
Когда кто-то занимается машинным обучением, его задачи часто представляют так: обработать данные, провести несколько десятков экспериментов с разными архитектурами моделей и выбрать ту, которая даёт самые высокие метрики. Действительно, все эти шаги — неотъемлемая часть работы ML-специалиста, однако она максимально вариативна и может быть реализована с помощью бесконечного количества инструментов: от самописных скриптов до готовых решений.
Кто мы такие?
Меня зовут Смирнова Мария, я инженер по машинному обучению в ML-команде проектов для бизнеса и покупателей ВКонтакте. Расскажу, как мы оптимизировали обучение моделей, внедрив инструмент Kubeflow Pipelines в нашу практику. Я хочу показать, чем Kubeflow Pipelines может быть полезен ML-специалисту и как в нём без потери существующей кодовой базы можно запускать готовые пайплайны.
В организационной структуре VK наше бизнес-подразделение именуют как «Средний и Малый бизнес». Мы разрабатываем функциональность, которая помогает продавцам и покупателям найти друг друга: продавцу — разместить объявление о продаже своего товара так, чтобы как можно быстрее найти «своего» клиента, а клиенту — предоставить площадку, на которой он сможет ознакомиться с товарами, как минимум один из которых точно захочет купить.
Большая часть наших задач связана с NLP. Мы экспериментируем с различными методами обработки данных и десятками архитектур: от классических моделей до продвинутых нейронных сетей. Вот лишь некоторые примеры наших задач:
Классификация постов: может ли пост о продаже товара на стене быть переформатирован в карточку товара?
Извлечение именованных сущностей: нужно достать из текста объявлений основные характеристики товара, например, название и цену.
Кластеризация по названиям и фотографиям товаров.
При процесс решения абсолютно любой задачи выглядит следующим образом:

Этап проектирования: с заказчиком (это менеджер продукта, сотрудник другого подразделения или член нашей команды) мы обговариваем цель, как мы будем измерять успешность решения, договариваемся о сроках. Со своей стороны продумываем этапы выполнения задачи, то есть попросту её декомпозируем.
Этап разработки: сбор данных, их обработка, проведение ML-экспериментов, выбор лучшей модели, её тестирование.
Этап внедрения: этим тоже занимаемся мы, то есть наша работа не заканчивается на самой модели — дальнейшее её затаскивание в продукт происходит также с помощью ML-специалистов.
ML-разработка — это больше, чем Jupyter Notebook, который считается ключевым инструментом в нашей работе. Бесспорно, ноутбуки очень полезны: в них удобно проводить эксперименты, обрабатывать данные, проверять выводы написанных скриптов и строить графики. Однако, после проведения экспериментов нужно сделать следующее:
Реализовать инференс: это то, как наша модель будет вести себя в проде. Своего рода процесс, который принимает на вход данные, а возвращает предсказание модели.
Убедиться в том, что использованный нами код для лучшей версии модели не пропадёт, как и время на выполнение нашей задачи. Здесь мы приходим к тому, что такое пайплайн. Пайплайн – это набор операций машинного обучения.
На этой ноте процесс запуска ячеек в ноутбуке превращается в полноценную разработку функциональности, которая в дальнейшем будет использована в эксплуатации.
Как мы реализовали работу с пайплайнами
В ходе работы мы пришли к выводу, что процесс обучения ML-модели (пайплайн) практически повторяет собой тот процесс, в рамках которого мы решали задачи,за исключением первого и последнего этапов.
У нас есть репозиторий, в котором мы храним наши пайплайны: на одну продовскую задачу одна директория. Эта директория, как минимум, включает в себя два скрипта: для обработки сырых данных и для обучения модели.

Скрипт для обработки данных принимает на вход путь к сырому набору данных и формирует из него выборки, включающие в себя набор признаков и целевых переменных, для обучения и тестирования модели. Скрипт обучения использует эти выборки для того, чтобы в результате получить готовую ML-модель.
