
В последнее время я серьезно взялся за изучение языка Rust, и, как поступил бы на моем месте любой адекватный программист, после написания нескольких небольших программ я решил попробовать сделать что-то немного более амбициозное: я написал на Rust виртуальную машину Java. Не став сильно оригинальничать, я назвал ее просто rjvm. Вы можете найти ее код на GitHub.
Хочу подчеркнуть, что это лишь простенькая модель JVM, созданная в учебных целях, а не серьезная реализация. В частности, она не поддерживает:
дженерики
потоки
рефлексию
аннотации
I/O
just in time компилятор
интернирование строк
Однако мной было реализовано достаточно много нетривиальных вещей:
операторы управления потоком выполнения (
if, for, ...)создание примитивов и объектов
вызов виртуальных и статических методов
исключения
сборка мусора
разрешение классов из
jar-файла
Например, ниже представлен фрагмент кода тестовой программы:
class StackTracePrinting {
public static void main(String[] args) {
Throwable ex = new Exception();
StackTraceElement[] stackTrace = ex.getStackTrace();
for (StackTraceElement element : stackTrace) {
tempPrint(
element.getClassName() + "::" + element.getMethodName() + " - " +
element.getFileName() + ":" + element.getLineNumber());
}
}
// Мы используем это вместо System.out.println, поскольку реального ввода/вывода у нас нет.
}Здесь используется реальный rt.jar, содержащий классы из OpenJDK 7 — то есть, в приведенном выше примере класс java.lang.StackTraceElement получен из самого настоящего JDK!
В целом, я очень доволен тем, что узнал о Rust и о том, как реализовать виртуальную машину. В частности, я невероятно рад, что смог реализовать настоящий, работающий сборщик мусора. Конечно, он довольно примитивен, но он мой, и он мне нравится. Учитывая, что я достиг той цели, которую изначально ставил перед собой, я решил закончить работу над этим проектом. Я знаю, что он грешит некоторыми багами, но исправлять их я не планирую.
Обзор
В этой статье я расскажу о том, как работает моя JVM. В последующих частях я более подробно расскажу о некоторых аспектах, упомянутых в этой обзорной части.
Организация кода
Код представляет собой стандартный проект на языке Rust. Я разделил его на три крейта (т.е. пакета):
reader, который умеет читать.classфайлы и содержит различные типы, моделирующие их содержимое;vm, содержащий виртуальную машину, которая может выполнять код в виде библиотек;vm_cli, содержащий очень простую программу запуска виртуальной машины из командной строки в духе исполняемого файла java.
Я подумываю о том, чтобы вынести крейт reader в отдельный репозиторий и опубликовать его на crates.io, поскольку, как мне кажется, он действительно может пригодиться кому-нибудь.
Парсинг .class файла
Как известно, Java является компилируемым языком — компилятор javac берет ваши исходные .java файлы и создает различные .class файлы, обычно распространяемые в .jar файле, который по сути является обычным zip-архивом. Таким образом, первое, что необходимо сделать для выполнения какого-либо Java-кода, — это загрузить .class файл, содержащий байткод, сгенерированный компилятором. .class файл, в свою очередь, содержит различные сведения:
метаданные класса, такие как его имя или имя исходного файла
имя родительского класса
реализованные интерфейсы
поля с указанием их типов и аннотаций
-
и методы с:
их дескриптором, представляющим собой строку с указанием типа каждого параметра и возвращаемого типа
метаданными, такими как выражения
throws, аннотации, информация о дженерикахбайткодом, а также некоторыми дополнительными метаданными, такими как таблица обработчика исключений и таблица номеров строк.
Как уже упоминалось выше, я создал в рамках rjvm отдельный крейт под названием reader, который может парсить .class файл и возвращать структуру Rust, моделирующую класс и все его содержимое.
