
Привет, Хабр! С вами Валентин, архитектор направления Backend компании SimbirSoft. В данной статье мы с коллегами поделимся опытом реализации большого и сложного проекта с микросервисной архитектурой, а также поговорим о роли архитектора в таких проектах.
Статья ориентирована на разработчиков различного уровня, управленцев, а также IT-специалистов, занимающихся построением архитектуры, в частности микросервисной. Надеемся, что материал будет полезен широкому кругу читателей, вне зависимости от специализации и компетенций.

Постановка задачи
Нам необходимо было повторить и улучшить функциональность имеющийся системы. Ее предыдущая реализация представляла собой коробочное решение с монолитом «под капотом». Постепенное увеличение нагрузок, которое неизбежно при развитии системы, в результате привело к решению переходить на микросервисы, чем мы и занимались.
Заказчик – крупное предприятие тяжелой промышленности. На реализацию нам было отведено 9 месяцев.
Начальные требования были следующими:
Использование облачной инфраструктуры в Яндекс.Облако.
Работа с 10k пользователей.
Возможность авторизации от имени другого пользователя.
Реализация больших и сложных бизнес-процессов по работе с заявками.
Наличие чата на платформе.
Реализация механизма рассылок.
Реализация системы уведомлений.
Однако большие и сложные проекты всегда живут своей жизнью. Зачастую автоматизируемые процессы, а значит и требования к ним эволюционируют параллельно уже начавшемуся процессу разработки. И, как следствие, важная особенность таких проектов — необходимость постоянного внесения изменений в процессе проектирования и реализации.

Что добавилось и изменилось в процессе работы над системой:
Выяснилось, что компании-контрагенты заказчика могли быть одновременно как подрядчиками, так и заказчиками (например, компания может предлагать услуги по сверлению заготовок и в то же время заказывать сверла). Соответственно пользователи, являющиеся контактами этой компании, также обладают ролью как исполнителя, так и заказчика.
Изначально предполагалось, что у нашего заказчика с каждой компанией-подрядчиком заключается один договор. Однако в процессе реализации выяснилось, что договор может быть не один, а отдельный для каждой роли, поскольку для каждой роли договоры различаются.
На понимание работы системы довольно сильное влияние оказывают особенности бизнес-процессов и их понимание сотрудниками (закон Конвея). В нашем случае во множестве случаев имело место сращивание понятий, которые в самой системе реализуются в виде различных бизнес-сущностей. Например, такое понятие как «заявка» для нашего заказчика с точки зрения бизнеса неделимо, но при реализации системы распадается на целую иерархию объектов и таблиц БД.
Присутствуют дорогостоящие запросы в сторонние сервисы, такие как Яндекс.Карты и прочие, в которых присутствуют платные тарифы для запросов извне.
Отдельную сложность в реализацию системы вносят дополнительные требования UX. Согласно им заказчику необходимо иметь максимум полезной информации буквально на каждой странице приложения, а также возможность переходов буквально «из любой точки в любую точку».
Особенности реализации системы, предшествовавшей нашей, были таковы, что каждый экран был максимально насыщен элементами управления, различными информационными иконками и ссылками. С одной стороны, пользователь получает буквально «кабину пилота» со множеством возможностей, которые рано или поздно вызывают некоторую степень привыкания. С другой стороны, тренды в дизайне UI/UX направлены на облегчение страниц и снижение количества объектов, требующих удержания внимания пользователя. Здесь приходилось искать золотую середину между удобством, привычками пользователей и нагрузкой на систему.
Потребовалось реализовать возможность работы с множеством различных документов: договорами, презентациями, счетами на оплату и так далее.
Немного теории: об особенностях микросервисной архитектуры
Микросервисная архитектура – это подход, при котором приложение разбивается на небольшие автономные сервисы, каждый из которых выполняет отдельную функцию. Эти сервисы взаимодействуют между собой через сетевые вызовы, коммуницируя посредством API.
Преимущества микросервисной архитектуры:
1. Гибкость и масштабируемость. Микросервисы могут быть разработаны и развернуты отдельно, что дает возможность масштабировать и изменять только нужные компоненты системы.
2. Независимость. Каждый сервис может быть разработан с использованием разных языков программирования, технологий или фреймворков. Это позволяет командам разработчиков работать над разными сервисами независимо друг от друга.
