

Не буду распространяться о преимуществах использования библиографических менеджеров. На дворе 2015 год. Тема не раз обсуждалась на Хабре.
Здесь подробно описываются все прелести использования библиографического менеджера на примере Mendeley (это один из главных конкурентов Zotero, сравнение позже в этой статье). Здесь любопытно представлена система Citavi. Вроде бы, все в ней неплохо, но платить за софт приличные деньги, когда есть прекрасные бесплатные аналоги — развлечение на любителя. Кстати, от души рекомендую почитать комментарии к этой статье — познавательнее иных опусов. Здесь автор библиографического менеджера SciRef предлагает получить программку бесплатно.
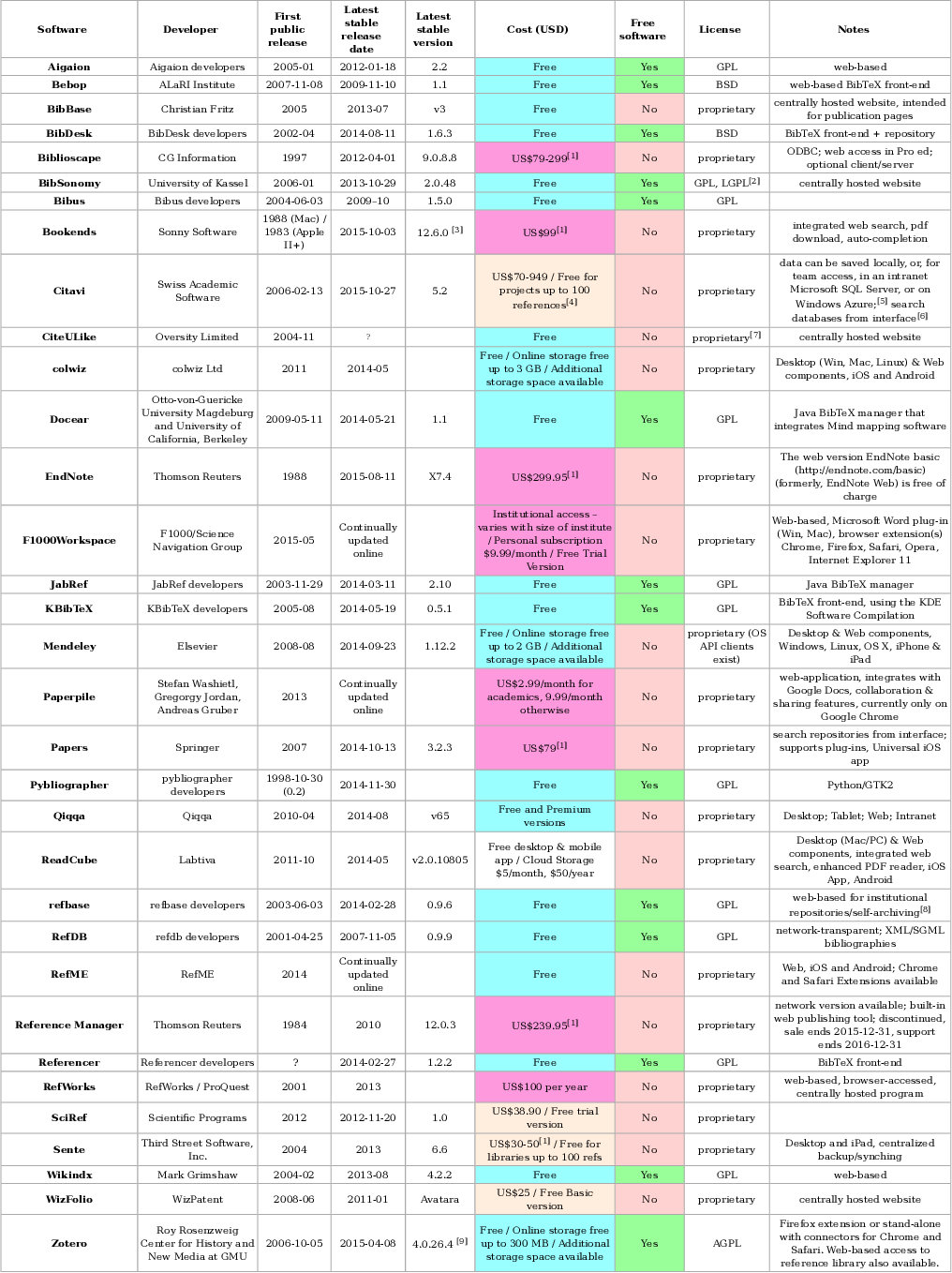
Существует огромное множество различных библиографических менеджеров (см. таблицу в подвале, источник).
Разумеется, при таком многообразии глупо говорить об одном идеальном решении. В этой статье я хочу рассказать вам о решении, которым пользуюсь и которое устраивает меня почти полностью. Как видно из названия статьи, это Zotero.
Zotero — проект с открытым исходным кодом. Программа принципиально бесплатна. Но есть один малоприятный нюанс. Zotero предлагает бесплатно онлайн хранилище лишь на 300 МБ (на практике выясняется, что это очень мало — не более 500 статей). Нет, локально можно хранить сколь угодно большую библиотеку, но если желаешь синхронизировать все в онлайн, придется платить. Именно пошаговый обход этого неприятного момента я и покажу в данной статье. Логика проста: храним библиографические описания в онлайн-хранилище Zotero, а полные тексты статей — в любом облаке.
