

Для создания самодельного CPU требуется большое количество чипов логики. И в самом деле разумно, что для реализации регистров, счётчика команд, АЛУ и других компонентов CPU на логике TTL или CMOS действительно необходимо существенное число чипов. Но сколько конкретно?
Я попытался оптимизировать свой самодельный CPU, минимизировав количество чипов логики, чтобы ответить на вопрос: какое минимальное число интегральных схем требуется для полного по Тьюрингу CPU без CPU?
Мой ответ: для создания 16-битного последовательного CPU нужно всего 8 интегральных схем, включая память и тактовый генератор. Он имеет 128 КБ SRAM, 768 КБ FLASH и его можно разгонять до 10 МГц. Он содержит только 1-битное АЛУ, однако большинство из его 52 команд работает с 16-битными значениями (последовательно). На своей максимальной скорости он исполняет примерно 12 тысяч команд в секунду (0,012 MIPS) и, среди прочего, способен выполнять потоковую передачу видео на ЖК-дисплей на основе PCD8544 (Nokia 5110) с частотой примерно 10 FPS.
Если выбрать подходящую классификацию разделения конечных автоматов и CPU, то моя 16-битная система может считаться CPU с наименьшим количеством интегральных схем. Другими претендентами на это звание могут быть 1-битный компьютер Джеффа Лофтона с 1 командой и 1 битом памяти, а также простой CPU Дэниела Торнбурга с 1 командой byte-byte-jump (копирует 1 байт из одного участка памяти в другой, а затем выполняет безусловный переход) и памятью, симулируемой на Raspberry PI.
▍ Оборудование
Источником вдохновения для создания архитектуры стали другие проекты CPU наподобие JAM-1 Джеймса Шэрмана, SAP-1 Бена Итера, 4-bit Crazy Small CPU Уоррена, его 8-битная версия и другие. Все они и многие другие подобные архитектуры используют «управляющие» EEPROM, EPROM или ROM для генерации управляющих компонентами CPU-сигналов, потому что это намного проще, чем генерировать их только логическими цепями, а также потому, что это обеспечивает гораздо большую гибкость на будущее. Я тоже решил использовать такую «управляющую» память, а конкретно EPROM. В отличие от упомянутых выше проектов я стремился к наименьшему количеству чипов, поэтому попытался «запихнуть» в память как можно больше обработки данных, чтобы снизить требования к другим компонентам CPU или, того лучше, полностью от них избавиться. Предпринятые мной основные шаги были следующими:
- Я полностью избавился от АЛУ и реализовал его как таблицу поиска. Так как большинство EPROM имеет всего лишь 8-битный выход, а системе также нужны другие управляющие сигналы, то разрядность данных АЛУ необходимо было существенно ограничить. Но не нужно волноваться, её можно уменьшить вплоть до одного бита: на самом деле, нам достаточно 1-битных вычислений.
- Чтобы иметь возможность выполнения любых значимых вычислений, результаты работы 1-битного АЛУ должны сериализироваться. Это идеально подходит для использования последовательной SRAM, которая также обеспечивает другие преимущества. Во-первых, она избавляет от необходимости в регистрах, так как все операции с АЛУ могут выполняться напрямую с данными в SRAM. Во-вторых, последовательные SRAM также имеют последовательную адресацию, поэтому нам не нужно защёлкивать исходный и конечный адреса. В-третьих, произвольную разрядность обработки данных можно получить простым выбором периода повторения тактовых импульсов SRAM. Я выбрал 16 битов (16 периодов повторения тактовых импульсов SRAM на 1 операцию АЛУ) как приемлемый компромисс между удобством и скоростью.
- Требуется как минимум два чипа последовательной SRAM, один из них должен предоставить сериализованный вход для нашего 1-битного АЛУ, а второй в то же время должен сохранять результат.
- Для операций АЛУ с двумя операндами (например, ADD/AND/XOR...) необходимы два сериализованных входа. Разумеется, можно добавить и третью SRAM (2 для входов АЛУ, 1 для результата), но есть решение получше. Если вместо SRAM использовать последовательную память FLASH, то преимущества сохранятся (уже сериализованные данные, сериализованный адрес), но FLASH можно использовать для хранения команд/программы, а также для обеспечения ввода АЛУ.
- Необязательно добавлять оборудование для счётчика команд, потому что в SRAM и так уже есть достаточно места для хранения его значения.
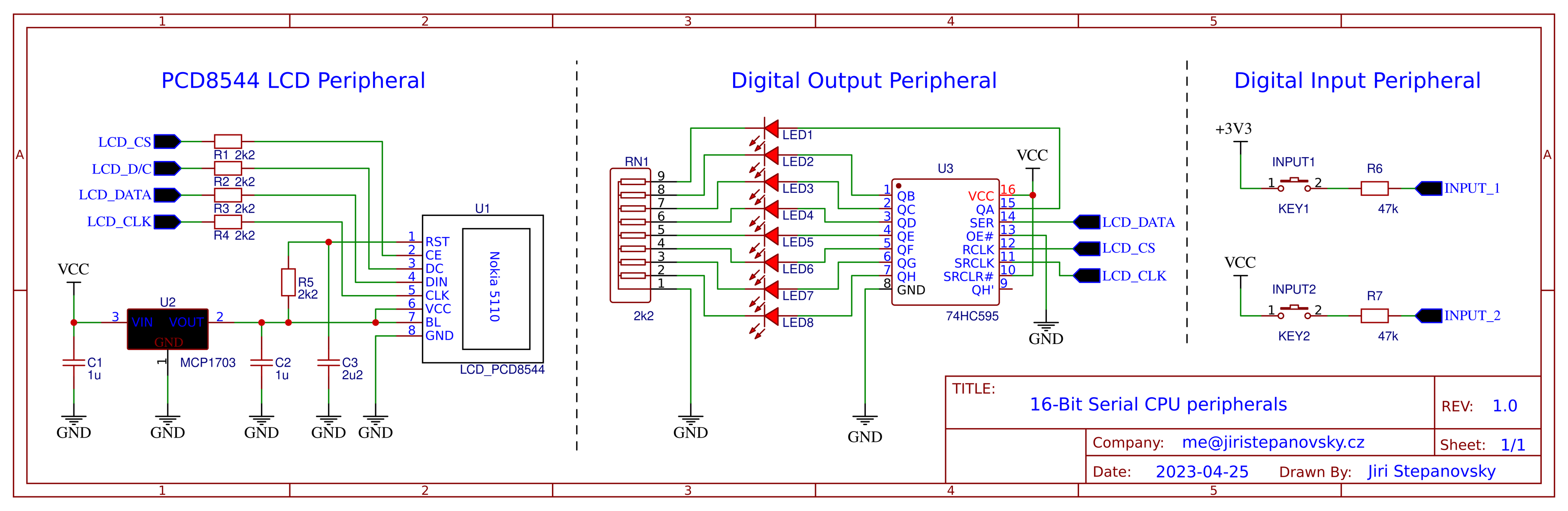
Но даже при таких существенных упрощениях всё равно требуется дополнительное оборудование. Однако всё можно собрать всего на 8 чипах в соответствии с показанной ниже схемой:

Схема построена на основе 128-килобитной EPROM M27C1001-15, работающей на 5 В, которая сочетает конечный автомат управления с 1-битным АЛУ. Её выходные линии защёлкиваются 74HC574 каждый период повторения тактовых импульсов и управляют двумя последовательными SRAM 23LCV512 на 64 КБ и одной последовательной FLASH W25Q80 на 1 МБ. Выходов недостаточно для управления каждой памятью по отдельности, поэтому они имеют общую шину данных, а также частично линию выбора чипа. Разделёнными остаются только линии синхронизирующих импульсов. Я не смог найти последовательную память FLASH на 5 В, поэтому резисторы R3, R4 и R5 ограничивают ток и образуют мост с 5 В на 3,3 В. Я не считаю регулятор напряжения MCP1703 на 3,3 В частью CPU (я учёл его, но только как часть источника питания), но если учитывать его, то CPU содержит 9 чипов.
Текущая команда хранится в буферизированном регистре сдвига 74HC595, линии управления которого также частично являются общими с чипами памяти. На выполнение каждой команды необходима пара тактов, так что прогресс выполнения команды отслеживается счётчиком «микрокода» 74HC393. После завершения команды линия «Counter_reset» выполняет сброс счётчика «микрокода» и начинает исполнение следующей команды, буферизированной в 74HC595.
74HC574 и счётчик «микрокода» 74HC393 используют противоположные фронты синхроимпульса, поэтому тактовый генератор 74HC14 передаёт на 74HC393 инвертированный сигнал синхронизации, чтобы они были синхронизованы.

