
Сегодня мы находимся на переходе от ML творческого, в котором человек творит как художник, к ML энтерпрайзному, похожему на разработку в классическом понимании. В 2014 году в России появилась магистратура по машинному обучению, то есть уже начали готовить специалистов. Примерно тогда рандом форест и градиентный бустинг начали заезжать в прод. Тем не менее всё ещё мало кто может внедрить весь этот зоопарк моделей и алгоритмов ML в бизнес.
Меня зовут Андрей Зубков, я глава отдела AI в ЕВРАЗе. Расскажу о том почему и откуда возникают проблемы внедрения ML в бизнес и подумаю вместе с вами как достигать взаимопонимания с заказчиком.

С чего начинается энтерпрайзный ML
Точно так же как в классической разработке. Сначала мы должны провести этап бизнес-анализа. И это самая сложная часть работы, потому что от неё зависит всё остальное, а сделать её качественно могут немногие, так как нет рецептов, строгой инструкции о том, как это сделать хорошо.
Первое, о чём стоит задуматься — это какие проблемы нужно решить. Важно сформулировать задачу так, чтобы она была связана с исходным вопросом: зачем мы туда лезем?
Дальше, несмотря на то, что мы говорим, что машинное обучение — это что-то новое, мы приходим в те места, где какое-то решение уже существует. По-настоящему новые задачи, которых никто никогда не решал, встречаются архиредко.
Поэтому у нас почти всегда есть какое-то «бейзлайн» решение. Оно может быть тупое, простое, как угол дома, и даже не очень хорошо работать, но оно есть. И это радость, счастье, гордость, и повод для единства, потому что с ним можно сравниваться. Мы можем сказать, если наша последующая работа превзойдёт имеющееся решения. Это позволяет видеть пользу от работы как нам, так и заказчику.
Также может возникнуть штука, о которой редко задумываются, но её всегда надо учитывать – непреодолимые ограничения. Потому что есть физика — бессердечная как статистика. Отменить её нельзя, приходится с ней считаться. Соответственно, нам нужно понимать, а какие чисто физические ограничения есть в нашем процессе.
Помимо этого есть бизнес-процессы, которые поменять не получится. Чем больше потенциальный эффект и значимость нашего начинания, тем таких мест меньше, но определённый предел есть всегда.
Продувка металла: как ML ничего не решает
Как ни странно, все говорят, что машинное обучение — это про данные. Хотя я бы сказал, что данные — это лишь четвёртый пункт. Потому что чисто теоретически, если данные можно собрать, то это уже не проблема, это вопрос затрат. И по времени, и по деньгам. Проблемы же возникают, когда данных нет вообще...
Возьмём пример.
Была задача про продувку металла. Есть кислородный конвертор, туда заливают сталь, в этой стали есть примеси. Нужно их продуть кислородом и выжечь. Заодно довести металл до нужной температуры.
Проблема в том, что кислородный конвертор не последний этап обработки и ему нужно успевать вовремя отдавать металл с нужными свойствами. А продувка к этому моменту отдачи может ещё не закончиться или не получить требуемого качества.
Существующее решение этой проблемы на комбинате было сколь простым, столь же и нестабильным: посадить оператора, который будет пытаться с помощью ломаопыта угадать, сколько времени нужно продувать, каким количеством воздуха и какой результат из этого получится.