Итак, скачать установочники можно безвозмездно с официального сайта. Zotero существует в двух вариантах: в качестве дополнения Firefox и в качестве отдельной программы. Мне лично удобнее пользоваться самостоятельной программой. Но это дело вкуса. Функционал обоих решений идентичен. При этом можно установить оба варианта параллельно, что мне кажется очень удобным: Zotero Firefox для удобства быстрого поиска и экспорта статей; Zotero Standalone для удобства работы исключительно с литературой в полноэкранном режиме. Разумеется, при таком подходе настраивать Zotero Firefox и Zotero Standalone надо одинаково (хак: если сперва настроить Standalone, то при открытии Zotero Firefox появится опция импортировать настройки). Приятно, что программа кроссплатформенна. Недавно пересел на Linux — никаких проблем с использованием библиотеки.
Из предварительных шагов осталось еще три: (1) завести учетную запись на сайте Zotero (она понадобится для синхронизации); (2) установить расширение для экспорта цитат из Google Scholar — Zotero Scholar Citations; (3) установить расширение для более тонкой работы с файлами, прикрепленными к библиографическим описаниям — Zotfile. Имеет смысл скачивать и устанавливать наиболее свежую версию Zotfile с github странички разработчика. Процесс установки описан на английском; если проще на русском, смотри спойлер ниже.