▍ Входы и выходы
Чего я не смог реализовать в своём CPU разумно — так это самопрограммирование памяти FLASH. Следовательно, bootloader невозможен, а загрузку новой программы в последовательную FLASH необходимо выполнять снаружи. Для этого я использовал микроконтроллер Attiny13, прослушивающий по UART последовательность команд, поэтому для загрузки нового кода достаточно любого адаптера USB-UART. При программировании он отключает выход 74HC574 через линию «Prog_en» и начинает напрямую программировать память FLASH. Микроконтроллер используется только для загрузки новой программы, и CPU замечательно работает без него.
Единственные доступные выходы — это два верхних бита регистра сдвига команд 74HC595. Я использовал одну из этих инвертированных линий для выбора чипа, что позволило CPU подключаться к устройствам наподобие SPI. Например, к нему можно напрямую подключить ЖК-дисплей SPI на основе PCD8544 напряжением 3,3 В (Nokia 5110), а второй старший бит команд используется как селектор данных/команд ЖК-дисплея. Также можно вместо ЖК-дисплея подключить дополнительный регистр сдвига 74HC595, чтобы получить классические линии цифрового вывода.
Единственные доступные входы — это два сигнала данных/входа памяти, подключённые к адресным шинам EPROM (A9, A11). Чипы последовательной памяти удерживают высокий импеданс этих сигналов, когда они не используются, чтобы их можно было сэмплировать как общие цифровые входы, когда чипы памяти находятся в состоянии простоя. Важно отметить, что входной сигнал не должен создавать помехи данным памяти, поэтому требуется высокое сопротивление между входным сигналом и входной шиной памяти (R6, R7). Примечание: чтение входного сигнала на шинах данных памяти работает только для тактовых частот до примерно 8 МГц. При более высоких частотах сэмплируемые данные становятся ошибочными и работа CPU может приостановиться.
Выше уже было видео о том, как мой CPU воспроизводит музыкальное видео «Bad Apple!!» на ЖК-дисплее PCD8544. В видео ниже я покажу возможность управления общими цифровыми выходами после добавления ещё одного 74HC595. Ту же схему можно использовать для создания 8-битной музыки с частотой до 4300 сэмплов/с, если вместо светодиодов бы использовалась резисторная матрица R-2R, и именно эту схему я использовал для создания саундтрека к видео «Bad Apple!!».
▍ Таблица распределения памяти
У CPU нет отдельных регистров, но есть две SRAM, из которых можно выполнять чтение и запись. Недостаток заключается в том, что каждый раз, когда CPU хочет получить доступ к данным, он должен выполнить запись в полный 16-битный адрес последовательной SRAM. Плюс заключается в том, что поскольку ему всё равно нужно записывать полный 16-битный адрес, CPU (и команды в целом) может иметь доступ ко всем 64 КБ SRAM с постоянным временем.
Я выбрал одну SRAM (U8/RAM1) для хранения данных программ, а все арифметические и логические операции должны выполняться со значениями внутри этой памяти. Вторая SRAM (U7/RAM2) должна использоваться для стека, поэтому считывать и изменять её содержимое могут лишь некоторые команды. Первые несколько байтов обоих чипов памяти зарезервированы под хранение внутреннего состояния CPU (счётчика команд, бита флага, указателя стека, промежуточного результата, исходного/конечного адресов и других используемых внутри значений). Приблизительная таблица распределения памяти:
| Адрес: | 0x0 | 0x1 | 0x2 | 0x3 | 0x4 | 0x5 | 0x6 | 0x7 | 0x8 | 0x9 | 0xA | 0xB | 0xC | 0xD | 0x000E~0xFFFF |
| RAM1: | Флаг и ввод | Счётчик команд (PC) | Обратный счётчик команд | Указатель стека (SP) | Значение стека (SPVAL) | Регистры и пользовательские данные | |||||||||
| RAM2: | Flag | Счётчик команд (PC) | Конечный адрес | Результат команды | Стек и пользовательские данные | ||||||||||
Стоит также упомянуть о способе использования памяти FLASH в качестве второго входа АЛУ. Так как FLASH довольно велика (1 МБ), внутрь неё можно поместить полную 16-битную таблицу поиска, содержащую идентичные 16-битные значения. Имея эту таблицу поиска на 128 КБ, можно записывать 16-битное значение в FLASH как адрес и считывать те же 16-битные значения как данные, чтобы использовать их как вход АЛУ.
Небольшое неудобство в использовании последовательных чипов памяти заключается в том, что их адресация происходит в формате MSB-first, а 1-битное АЛУ выполняет вычисления в формате LSB-first. Чтобы адресация памяти работала, нам нужно обратить биты из формата LSB-first, с которым работает CPU, в формат MSB-first, с которым работают чипы памяти. Обращение битов при помощи 1-битного АЛУ — не такая простая задача, поэтому я зарезервировал ещё 128 КБ памяти FLASH под таблицу поиска «обращённых значений», чтобы ускорить операцию. Всё работает так же, как и предыдущая таблица — значение записывается в память FLASH как адрес, и в обращённом виде считывается как данные.
Именно из-за этих таблиц поиска у моего CPU всего 768 КБ памяти FLASH, а счётчик команд (PC) начинается с адреса 0x040000, а не с нуля.
▍ Набор команд
Из-за слабого оборудования набор команд имеет определённые ограничения. CPU способен выполнять только 64 уникальных команд/операций, каждая из которых должна уместиться в 256 этапов микрокоманд и должна исполняться при помощи только 1-битного АЛУ и 1 бита флага. Но даже при наличии этих ограничений, как ни удивительно, можно создать вполне удобный набор команд:
| Опкод | Имя | Операнды | Разрядность | Флаг | Такты | Всего | Описание |
| 0x00 | INIT | - | - | сброс | 256 | 256 | Ожидание стабилизации синхросигнала, затем инициализация интегральных схем ОЗУ в последовательном режиме |
| 0x01 | RESET | - | - | сброс | 235 | 235 | Установка счётчика команд PC = 0x040000 и указателя стека SP = 0x000A |
| 0x02 | - | - | - | - | 158 | 414 | Теневая команда: получение |
| 0x03 | - | - | - | - | 256 | 414 | Теневая команда: продолжение получения |