При этом, в задаче есть непреодолимые ограничения. Если идёт процесс, то его нельзя останавливать, надо доводить металл до точки кипения. Такая данность. При этом мы знаем, что если мы дадим больше топлива, то получим более высокую температуру и меньше углерода и других примесей, т.к. их попросту выжжет. И чем больше времени будет затрачено на продувку, тем при прочих равных условиях температура будет ниже, т.к. металл охлаждается вполне стандартно: какое-то количество энергии со временем теряется.
Проблема сформулирована — классно! Теперь нужно от этой проблемы прийти к «brand new»новому решению На существующем примере решения, мы можем попытаться сформулировать, насколько мы должны улучшить процесс, чтобы само предприятие стало осмысленным, экономически оправданным. Отсюда рождаются критерии успеха и требования к эффекту.
Из непреодолимых ограничений — возникают вопросы про то, насколько хорошо должна работать модель и каким чисто техническим требованиям должна соответствовать, чтобы она не противоречила физике.
Формулируя требования к решению, мы ещё ставим задачу окончательно. Так, по имеющимся данным необходимо понять всего ли нам достаточно, или какие-то показатели нужно дособирать.
В данном случае проблема поставки металла решается не вовремя и может быть решена двумя вариантами. Во-первых, можно держать какое-то количество металла в запасе. Если продувка не вовремя закончилась или не получила качество нужное, то достаём металл из запаса, закидываем в топку и делаем следующую продукцию.
Во-вторых, можно попытаться научиться лучше предсказывать продувку, ограничив её так, чтобы она всегда давала нужное качество вовремя или более часто.
Итак, мы сформулировали требования к данным, к точности и скорости модели. На этом этапе обычно возникает один вопрос: а где тут ML?
Выясняется, что пока что нет никакого ML. По крайней мере, ничего специфичного для ML. Ведь для любого классического алгоритма на чистой логике и фелс также понадобятся данные, понимание требований, ограничений, времени на выполнение алгоритма и прочее. Таким образом есть просто термины, которые могут, в принципе, легко трансформироваться.
Различия появляются только тогда, когда мы начинаем писать код. Потому что у нас есть требования к модели, которые описаны на языке непонятному для классического разработчика. Это какие-то метрики, объяснения, принцип черного/белого ящика и тому подобное. Но при этом, как ни странно, в этот момент задачей занимается уже конкретный специалист, и у него есть очень конкретные, сопоставимые one to one к предыдущим полученным данным. Для такого узкого специалиста внутренние критерии успеха не являются задачами всего проекта. Поэтому сформулировав решение проблемы, задача ещё не поставлена.
Мы приходим к ситуации, когда есть специалист, например, по java, у него есть свои фреймворки и понимание того, как на этих фреймворках выполнить конкретные требования проекта. И точно так же работает с машинным обучением.
На данном этапе всё ещё не появляется никакой специфики для проекта и для самого процесса внедрения решений. Мы лишь сформулировали целевую задачу, что должна быть зависимость в моделях: химический состав должен быть важнее для предсказаний. Погода – это второй фактор, а скорость продувки на последнем месте. Также мы сформулировали критические метрики, проверили их, выяснили, что нужны данные вот такие для этих предсказаний. Тоже их проверили, удостоверились. Но, как ни странно, модель не выстрелила.
При этом на моменте, когда мы сформулировали эту модель, сама задача, которую поставил себе MLщик, не решена. Хотя цель всего проекта вполне может быть уже достигнута, потому изначальные требования бизнес-анализа не совсем чёткие.