2. Распаковать архив
3. Открыть папку zotfile-master, выбрать все файлы и папки и снова заархивировать с расширением .zip
4. Переименовать полученный архив в zotfile.xpi
5. Установить. Пользователи Zotero Firefox могут просто перетащить архив в любую открытую вкладку браузера и согласиться на установку. Пользователям Zotero Standalone надо открыть программу. Дальше Tools->Add-ons->Tools for all Add-ons (кнопка справа – см. скриншот)->Install Add-on From File. Выбираем zotfile.xpi

Предварительные шаги пройдены. Осталось настроить параметры. Отправляемся в настройки. Edit-> Preferences. Открывается окно с настройками на вкладке General. Здесь из настроек я только убрал галочку с автоматического скриншота сайта, когда сохраняешь статью. Не вижу смысла засорять БД кучей мелких файлов. Впрочем, кто-то может найти эту опцию крайне полезной.

Дальше идем по вкладкам меню настроек. Sync. Тут надо ввести данные учетно записи Zotero для синхронизации библиографических описаний. Убираем галочку с Sync full-text content. Это как раз и есть опция синхронизации полных текстов статей в хранилище Zotero. Нам не интересно облако с лимитом в 300МБ.

Search. Тут надо щелкнуть по плашке, чтобы установить дополнение, которое позволяет вытаскивать полные библиографические описания из самих PDF статей. Это работает только в том случае, если опция заложена создателем файла. Но большинство современных научных издательств все делают грамотно.

Export. Пропускаем сейчас.
Cite. Очень важно. Тут надо установить интеграцию с MS Word и/или Libreoffice. В соседней дополнительной вкладке Styles можно устанавливать новые стили цитирования. Многие журналы выпускают свои стили, подогнанные до мельчайших деталей. Скачать можно тут.
Advanced. Нас интересует только дополнительная вкладка Files and Folders. Тут и кроется главная хитрость.

В первом пути указываем директорию, в которой будут храниться полные тексты статей (я ее назвал Zotero_Library). Эта директория располагается где-то в синхронизируемой части файловой системы. В моем случае это директория Jottacloud — облако, которое я использую. Во втором пути надо указать директорию, в которой будут храниться системные файлы (Zotero_System). Эту директорию желательно создавать где-то в неизменяемой части файловой системы. Ее будет перезаписывать синхронизация Zotero. Подобное разделение позволяет нам избежать конфликтов синхронизации библиографических описаний в хранилище Zotero и полных текстов статей в наше облако по выбору.
Остался последний штрих — настроить Zotfile. Идем в Tools->Add-ons и нажимаем на кнопку Preferences напротив Zotfile. Появляется окно с настройками, вкладка General Settings.
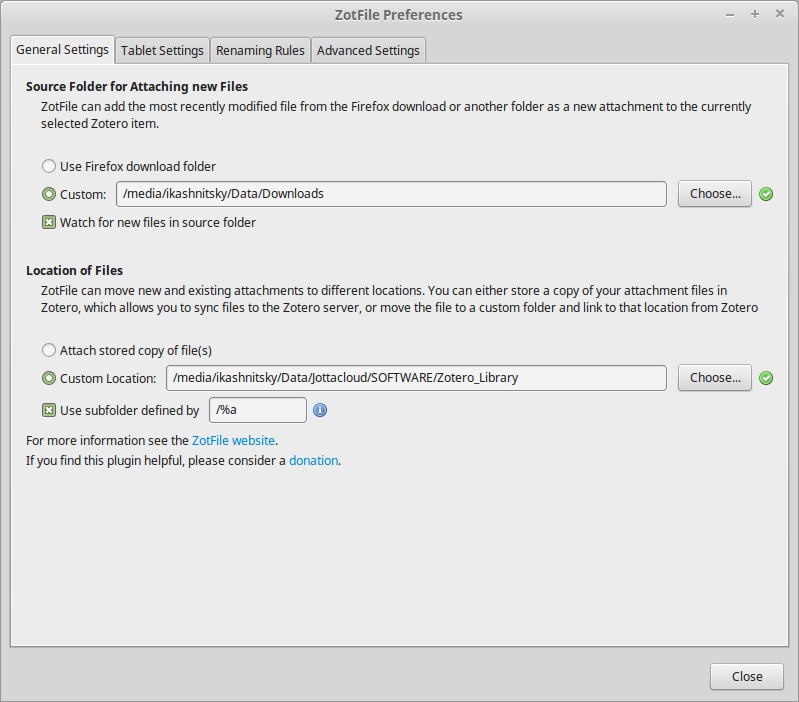
В первом пути указываем директорию, куда браузер сохраняют по умолчанию файлы. Это позволяет Zotfile автоматически прикреплять PDF только что сохраненных статей, если открыт доступ к скачиванию файла. Но это мелочь, второй путь гораздо важнее. Тут выбираем директорию, созданную для хранения полных текстов — Zotero_Library. Помечаем ниже использовать отдельные папки. /%a означает, что PDF статей будут размещаться в папки, названные в честь автора. Вариантов куча, можно ознакомиться на сайте разработчика Zotfile.
Дальше вкладка Renaming Rules. Тут нужно убедиться, что прикрепленные файлы будет переименовывать именно Zotfile. Куча настроек. Я использую стандартные — они кажутся вполне разумными.

