

Продолжаем обсуждать инструменты анализа производительности систем на PostgreSQL.
В прошлой статье я начал рассказывать о расширении SP_TRACE, устанавливаемого на любые сборки PostgreSQL, и являющегося неотъемлемой частью мониторинга PerfExpert. SP_TRACE предоставляет новые сведения в виде счетчиков и трасс, которых нет в других известных инструментах.
Статья была посвящена описанию новых счетчиков и нескольким практическим примерам их использования. Кратко перечислю их ниже в таблице 1, чтобы лишний раз не перепрыгивать между публикациями, и чтобы был понятен полный массив статистических данных, которые предоставляет в итоге SP_TRACE.
Таблица 1. Счетчики SP_TRACE
№ |
Счетчик |
Описание |
1 |
Total queries |
Общее количество запросов на сервере СУБД |
2 |
Queries per second |
Количество запросов в сек |
3 |
Average query duration (ms) |
Средняя длительность запроса SQL |
4 |
Disk read speed (MB/s) |
Скорость чтения Мб/c с диска |
5 |
Disk write speed (MB/s) |
Скорость записи Мб/c на диск |
6 |
Cache read speed (MB/s) |
Скорость чтения в Мб/c из памяти (кэша) |
7 |
Cache write speed (MB/s) |
Скорость записи в Мб/c в память (кеш) |
8 |
Temp read speed (MB/s) |
Скорость чтения в Мб/c данных из временных файлов |
9 |
Temp write speed (MB/s) |
Скорость записи в Мб/c данных во временные файлы |
10 |
CPU load (ms/s) |
Совокупная процессорная нагрузка в секунду на все ядра |
11 |
Cache hit ratio |
Cache Hit Ratio – вероятность попадания в кеш |
12 |
Memory/Temp ratio |
Соотношение записи в память и временные файлы |
13 |
CPU heavy queries (s) |
Потреблённые ресурсы CPU (в сек) со стороны тяжелого запроса в момент его окончания, если его длительность больше чем 10 сек (специфичный счетчик мониторинга для поиска тяжелых по CPU запросов) |
А теперь рассмотрим не менее интересную часть расширения SP_TRACE – трассировщик. Как известно в PostgreSQL отсутствует сущность "трассы". Есть, правда, так называемая динамическая трассировка, подключаемая в коде путем вызова внешней утилиты (D-Trace или SystemTap) в определенных точках. Но это всё очень далеко от привычного профайлера в Microsoft SQL Server. Как не крути, в PostgreSQL не хватает инструмента трассировки запросов, а поиск причин просадки производительности представляет собой "рыбалку" – удалось поймать запрос или не удалось в стандартных представлениях, особенно сложно для 1С с большой вариативностью запросов.
Профайлинг запросов в SP_TRACE выполнен по аналогии с трассами Microsoft SQL Server: можно создать несколько трасс с гибкими условиями отбора и управлять ими независимо друг от друга. Такой подход поможет специалистам, работающим с MS SQL, легко адаптироваться к специфике PostgreSQL и уменьшить время на поиск проблем производительности 1С (или любых других платформ приложений). Одно из применений – отбор запросов по подстроке, выборка запросов с количеством чтений логических страниц больше определенного порога или больше определенной длительности и т.д. Протоколируется каждый запрос, подходящий под критерии фильтров, а состав полей имеет весь набор характеристик запросов, необходимый для проведения анализа – см. таблицу 2.
Таблица 2. События трассы SP_TRACE.
Параметр |
Тип данных |
Описание |
dt_begin |
timestamp |
Дата и время старта запроса |
dt_end |
timestamp |
Дата и время окончания запроса |
pid |
bigint |
Идентификатор процесса выполнения запроса |
user_id |
bigint |
Идентификатор пользователя |
db_id |
bigint |
Идентификатор базы данных |
db_name |
text |
Имя базы данных |
query_id |
text |
Идентификатор запроса |
cputime_us |
bigint |
Процессорное время затраченное при выполнении запроса (микросекунды) |
pgtime_us |
bigint |
Длительность выполнения запроса измеренная внутри Postgres (микросекунды) |
sptime_us |
bigint |
Длительность выполнения запроса измеренная sptc (микросекунды) |
mem_start |
bigint |
Резидентная часть памяти на начало отслеживания запроса |
mem_stop |
bigint |
Резидентная часть памяти на момент окончания отслеживания запроса |
lreads |
bigint |
Количество страниц логического чтения |
preads |
bigint |
Количество страниц физического чтения |
writes |
bigint |
Количество записанных страниц |
rows_cnt |
bigint |
Количество возвращаемых/обработанных строк |
transaction_id |
bigint |
id транзакции |
client_addr |
text |
IP адрес пользователя |
application_name |
text |
Название приложения |
query_text |
text |
Текст запроса |
plan_text |
text |
План выполнения запроса |
Для каждого запроса мы имеем возможность видеть расширенные значения потребления памяти, нагрузки на процессор, кол-во физических и логических чтений, размер рекордсета, номер транзакции и, одно из ключевых значений – реальный план выполнения запроса – см. скриншот (в новой версии мониторинга PerfExpert, план выполнения запроса также будет представлен в графическом виде дерева операций).

