
На сегодняшний день Kubernetes — одно из наиболее оптимальных решений для работы с микросервисной архитектурой, альтернативы этому ПО пока нет. Но все понимают, что Kubernetes — это не традиционная комплексная система PaaS. В ванильный K8s входит семь стандартных компонентов, которые отвечают только за минимальный набор необходимых функций. Но для эффективной работы приложений и деплоя продуктовой среды необходимо множество дополнений — CNI, СSI, DNS, Ingress контроллер, внешние LB и т. д. Цель нашей команды — готовая для комфортной работы с кластером PaaS‑платформа. В этой статье мы расскажем, как готовим Kubernetes в dBrain.cloud, чтобы ее достичь.
Галочка за бэкап
Все больше специалистов сейчас работают именно с Kubernetes. K8s имеет самое большое комьюнити, благодаря чему пользователи быстро находят ответы на свои вопросы и решают не шаблонные задачи. Разработка ПО, внедрение новых фич, устранение багов в Kubernetes происходит значительно быстрее, чем в других продуктах.
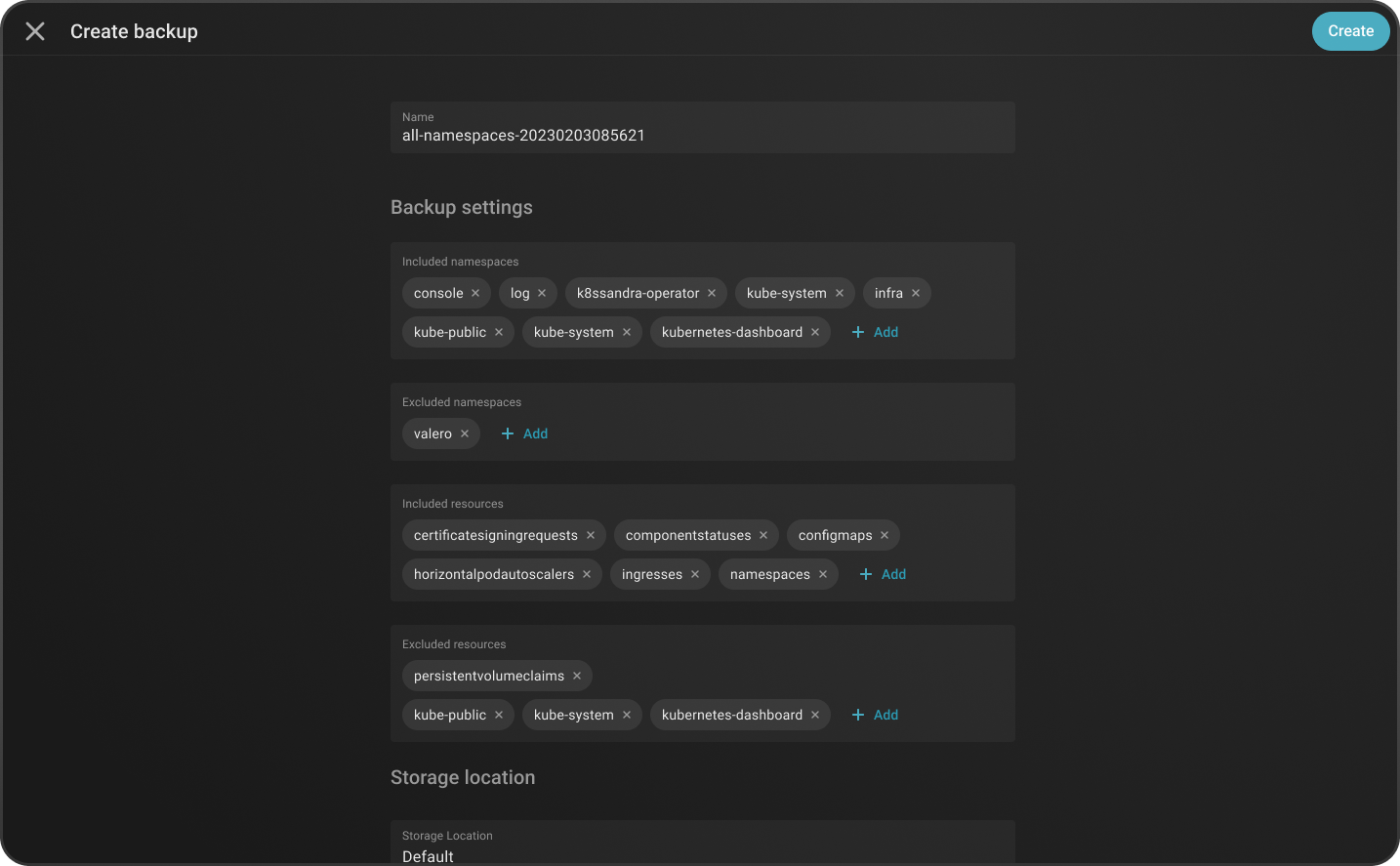
Но при этом у Kubernetes из коробки нет никаких средств бэкапирования. А без резервной копии дальше двигаться опасно, сами знаете. В платформе dBrain мы учли это и внедрили сервис Velero. Он позволяет бэкапить конфигурации, все абстракции и компоненты Kubernetes. В консоли dBrain есть возможность указать откуда, что и как бэкапить, куда восстанавливать. Для этого нужно только поставить галочки в нужных ячейках.
За взаимодействие с K8s отвечает один из его сервисов — kube API. Это интерфейс для управления внутренними структурами Kubernetes и сервисами, которые в нем работают. По сути, kube API принимает команды и отдает их на исполнение.
Сам kube API имеет «под капотом» много версий API для разных ресурсов Kubernetes. В dBrain мы используем интерфейсы взаимодействия со стандартным набором Kubernetes и API сервисов, которые интегрировали в платформу.