| 0x04 | - | - | - | - | 129 | 129 | Теневая команда: инкремент счётчика команд PC = PC + 3 |
| 0x05 | - | - | - | - | 129 | 129 | Теневая команда: инкремент счётчика команд PC = PC + 5 |
| 0x06 | - | - | - | - | 129 | 129 | Теневая команда: инкремент счётчика команд PC = PC + 7 |
| 0x07 | - | - | - | - | 129 | 129 | Теневая команда: инкремент счётчика команд PC = PC + 8 |
| 0x08 | - | - | - | - | 162 | 291 | Теневая команда: копирование 32-битного результата |
| 0x09 | - | - | - | - | 130 | 259 | Теневая команда: копирование 16-битного результата |
| 0x0A | - | - | - | - | 113 | 113 | Теневая команда: копирование счётчика команд |
| 0x0B | - | - | - | - | 167 | 296 | Теневая команда: сохранение в ОЗУ косвенное |
| 0x0C | - | - | - | - | 151 | 280 | Теневая команда: сохранение в ОЗУ косвенное |
| 0x0D | - | - | - | - | 173 | 587 | Теневая команда: отправка арифметической команды |
| 0x0E | STF | - | - | установка | 132 | 546 | Установка FLAG |
| 0x0F | CLF | - | - | сброс | 132 | 546 | Сброс FLAG |
| 0x10 | NOP | - | - | - | 132 | 546 | Нет операции |
| 0x11 | MOV | addr16 <- addr16 | 16 | - | 231 | 774 | Передача 16-битного значения |
| 0x12 | MOVW | addr16 <- addr16 | 32 | - | 146 | 851 | Передача 32-битного значения |
| 0x13 | INC | addr16 <- addr16 | 16 | переполнение | 231 | 774 | Инкремент |
| 0x14 | DEC | addr16 <- addr16 | 16 | переполнение | 231 | 774 | Декремент |
| 0x15 | COM | addr16 <- addr16 | 16 | ноль | 231 | 774 | Обратный код (NOT) |
| 0x16 | NEG | addr16 <- addr16 | 16 | ноль | 231 | 774 | Дополнительный код |
| 0x17 | LSL | addr16 <- addr16 | 16 | переполнение | 233 | 776 | Сдвиг влево (<<) |
| 0x18 | LSR | addr16 <- addr16 | 16 | переполнение | 233 | 776 | Сдвиг вправо (>>) |
| 0x19 | ROL | addr16 <- addr16 | 16 | переполнение | 233 | 776 | Сдвиг влево с переносом |
| 0x1A | ROR | addr16 <- addr16 | 16 | переполнение | 255 | 798 | Сдвиг вправо с переносом |
| 0x1B | ASR | addr16 <- addr16 | 16 | переполнение | 235 | 778 | Арифметический сдвиг вправо (с сохранением бита знака) |
| 0x1C | REV | addr16 <- addr16 | 16 | - | 238 | 781 | Инвертирование бита |
| 0x1D | ADDI | addr16 <- addr16, val16 | 16 | переполнение | 231 | 774 | Непосредственное сложение |
| 0x1E | ADCI | addr16 <- addr16, val16 | 16 | переполнение | 231 | 774 | Непосредственное сложение с переносом |
| 0x1F | SUBI | addr16 <- addr16, val16 | 16 | переполнение | 231 | 774 | Непосредственное вычитание |
| 0x20 | SBCI | addr16 <- addr16, val16 | 16 | переполнение | 231 | 774 | Непосредственное вычитание с переносом |
| 0x21 | ANDI | addr16 <- addr16, val16 | 16 | ноль | 231 | 774 | Логическое AND с непосредственным значением |
| 0x22 | ORI | addr16 <- addr16, val16 | 16 | ноль | 231 | 774 | Логическое OR с непосредственным значением |
| 0x23 | XORI | addr16 <- addr16, val16 | 16 | ноль | 231 | 774 | Логическое XOR с непосредственным значением |
| 0x24 | ADD | addr16 <- addr16, addr16 | 16 | переполнение | 171 | 887 | Прибавление регистра |
| 0x25 | ADC | addr16 <- addr16, addr16 | 16 | переполнение | 171 | 887 | Прибавление регистра с переносом |
| 0x26 | SUB | addr16 <- addr16, addr16 | 16 | переполнение | 171 | 887 | Вычитание регистра |
| 0x27 | SBC | addr16 <- addr16, addr16 | 16 | переполнение | 171 | 887 | Вычитание регистра с переносом |
| 0x28 | AND | addr16 <- addr16, addr16 | 16 | ноль | 171 | 887 | Логическое AND с регистром |
| 0x29 | OR | addr16 <- addr16, addr16 | 16 | ноль | 171 | 887 | Логическое OR с регистром |
| 0x2A | XOR | addr16 <- addr16, addr16 | 16 | ноль | 171 | 887 | Логическое XOR с регистром |
| 0x2B | JMP | addr24 | - | - | 197 | 611 | Переход к адресу |
| 0x2C | CALL | addr24 | 32 | - | 221 | 748 | Копирование адреса следующей команды (PC + 4) и текущего FLAG в SPVAL, затем переход |
| 0x2D | RET | - | 32 | восстановление | 138 | 552 | Передача SPVAL в PC и FLAG (по сути, выполняет возврат из CALL и восстанавливает предыдущий FLAG) |
| 0x2E | BRFS | addr24 | - | - | 160 | 625|574 | Ветвление, если FLAG установлен |
| 0x2F | BRFC | addr24 | - | - | 160 | 625|574 | Ветвление, если FLAG сброшен |
| 0x30 | BREQ | addr16, addr24 | 16 | - | 243 | 708|657 | Ветвление, если регистр равен нулю |
| 0x31 | BRNE | addr16, addr24 | 16 | - | 243 | 708|657 | Ветвление, если регистр не равен нулю |
| 0x32 | LDI | addr16 <- value16 | 16 | - | 81 | 624 | Загрузка 16-битного непосредственного значения |
| 0x33 | LDIW | addr16 <- value32 | 32 | - | 113 | 656 | Загрузка 32-битного непосредственного значения |
| 0x34 | LD | addr16 <- [addr16] | 16 | - | 238 | 911 | Косвенная загрузка 16 битов из адреса |
| 0x35 | LDB | addr16 <- [addr16] | 8 | - | 238 | 911 | Косвенная загрузка 8 битов из адреса, верхним 8 битам присваивается 0 |
| 0x36 | ST | [addr16] <- addr16 | 16 | - | 163 | 873 | Косвенное сохранение 16 битов по адресу |
| 0x37 | STB | [addr16] <- addr16 | 8 | - | 163 | 857 | Косвенное сохранение 8 битов по адресу |
| 0x38 | LD2W | [addr16] | 32 | - | 256 | 799 | Косвенная загрузка 32 битов из адреса в RAM2 в регистр SPVAL |
| 0x39 | LD2 | [addr16] | 16 | - | 224 | 767 | Косвенная загрузка 16 битов из адреса в RAM2 в регистр SPVAL |
| 0x3A | ST2W | [addr16] | 32 | - | 256 | 799 | Косвенное сохранение 32 битов из регистра SPVAL в адрес RAM2 |
| 0x3B | ST2 | [addr16] | 16 | - | 224 | 767 | Косвенное сохранение 16 битов из регистра SPVAL в адрес RAM2 |
| 0x3C | LPM | addr16 <- [addr16] | 16 | - | 211 | 884 | Косвенная загрузка 16 битов из адреса FLASH |
| 0x3D | LPB | addr16 <- [addr16] | 8 | - | 211 | 884 | Косвенная загрузка 8 битов из адреса FLASH, верхним 8 битам присваивается 0 |
| 0x3E | OUT | addr16 | 8 | - | 252 | 795 | Вывод 8 битов по SPI |
| 0x3F | HALT | - | - | clear | 14 | 428 | Остановка исполнения |
Первые команды (INIT и RESET) исполняются при включении питания или при нажатии кнопки RESET. «Теневые» команды недоступны для пользователя и в основном используются для повторяющихся операций, например, получения команды, инкремента счётчика команд, записи обратно результата и так далее.