Обучение моделей мы проводим с помощью конфигурационного файла — каждый скрипт предобработки и обучения принимает на вход набор аргументов: для обработки данных это может быть название файла, который мы хотим использовать, параметры для train_test_split, настройки самописных функций для обработки текста; для обучения модели — различные параметры объектов Dataset и Dataloader, нейронной сети и коллбэков (обратных вызовов).
Мы сформировали универсальную функциональность, с помощью которой запускаем все наши пайплайны. Она принимает на вход нужный конфигурационный файл с параметрами и функции для указанного нами пайплайна. Схематично это показано на изображении:

Доступ к ресурсам у нас реализован через платформу Kubeflow, поэтому мы с помощью манифеста через терминал запускали обучение всегда как один сервис в одном Pod.
Вся эта история прекрасно работала до тех пор, пока мы не столкнулись со следующими ограничениями:
Мы не можем из терминала обращаться к какому-либо этапу пайплайна. На самом деле можем, но не так, как хотим. Ситуация: если у нас очень долго обучается модель, но её качество нас устраивает и мы хотим сохранить текущую контрольную точку, то просто так остановить этот процесс мы не можем. Так как весь пайплайн у нас запускается в одном Pod’е, то, соответственно, работать с этим процессом мы можем как с одной сущностью. В текущей ситуации мы вольны либо остановить весь пайплайн и настроить коллбэк модели под нашу возникшую внезапно потребность, либо дождаться, пока модель обучится до конца.
При возникновении ошибки внутри какого-либо этапа пайплайна всё нужно запускать заново. Ситуация аналогична первому пункту. Что-то сломалось в конце пайплайна — исправляем и запускаем с нуля.
Сложно сохранять все параметры пайплайна. Самостоятельно придумываем, как будем сохранять все параметры для всех запущенных экспериментов.
Неудобно запускать новые эксперименты: параметры приходится настраивать через терминал или прямо в коде.
Как мы используем Kubeflow Pipelines
Kubeflow Pipelines — это один из компонентов платформы Kubeflow, который позволяет строить ML-пайплайны в виде графов. С помощью этого сервиса можно декомпозировать один большой ML-пайплайн на универсальные блоки, чтобы использовать их повторно.
Для разработки пайплайна Kubeflow Pipelines используется DSL (domain-specific language), логика которого реализована в библиотеке kfp. В документации Kubeflow Pipelines говорится о двух версиях DSL, однако на момент реализации нашего решения при работе с разными версиями этой библиотекой мы выбрали версию kfp 1.8.11.
С помощью kfp можно работать с пайплайном как с графом, узлами которого являются этапы пайплайна. Каждый этап можно повторно использовать, а последовательность этих этапов настраивать так, как нам хочется, с помощью условий — объектов kfp.dsl.Condition.
Структура проекта
Для работы с Kubeflow Pipelines был разработан отдельный репозиторий. Основная составляющая пайплайна, компонент, представляет собой один независимый его шаг. Например: предварительная обработка, обучение, тестирование. В нашем случае компонентами являются Python-функции, в аргументы которых мы будем передавать нужные для каждого шага параметры. Так как у нас уже были готовые скрипты, которые декомпозировали наши пайплайны, то мы их попросту вынесли в этот проект.
Структура итогового репозитория приведена ниже:

Всю питоновскую функциональность, которая у нас была, мы перенесли в директорию core/components и разбили на универсальные компоненты, base, и относящиеся к конкретным пайплайнам — в примере это task_1 и task_2. Все конфигурационные файлы пайплайнов отдельно добавляем в core/configs.
Также мы добавили словарь всех компонентов core/components.yaml:

При разработке нового пайплайна требуется добавить необходимые его этапы в core/components и зафиксировать в этом словаре. Дальше процесс автоматизируется.
Автоматизированная сборка пайплайна
Для формирования и запуска пайплайна каждый компонент преобразуется в контейнер, объект kfp.dsl.ContainerOp, у которого обязательно должен быть задан базовый образ. Он должен содержать все библиотеки и другие зависимости, которые используются в функции этого компонента. Базовые образы всех компонентов могут быть одинаковыми или различаться между собой. В нашем случае для всех компонентов базовый образ один и содержит Python-библиотеки, которые используются в пайплайне.