Основная ценность сохраненных данных трассы (одной, а лучше нескольких) – это возможность ретроспективного анализа, например, проблема производительности произошла и зафиксирована системой мониторинга в ночные часы, а анализ ситуации мы имеем возможность выполнить утром или позже. То есть, нужно видеть картину в динамике, для этого PerfExpert записывает данные непрерывно 24/7, как бортовой самописец. По любой базе данных, на любом инстансе у вас будет статистика по счетчикам (см. список в таблице 1) и по тяжелым запросам (см. таблицу 2). Почему только по тяжелым запросам? Записывать в трассы все без исключения – мероприятие избыточное, ведь массив данных в трассах будет невообразимо большим, его тяжело хранить и обрабатывать, а процесс сбора будет отбирать много вычислительных ресурсов - сам может стать причиной деградации быстродействия системы. Поэтому писать имеет смысл только то, что будет представлять ценность для дальнейшего анализа. Исходя из нашего опыта работы с высоконагруженными системами, например 1С, программа мониторинга PerfExpert по умолчанию записывает два вида трасс, достаточных для проведения анализа запросов в 99% случаях:
DURATION – все запросы, которые выполняются более пяти секунд;
READS – все запросы, выполняющие более 50 тыс. логических чтений;
Таким образом, используя подобные ограничения, мониторинг содержит данные, позволяющие проанализировать, по нашей практике, не менее 95% встречающихся проблем (инцидентов) снижения производительности ИТ-системы. Опять же, включить полную трассировку можно, но делать это нужно крайне осторожно и кратковременно, когда на то есть аргументированная потребность.
Кроме этого, в мониторинге есть возможность сохранять данные из уже привычных лога PostgreSQL и представления pg_stat_statements().
Приведу несколько примеров, иллюстрирующих подход к поиску причин просадки производительности с помощью данных по счетчикам и трассам.
Пример 1. Жалобы пользователя на замедления в программе 1С
Пользователь «Колпаков…» жалуется на замедления работы программы 1С, с его слов в промежутке времени с 12:45 до 12:55. Опишу алгоритм действий эксперта, работающего с программой PerfExpert:
1. Находим в мониторинге PerfExpert отрезок времени, на который жалуется пользователь и находим в панели «Сессии 1С» данного пользователя и соответствующий ему SPID.

Пользователю «Колпаков…» соответствуют два SPID: 4128183 и 4123548.
2. Теперь в трассе READS находим запросы, соответствующие этим SPID

Отобранных запросов за выбранный промежуток достаточно много, но видов запросов фактически всего три-четыре. Поэтому каждый из них можно посмотреть, посмотреть их план и принять решение о необходимости оптимизации.
Пример 2. Увеличение нагрузки на CPU + жалобы пользователей
Пользователем PerfExpert зафиксировано повышение потребления CPU, при этом от пользователей программы 1С начали поступать жалобы на её замедление.
Ход анализа инцидента следующий:
1. По счетчикам сопоставляем время жалоб пользователя и рост нагрузки на CPU
2. В панели сессий SQL сортируем все строки по потребленному CPU. Видим сессию (их может быть множество), которая потребила почти целиком одно процессорное ядро. Фиксируем ее SPID (837043).
3. Тут же можно сразу посмотреть запрос, который вызвал подобную нагрузку. Не весь, только первые 1000 символов. Полный запрос можно посмотреть уже в трассе.