Velero расширяет kube API за счет своих CRD (Custom Resource Definition). Его функция — получить ресурсы через kube API и сложить их в хранилище, например, в S3. Бэкапы можно складировать в любые S3-хранилища. В dBrain разработчики могут вернуться к любой версии приложения. В зависимости от того, каким образом делался бэкап (по расписанию либо мануально), можно вернуть все сущности в одном или нескольких неймспейсах.
Фирменный рецепт Kubernetes: фишки dBrain
Главное в нашем рецепте — не просто подбор ингредиентов, а результат, т. е. насколько удобным и очевидным будет управление всей системой. Поэтому все фишки мы прорабатываем с учетом их последующей интеграции в единый UI консоли dBrain. Но вернемся к ингредиентам…
Calico наилучшим образом зарекомендовало себя в большинстве крупных продакшн кластеров Kubernetes. Поэтому в нашей платформе это решение используется в качестве CNI (Container Networking Interface). Также у нас есть экспериментальная опция Cilium. Этот инструмент предлагает ряд уникальных фишек, не имеющих аналогов в Open Source поставке Calico, например, удобный Web UI Hubble для отображения всех роутов и быстрого поиска проблем внутри сети кластера. Calico — текущее решение, Cilium рассматриваем как альтернативу. Мы уже можем деплоить Cilium в наш Kubernetes, но пока еще не сделали его Production Ready. Calico расширяет стандартный функционал Kubernetes как с точки зрения возможности создания подсетей внутри самого K8s, так и с точки зрения сетевых политик. Есть стандартные API network policies и Calico network policies, которые можно гибко настраивать в качестве файрвола внутри самого Kubernetes.

CSI (Container Storage Interface). У нас есть несколько Production Ready решений по CSI, которые можно использовать как дополнение к Kubernetes при разворачивании платформы dBrain. В зависимости от размера и архитектуры кластеров, выбирается оптимальное решение при планировании конфигурации. Одним из таких решений для крупных инсталляций является программно‑определяемая СХД Ceph.
