
Прежде, чем начать рассказывать, что и как мы сделали, немного вводных данных.
Немного контекста
Мы — технологическая платформа для всех систем УКД ЮЛ — самого лучшего интернет-банка и мобильного приложения для бизнеса, и новейшего технологического решения для аутентификации клиентов — Alfa ID. Регулярно готовим и внедряем решения, которые обеспечивают миллионам наших клиентов быстрый и безопасный сервис для ведения своих задач в продуктах Альфы.
Тестирование надёжности до нашего пилота проходило достаточно тривиально — на контуре нагрузочного тестирования были развёрнуты все компоненты системы целиком и гонялись тесты стабильности. Результатом их было максимальное количество запросов в секунду для каждой из подсистем, при которых они корректно работали под большой нагрузкой.
Минусом этого подхода было то, что, несмотря на верные цифры максимально допустимой нагрузки, они не давали ответа на все вопросы. Случались (редко, но тем не менее) инциденты, при которых компоненты системы уходили в ребут и не полноценно возвращались в строй, и приходилось дотюнивать их наживую руками. Пока Alfa ID был на стадии запуска, до этих деталей руки не доходили, но при полноценной промышленной эксплуатации таких моментов хотели избежать — и решили потестировать подход Chaos Engineering, который как раз про это.
На первый взгляд, идея намеренно вызывать сбои и неполадки в системе может показаться контринтуитивной. Но мы намеренно проводим эксперименты, симулируя различные виды сбоев и неполадок, чтобы оценить её устойчивость и подготовленность к экстремальным условиям, и обнаружить слабые места и уязвимости системы до того, как они приведут к серьезным проблемам в реальных условиях эксплуатации.
Из допущений, о которых сразу хочется сказать — ломать прод, как в Netflix, основоположнике Chaos Engineering`a, и подвергать риску клиентов на этапе пилота нам, разумеется, никто не дал, поэтому мы воссоздали точную копию боевой среды на контуре нагрузочного тестирования. Инфраструктура и количество эмулируемых запросов были идентичны продакшн-среде, поэтому результаты с небольшим допущением аналогичны боевым.
Применение Chaos Engineering происходит в несколько этапов:
Идентификация критических компонентов: выявление ключевых компонентов системы, от которых зависят бизнес-процессы и надежность.
Создание гипотез: определение сценариев сбоев, которые могут возникнуть в реальности, и формулирование гипотез, как система должна с ними справиться.
Реализация экспериментов: внедрение контролируемых сбоев, как указано в гипотезах, с применением специальных инструментов и методов.
Анализ результатов: оценка реакции системы на сбои, выявление слабых мест и анализ воздействия на работу системы в целом.
Теперь давайте подробнее пройдемся по этим этапам.
Подготовка
Для начала, за первые несколько минут командного брейншторма, мы выявили критические компоненты системы для тестирования. Это были кластеры K8S, движок бизнес-процессов Zeebe, Redis, Kafka, PostgreSQL и Java- и JS-приложения.
А вот к созданию гипотез ребята подошли с душой — за час нагенерили несколько десятков вариантов того, как и что можно сломать, и стало понятно, что нужно что-то приоритизировать.

В результате получилась достаточно милая табличка с 4 параметрами скоринга по десятибалльной шкале:
критичность;
масштаб трудозатрат;
применимость к системе;
возможность проверки на стенде НТ.

Наиболее приоритетными оказались две следующие гипотезы:
Выход из строя одного из дата-центров.
Критичные зависания/отключения брокеров Zeebe.
Давайте рассмотрим процесс и результаты по каждой.
Гипотеза 1: выход из строя одного из дата-центров
Гипотеза заключается в том, что проведение эксперимента по отключению одного из двух серверов позволит оценить, насколько готова система справиться с таким событием, минимизировать его влияние на клиентов и поддержать нормальную работу в остальных частях системы.
