

Как-то, на просторах бескрайнего, наткнулся на любопытную задачу, которая, к тому же,
довольно просто решается.
Дальнейший текст, будет полезен для начинающих практиков, у кого есть, хоть какая-то база в написании SQL запросов. Для ушлых сеньоров, все что будет сказано ниже, может показаться слишком просто, и так понятно, примитивно и тривиально.
Пару слов о необходимом арсенале.
Для решения задачи, понадобится следующее:
Изучить, либо освежить, как используются, в SQL, условные конструкции CASE WHEN THEN;
Повторить использование IN в связке с вложенным запросом, а именно, перед ним.
Вспомнить, что делает оператор DISTINCT;
Ну и не забывать, что когда проверяем значение на NULL, то пишем не '=', '<>', '!=' а IS NULL / IS NOT NULL.
И так, сама задача.
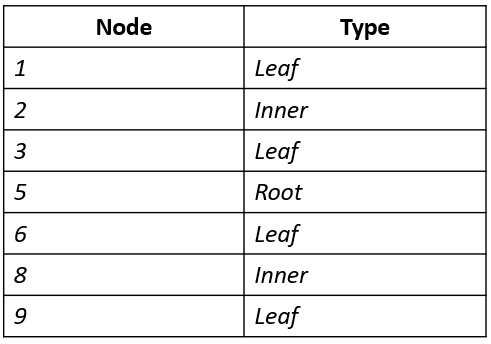
Есть, стало быть, у нас таблица, Tree:
;P - Parent (родительские элементы);")
P - Parent (родительские элементы);
Написать запрос, для определения типа узла (элемента) бинарного дерева.
Для каждого узла, вывести одно из следующих значений: Leaf / Inner / Root.
Упорядочить записи по значению узла.
Например:
Если на входе у нас нечто вроде такого:

В этом месте, можно сделать паузу, и скушав твикс, попробовать нарисовать, по приведенной таблице, бинарное дерево.
То, на выходе мы ожидаем получить:
Соответственно:
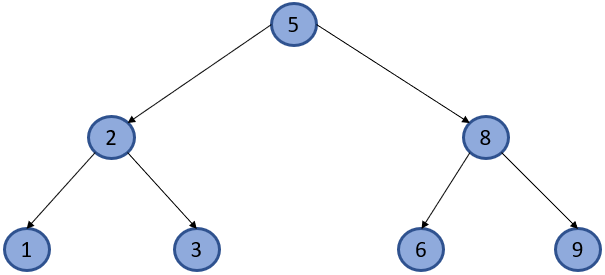
Leaf - это конечный элемент, который ни для кого более, не является родительским, как элементы, выделенные на рисунке ниже.
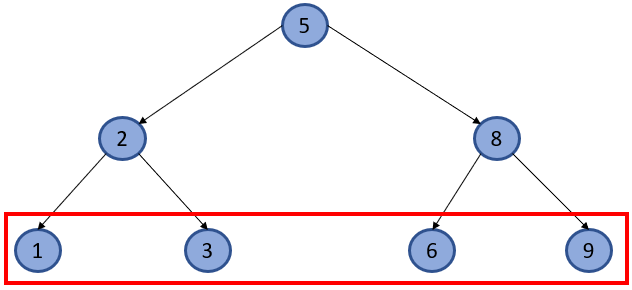
Inner - это элемент, который является родительским для одного, или более других элементов, но и у него самого, также есть родитель.

Root - элемент на вершине иерархии, от которого начинается ветвление, но вышестоящих родительских элементов, у него нет.
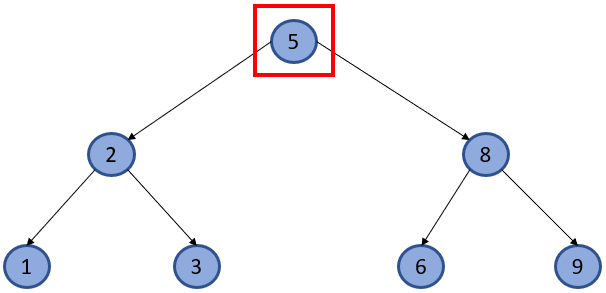
У тех, кто знаком с программированием, обычно в голове, сразу начинают мелькать алгоритмы прохода по массиву в цикле, но у нас тут SQL, и надо чуть перенастроиться)
Не исключаю, что кому-то, еще в период средне-высшего образования, могли настолько
"привить любовь", к решению вообще любых, и подобных задач, в частности, что от словосочетания "бинарное дерево", глаз начинает дергаться в двух местах. Однако повторюсь, задача простая, и сейчас можно сделать глубокий вдох, и попробовать ее решить, не читая пока то, что ниже.
Spoiler, дальше будет разбираться решение!
Иногда, те, кто уже знаком c некоторыми приемами, имеют тенденцию к усложнению, и могли навскидку подумать, что здесь понадобится какой-нибудь там хитрый JOIN, но нет. Все что нужно, так это уловить логику отличия разновидностей элементов, которая записана в табличной форме.
Совсем уж несложно догадаться, что элемент, который является Root-ом, имеет null, в столбце P (Parent).
-
Далее, столбец N (Node), cодержит перечисление всех узловых элементов.
Те значения столбца N, которые также присутствуют в столбце P (Parent), это промежуточные элементы, или внутренние (Inner), то есть они для кого-то являются Parent (родительскими) элементами, но и над ними также еще есть элементы, родительские по отношению к ним самим.Например, [1] -> [2] -> [5]. Элемент [2], является родительским для элеменnа [1], и имеет свой родительский элемент [5].
И наконец, все остальные элементы столбца N, которые не Root, и не являются ни для кого родительскими, это листья, или элементы типа Leaf. Элементы этого типа, отсутствуют в столбце P, т.к. не выступают в роли родительских элементов.
Кто уже понял, как решить, написать и выполнить запрос можно здесь (пишите запрос прямо под имеющимся кодом, учтите, что при первом запуске, система может задуматься).
Решение
SELECT N AS Node,
CASE
WHEN P IS NULL THEN 'Root'
WHEN N IN (SELECT DISTINCT P FROM Tree) THEN 'Inner'
ELSE 'Leaf'
END AS "Type"
FROM Tree
ORDER BY N ASC;Ну а кто хочет держать себя в форме, будь то на случай собеса, или SQL нужен для текущих задач, или просто мозги потренить, запрыгиваем в ТГ канал, SQL Решает (рекомендуется кликнуть на хэштег #задача, и планомерно решать все подряд).
А пока всё.
Успехов в развитии!
Комментарии (15)