Существует несколько способов преобразования функции в kfp.dsl.ContainerOp, мы выбрали метод kfp.components.func_to_container_op. Важное замечание: при работе с kfp все импорты библиотек и объявленные константы должны находиться внутри питоновской функции. Это, пожалуй, единственное изменение которое потребовалось нам сделать для внедрения Kubeflow Pipelines. Пример:

Процесс сборки пайплайна:
Преобразуем все нужные нам функции в
kfp.dsl.ContainerOp.Пишем логику пайплайна.
1. Преобразование в kfp.dsl.ContainerOp
Схема процесса:

В components.yaml мы храним все модули, которые хотим использовать, например:
base:
upload_data: kfp_pipelines.core.components.base. upload_data
download_data: kfp_pipelines.core.components.base. download_data
task_1:
preprocess_data: kfp_pipelines.core.components.task_1.preprocess_data
...
В основе функции для импорта компонентов лежит importlib.importmodule:
def import_from_config(obj_name: str, config: Dict[str, str]):
obj_name = obj_name.lower().strip()
if obj_name not in config.keys():
raise ValueError(
f"Provided object must be one of: {' '.join(list(config.keys()))}, "
f"but {obj_name} was given."
)
module_name, cls_name = config[obj_name].rsplit(".", 1)
retrieved_obj = getattr(import_module(module_name), cls_name)
return retrieved_obj
Для каждого пайплайна мы последовательно указываем название нужных нам компонент и для их импорта используем скрипт выше.
Преобразуем в объект kfp.dsl.ContainerOp с помощью метода kfp.components.func_to_container_op:
with open(Path(__file__).parent / "components.yaml", "rt") as config:
_CONFIG = yaml.safe_load(config.read())
def init_ops(steps: list, project: str = "task_1"):
_possible_steps = {**_CONFIG[project], **_CONFIG["base"]}
ops = {}
for step in steps:
ops[step] = func_to_container_op(
import_from_config(step, _possible_steps),
base_image={ПУТЬ К БАЗОВОМУ ОБРАЗУ},
)
return ops
На выходе из этой функции мы получаем словарь компонентов пайплайна, к которым будем обращаться по заданным нами ключам.
2. Строим пайплайн
Упрощённая схема пайплайна:
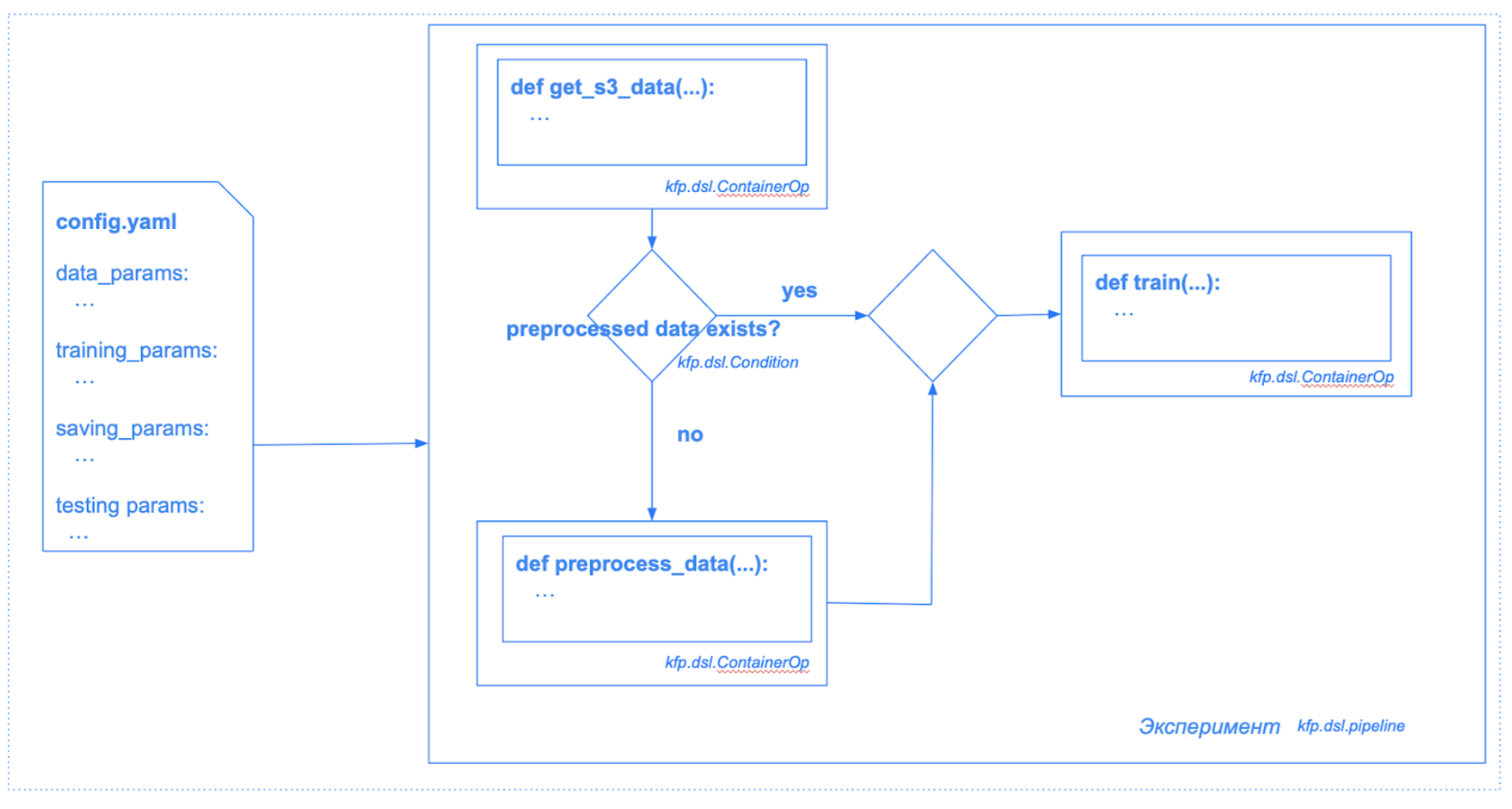