Для практического воплощения данного эксперимента решили эмулировать увеличение трафика в разных пропорциях на подопытный дата-центр. Тест состоял из трех этапов:
На первом этапе на систему подавалась стабильная нагрузка 80% от максимума на 30 минут.
На втором этапе нагрузка повышалась до 160% от максимума и держалась 20 минут — имитировали отключение одного дата-центра/кластера. На втором этапе фиксировались показатели утилизации ресурсов и ключевые метрики производительности системы.
На третьем этапе нагрузка возвращалась к уровню 80% на 2 часа, и фиксировалась способность системы восстанавливаться после критической нагрузки.
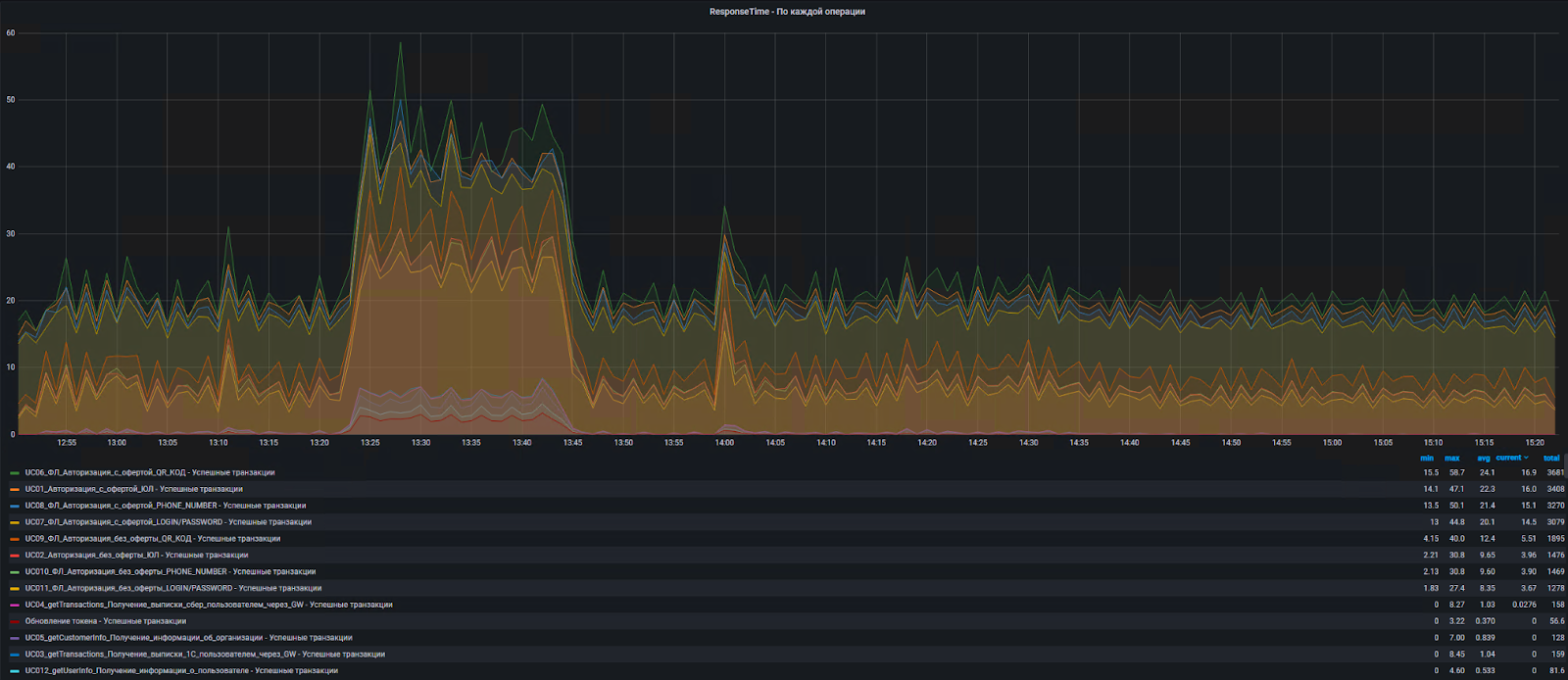
Результаты нас удивили — что и требовалось от подобного тестирования.
