
У нас было 2 ТБ данных на 4 информационных системы, 237 таблиц, 221 хранимая процедура, свыше 30 тысяч строк кода, ванильная версия PostgreSQL и потребность в реализации обратного потока данных в Oracle. Не то чтобы мы были экспертами в создании потоков данных между СУБД, но я знал, что рано или поздно нам придется этим заняться.
На фоне санкций и ухода Oracle из РФ мы, как и многие компании, начали задумываться о переходе с проприетарной СУБД Oracle на опенсорсную PostgreSQL.
Переводить нужно было именно на ванильную версию PG, и список разрешенных расширений ограничивался теми, что находятся в каталоге contrib. Это ограничение вызвано по большей части требованиями информационной безопасности: нет уверенности, что в других модулях не будет преднамеренных уязвимостей.
Но кто же начинает что-то внедрять, не опробовав это сначала и не набив шишек на «лабораторных мышах»? Выполнить пилотный проект и определить основные вехи переезда информационных систем выпало на нашу долю.
Меня зовут Игорь Тоескин, я главный разработчик и по совместительству тимлид команды разработки юридически значимого документооборота. В статье расскажу, как происходил переезд и какие шишки мы набили в процессе.
Итак, мы проанализировали все имеющиеся ИС в компании и определили список тех, которые можно было вырезать из существующего монолита и вынести из Oracle в PG. В списке оказалось 4 ИС. Одна из них – договорной учет (ДУ), – выпала мне, и работа закипела.
Мы провели исследование опыта других компаний, привлекли внешних экспертов «ФОРС», которые оказывали нам поддержку и консультации по различным вопросам. В итоге создали план, которого в конце концов и старались придерживаться.
Итак, первым шагом нужно было определить потребности каждой ИС при переносе на отдельный инстанс из монолита. В случае с ДУ потребности были такие:
Перенести метаданные.
Перенести все данные.
Получить необходимую нормативно-справочную информацию.
Адаптировать имеющуюся в монолите ролевую модель с доступами под PG.
Создать обратный поток с данными в монолит для тех потребителей, которые не переключились на новый источник.
Адаптировать фреймворк по созданию веб-интерфейсов для пользователей и использовать его в связанном с ИС АРМе.
В других системах, кроме этих потребностей, поднимались вопросы шедулинга (заданий по расписанию) и поиска аналогов очередей (передачи информации в хронологическом порядке). В итоге в качестве шедулинга был выбрали pgAgent, а для очередей – расширение pgQ.
Текущее и ожидаемое состояние системы
Состояние до переезда:
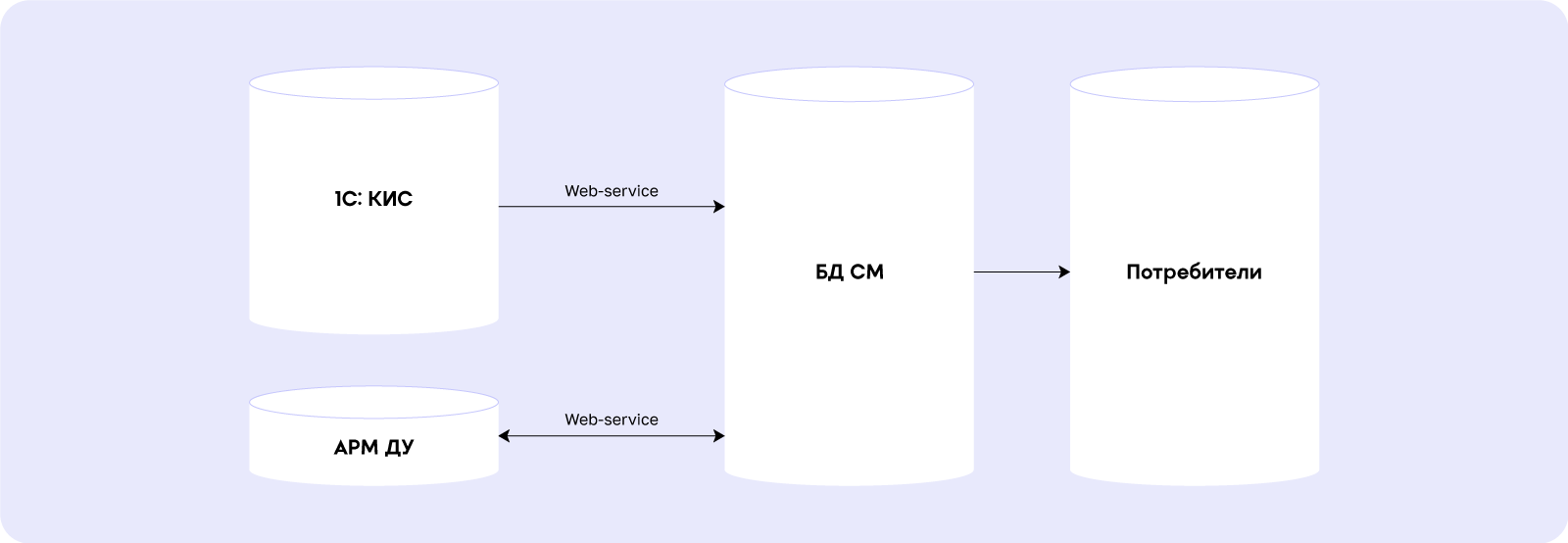
Система состоит из:
Непосредственно слоя хранения данных на БД СМ – Базе Данных Сети Магнит. Дальше они передаются различным потребителям при помощи CDC и других потоков.
1С:КИС – первоисточник данных.
АРМ ДУ – пользовательский инструмент, где дополнительно создаются отдельные документы.
Состояние после:

Как видим, в качестве пилотного проекта создается отдельная БД ДУ, которая будет являться источником данных. Туда в дальнейшем будут переключены все потребители.
Определение списка инструментов
Мы провели анализ доступных средств, проконсультировались с внешними специалистами и выбрали следующие инструменты:
Ora2PG – для ускорения переноса метаданных.
Oracle_FDW – для переноса данных.
In-house адаптер сервиса распространения НСИ (Java+PostgreSQL).
Informatica – для обратного потока данных на тот период, пока все потребители данных не переключатся на новую БД.
Набивание шишек
Перенос метаданных
После определения потребностей мы начали искать инструменты, которые бы помогли их реализовать. С переносом и трансформацией метаданных нам помог прекрасно освещенный на Хабре Ora2PG, но, конечно, без работы напильником дело не обошлось. Например, пришлось вручную переписывать модули с PRAGMA AUTONOMOUS_TRANSACTION:
Было:
procedure log(p_step_name in varchar2,
p_note in varchar2 default null) as
pragma autonomous_transaction;
begin
insert into a1(R_LOG_DATE, R_STEP_NAME, NOTE, R_SID, R_SERIAL)
values (systimestamp, p_step_name, p_note, v_sid, v_serial);
commit;
exception
when others then
rollback;
end log;
Стало:
FUNCTION log(p_step_name in varchar2,
p_note in varchar2 default null )
RETURNS INT AS
$BODY$
DECLARE
sql_insert text;
BEGIN
begin --если вдруг случайно осталось соединение.
PERFORM dblink_disconnect('conn_name');
exception when others then
null;
end;
sql_insert = ' insert into a1(R_LOG_DATE, R_STEP_NAME, NOTE, R_SID, R_SERIAL)
values (current_timestamp, [p_step_name], [p_note], [usr]);';
sql_insert = replace(sql_insert, '[p_step_name]', coalesce(p_step_name,''));
sql_insert = replace(sql_insert, '[p_note]', coalesce(p_note,''));
sql_insert = replace(sql_insert, '[usr]', coalesce(user,''));
PERFORM dblink_connect('conn_name', 'conn_str');
PERFORM dblink('conn_name',sql_insert);
PERFORM dblink_disconnect('conn_name');
RETURN 0;
END;
$BODY$
LANGUAGE plpgsql SECURITY DEFINER;
Много ручных доработок потребовалось, чтобы:
Переписать встроенные оракловые функции на их аналоги. Например, замена
nvl(val1,val2)наcoalesce(val1,val2), переписываниеdecodeнаcaseи так далее.Найти или написать альтернативные варианты для пакетов dbms_*:
dbms_output.put_lineзаменили наraise notice.Переписать все вызываемые пользовательские исключения:
pragma exception_initнаraise notice/raise exception.
От использования orafce решили отказаться, потому что:
Он не входит в список официально поддерживаемых расширений.
Эксперты «ФОРС» обозначили риски деградации производительности, если использовать его в пакетных обработках.
Дальше пришлось решить проблему с отсутствием оператора MERGE в PG 14. В итоге все запросы с его использованием были преобразованы в следующий вид.
Было:
merge into sdcn.contract_kind d
using (select :Ref id_ck
,:DeletionMark deletionmark
,hextoraw(:Parent) higher
,:Code code
,:Description description
from dual) o
on (d.id_ck = hextoraw(o.id_ck))
when matched then
update
set d.deletionmark = o.deletionmark,
d.higher = o.higher,
d.code = o.code,
d.description = o.description
when not matched then
insert
(id_ck, deletionmark, higher, code, description)
values
(o.id_ck, o.deletionmark, o.higher, o.code, o.description)
Стало:
INSERT INTO sdcn.contract_kind as d (id_ck, deletionmark, higher, code, description)
select :Ref as id_ck
,:DeletionMark as deletionmark
,cast(nullif(:Parent, '') as uuid) as higher
,:Code as code
,:Description as description
on conflict(id_ck) do update
set deletionmark = excluded.deletionmark,
higher = excluded.higher,
code = excluded.code,
description = excluded.description
Также пришлось дополнительно создавать уникальные индексы для условий UPSERT там, где их не было в Oracle и где уникальность обеспечивалась отдельными проверками при обновлении данных. Это повлекло за собой проблему: NULL в первичных ключах в PG.
Там, где в Oracle целостность и консистентность данных обеспечивалась их дизайном, в PG пришлось добавлять дополнительные ограничения. Покажу на примере.