Akina
04.09.2023 16:07Так себе решение... скорее всего оно будет медленное, и чем больше таблица, тем хуже производительность. Коррелированный WHEN EXISTS смотрится выгоднее - особенно если имеются соотв. индексы.

VladimirFarshatov
04.09.2023 16:07Классика жанра. :) На sql.ru была даже прибитая гвоздиком тема для поиска всех потомков дерева и не обязательно бинарного на переменных и в один проход по таблице... эх, жаль закрылся скуль-ру..

fraks
04.09.2023 16:07+2Открылась его копия, и не одна.
Тут даже регистрироваться можно, но активность нулевая, все в телеграм ушли.
VladimirFarshatov
04.09.2023 16:07Глянул, к сож. веток прибитых сверху гвоздиком не обнаружил, а искать поиском как-не задалось. Давно .. 2011-2014, где-то там, решение Бочкова, которое искалось "всем миром".
Пардон, нашлось (стоило вспомнить Бочкова) https://resql.ru/forum/topic.php?fid=47&tid=1830048 :) Тут много разных решений..

YDR
04.09.2023 16:07А можно альтернативные решения в студию? Я современный SQL не знаю, мне бы глянуть возможности.
А еще если бы бенчмарк сделать, и определить, кто прав по вопросу быстродействия. Тема для продолжения статьи.

Portnov
04.09.2023 16:07+2https://gist.github.com/portnov/2e5d0522e26513d7f594df4fe73ae862
Надо заметить, распределение мест зависит от объёма данных, от степени ветвления дерева... на небольшом наборе данных выигрывает предложенный в статье запрос. На 1млн строк выигрывает "ручное" решение с union all.

SemenovVV
04.09.2023 16:07+1проще некуда без IN на t-sql :
CREATE TABLE #Tree ( N int, P int ); INSERT INTO #Tree VALUES ( 1, 2), ( 3, 2), ( 6, 8), ( 9, 8), ( 2, 5), ( 8, 5), ( 5, null); ----SELECT * FROM #Tree; declare @root1 int select @root1= N from #Tree where p is null select N,'корень' from #Tree where p is null select P,'ветвь' from #tree where P != @root1 group by p select t.N,'лист' from #tree t left join #tree u on t.n = u.p where u.n is null drop table #Tree

Ivan22
04.09.2023 16:07+2Рекомендую такое решение:
Hidden text
SELECT N AS Node, CASE WHEN T.P IS NULL THEN 'Root' WHEN S.P IS NOT NULL THEN 'Inner' ELSE 'Leaf' END AS "Type" FROM Tree T LEFT JOIN ( SELECT DISTINCT P FROM Tree ) S on S.P = T.N ;тут всего два скана и один хэш джоин, и подойдет практически для любой базы

ArtyomMorozov1
04.09.2023 16:07Часто на практике нужно возвратить также уровень элемента из такой таблицы. В примере из статьи для промежуточных элементов мы получим только информацию о том, что он не конечный и не начальный. Возвратить таблицу вида "Node", "Parent", "Level" из исходной с произвольным количеством промежуточных уровней можно рекурсивным запросом.
with cte as ( select N as [Node] ,P as [Parent] ,1 as [Level] from t1 as d where d.P is null union all select d1.N ,d1.P ,cte.[Level]+1 as lvl from t1 as d1 inner join cte on d1.P=cte.[Node]) select * from cte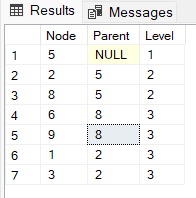

Kerman
понадобится какой-нибудь там хитрый JOIN, но нетЯсно-понятно. Мы не умеем в джойн, поэтому сделаем подзапрос. Может сразу CTE прикрутить?
Задача решается элементарным селфджойном, чтобы проверить потомка на нулл. Парент уже есть в полях. Дальше можно и кейсом, можно и ифом выдать нужное значение
darkmon
Встречался с такой задачей часто на больших таблицах. Безусловно, должен быть join. С масштабируемостью in (...) - начинаются проблемы от 10к+ элементов, к тому же где-то этот массив в памяти надо разместить. Ну и P должен быть проиндексирован, а иначе Nested loops.
uvic
Причем селфджойн скорее всего будет эффективней:
Оптимизатор скорее всего сделает его hash-join-ом (https://habr.com/ru/articles/657021/). Вместо ужасного N IN (SELECT DISTINCT P FROM Tree) внутри CASE, с которым не понятно как оптимизатор справится, даже при наличии индекса по P... А без индекса вообще мрак на большой таблице.
Akina
Self-join тут не стреляет. У узла может быть много детей, что породит дубликаты, а DISTINCT - это дорого.
miksoft
В заголовке и в тексте упоминается бинарное дерево, так что не так уж и много.
И DISTINCT можно сделать до джойна.