Выполнение методов
Главным элементом API крейта vm является Vm::invoke, который используется для выполнения методов. Он принимает стек вызовов (CallStack), который будет содержать различные фреймы (CallFrame) — по одному на каждый выполняемый метод. При выполнении main стек вызовов изначально будет пуст, и для ее запуска будет создан новый фрейм. Затем каждый вызов функции будет добавлять в стек вызовов новый фрейм. По завершении выполнения метода соответствующий ему фрейм будет сброшен и удален из стека вызовов.
Большинство методов будет реализовано на языке Java, и, соответственно, выполняться будет их байткод. Однако rjvm поддерживает и нативные методы, т.е. методы, которые реализуются непосредственно JVM, а не в виде байткода. Их достаточно много в более низкоуровневых частях Java API, где необходимо взаимодействие с операционной системой (например, для выполнения операций ввода-вывода) или средой выполнения. В качестве ярких примеров таких методов могут послужить System::currentTimeMillis, System::arraycopy и Throwable::fillInStackTrace. В rjvm они реализованы через функции Rust.
JVM — это стековая виртуальная машина, т.е. инструкции байткода оперируют в основном стеком значений (value stack). Также существует набор идентифицируемых индексами локальных переменных, которые могут использоваться для передачи аргументов методам и хранения значений. Они ассоциируются с каждым фреймом в rjvm.
Моделирование значений и объектов
Тип Value моделирует возможное значение локальной переменной, элемента стека или поля объекта и реализуется следующим образом:
/// Моделирует общее значение, которое может храниться в локальной переменной или в стеке.
#[derive(Debug, Default, Clone, PartialEq)]
pub enum Value<'a> {
/// Неинициализированный элемент. Его не может быть в стеке,
/// но он служит состоянием по умолчанию для локальных переменных.
Uninitialized,
/// Моделирует все 32-и-менее-разрядные типы в jvm: `boolean`,
/// `byte`, `char`, `short`, and `int`.
Int(i32),
/// Моделирует значение long.
Long(i64),
/// Моделирует значение float.
Float(f32),
/// Моделирует значение double.
Double(f64),
/// Моделирует объект
Object(AbstractObject<'a>),
/// Моделирует null
Null,
}Кстати, сюда отлично подходит тип enum из Rust — это идеальная абстракция для выражения того факта, что значение может быть нескольких различных типов.
Для хранения объектов и их значений я первоначально использовал простую структуру Object, содержащую ссылку на класс (для моделирования типа объекта) и Vec<Value> для хранения значений полей. Однако, когда я реализовал сборщик мусора, мне пришлось сделать эту реализацию более низкоуровневой, с кучей указателей и кастов (приведение типа) в стиле C! В текущей реализации AbstractObject (который моделирует "реальный" объект или массив) — это просто указатель на массив байтов, содержащий пару заголовочных слов и (после) значения полей .
Выполнение инструкций
Выполнение метода подразумевает поочередное выполнение инструкций его байткода. JVM имеет обширный список инструкций (более двухсот!), которые представлены в байткоде одним байтом. Многие инструкции сопровождаются аргументами. Некоторые из них имеют переменную длину. В коде это смоделировано типом Instruction:
/// Представляет собой инструкцию байткода Java.
#[derive(Clone, Copy, Debug, Eq, PartialEq)]
pub enum Instruction {
Aaload,
Aastore,
Aconst_null,
Aload(u8),
// ...Как уже говорилось выше, при выполнении метода мы получаем стек и массив локальных переменных, на которые инструкции ссылаются по индексу. Также будет инициализирован нулем счетчик инструкций (program counter), то есть адресом следующей инструкции, которая будет выполняться. Эта инструкция будет обработана, а счетчик инструкций обновлен — обычно увеличен на единицу, но различные инструкции перехода (jump instructions) могут перемещать его в другие места. Таким образом реализуются все операторы управления потоком выполнения программы, такие как if, for или while.
Особое семейство составляют инструкции, которые могут вызывать другой метод. Существуют различные способы определения того, какой метод должен быть вызван: самые главные из них - виртуальный или статический поиск, но есть и другие. После разрешения правильной инструкции rjvm добавит новый фрейм в стек вызовов и начнет выполнение метода. Возвращаемое значение метода будет помещено в стек, если оно не является void, и выполнение возобновится.