Мы до сих пор оперируем нашими старыми методами, но всю остальную логику будет реализовывать функциональность kfp. Рассмотрим псевдокод, реализующий эту схему для task_1:
from kfp.dsl import Condition, pipeline
from kfp_pipelines.core import init_ops, run_pipeline
# Pipeline metadata
_PROJECT_NAME = "task_1"
_RUN_NAME = f"{_PROJECT_NAME}_run"
# Pipeline steps
_LOAD_DATA = "download"
_FILE_EXISTENCE = "check_file_existence"
_PREPROCESS_DATA_STEP = "preprocess_data"
_TRAIN_STEP = "train"
_UPLOAD_DATA = "upload"
def main() -> None:
# Initiating `ContainerOp` objects
ops = init_ops(
_PROJECT_NAME,
[
_LOAD_DATA,
_FILE_EXISTENCE,
_PREPROCESS_DATA_STEP,
_TRAIN_STEP,
_UPLOAD_DATA,
],
)
# All the arguments of the whole pipeline should be specified
@pipeline(
name=_PROJECT_NAME,
description=f"`{_PROJECT_NAME}` data preprocessing and model training",
)
def task_1_pipeline(
data_param,
training_param,
) -> None:
_load_data = ops[_LOAD_DATA](
data_param=data_param
)
_data_existence = ops[_FILE_EXISTENCE](
paths=[
_load_data.outputs["train_data_path"],
_load_data.outputs["val_data_path"],
]
)
# if training and validation data do not exist, run preprocessing, else skip
# this step
with Condition(
_data_existence.output == 0,
_PREPROCESS_DATA_STEP,
):
_preprocess_data = ops[_PREPROCESS_DATA_STEP](
data_param=data_param
).after(_load_data)
_train = ops[_TRAIN_STEP](
train_data_path=_load_data.outputs["train_data_path"],
val_data_path=_load_data.outputs["val_data_path"],
training_param=training_param
).after(_preprocess_data)
_upload = ops[_UPLOAD_DATA](
output_path=_train.outputs["output_path"],
save_param=_train.outputs["to_save"],
).after(_train)
run_pipeline(
project_name=_PROJECT_NAME,
run_name=_RUN_NAME,
func=task_1_pipeline,
)
if __name__ == "__main__":
main()
Мы формируем функцию main, в которой будем инициализировать словарь компонентов ops. Далее выстраиваем логику самого пайплайна. Для этого мы пишем функцию и используем для неё декоратор kfp.dsl.pipeline. Важное замечание: функция пайплайна должна в качестве параметров явно содержать всё то, что мы будем использовать, а функции внутри пайплайна должны содержать явно указанные аргументы. DSL kfp не поддерживает *args и **kwargs, поэтому все параметры компонентов в пайплайне нужно задавать явно.