Для Kubernetes есть два типа приложений — Stateful и Stateless. Stateless‑приложения можно в любой момент перезапустить, их состояния нигде не хранятся, они просто выполняют свою функцию, например, отвечают на внешние запросы. Stateless‑приложения делают это при любых обстоятельствах при старте из того состояния, которое было описано при создании самого контейнера.
CSI же используется для Stateful‑приложений. Stateful‑приложения должны иметь какой‑то бэкэнд, куда они пишут свои данные, которые никак нельзя потерять. Мы выделяем для каждого приложения RBD‑диск, который в случае с Container Storage Interface Ceph может быть примонтирован к любой из нод кластера. Таким образом, при использовании Ceph‑CSI у нас нет жесткой привязки к нодам.
Есть другие решения, например, TopоLVM. Его мы тоже используем в платформе. Он выделяет только локальные диски. Это говорит о привязке к конкретной ноде, на которой первоначально был выделен persistent volume.
В dBrain также есть возможность развернуть Minio, которое тоже поддерживает реализацию протокола S3. Это позволяет реализовать абстракцию S3-хранилища — объектный Storage на небольших инсталляциях до трех нод.
В случае развертывания поверх виртуальных машин на платформе VMware vSphere есть интеграция с vSphere Storage. Хранилище предоставляет сама vSphere. Kubernetes может запрашивать определенные диски у vSphere. В таком случае платформа будет нарезать эти диски в своем глобальном Storage и отдавать Kubernetes в качестве persistent volume. То есть разработчику приложения или конечному пользователю надо только указать Persistent Volume Claim, отметить, сколько требуется места на диске, а также выбрать соответствующий Storage‑класс, который создается при разворачивании платформы. dBrain избавляет разработчиков от решения вопроса, каким образом эти диски будут выделены. Все произойдет автоматически с помощью соответствующего CSI‑плагина.
Через консоль dBrain мы предоставляем возможность изменять размер дисков (resize pvc), которые уже примонтированы к Stateful‑приложениям, например, к базам данных без downtime. Это одно из конкурентных преимуществ платформы dBrain.
У нас реализована поддержка внешнего балансировщика нагрузки, то есть реализация самой абстракции Load Balancer в Kubernetes через расширение PureLB.
PureLB использует стандартную линуксовую сетевую подсистему. С помощью сервиса Load Balancer выделяется какой‑то виртуальный IP‑адрес и вешается на внешний сетевой интерфейс на той ноде, где живет под PureLB. Как правило, это ноды с ролью Load Balancer. Адрес выделяется в подсети самих серверов. То есть эти адреса выделяются не из внутренней оверлейной сети кластера, а либо из отдельной публичной сети, либо с адресацией хостов (нод самого Kubernetes). Отметим, что из коробки PureLB не будет из своих пулов автоматически выделять адреса для сервисов типа Load Balancer. То есть это оставлено на откуп администратору, который должен сам повесить аннотации на сервисе. У нас есть собственный компонент, который следит за состоянием сервисов внутри Kubernetes. При создании абстракции сервиса с типом Load Balancer он проставляет нужные нам аннотации для того, чтобы полностью автоматизировать процесс выделения виртуального ip‑адреса.
В качестве Ingress Controller для точки входа внешнего L-7 трафика у нас используется Ingress NGINX, как одно из наиболее широко распространенных решений для реализации абстракций Ingress в Kubernetes. Также Ingress NGINX в dBrain поддерживает и L-4, то есть работает как в режиме http и https‑протоколов, так и tcp/udp.
Cert Manager можно использовать для внутренних сертификатов, которые нужны, например, для подписи вебхуков работающих в кластере сервисов. Также Cert Manager можно использовать для ротации сертификатов для Ingress и выдачи самоподписанных сертификатов при необходимости.
Кроме Cert Manager, у нас есть расширение Node Problem Detector, которое отслеживает состояние нод при появлении каких‑либо проблем, например, deadlock ядра, рассинхронизации времени на машинах, сложностей с переходом примонтированных к ноде файловых систем в состояние read only.