Для начала положительное — система вполне предсказуемо вела себя в период резкого повышения нагрузки и быстро восстановилась после него.
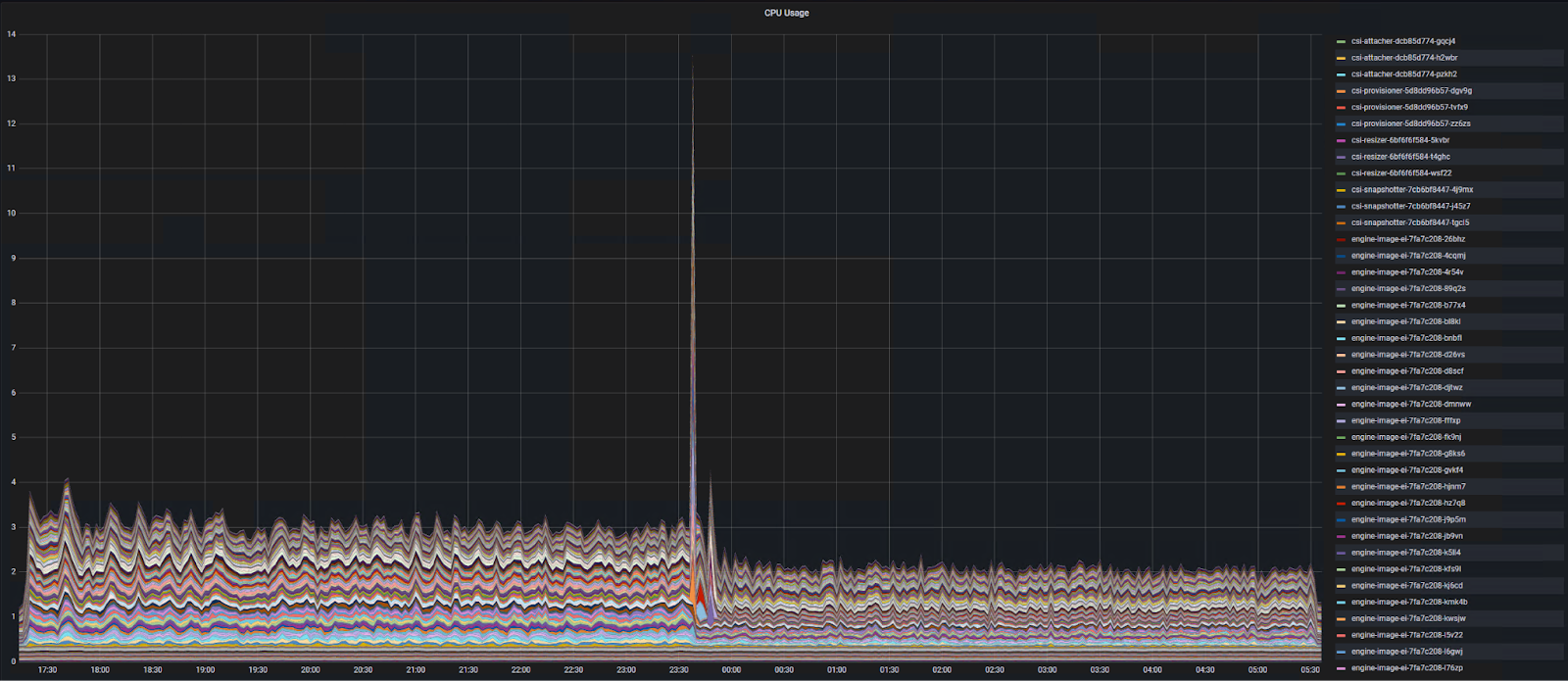
Из найденных «точек роста» — при нагрузке около 110 аутентификаций в секунду, случайным образом происходил сбой в Longhorn (распределенное блочное хранилище, которое использовалось у нас в качестве volume provisioner в K8S), приводивший к деградации производительности.