Внутри пайплайна мы можем передавать параметры компонента как из конфига, так и из других компонентов. Чтобы один компонент принимал на вход значения из другого, выход первого должен быть представлен в виде объекта NamedTuple. Пример:
from typing import NamedTuple
def download(
data_param
) -> NamedTuple(
"Outputs",
train_data_path=str,
val_data_path=str,
):
from collections import namedtuple
...
train_data_path = "sample_path"
val_data_path = "sample_path"
output = namedtuple(
"Outputs",
[
"train_data_path",
"val_data_path",
],
)
return output(train_data_path, val_data_path)
Важно:
В теле функции-компонента должны быть указаны все импорты. Это значит, что импортируемые библиотеки должны быть установлены в образе, указанном при формировании контейнера из этой функции-компонента.
Объекты
kfpне умеют обрабатывать русский язык: docstring и комментарии нужно писать на английском.DSL
kfpне поддерживает типNone, булевы значения (True/False), типtyping.Dict(обычный dict поддерживается), типы любых нестандартных объектов.
Касаемо последнего пункта, если у вас есть функция:
def train(
sample_obj: torch.utils.data.DataLoader,
sample_bool: bool = False,
sample_dict: Dict[str, Any],
sample_none = None,
...
то kfp не сможет её обработать из-за типов. Пример, как можно избежать ошибки:
def train(
sample_obj, # не указывать тип
sample_bool: bool = 0, # заменить True/False на 1/0
sample_dict: dict, # не конкретизировать дикт typing'ом
sample_none = "", # вместо None вставлять пустую строку или иначе обрабатывать это значение
...
Как это выглядит
Интерфейс экспериментов показан ниже.

У одного эксперимента может быть несколько запусков. Индикатор статуса показывает, завершился ли эксперимент успешно либо упал с ошибкой. На картинке показан эксперимент vko_name_predictor, у которого было три запуска, два из которых успешно завершились. Причины, по которым запуск может провалиться в основном связаны Python-кодом, а именно логикой, реализованной внутри компонент пайплайнов.