На этом настройка завершена. Можно пользоваться.
Важный нюанс! Прикрепленные текст должен обязательно быть переименован Zotfile, иначе он не попадет в правильное хранилище в правильном виде. Не вдаваясь в подробности, приложение к библиографической карточке должно быть ссылкой на переименованный файл.

А не самим файлом.

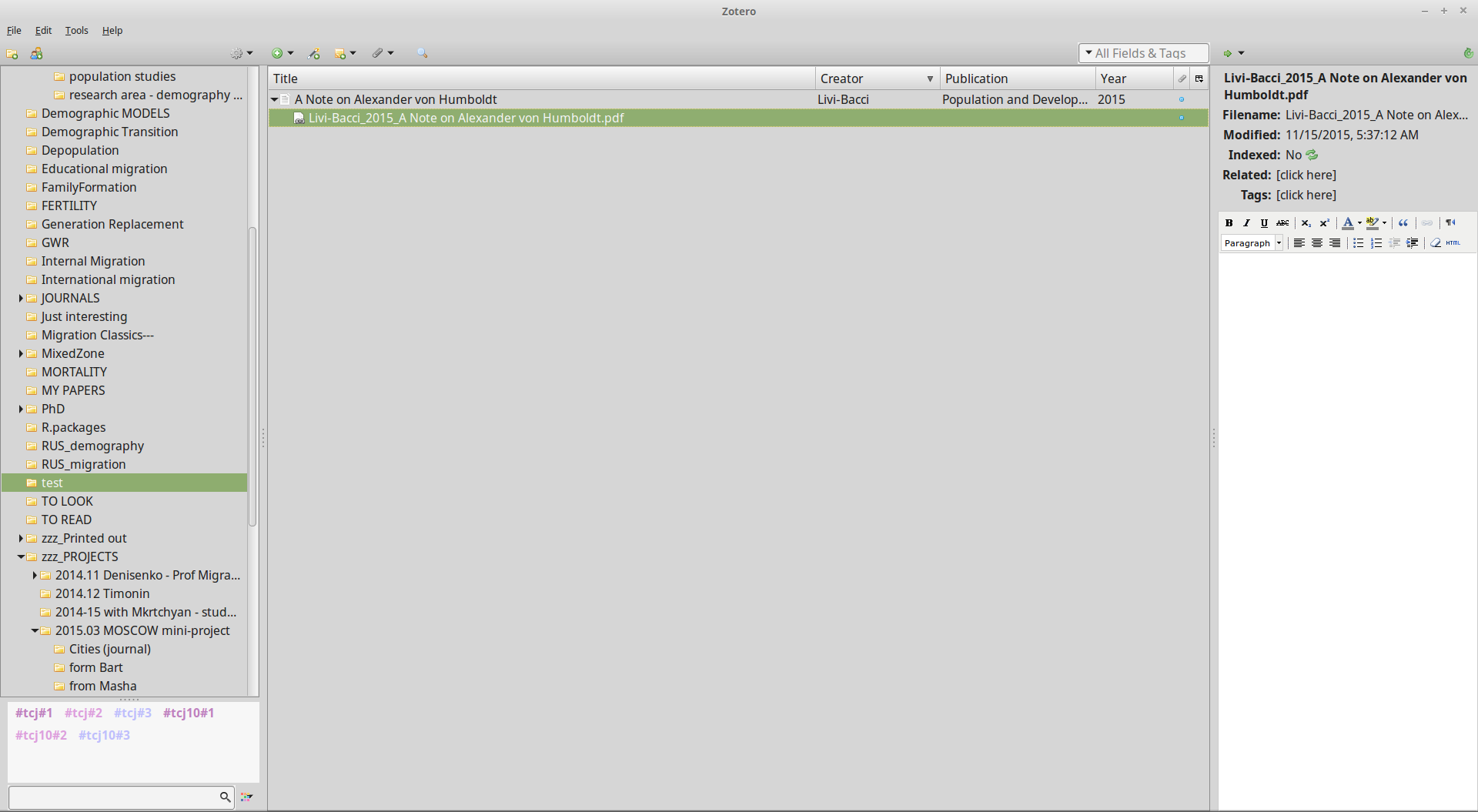
А теперь посмотрим, в чем же главна прелесть Zotero в связке с Zotfile. Вот так выглядит библиографическое описание статьи из моей библиотеки, выгруженное в формате bibtex.