Соответственно, всегда, когда мы доходим до какого-то этапа и имеется какой-то успех, можно сделать очень простую штуку — протестировать. И точно так же, когда мы реализуем какое-то решение, оно может заработать не совсем так как хотелось. Именно тут начинается примерно 60% работы дата саентиста, или MLщика на проекте, то есть на моменте А/Б-тестирования. Так что же тут специфично для ML? А примерно ничего. И это радует и бодрит, потому что с проблемами бизнес-анализа — как ставить в классических интерпрайз-проектах задачи и как их связывать с целями — мы что-то понимаем и умеем.
А теперь от этого концептуального и идеологического рассуждения давайте разберёмся, всё ли так работает на деле?
Как мы катили ML в прод
Как показывает опыт ЕВРАЗ, плюс/минус всё, так и работает. Потому что в 2020 году мы начинали самостоятельно внедрять ML в ЕВРАЗ, и за год внедрили четыре ML-решения.

Инфраструктура
В ЕВРАЗе на сегодняшний день команда машинного обучения состоит из 23 человек. Техлидерство в этой команде было вне компетенции, вне границ ЕВРАЗа. При этом ещё идеи зачастую брали уже из каких-то реализованных внешних проектов. А в 2021 году в то же время мы пришли к ситуации, что сделали 40 проектов, которых внедрили в продакшн. И до сих пор они нормально работают. Возникают, как везде, проблемы, но они не катастрофичны, выводить из релиза не приходиться.
Почему это так сработало? Было несколько факторов, которые спасли нас от того, чтобы сесть в лужу.
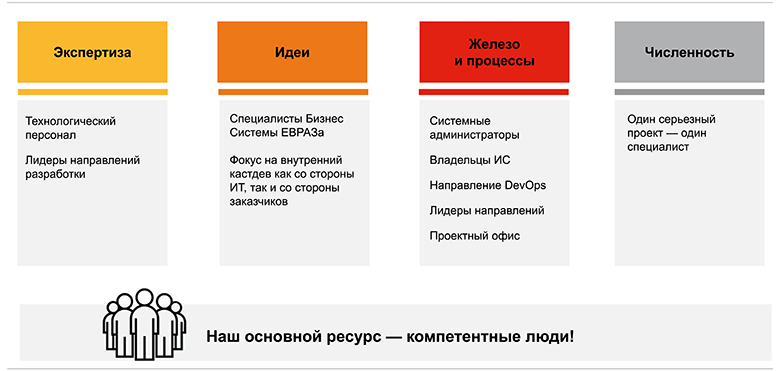
В первую очередь, было понимание, что для того, чтобы строить такие наукоёмкие проекты, нужно не столько железо, базы данных, серверы и прочее, сколько экспертиза. Если ребята, которые пишут код, обладают более-менее универсальными знаниями, то есть они могут пойти в любую сферу, то с технологическим персоналом всё сложнее. Они — те самые эксперты в доменной области бизнеса. Их за один год из какой-то левой компании не привезти.
Далее, чтобы делать проекты и внедрять какие-то решения, нужны нормальные, здоровые идеи. Они тоже не берутся из ниоткуда. Должны быть люди, которые придумают их и самое главное расскажут про неё компании. Ведь бывают ситуации, когда стоишь с товарищем в курилке, он рассказывает классную идею, но к руководству идти с ней не собирается. Говорит, что они не воспримут или заставят его её самому реализовывать. Короче, доносчику — кнут. Поэтому такие люди не высовывают голову выше травы. И это здоровая реакция. Тем не мене, должен быть отлаженный внутренний customer development.
Естественно, без железа тоже нельзя. Нужны и сервера, и базы данных. А, главное, нужны люди, которые со всем этим умеют работать и знают, как это построено в случае вот этой конкретной компании. Потому что если вы пытались хотя бы раз зайти в какую-то новую компанию в качестве консалтинга или просто аутсорсного разработчика, то сталкивались с ситуацией, когда вы спрашиваете, где лежат те или иные данные, а 20 человек, сидящие в комнате, разводят руками и говорят, что у них был Вася Пупкин, который уволился три года назад, и с тех пор никто об этом не знает. Я об это сломал не один и даже не два комплекта зубов. Массовая проблема.
Помимо того, эти люди должны не просто знать как строить, но и делать это хорошо. Причём, не надо никого обвинять из предшественников, они тоже знали, как строить хорошо. У них были свои причины, чтобы сделать то, что они сделали, и построить те костыли, которые нужно потом пытаться исправлять.
Но самая страшная штука на нашем перегретом рынке труда — это численность задач. В ЕВРАЗ мы неоднократно убеждались и продолжаем убеждаться, что если ты хочешь получить хороший результат, то один человек должен заниматься одной серьёзной темой. Потому что наш мозг однозадачный, как вполне себе понятный процессор. Если дать ему несколько задач, он будет просто между ними переключаться, тратить на это время, и его эффективность работы будет снижаться. Кроме того, у него не будут работать и внутренние офлайн механизмы в психике, которые не сознательно могли бы подтаскивать ему новые идеи. Ведь эта штука работает только при полном погружении, когда мозг ничто не отвлекает и не заставляет переключаться. Соответственно, больше проектов — больше людей.
Приоритезация
Мы разобрались с инфраструктурой и тем, на чём стоит ЕВРАЗ. Дальше возникает следующая штука, с которой я в рамках работы в консалтинге сталкивался регулярно — приоритизация. Представим, что у нас есть какое-то количество идей и людей. Вопрос: Что делать? За что браться первым? Ведь в отличие от идей, количество ресурсов ограничено. Выясняется, что есть так называемый cost benefit analysis (CBA) — подсчёт того, сколько будет стоить разработка и чего она принесёт. Им практически никто не занимается. Зато, люди говорят о нём, критикуют, но при этом не делают. Как правило, просто берётся группа экспертов, которые от балды выставляют какие-то оценки и закрытыми глазами стреляют в мишень.
Проблема в том, что если не делать такого анализа, то получается, что мы не стреляем в мишень, а играем в русскую рулетку.

При этом, главное — даже не метод оценки, а контроль за прогрессом и корректировка предыдущих результатов.

Дополнительно почитать про анализ CBA можно в этих статьях:
Про то почему оценки без техники — беда, и это научно доказано
Пример, когда экспертные оценки в попугаях сработали
Пример, как улучшить эффективность за счет более долгой оценки
Коммуникация и взаимопонимание
Всё, о чём мы говорили, приводит к мысли о том, что основная проблема — это взаимопонимание. Выясняется, что коммуникация важнее, разработки. Без коммуникации и внятного ТЗ результаты получаются так себе.