Формат байткода Java весьма интересен, и я планирую посвятить отдельный пост различным видам инструкций.
Исключения
Исключения — довольно сложный в реализации элемент, поскольку они ломают нормальный поток выполнения программы и могут вернуться из метода (и распространиться по стеку вызовов!) раньше времени. Однако я вполне доволен тем, как я их реализовал, и собираюсь продемонстрировать вам часть их кода.
Первое, что нам необходимо знать, это то, что каждый блок catch соотносится с соответствующей записью таблицы исключений метода — каждая запись содержит диапазон покрытых счетчиков инструкций, адрес первой инструкции в блоке catch и имя класса исключения, которое блок перехватывает.
Далее, сигнатура CallFrame::execute_instruction выглядит следующим образом:
fn execute_instruction(
&mut self,
vm: &mut Vm<'a>,
call_stack: &mut CallStack<'a>,
instruction: Instruction,
) -> Result<InstructionCompleted<'a>, MethodCallFailed<'a>>Где типы:
/// Возможный результат выполнения инструкции
enum InstructionCompleted<'a> {
/// Указывает на то, что выполненная инструкция относится к семейству
/// return. Вызывающая сторона должна остановить выполнение метода и вернуть значение.
ReturnFromMethod(Option<Value<'a>>),
/// Указывает на то, что это не return-инструкция, и поэтому выполнение должно
/// возобновиться с инструкции в соответствии со счетчиком инструкций.
ContinueMethodExecution,
}
/// Моделирует факт неудачного выполнения метода
pub enum MethodCallFailed<'a> {
InternalError(VmError),
ExceptionThrown(JavaException<'a>),
}и стандартный для Rust тип Result:
enum Result<T, E> {
Ok(T),
Err(E),
}Таким образом, выполнение инструкции может привести к четырем возможным состояниям:
инструкция выполнена успешно, и выполнение текущего метода может быть продолжено (стандартный случай);
инструкция выполнена успешно, и это была return-инструкция, поэтому текущий метод должен сделать return с (опциональным) возвращаемым значением;
инструкция не могла быть выполнена, так как произошла внутренняя ошибка виртуальной машины;
или инструкция не могла быть выполнена, так как было выброшено стандартное исключение Java.
Таким образом, код, выполняющий метод, выглядит следующим образом:
/// Выполняет метод целиком
impl<'a> CallFrame<'a> {
pub fn execute(
&mut self,
vm: &mut Vm<'a>,
call_stack: &mut CallStack<'a>,
) -> MethodCallResult<'a> {
self.debug_start_execution();
loop {
let executed_instruction_pc = self.pc;
let (instruction, new_address) =
Instruction::parse(
self.code,
executed_instruction_pc.0.into_usize_safe()
).map_err(|_| MethodCallFailed::InternalError(
VmError::ValidationException)
)?;
self.debug_print_status(&instruction);
// Перемещаем pc к следующей инструкции, перед ее выполнением,
// поскольку мы хотим, чтобы "goto" перенаправил поток выполнения
self.pc = ProgramCounter(new_address as u16);
let instruction_result =
self.execute_instruction(vm, call_stack, instruction);
match instruction_result {
Ok(ReturnFromMethod(return_value)) => return Ok(return_value),
Ok(ContinueMethodExecution) => { /* продолжаем выполнение цикла */ }
Err(MethodCallFailed::InternalError(err)) => {
return Err(MethodCallFailed::InternalError(err))
}
Err(MethodCallFailed::ExceptionThrown(exception)) => {
let exception_handler = self.find_exception_handler(
vm,
call_stack,
executed_instruction_pc,
&exception,
);
match exception_handler {
Err(err) => return Err(err),
Ok(None) => {
// Передача исключения вызывающей стороне
return Err(MethodCallFailed::ExceptionThrown(exception));
}
Ok(Some(catch_handler_pc)) => {
// Повторно помещаем исключение в стек и продолжаем
// выполнение метода из обработчика исключений
self.stack.push(Value::Object(exception.0))?;
self.pc = catch_handler_pc;
}
}
}
}
}
}
}Я знаю, что в этом коде довольно много деталей реализации, которые не мешало бы объяснить, но моя цель здесь — дать вам общее представление о том, как с помощью Result и паттерн матчинга в Rust можно описать поведение, представленное выше. Должен признаться, что я очень горжусь этим кодом.