Обратите внимание, что путь к файлу хардкорно прописан в самом библиографическом описании. Это значит, на каком бы компе я ни развернул свою библиотеку, мне надо только настроить все привычным образом (указать путь к локальному хранилищу) и синхронизироваться с учетной записью Zotero.
Mendeley так не умеет. Впечатлившись более эффектным интерфейсом, я недавно предпринял попытку пересесть на Mendeley, но очень быстро уперся в невозможность восстановить целостность своей БД. А вручную прикреплять тысячу PDF к библиографическим записям — работка не для слабонервных. Ниже в подвале — некоторые пункты сравнения Mendeley с Zotero, которые определили мой выбор в пользу Zotero. Сравнение не претендует на полноту: оно затрагивает только вопрос оптимального хранения всей БД литературы. При желании по запросу «Zotero VS Mendeley» Google выдаст кучу толковых статей (обращайте только внимание на возраст статей — оба проекта бурно развиваются, и многие недостатки прошлого уже устарели).
Mendeley не работает без подключения к интернету. Казалось бы не велика беда — интернет сейчас везде. Но вот пописать статью в самолете с Mendeley не получится. Мелочь, а неприятно.
Есть у Mendeley и очевидные преимущества. Программа проще в установке и настройке. Есть собственные очень приличные приложения под Android и iOS. Значительно быстрее Zotero парсит метаданные из PDF статей. Есть встроенный просмотрщик PDF с возможностью быстрого выделения и аннотации. Однако все эти плюшки, на мой взгляд, не перевешивают проблем с организацией БД.
Ну и напоследок. Периодически можно вычищать все из папки Zotero_System/storage. В ней хранятся копии еще не переименованных файлов и прочий шлак. Но внимание (!), там же хранятся скриншоты, если они вам нужны.
Наслаждайтесь Zotero с облачным хранилищем любого размера!
Комментарии (2)

ikashnitsky
18.11.2015 01:18+11. Знаю, что это принципиально возможно, но сам не пробовал. Вероятно, это может быть удобно. Меня устраивает описанный метод тем, что базовая синхронизация с хранилищем Zotero обеспечивает молниеносное и бесперебойное обновление библиографических описаний на любом количестве компьютеров. Я рассуждаю так, что в крайнем случае мне будет жальче потерять саму структуру БД (метаданные, разбивку по папкам, тэги). Что касается самих pdf статей, делай периодически бэкап директории с ними — и все будет в порядке.
2. Не совсем понятно, что подразумевается под «разложил». Zotfile копирует, переименовывает и складывает pdf в указанной директории, сортируя по вложенным директориям (которые в свою очередь могут быть названы по какому угодно правилу). Если речь об извлечении метаданных из pdf, то тут не всегда все работает по волшебству. Во-первых, метаданные должны быть грамотно зашиты в файлы; у многих старых статей с этим бывают проблемы. Во-вторых, Zotero довольно медленно парсит метаданные. С этой задачей, по-моему, Mendeley справляется на порядок лучше. Но в действительности извлекать метаданные приходится редко. Как правило, находишь статью в интернете, нажимаешь на кнопочку — полное описание у тебя в библиотеке.
ivlis
Несколько вопросов:
1. А свой сервер этого Zotero пробовали поднимать? Тогда можно без танцев с бубном залить много статей. Смущает только, что сам сервер у них на github без всяких инструкций как поднимать.
2. Можно ли Zotero скормить директорию со 100500 статей, чтобы он их сам разложил?