Здесь уникальным является сочетание guid1, guid2, guid3, int_value. В итоге пришлось создавать уникальный индекс по типу:
CREATE UNIQUE INDEX idx1 ON schema.table USING btree (guid1,guid2,guid3, COALESCE(int_value, 0));Еще один камень преткновения – вложенные функции и в принципе пакеты. Их пришлось разбивать на отдельные процедуры и функции и менять вложенные вызовы там, где Ora2PG не справился.
Следующая проблема, которая связана со структурами, – отсутствие механизма автоматической нарезки секций в PG 14. С этим мы боролись с помощью перевода на PG внутреннего проекта «Магнита» по управлению горизонтом хранения данных (Master_Log), о котором, надеюсь, однажды расскажут коллеги.
Также была проблема с «Current transaction is aborted…» на стороне сервиса, которая требовала явного завершения транзакции в случае возникновения каких-либо ошибок, и многие другие грабли, на которые наступали все, кто сталкивался с миграцией Oracle -> PG.
Перенос данных
И вот, метаданные перенесены. После этого нужно перенести и уложить данные. Эту задачу решили тривиальным способом: прямым импортом с использованием расширения oracle_fdw, поскольку позволяли объём данных, построенный процесс, сроки переноса данных.
Суммарно перенесли ~60 Гб данных за 10 минут. Для этого написали процедуру, которая вызывалась несколькими параллельными процессами и заполняла каждую таблицу по отдельности. Здесь я приведу схематичную структуру этой процедуры.
CREATE OR REPLACE PROCEDURE sdcn.parallel_initiate_data_prc(IN step_no integer)
LANGUAGE plpgsql
AS $procedure$
begin
case step_no
when 1 then
insert into table1
select ..
from ora_fdw.table1;
when 2 then
insert into table2
select ..
from ora_fdw.table2;
when 3 then
insert into table3
select ..
from ora_fdw.table3;
end case;
end$procedure$
;
А также того PLpgSQL блока, который инициировал запуск в параллели.
do
$$
declare
n_partition int = 20;
processes varchar [ ];
process_name1 varchar;
process_name2 varchar;
is_busy int;
res varchar;
ret varchar = '';
cnt int;
begin
for i in 1 .. n_partition
loop
process_name1 = format('sdcn_initiate_load_data_start2_%s', i);
process_name2 = format('nsi_initiate_load_data_start2_%s', i);
perform public.dblink_connect(process_name1,
'fdtest');
processes = array_append(processes, process_name1);
perform public.dblink_send_query(process_name1, format('call sdcn.parallel_initiate_data_prc(%s::int)', i));
if i <= 6
then
perform public.dblink_connect(process_name2,
'fdtest');
processes = array_append(processes, process_name2);
perform public.dblink_send_query(process_name2, format('call nsi.parallel_initiate_data_prc(%s::int)', i));
end if;
end loop;
end$$;
Получение нормативно-справочной информации (НСИ)
Следующая задача, которая встала перед нами, – получить всю нормативно-справочную информацию, необходимую для корректного функционирования ИС, – справочники, общие для всех ИС Магнита.
Мы создали API для получения данных на стороне БД и адаптера для нашей БД от сервиса распространения НСИ, написанного на Java. Была возможность получать данные и через GraphQL, но сжатые сроки пилота не позволили ее использовать.
Пример API:
CREATE TYPE nsi.article_info_row AS (
guid uuid,
code varchar,
"name" varchar,
isdeleted bool,
unit varchar);
/
CREATE TYPE nsi.result_info_row AS (
code int4,
info text);
/
CREATE OR REPLACE FUNCTION nsi.load_article_info_fnc(p_info nsi.article_info_row)
RETURNS nsi.result_info_row
LANGUAGE plpgsql
AS $function$
begin
insert into nsi.article
(guid
,code
,name
,isdeleted
,unit)
values
(p_info.guid
,p_info.code
,p_info.name
,p_info.isdeleted
,p_info.unit) on conflict
(guid) do update set code = p_info.code, name = p_info.name, isdeleted = p_info.isdeleted, unit = p_info.unit;
return row(0, 'success') ::nsi.result_info_row;
end;
$function$
;
/Создание обратного потока
Обратный поток, чтобы сэкономить временя, сделали через Informatica с настройкой алертингов и реализацией отдельного механизма импорта данных на стороне Oracle и экспорта на стороне PG. Схема потока выглядит так:

При передаче данных веб-сервисом в таблицы-источники срабатывают триггеры следующего типа:
create trigger fct_t_aiu_contract after
insert
or
update
on
sdcn.contract for each row execute function sdcn.convert_data_to_json_iu_fnc();
CREATE OR REPLACE FUNCTION sdcn.convert_data_to_json_iu_fnc()
RETURNS trigger
LANGUAGE plpgsql
SECURITY DEFINER
AS $function$
declare
v_id_op_doc uuid;
v_id_contract uuid;
BEGIN
begin
if to_jsonb(new) ? 'id_contract' then
v_id_contract := coalesce(new.id_contract,null);
end if;
if to_jsonb(new) ? 'id_op_doc' then
v_id_op_doc := coalesce(new.id_op_doc,null);
if v_id_contract is null then
v_id_contract := (select cod.id_contract from sdcn.contract_op_doc cod where cod.id_op_doc = coalesce(new.id_op_doc,null) );
end if ;
end if;
end;
insert into sdcn.import_data_content_tbl(schema_name,table_name,content, id_op_doc, id_contract)
select upper(TG_TABLE_SCHEMA),upper(TG_TABLE_NAME),json_agg(t), v_id_op_doc, v_id_contract
from (
select case when TG_OP = 'UPDATE' then 'U' when TG_OP = 'INSERT' then 'I' else null end action,new.*
) t;
RETURN NEW;
END
$function$
;
Эти триггеры заполняют таблицу унифицированными JSON, которые содержат атрибуты с наименованиями, дублирующими наименования полей в таблице. Поскольку целевые таблицы переезжали один к одному по своей структуре, это позволило на системе-приемнике создать также унифицированный механизм по их обработке. Далее таблица, которая заполняется триггером, опрашивается информатикой, и, если там появились новые записи – проливает их в приемник.
Упрощенно схема обработки сущностей информатикой выглядит следующим образом:

Эта структура была сделана для того, чтобы, во-первых, корректно отрабатывали мониторинги, а во-вторых, чтобы содержимое (clob с json) можно было долго не хранить в БД и таким образом экономить место.
Далее на стороне приемника отрабатывает джоб, который вычитывает необработанные записи из стейджа, формирует динамический merge, в котором данные вытягиваются из JSON и импортируются в нужную таблицу, и обновляет целевые таблицы.
Дополнительные инструменты, адаптированные под PG
На PG перенесли нашу внутреннюю систему контроля версий БД (Install) и CI/CD процессы с минимальными исправлениями: это позволило качественно и с полным контролем процесса провести внедрение.
Ролевую модель воссоздали через создание групповых ролей, которые в дальнейшем назначались пользователем. Что касается миграции фреймворка проектирования веб-интерфейсов, перевод осуществили с использованием всё того же ora2pg и допиливания полученного результата «напильником», чтобы устранить все перечисленные выше проблемы.
Внедрение
После того, как все кусочки пазла были собраны, мы протестировали новую версию ИС и перевели её в опытно-промышленную эксплуатацию. Процесс внедрения суммарно занял 40 минут и включал в себя следующие этапы:
Остановка веб-сервиса
Накат метаданных: самих структур без индексов, ключей, триггеров
Первичная проливка данных – около 60 Гб
Донакат оставшихся объектов БД: индексов, ключей, триггеров
Обновление Informatica
Обновление веб-сервиса
Установка адаптера сервиса НСИ
Внедрение функционала по передаче данных на приемнике
Запуск VACUUM ANALYZE
Запуск веб-сервиса
Итоговая схема обновленной ИС получилась следующая:

Комментарии (14)

usv_usv
27.06.2023 11:04+2согласно последней схемы на выходе получили БДСМ ))

RealitySculptor
27.06.2023 11:04да, если обратить внимание на предыдущие статьи, то мы тесно связаны с этим ))

FlyingDutchman
27.06.2023 11:04+1Оставив в стороне вопросы лицензий, поддержки и прочих финвопросы и сосредоточившись лишь на технической части - стоило оно того? Есть еще какой-то бенефит от переезда на PG, кроме финансового (стоимость лицензий, санкции opesource софт) ?
RealitySculptor
27.06.2023 11:04при решении описанной задачи помимо финансового профит был в том, что в данной ИС мы перестали бить "из пушки по воробьям" - т.е. тратить ресурсы нашего монолита (БД СМ), и при этом в плане производительности остались в SLA. Со стороны удобства разработки - кажется, даже стало удобнее в чем-то, а так, основной профит заключался именно в решении финвопросов и минимизации риска санкций

korvint
27.06.2023 11:04А можно поподробнее про возможные риски санкций? В смысле не юридические, а технические. Что зайдут через back door и отрубят всем oracle сервера? Такое пока только слухи, или где-то пробегала официальная информация о такой возможности?
RealitySculptor
27.06.2023 11:04+1про такое я не слышал, но отсутствие официальной техподдержки тоже является достаточно критичным вопросом

k-semenenkov
27.06.2023 11:04Спасибо что поделились опытом и инструментами. Если не секрет, с какой версии оракла переезжали?
RealitySculptor
27.06.2023 11:04+1переезжали с 12с на 14ю версию PostgreSQL, поэтому у нас несколько in-house решений тут используется (например, с секционированием)

plumqqz
27.06.2023 11:04+1exception when others then null;Какая прелесть!
RealitySculptor
27.06.2023 11:04подловили) согласен, что в вакууме это плохая практика, но здесь блок был добавлен больше ради страховки, и нам не особо критично, если он упадет с какой-то ошибкой

kpa23
Спасибо за то что поделились опытом!
RealitySculptor
спасибо, надеюсь, это было полезно ))