имена отдельных атрибутов
ActiveRecord::Base.descendants.collect(&:attribute_names).flatten.uniq.sort
=> ["about_url",
"access_control_post_id",
"acting_user_id",
"action",
"action_code",
"action_type",
"active",
"admin",
"admin_only",
"agreed_at",
"agreed_by_id",
"all_score",
"all_topics_wiki",
"allow_badges",
"allow_channel_wide_mentions",
"allow_global_tags",
...Теперь у нас есть удобный справочник, который можно использовать для проверки терминологии, принятых сокращений или форм имен! Каждый раз при добавлении таблицы или нового имени поля мы можем провести пробежаться по нему, чтобы обеспечить согласованность.
# Получить атрибуты с цифрами
ActiveRecord::Base.descendants.collect(&:attribute_names).flatten.uniq.sort.grep(/d/)
=> ["content_sha1",
"day_0_end_time",
"day_0_start_time",
"day_1_end_time",
"day_1_start_time",
"day_2_end_time",
"day_2_start_time",
"day_3_end_time",
"day_3_start_time",
"day_4_end_time",
"day_4_start_time",
"day_5_end_time",
"day_5_start_time",
"day_6_end_time",
"day_6_start_time",
"featured_user1_id",
"featured_user2_id",
"featured_user3_id",
"featured_user4_id",
"include_tl0_in_digests",
"original_sha1",
"sha1"]Есть небольшая путаница в вопросе о том, что лучше: day_1 или user1, но в целом в этом проекте проделана фантастическая работа по обеспечению согласованности. Судя по увиденному в ходе нашего краткого знакомства, проект отлично подходит для управления сложностью имен.
Извлеченные уроки
Чему это нас учит?
Проект с хорошими соглашениями об именовании может быть удивительно простым для навигации и изучения. Имена методов говорят об их назначении, классы названы логично и сгруппированы.
Проанализируйте свой проект или кодовую базу с помощью перечисленных выше инструментов. Интересно, сколько непонятных аббревиатур, несогласованных систем нумерации или доменов с плохими именами вам удастся найти. Представьте, что вы знакомите с ними только что принятого в штат разработчика, — выделите те, что трудно объяснить. Помните: чем лучше имена, тем легче жить всем.
Даже совершенно новая кодовая база может показаться знакомой и понятной, если она следует стандартам именования, соглашениям фреймворка и обозначает намерения с помощью отличных имен переменных. Придумать хорошее имя бывает трудно, но затраченное время окупается сполна.