Арифметические и логические операции используют один бит флага как флаг переноса/переполнения, или как флаг нуля. Как говорилось выше, при доступе к полному пространству адресов скорость не снижается, так что во всех этих командах можно указывают любой исходный/конечный адрес в пределах пространства адресов SRAM (64 КБ). Косвенная адресация для арифметических операций не поддерживается напрямую, а должна выполняться командами LD/ST (загрузки/сохранения).
Второй набор команд LD2/ST2 получает доступ ко второй SRAM. Она должна использоваться для стека, но в ней могут храниться любые данные. Команды PUSH м POP не реализованы, но их можно собрать из команд LD2/ST2 и INC/DEC.
В среднем исполнение команды занимает примерно 800 тактов с учётом операции получения и с инкрементом счётчика команд. При максимальной тактовой частоте (10 МГц) CPU может исполнять примерно 12 тысяч команд в секунду.
▍ Код на ассемблере
Для генерации двоичных файлов из исходного ассемблерного кода я использую customasm Лоренци. Двоичные файлы можно загружать при помощи небольшого приложения на python3 в программирующий микроконтроллер Attiny13, который записывает двоичный файл во FLASH.
Ниже приведены два примера небольших процедур, написанных на ассемблере для моего CPU. Первая процедура возвращает 32-битный результат перемножения двух 16-битных значений. Вторая выводит на ЖК-дисплей ascii-строку, хранящуюся внутри памяти FLASH.
| Multiply32_16x16 | LCD_WriteStrF |
; Возвращает FA32 = FA16 * FB16
; Ожидается, что FB - меньшее из чисел
Multiply32_16x16:
;PUSH_PC ; Необязательно
LDIW FC, 0 ; Сброс результата
LDI FA+2, 0 ; Преобразование FA16 в FA32
.loop:
ANDI TMP, FB, 1
BRFS .skip_add
ADD FC, FA ; Сложение FC32 += FA32
ADC FC+2, FA+2 ; Сложение FC32 += FA32
.skip_add:
LSL FA ; Сдвиг FA32 << 1
ROL FA+2 ; Сдвиг FA32 << 1
LSR FB ; Сдвиг FB16 >> 1
BRNE FB, .loop
MOVW FA, FC ; Копируем результат
;POP_PC ; Необязательно
RET
|
; Записываем строку во Flash
; input: FA32 <- Адрес строки во Flash
LCD_WriteStrF:
PUSH_PC ; Сохраняем адрес возврата
PUSHW RA ; Сохраняем RA 32 бит
MOVW RA, FA
.loop:
LPB FA, RA ; Загружаем символ из Flash
BREQ FA, .stop ; Проверяем символ "\0"
REV FA ; MSB-first -> LSB-first
ANDI FA, FA+1, 0xFF ; Преобразование в 8 бит
CALL LCD_WriteChar ; Записываем символ
ADDI RA, 1 ; Увеличиваем 32-битный указатель
ADCI RA+2, 0 ; Увеличиваем 32-битный указатель
JMP .loop
.stop:
POPW RA ; Восстанавливаем RA 32 бит
POP_PC ; Восстанавливаем адрес возврата
RET |
▍ Максимальная частота и критический путь
Согласно спецификациям, суммарная задержка распространения по критическому пути равна:
- 12 нс в 74HC14 от «Clock_pos» до «Clock_neg»,
- 54 нс в 74HC393 на пульсацию до последнего 8-го бита (12+3x5+12+3x5 нс),
- Время доступа 150 нс к EPROM M27C1001-15,
- 2 нс в 74HC574 на стабилизацию входов до фронта синхроимпульса.
Если соединить всё вместе, то можно прийти к выводу, что схема должна работать только на частоте примерно 4,6 МГц. Однако конкретно моя сборка может без проблем работать на частотах до 10 МГц и становиться нестабильной только при частотах выше примерно 10,5 МГц. Я считаю, что это довольно впечатляющий результат для схемы на макетной плате со множеством паразитных ёмкостей. Максимальную тактовую частоту можно даже увеличить, если использовать более быстрый двоичный счётчик или EPROM.
▍ Заключение и ретроспектива
Я очень доволен получившимся CPU. Он имеет удобный и простой в работе набор команд со всеми базовыми командами. Он достаточно мощный, чтобы передавать видео на небольшой ЖК-дисплей, воспроизводить аудио (благодаря использованию внешней «звуковой карты»), и в целом выполняет простые вычислительные операции ввода-вывода, для которых и предназначался. В конечном итоге, он успешно демонстрирует, что на небольшом количестве интегральных схем можно изготовить функциональный самодельный CPU.
Однако в него можно внести и небольшие улучшения:
- Счётчик числа колебаний 74HC393 — существенное узкое место на критическом пути. Замена его быстродействующим сумматором (carry-lookahead adder) или счётчиком с буферизацией наподобие 74HC590 увеличит максимальную тактовую частоту.
- То же самое относится к EPROM M27C1001-15. Использование более быстрой памяти, например, EPROM M27C1001-35 или FLASH SST39SF020A-70 тоже позволит увеличить тактовую частоту.
- Более крупная EPROM с более чем семнадцатью шинами адреса может использоваться или для увеличения количества команд, или для применения дополнительных шин адреса в качестве цифровых входов общего назначения.
- Добавление команд для стирания и программирования внутренней памяти FLASH позволило бы создать bootloader, а значить, и избавиться от схемы программирования на Attiny13.
- Система может исполнять код только из памяти FLASH. Можно создать эмулятор внутри FLASH, чтобы он исполнял код из SRAM, но чтобы CPU мог исполнять код из SRAM нативно, потребовался бы другой процесс получения команд, возможно, с использованием дублирующего набора команд для самого исполнения в SRAM.
Мне придётся подумать, стоит ли реализовывать эти улучшения. Если вам понравился проект и вы хотите изучить его глубже, то просмотрите исходный код, выложенный здесь. Он содержит симулятор, генератор микрокода EPROM, прошивку Attiny13 для программирования и весь мой ассемблерный код.
▍ Дополнение 1
Я реализовал минималистичный движок проецирования каркасных 3D-объектов с использованием 16-битной арифметики с фиксированной запятой. Умножение матриц на моём CPU мощностью 0,012 MIPS выполняется довольно медленно, поэтому вряд ли в ближайшее время стоит ожидать 3D-игр:
Также я постепенно расширяю список оборудования, напрямую поддерживаемого моим CPU. Я добавил алфавитно-цифровой ЖК-дисплей SPI, извлечённый из старого принтера HP:

И мне удалось выполнить bit-banging последовательного интерфейса таймера реального времени DS1302. Для создания необходимых сигналов программному обеспечению требуется использовать особые последовательности команд, но это возможно и не требует дополнительного оборудования.

▍ Дополнение 2
Теперь CPU поддерживает драйвер LCD PCF8833, хотя для рендеринга одного кадра требуется примерно 96 секунд.

▍ Веб-кольцо самодельных CPU
Рекомендую вам изучить другие потрясающие архитектуры CPU от Уоррена.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх ????️

Комментарии (48)

redsh0927
30.08.2023 14:42+4чтобы ответить на вопрос: какое минимальное число интегральных схем требуется для полного по Тьюрингу CPU без CPU?
Мне кажется что при такой постановке вопроса просто запихать логику в ПЗУ большого объёма с минимальной обвязкой, это как-то не очень спортивно. Тогда уж можно ПЛИС взять, тоже будет "без CPU".
А так красиво получилось, особенно понравилось что все чипы ходовые и есть в каждом радиомагазине, что весьма нетипично для самодельных цпу

YDR
30.08.2023 14:42в любом случае LUTы где-то надо хранить. Не до логики же их разбивать. PLD или ROM - вполне нормальный выход.

Dremkin
30.08.2023 14:42-3Очень круто, но и очень жалко время автора на это :)

dlinyj
30.08.2023 14:42+4но и очень жалко время автора на это :)
Вы же тратите время на чтения статей, и написание этого комментария. При этом, в сути роста личного не происходит. А этот проект повышает автора как специалиста. Уж лучше так тратить своё время, чем на чтение всяких статеек и просмотра сериалов.
Dremkin
30.08.2023 14:42-3Я Хабр просматриваю раз в 3 недели, трачу на это 10 минут, черпаю иногда очень интересное для работы, так что время на "чтение всяких статеек" окупается в степени :) Сериалы, кстати, не смотрю. И водку не пью (сообщаю, ибо предвкушаю ваш следующий аргумент :)

sim2q
30.08.2023 14:42Очень круто!
ps проситься запилить в место FLASH -> SRAM, а может и DRAM, загрузчик получается сложнее всей этой штуки

CBET_TbMbI
30.08.2023 14:42+1С оодной стороны круто, с другой стороны мне тееперь интересно, можно ли собрать что-то подобное используя одни диоды, транзисторы и прочие подобные элементарные детали.
Калькулятор, кажется, возможно. А вот что-то более сложное...
shiru8bit
30.08.2023 14:42+5Конечно можно. В 60-х годах это было второе поколение ЭВМ - на отдельных транзисторах. В СССР это были машины БЭСМ-6, М-220, и многие другие. А сейчас подобные конструкции делают энтузиасты, есть много проектов компьютеров на транзисторах, лампах, реле.