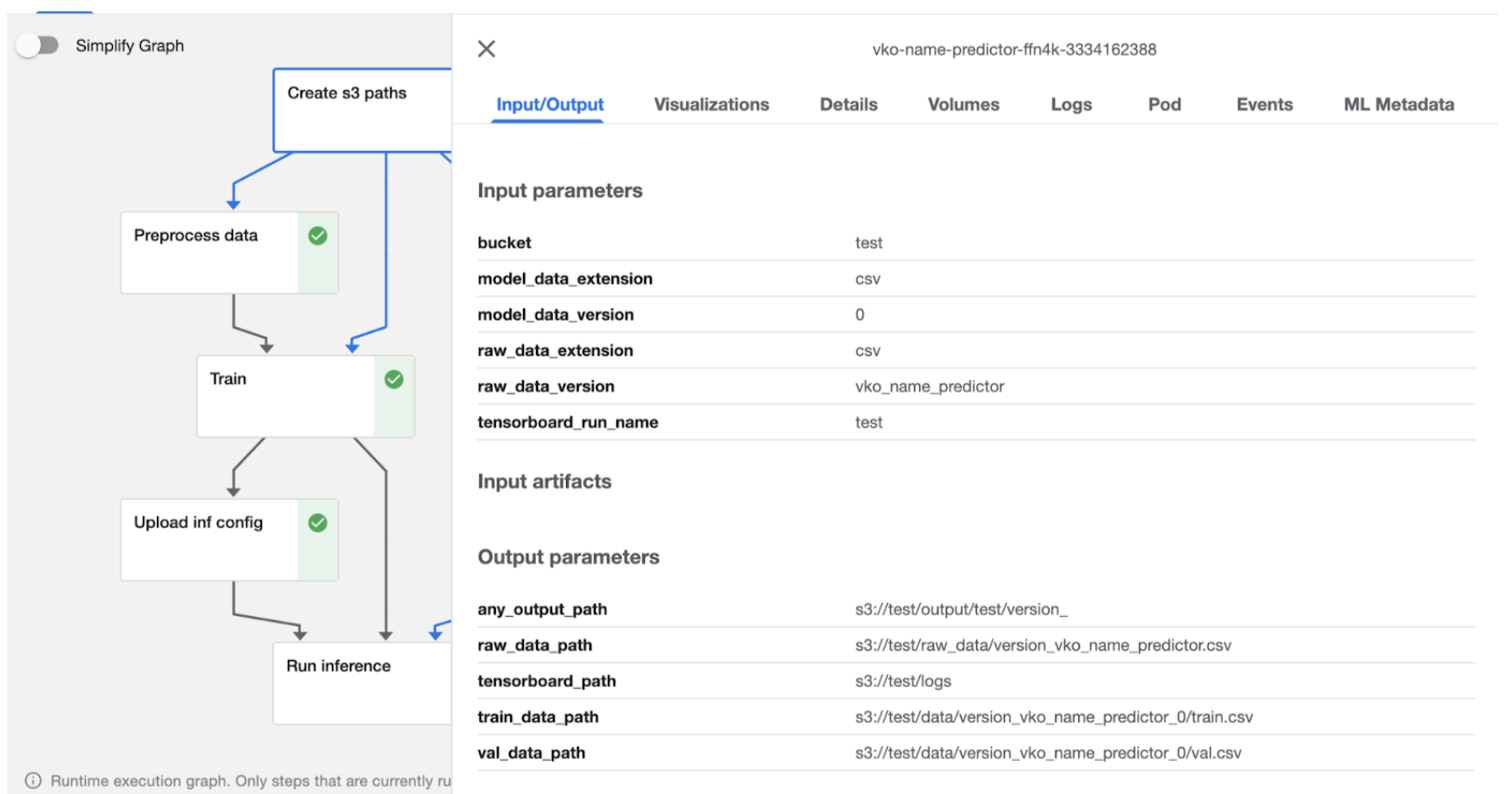
Можем нажать на один из завершенных пайплайнов и посмотреть о нем детальную информацию.

Каждый запуск имеет графическое отображение выполнения всех этапов в виде графа: по ходу выполнения этапов пайплайна пользователь может наблюдать, какой из них сейчас выполняется. Успешно завершенные этапы пайплайна обозначены зелеными индикаторами. На картинке наш пайплайн состоит из следующих этапов:
create s3 paths – создаем пути на нужные нам данные;
preprocess data – обрабатываем данные;
train – обучаем модель;
upload inf config – формируем конфигурационный файл инференса и сохраняем его;
run inference – тестируем модель на инференсе.