4. Открываем трассу Reads (все запросы с более 50 тыс. логических чтений) и строим трассу с фильтром по SPID = 837043.
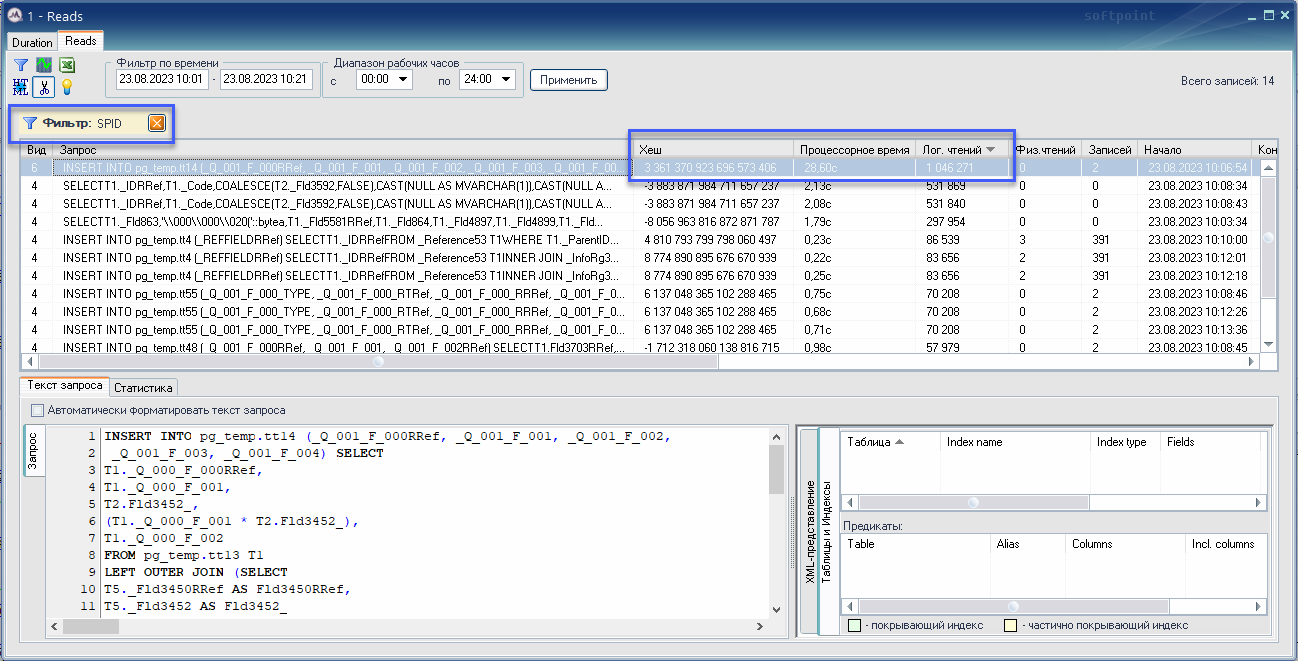
Из списка всех запросов по отфильтрованному SPID видно, что наш запрос находится в ТОПе как по числу логических чтений (более 1 млн.), так и по процессорному времени (28,6 сек).
5. Запоминаем хеш запроса (3 361 370 923 696 573 406) и теперь строим трассу READS по всем запросам за неделю. При этом, все запросы группируем по виду запроса (по хешу)

Если отсортировать сгруппированные запросы (всего в трассе 19 034 запроса) по доле потребленного процессорного времени, то наш вид запроса опять попал в ТОП и отъедает чуть более 14% CPU.
То есть это первый кандидат на оптимизацию. Анализируем план и ищем варианты оптимизации – индексный тюнинг или код приложения.
Для просмотра плана в трассе есть специальная колонка «План выполнения».

Заключение
Этой статьей я завершу описание общих возможностей расширения SP_TRACE в связке с мониторингом PerfExpert. Первую часть см. здесь.
Основная мысль, которую хотелось донести, – теперь возможности анализа проблем производительности в PostgreSQL возросли кратно, и не просто приблизились к возможностям мониторинга MS SQL, но и в чём-то превзошли их. Благодаря новым инструментам, PostgreSQL перестаёт быть черным ящиком и открываются возможности для использования этой СУБД в качестве платформы для высоконагруженных систем. А задача команды Софтпоинт – развивать инструменты мониторинга и специализированных продуктов повышения производительности баз данных PostgreSQL. Обязательно будем и дальше делиться с вами нашими наработками.
Напомню, что посмотреть возможности мониторинга PerfExpert (как для MS SQL, так и для PostgreSQL) можно на нашем сайте. Кроме этого, можно посмотреть несколько коротких обзорных видеороликов:
Первая часть статьи: Мониторинг PostgreSQL. Новые возможности анализа производительности 1С и других систем. Часть 1: Счётчики