Тут показано, что со временем разработка становится хуже, так как мы начинаем переживать, испытывать психологические проблемы, выгорать и прочее. А вот с коммуникацией и взаимопониманием ситуация обратная.
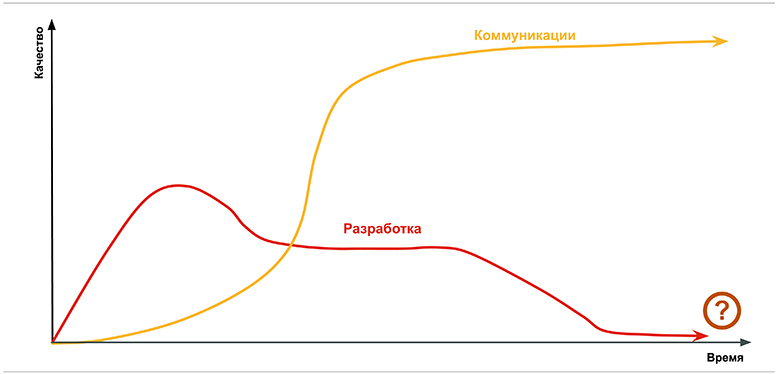
Чем больше времени тратиться на неё, тем лучше в целом результат. И это практически бесконечное улучшение. Это человеческая специфика, биология. Мы социальные животные. Однако есть важное замечание: не всякий разговор, письмо или сообщение в чате — это коммуникация. Она возникает лишь тогда, когда есть стремление понять собеседника. И для этого есть очень много методов помимо разговора one to one:

Используйте их все, они помогают.
Как не облажаться?
Мы приходим к тому, что есть три штуки, которые позволяют не облажаться: коммуникация, приоритизация и инфраструктура:

А также три тезиса:

Вот примеры как это всё соблюдается в ЕВРАЗе:
От концепции к реализации:
-
Используем централизованное хранение кода и сборочных конфигураций:
а. Azure DevOps Repos & Pipelines
b. GitLab & GitLab CI/CD - opensource альтернатива
-
Обученные модели хранятся в BLOB хранилище Maven Nexus
a. Версия модели используемая для доставки указывается в конфигурации
b. Изменение версии кода - не обязательно влечёт изменение модели
-
Финальным артефактом является образ докер, используемый при доставке:
a. При сборке обученная модель упаковывается в образ
b. Изменение версии модели - влечёт изменение версии кода, а значит пересборку решения
-
Доставка в кластеризованные среды:
a. RedHat OpenShift
b. Kubernetes - opensource альтернатива
Используется единый набор скриптов для тестирования и объяснения стандартных моделей, объяснения и метрики хранятся в MLFlow
Выбор release candidate осуществляется разработчиком
Обновление модели утверждается владельцем процесса/продукта, а не разработчиком

Вдобавок, маленький хинт для тех, кто неоднократно страдал от ситуации, когда клиент начинает наседать во время проекта. В проектах есть критические задачи. Но их делать необязательно, если высокий теншен и есть задачка попроще.

Выводы
Я попытался показать что, ML — это не революция ни в каком виде, и тем более не new programming. Это просто ещё одна технология, ещё один модуль, который мы можем подключать к какому-то решению. Сама же оценка перед решением не изменилась. Остались те же самые подходы к тестированию, весь тот же самый Q One Day. В целом мы продолжаем использовать одни и те же базовые принципы.
Даже самая сложная часть в ML, из-за которой модели проваливаются, присутствует также в обычной разработке. Иначе говоря, она вне ML. Это бизнес-аналитика, тестирование, архитектура, DevOps. Достаточно простые ходы.
Кроме этого нужно сделать важное замечание: artificial neural network, или глубокое обучение пока кроме CV, не находится в проде.
Также есть важный момент с CBA. Нужно понимать, что это не инструмент, который даёт нам результат в виде артефакта. Скорее это некий план. И как большинству планов - мы не следуем ему до конца. Бенефит мы получаем от обсуждения и погружения в тему, ведь так мы понимаем ситуацию лучше. Дело в том, что проект — это занятие не на два дня, не на неделю и даже не на месяц. Как правило, это от четырех месяцев до целого года, а то может быть и на несколько лет. За это время убеждения людей существенно меняются, а ещё у них оперативная память конечная: они свои взгляды и понимание ситуации забывают. Чтобы эта трансформация в один момент не привела к какому коллапсу, для этого нужно фиксировать то, что они когда-то сформулировали.