Взрывной рост потребления CPU у Longhorn при сбое.
Падение производительности Zeebe.

После анализа системных, сетевых и прикладных метрик и логов пришли к выводу, что из-за резко увеличивающегося количества IO операций, которые генерирует Zeebe, не выдерживает Longhorn, и persistent volume у некоторых брокеров Zeebe отваливается без возможности автоматического восстановления. Подробнее об этом и других тонкостях прокачки Zeebe мы расскажем в отдельной статье.
Гипотеза 2: стабильность движка бизнес-процессов — кейсы с Zeebe
Цель гипотезы — «пошатать» движок бизнес-процессов Zeebe и убедиться в его корректной работоспособности в нештатных ситуациях.
Тестировали 3 разных сценария:
Перезапуск одного брокера Zeebe (проверка репликации схемы процессов при отключении брокера с нулевой партицией).
Одновременный перезапуск всех брокеров Zeebe.
Временное уменьшение количества брокеров на 50%.
Тест 1 — перезапустили один из брокеров.

Отключение прошло успешно, остальные брокеры подхватили текущие процессы в очереди. После включения за ~2 минуты всё вошло в норму
Тест 2 — одновременный перезапуск всех брокеров.

В момент выключения брокеров, как и ожидалось, наблюдалось падение производительности. После перезапуска система полностью восстановилась, при этом наблюдается снижение количества сборок мусора и общее использование памяти JVM.
Тест 3 — временное уменьшение количества брокеров и партиций Zeebe на 50%.

На графиках во время уменьшения количества брокеров наблюдалось двукратное увеличение одновременно выполняемых операций в каждой партиции, и увеличение очереди операций на каждую партицию. После увеличения количества брокеров до исходных значений, производительность возвращается к прежним показателям. Провалы производительности в 16:03 и 16:27 вызваны реконфигурацией кластера Zeebe.
В результате наших издевательств над Zeebe мы выяснили, что движок оказался достаточно живучим, и каких-то явных дефектов выявлено не было. Немного углубившись в их документацию мы обнаружили, что разработчики Zeebe аналогично практикуют Chaos Engineering, но уже в промышленном масштабе, и их кейсы сильно забористее, чем наши пилотные. Подробнее можно посмотреть здесь в их блоге в статье «Using Large Multi-Instance»
По правде сказать, мы были приятно удивлены, и следующие итерации chaos-тестирования будут направлены на другие компоненты системы.
Что можно сказать в завершение?
Как я и говорил ранее, это был пилот — тестирование подхода Chaos Engineering. Он был оценен всеми участвующими коллегами успешно — мы однозначно будем копать и глубже, придумывая более сложные кейсы с компонентами системы, и шире, задействуя больше систем в одном тесте.
Несмотря на первую итерацию и запуск с колёс, был выявлен ряд описанных негативных моментов с Longhorn, которые подтвердили нашу уверенность в том, что от него нужно отказываться и переходить на более надежные аналоги. Без пилота это выяснилось бы несколько позже, и, возможно, при более трагических обстоятельствах.
Мы действительно взглянули на надежность под новым углом — нагрузочное тестирование теперь не только будет определять максимально допустимое количество запросов в секунду, но и более тонкие моменты, в которых требуется творческая совместная коммуникация разработчиков, функциональных и нагрузочных тестировщиков и сопровожденцев
Суммарно на весь проект у нас ушло не более месяца — от этапа discovery до полноценных результатов с проработанными выводами. Мы считаем, что выделить пару спринтов и посмотреть на систему со всеми её участниками, а-ля helicopter view, всегда полезно и может дать крутые результаты за достаточно короткий срок.
Поделитесь в комментариях, есть ли подобные подходы у вас? Как происходит этот процесс в ваших системах?