CoreDNS. Это кластерный DNS, который резолвит все сервисы Kubernetes. В dBrain он еще используется и как резолвер непосредственно для самих хостов. Он может держать дополнительные DNS‑зоны, т. е. не только зоны Kubernetes. В нашем случае — это кластерная зона, которую можно забирать извне. Это нужно для того, чтобы по доменным именам ходить на внутренние и внешние сервисы кластера, в том числе типа Load Balancer, а также при необходимости отдавать внутрикластерные доменные имена во вне.
Для этой же цели служит ExternalDNS. Он отслеживает состояние сервисов типа Load Balancer и Ingress. В зависимости от аннотаций, ExternalDNS пропишет в CoreDNS доменную зону или конкретный домен, который будет вести в определенный сервис. Это работает на Ingress, т. е. на L-7 и на L-4 Load Balancer.
Vertical Pod Autoscaler. Позволяет динамически на основе заданных правил менять у рабочей нагрузки реквесты и лимиты, то есть скейлить ее вертикально. Горизонтальный скейлинг (через количество реплик) не всегда оптимален, так как не может гарантировать отсутствие OOMKilled состояний. Поэтому в dBrain наряду с Horizontal Pod Autoscaler также используется вертикальный способ масштабирования рабочей нагрузки.


Storage Classes. В любой инсталляции платформы dBrain, как правило, есть два Storage Classes для каждого вида CSI: один на медленных жестких дисках HDD (с уклоном на объем), другой на SSD (с приоритетом на скорость обработки данных). В зависимости от типа приложения можно выбрать наиболее оптимальный вариант Storage Class.
Мы перечислили только часть наших надстроек Kubernetes, которые помогают создавать PaaS‑платформу для работы с кластером. В этот список не вошли lb‑autohealer, lb‑gen‑svc, lost‑node‑cleaner, descheduler, gen‑svc, namespace‑controller, node‑problem‑detector и ряд других компонентов, отслеживающих пограничные состояния определенных сервисов K8s и выполняющих ряд функций. Это специфичные компоненты собственной разработки именно для нашей реализации платформы. Мы обязательно расскажем о них детальнее в отдельной статье.
Стой, кто идет?
Не каждый разработчик готов настраивать Kubernetes своими силами, искать собственный универсальный рецепт. Гораздо проще использовать готовую платформу, где все предусмотрено для комфортной работы.
У нас есть свой описанный деплой Kubernetes, процесс полностью автоматизирован. Мы устанавливаем и обновляем сам Kubernetes через описанные, заранее подготовленные идемпотентные скрипты Ansible Playbooks.
В dBrain есть компонент для проверки короткоживущего OpenID токена, который выдается KeyCloak назначенным identity‑провайдером для кластера. Каждый пользователь наделен ролью для доступа к неймспейсам/кластерам. Данные роли позволяют авторизоваться внутри API‑сервера и иметь доступ с определенными правами к группам объектов K8s. В нашем случае это, как правило, доступы по неймспейс — на чтение или админский доступ, который позволяет модифицировать все ресурсы внутри заданных неймспейсов. Наш компонент kube‑jwt‑auth проверяет валидность OpenID JWT токена при авторизации через kubectl. То есть при подключении через командную строку к API‑серверу кластера Kubernetes пользователь, зарегистрированный внутри KeyCloak, получит доступ к разрешенным ресурсам. Другой вариант получения доступа — через консоль. С помощью веб‑интерфейса пользователь получит доступ к тем же ресурсам, которые прописаны в KeyCloak. Таким образом, роли распространяются как на интерфейс командной строки kubectl, так и на Web UI, т. е. дашбор Kubernetes в консоли dBrain.
Такие фишки мы применяем, чтобы сделать из ванильного Kubernetes продукт «всё‑в-одном» для легкого построения кластера. В следующих материалах расскажем об инструментах для централизованного сбора логов и мониторинга всех узлов и компонентов платформы.
Задавайте свои вопросы в комментариях. Мы обязательно на них ответим.