3. Легкость поддержки. Когда сервисы разбиты на микросервисы, их поддержка и обновление становятся проще, так как изменение отдельного сервиса не влияет на работу других компонентов системы.
4. Расширяемость. Благодаря модульной структуре микросервисной архитектуры добавление новых функций или компонентов становится проще и быстрее.
Однако у микросервисной архитектуры есть и свои проблемы:
1. Сложность управления. Управление большим числом микросервисов может быть сложным. Необходимо обеспечить координацию между сервисами, управление конфигурацией, мониторингом и отладкой.
2. Сетевая сложность. Коммуникация между микросервисами происходит через сетевые вызовы, что может привести к увеличению времени отклика и снижению производительности. Также может возникнуть проблема отказоустойчивости и сбоев в сети.
3. Усложнение разработки. Разработка и отладка микросервисов может быть сложнее в сравнении с монолитной архитектурой. Требуется уделить внимание разработке API для взаимодействия между сервисами и обеспечению их совместимости.
4. Тестирование. Тестирование микросервисов требует большего внимания, так как каждый сервис должен быть протестирован отдельно и в совокупности с другими сервисами.
Несмотря на эти проблемы, микросервисная архитектура остается популярным подходом, особенно для больших и сложных систем, где гибкость и расширяемость играют важную роль. Но при ее использовании необходимо учитывать и решать соответствующие проблемы.
Для снижения рисков, связанных с проблемами микросервисной архитектуры, был необходим высококлассный специалист. В нашем случае это был архитектор. Он же совмещал функции тимлида.
Наши архитектурные и управленческие решения на старте
Особенности задачи, сжатые сроки и формирование ТЗ буквально одновременно с реализацией привели к необходимости фундаментальных решений касаемо как архитектуры, так и процесса разработки на самом старте.
Отсутствие полноценного готового ТЗ вносит серьезные ограничения на выбор архитектурных решений, а высокая степень неопределенности сильно влияет на работу команды. В то же время архитектура даже в этих условиях должна быть поддерживаемой, масштабируемой и достаточно гибкой по отношению к изменениям в требованиях.
Таким образом на старте проекта были сформированы следующие подходы, которые легли в основу всей дальнейшей разработки:
-
Выделение слоя адаптеров
Вполне классический рекомендуемый подход, который мы тажке приняли на вооружение. Поскольку требования к системе предполагали наличие ряда интеграций с внешними сервисами, было решено для каждой из таких интеграций сразу разработать свой сервис-адаптер, хотя ввиду сжатых сроков и был велик соблазн до поры до времени (пока оно используется только в одном месте) реализовать интеграцию в сервисе-потребителе.
Однако довольно быстро стало ясно, что потребителей будет несколько, клиенту могут потребоваться дополнительные API, а сам механизм интеграций может претерпевать изменения (поскольку ТЗ также часто меняется). Впоследствии это решение оказалось крайне полезным, поскольку логикой, инкапсулированной в одном конкретном сервисе-адаптере, проще управлять, и в нее значительно проще и быстрее вносить изменения. В то время как переиспользование этой логики, если вдруг появляется еще один потребитель, становится максимально простым и дешевым.
-
Security-компонент
Один из первых механизмов, который предстояло реализовать – модель безопасности и доступа к данным. Здесь был велик соблазн снизить стоимость решения и использовать один из готовых вариантов, например, keycloak. Однако требование сложной авторизации от лица другого пользователя повлекло бы довольно сложные кастомизации, что свело бы на нет все преимущества этого решения. Поэтому было принято решение разработать свой собственный security-компонент. Впоследствии это решение вполне оправдало себя.
Но в угоду гибкости мы решили отделить сервис с пользовательскими данными от security-сервиса, что привело к тесной связи между ними и де-факто сращиванию их логики. Оглядываясь назад, возможно, имело смысл сразу на старте «склеить» эти сервисы в один, что снизило бы нагрузку, хоть и повысило бы связанность.
-
DB per service
Данный подход также относится к классическим подходам в микросервисной архитектуре, поэтому мы старались его придерживаться. Это позволило с первых этапов разработки установить четкие архитектурные границы между сервисами и избежать роста связанности по данным. К условным минусам этого подхода можно отнести два момента.