MiraclePtr
30.08.2023 14:42Конечно можно. Всё это - логические элементы, триггеры, сдвиговые регистры, счетчики - они строятся как раз из "транзисторов и диодов". Разве что с флеш-памятью и SRAM будет чуть-чуть сложнее...





Ivoylov
30.08.2023 14:42+4Теперь по классике осталось на нём Doom запустить и вообще красота)))))) Автору респект!
dlinyj
30.08.2023 14:42Идея интересная, я много думал о возможности использования ПЗУ как ПЛИС. И вот тут реализация. Хотя, конечно у автора некоторое мошенничество, потому что можно так процессор на одной микросхеме ПЛИС сделать. С другой стороны, интересен сам по себе, как можно нестандартно использовать микросхемы.

MaFrance351
30.08.2023 14:42+1Видел, как во всяких полукустарных контроллерах на шину ISA делали дешифраторы адреса на одной РТшке вместо нескольких чипов логики. Так что да, работоспособно.

DarkTiger
30.08.2023 14:42Насколько помню статью из журнала «Радио», года так 87, РТ программировалась правильно в 70%, остальное - брак. У меня, правда, нормально тогда прошилась.
Ну и стоила она сильно дороже нескольких чипов мелкой логики, если говорить про именно отечественные. Так что для опкодов процессора она хороша, а для дешифратора - так себе. Особенно с учетом того, что полная адресная дешифрация на ISA не так часто бывала нужна.
MaFrance351
30.08.2023 14:42Думаю, это издержки тех времён, когда собирали из того, что удалось намутить в больших количествах.
А так — реально использовали, вот, к примеру:
http://imlab.narod.ru/Electron/ISA/ISA.htmДля программирования микросхемы ПЗУ может быть использован аппаратный программатор [2]. Для вышеуказанного распределения адресов каналов все ячейки микросхемы ПЗУ, кроме ячейки с адресом C0H, программируются в логическую единицу. Для ячейки с адресом C0H (11000000 в двоичной системе счисления) биты данных D1 — D3 программируются в логическую единицу, значение бита D0 должно остаться равным логическому нулю.
dlinyj
30.08.2023 14:42За РТ не скажу, но вот РФ5 мне прошить так и не удалось https://habr.com/ru/companies/ruvds/articles/648649/.

forthuse
30.08.2023 14:42+1Автор проекта, вроде, кроме опубликованной статьи не разместил полные данные о сделанной разработке, но не суть для возможности осмысления для себя.
DarkTiger
30.08.2023 14:42-1Описанное в статье - вполне себе стандартная вещь для студентов Бауманки на ИУ5. Курсовая, 3 семестр, 5 курс.
Задумка отличная, а вот требования к реализации от преподавателя - очень, мягко говоря, странные, можно это сделать на современном софте (тот же Xilinx ISE) в 10 раз быстрее, при этом не теряя в качестве обучения, а наоборот, изучая по пути реальную разработку. За счет сэкономленного времени можно было и верификацию подтянуть. Но преподаватель застрял в 1988...
NutsUnderline
30.08.2023 14:42+2Jiri Stepanovsky вряд ли учился там
Понять КАК это работает на примере К155ИР13 гораздо проще, чем на ПЛИС - нет отвлечения на специфику.DarkTiger
30.08.2023 14:42При чем тут плис? Я про синтез логических схем. Все равно, куда раскладывать полученную логику и opcodes - в свой ip block “ir13” и память плис или в реальные мелкосхемы. В первом случае - практически неограниченные возможности симулятора для анализа, параметризации и тестирования функционала. Во втором - ну, воткнул чипы и провода в breadboard и чего? Девушкам и друзьям показывать? Или цель была все-таки прокачать собственные мозги?
Да и никто не мешает по отлаженному проекту в ISE собрать железку на breadboard. А если сразу на борде собирать - там куча ошибок будет, очень трудно диагностируемых
NutsUnderline
30.08.2023 14:42+2Ну положим.. в учебном процессе это обязательно выльется в изучение пользованием конкретной программой с большим отдалением от физической реальности . А потом вообще окажется что и в популярном случае: "Мы только Word 1997 умеем, а Word 2011 не понимаем, какой такой OpenOffice".
В breadboard можно в любую точку ткнуться осциллографом (физическим, не виртуальным) , и да где то поломать мозги потому что "опыт - сын ошибок трудных". А вот потом уже можно и сравнить все это с ISE. Причем - заниматься только этим, а не получать "широкое и разностороннее"
Показывать же это друзиаям, а тем паче девушкам (c других курсов) - вообще идея странная :)
PS щас уже не помню, вроде в MIT были лабораторки типа создания своей ОС и синтеза проца на ПЛИС
forthuse
30.08.2023 14:42Курсовая, 3 семестр, 5 курс.
Но преподаватель застрял в 1988...Да, поздновато эту курсовую дают по материалу нормально проходимому на 2-3 -ьем курсе по цифровой электронике. :)
P.S. Недорабатывает наше Министерство Высшего Образования и/или не корректирует и не принимает/утверждает учебные программы отдельных Вузов спуская это на самотёк в управлениии и принятии решений на местный электорат Вузов.

AAnarbaev
30.08.2023 14:42+2Интересная реализация. Автору успехов, не слушайте "душных" коллег, любой практический опыт и идея доведенная до конца полезен.