Сборка мусора
Последним этапом работы над rjvm для меня была реализация сборщика мусора. Алгоритмом, который я выбрал для реализации стал stop-the-world (что тривиально следует из отсутствия потоков!) копирующий (semispace) сборщик мусора. Я реализовал простенькую версию алгоритма Чейни, но, если честно, мне стоило бы реализовать что-нибудь посерьезнее...
Идея алгоритма заключается в том, что доступная память разделяется на две части, называемые полу-кучами (semispace): одна (активная) будет использоваться для выделения объектов, а вторая - не будет использоваться. При заполнении первой полу-кучи будет запущена сборка мусора, и все живые объекты будут скопированы во вторую полу-кучу. Затем все ссылки на объекты будут обновлены, чтобы они указывали на новые копии. Наконец, роли двух полу-куч поменяются местами - аналогично тому, как работает "сине-зеленое" развертывание.
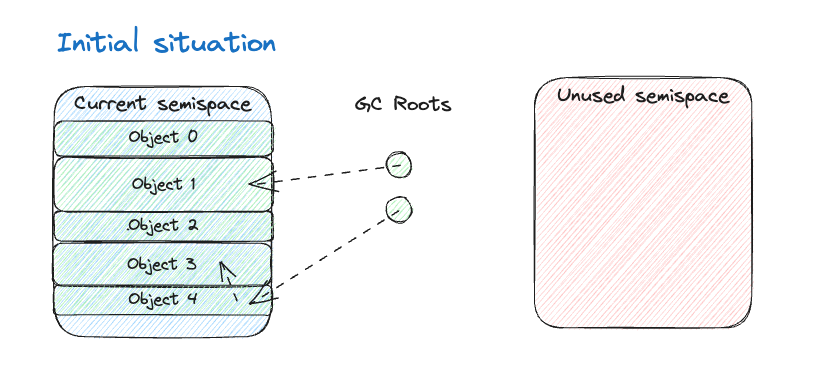



У этого алгоритма есть несколько особенностей:
очевидно, что он тратит много памяти (половину возможной максимальной памяти!);
аллокации происходят очень быстро (pointer bumping);
копирование и уплотнение объектов позволяет обойтись без фрагментации памяти;
уплотнение объектов может улучшить производительность за счет лучшего использования кэша.
В реальных виртуальных машинах Java используются гораздо более сложные алгоритмы, как правило, сборщики мусора на основе поколений, такие как G1 или parallel GC, которые являются эволюциями стратегии копирования.
Заключение
При написании rjvm я многому научился и получил массу удовольствия. Большего от тренировочного проекта и требовать нельзя... но, возможно, в следующий раз, когда я буду изучать новый язык программирования, я выберу что-нибудь менее амбициозное.
В качестве отступления хочу сказать, что мне очень понравилось работать с Rust. Я думаю, что это отличный язык, как я уже писал ранее, и мне очень понравилось использовать его для реализации моей JVM.
С момента выхода первой стабильной версии Rust разработчики ведут холивары на тему наличия в нём возможности организации кода в объектно-ориентированном стиле. 24 августа пройдет бесплатный урок, посвященный теме реализации паттернов проектирования на Rust.
На этом занятии мы постараемся разобраться, как язык стыкуется с ООП парадигмой и попробуем реализовать некоторые паттерны проектирования. Эта встреча будет полезна всем, кто интересуется проектированием и разработкой ПО. Записаться на нее можно на странице курса "Rust Developer. Professional".