Стрелки показывают, откуда идут входные данные в этапы пайплайна. Например, все три этапа «preprocess data», «train» и «run inference» получают на вход путь к данным, с которыми предстоит работать, из этапа «create s3 paths». Графическое отображение стрелок можно настроить с помощью кнопки «Simplify Graph», тогда в случае упрощенного графа стрелки будут показывать последовательность этапов, а не потоков данных.
Нажав в интерфейсе на любой из этапов, можно посмотреть какие у него параметры, что он ожидает на вход и должен отдавать на выход. Пример показан ниже.
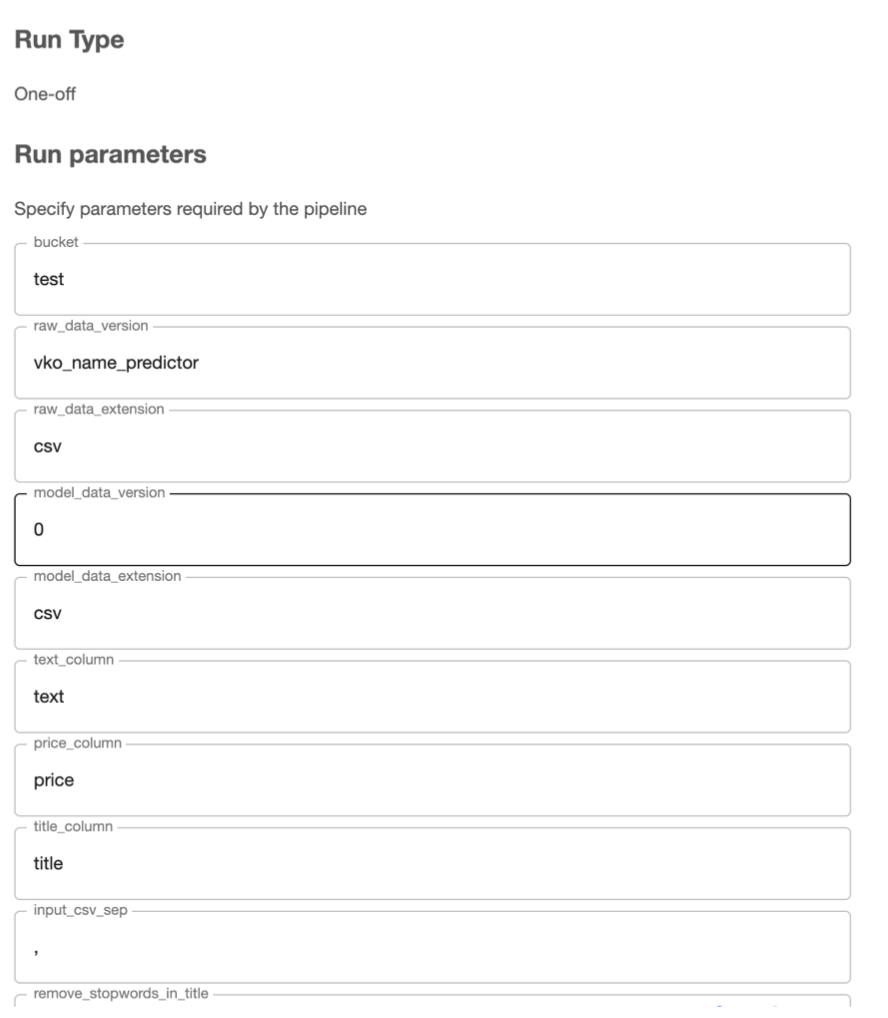
Для нового запуска эксперимента достаточно нажать «Clone Run» в интерфейсе и ввести в интерфейсе новые параметры, с которыми мы хотим работать. Форма, которая будет представлена, повторяет конфигурационный файл пайплайна. Все значения можно будет настроить через интерфейс.
Итог
Таким образом, с помощью библиотеки kfp и нескольких функций мы можем интегрировать существующий код для запуска ML-пайплайнов в инструмент Kubeflow Pipelines с удобным интерфейсом, в котором пользователь, он же разработчик, может быстро запускать эксперименты по машинному обучению и выбирать лучшее решение.