Soukhinov
30.08.2023 14:42Я правильно понимаю, что такую архитектуру в советской литературе именовали «микропрограммным автоматом»?
И мне удалось выполнить bit-banging последовательного интерфейса таймера реального времени DS1302.
И ещё вопрос немного не в тему: когда уже, наконец, микроконтроллеры станут настолько быстрыми, что при помощи bit-banging смогут подключаться к WiFi? (Отправлять сигнал переключением ноги, а принимать чтением ноги при помощи встроенного АЦП).
NutsUnderline
30.08.2023 14:42Да они как бы стали, но в случае WiFI практически нет этапа где есть именно битовый поток. Упомянутое Software Defined Radio (SDR) использует т.н. IQ stream с АЦП который обрабатывают либо специализированные ПЛИС, либо софт написанный на каком нибуть python, который требует уже Core I7 для работы. Таким образом можно например поднять свою соту GSM/4G/LTE, делать всяко с GPS и т.д.
В случае WiFi проще воспользоваться микросхемой с аппаратной обработкой всего этого -WiFi адаптер с расширенным доступом, оперируя более высокоуровневыми структурами данных, там и так обработки полно, но в общем то это работает
Tuvok
Навтыкать готовые микросхемы в бредбоард это проектирование? По заголовку предполагалось что это будет схемотехника ЦП чтобы потом описать технологию изготовления в один кристалл на подложке, а тут ардуиноподобие.
nochkin
Почти всегда проектирование использует уже какие-то готовые компоненты и наработки. Не начинать же проектирование с добычи кремния?
"Просто навтыкать" -- это когда по чужой готовой схеме просто повторяют чей-то проект.
Tuvok
Начинать со схемотехники, в этом же суть проектирования?
MaFrance351
Так схемотехника этого устройства им же и была придумана, не?
YDR
да, считаю, что вполне проектирование. Минималистичный процессор из логики и ПЗУшки. Очень познавательно, и подойдет для курса по FPGA.
А вот если еще компилятор С сделает, и MMU, и памяти побольше, то можно будет и Linux запустить :-)
MiraclePtr
Можно даже без этого, см. CONFIG_MMU=no + uClibc
forthuse
Идейно похожему данному проекту процессора публиковалась статья на Хабр. :)
(если кто пропустил)
My4TH — домашний компьютер без процессора
P.S. Микросхем, правда, немного поболее, но также используется одно битное АЛУ и тоже задействованы микросхемы последовательной флэш памяти.
forthuse
На FPGA подобный проект запустится на высокой тактовой частоте.
Как пример:
Бит-последовательный процессор описанный в VHDL, с симулятором на Си.
(до 123МГц на Spartan-6 при использовании Xilinx ISE 14.7)
checkpoint
Вы либо не прочитали статью, либо совершенно не поняли всей сути. Ардуинами здесь даже близко не пахнет (разве что как средство прошивки ППЗУ).
В двух словах. Автор предлагает однобитный процессор, который оперируя однобитовыми операциями эмулирует многобитовые (16 битные) операции за счет большого числа циклов и таким образом реализуются все 52 команды этого процессора. Но это еще не все. Автор использует последовательное ОЗУ для размещения регистров - это сильно напоминают Машину Тьюринга.
NutsUnderline
Даже слово "самодельный" в заголовке совсем не смутило? Есть конечно уникумы которые могут и до кристалла дойти (вроде бы были тут такие статьи), но если бы это все было так легко и просто...
Tuvok
Он не самодельный, он самосборный.
Вот так выглядит проектирование (правда тут ближе к технологии) https://habr.com/ru/articles/553356/
А так самоделание: https://www.ixbt.com/news/2021/08/15/kak-sozdat-mikroprocessor-v-domashnih-uslovijah-jentuziast-sozdal-integralnuju-shemu-s-1200-tranzistorami-u-sebja-v.html?ysclid=llz2fb8uwz340061333
А это, вы меня не переубедите, это сборка из готовых компонентов.
По вашей логике тогда программирование ПЛИС это тоже самодельный процессор, но на самом деле нет.
И вот ещё проектирование со схемотехникой: https://kit-e.ru/mikroproczessor-svoimi-rukami-chast-1-1/?ysclid=llz2fetdok499986286
Автор просто взял и путём отсечения лишнего выяснил что нужно для минимальной обвязки готового компонента. Ну ок, собрал материнку, но не спроектировал процессор. Название статьи поменять, хотя бы в слове "проектирование", тогда соглашусь.
NutsUnderline
Отличный набор ссылок, думаю если бы это был изначальный пост то он был бы воспринят более позитивно ;) вопрос в глубине проработки, там ведь люди тоже какое-никакое оборудование использовали. тут схемотехника есть, пусть и уровня готовых микросхем, архитектуру тоже спроектировал .. кто то, сделано коленке. Понятие самодельный - довольно широкое, на самом деле.
ПЛИС вообще не обязательно реализует процессор, и как по мне, VHDL это не совсем программирование, а описание цепочки сигналов, которое как ни крути, проектируют.
Сасмосборный вроде как подразумевает сборку по готовому проекту, например мебель из Икеи
forthuse
Есть повод подумать над возможным применением такого процессора в каких то масс-изделиях при тиражировании его в кремнии.
(таже флэш память в этом проекте не работает на максимальной возможной частоте от 100МГц, а использованная SRAM на 20МГц)
P.S. К примеру, как один из вариантов — использовать для обновления ценников в магазине с шильдиками на электронных чернилах. :)
...
YDR
нет, не надо сюда практическое применение прикручивать (для ценников есть гораздо более подходящие контроллеры). Это - концепт. Просто показать, что так можно, и рассказать, как конкретно можно.