Во-первых, наличие требования по максимальному наполнению страниц (см. выше), что привело к множеству обогащений данными из других микросервисов, и, как следствие, к падению производительности. Здесь велик соблазн собрать все данные в одну БД, однако возникающая связанность и потенциальные проблемы превысили бы видимые преимущества, к тому же для решения этой проблемы применяются отдельные БД для предварительной агрегации данных.
Во-вторых, условный минус связан с ростом числа экземпляров БД в кластере с ограниченным количеством соединений и, как следствие, падением производительности. Но этот случай — скорее вопрос настройки инфраструктуры и выбранной стоимости тарифов, а потому не совсем рационально идти на серьезные архитектурные риски в угоду снижения количества соединений.
-
Shared components
На самом старте проекта мы выделили отдельную группу библиотек в виде многомодульного проекта для размещения в нем общих настроек анализа кода, перечислений, типовой логики взаимодействия, логирования и многих других стандартных операций. Это позволило ввести определенный стандарт в разработке микросервисов и избежать затрат на дублирование кода и устранение его последствий.
На протяжении всей разработки проекта этот подход многократно оправдывал себя. Однако для его эффективного использования необходимо на самых начальных этапах четко зафиксировать правила версионирования, создания релизов и обновления версий этих библиотек в микросервисах.
Из минусов можно отметить потенциальные риски получения идентичных ошибок в нескольких микросервисах при наличии ошибок в очередной версии библиотеки. Кроме того, очевидно, этот подход работоспособен только в том случае, если микросервисы как минимум разрабатываются на одном языке и на взаимно совместимых стеках технологий.
-
«Подводящие упражнения»
Под этим названием я подразумеваю предварительный запуск подготовительных работ, разработку базовых каркасов микросервисов, в том числе до получения согласованных текстов первых ТЗ, когда очерчены лишь общие контуры системы, которую предстоит разработать. Это в определенной степени рискованно, поскольку дальнейшие требования могут вызвать значительные переработки. Но будучи примененным аккуратно и ограниченно, данный подход позволяет начать накапливать хотя бы минимальные базовые наработки по функциональности еще до появления устоявшихся требований.
К примеру, на этом этапе были разработаны все базовые каркасы взаимодействий, исследованы возможности для интеграций с внешними системами и разработаны их прототипы, утверждены форматы кодстайла и выполнены прочие работы, на которые относительно слабо влияют требования к функциональности, но в то же время позволяют заложить работоспособный каркас будущей системы.
-
«Тупые» компоненты
Поскольку детальные требования рождались параллельно с разработкой, нам потребовалась некая точка опоры, то есть группа вспомогательных компонентов/микросервисов, выполняющих довольно общую логику. Здесь крайне важно обеспечить на практике четкое соответствие принципу Single Responsibility и не перегрузить такие компоненты логикой, за которую они не должны отвечать.
В результате были получены максимально сухие, можно сказать, узкоспециализированные или «тупые», но при этом генерализованные с точки зрения конфигурирования компоненты, ориентированные на выполнение единственной вспомогательной бизнес-функции: работа с файлами, безопасность, работа с документами, ядро чата. Причем степень независимости таких компонентов от бизнес-функций проекта настолько высока, что эти компоненты могут быть с легкостью переиспользованы практически для любого другого проекта без каких-либо изменений в исходном коде, то есть становятся де-факто утилитами.
Заложив подобные компоненты на начальных этапах проекта, нам удалось, во-первых, изолировать и отладить их логику и впоследствии пользоваться ей как надежным проверенным фундаментом, а во-вторых, выстроить архитектурные границы. Благодаря им дальнейшая функциональность разрабатывалась в соответствии с принципом Open-Closed и не требовалось вмешательства в уже разработанные фундаментальные компоненты.
-
Code review с пристрастием
Здесь читатель может сразу задаться вопросом: а зачем в принципе упоминать отдельно этот момент? Ведь ревью кода — это хороший тон любого процесса разработки и должен присутствовать по умолчанию, как и сам код. Всё верно, так и есть. Мы заостряем внимание на этом пункте лишь для того, чтобы подчеркнуть его исключительную важность на начальном этапе разработки, когда закладываются основы приложения (при этом ничуть не умаляя его важности на последующих этапах).
И если даже случается так, что цейтнот вынуждает чуть снижать планку ревью на более поздних этапах, то в самом начале ревью должно быть настолько жестким, насколько это возможно. В нашем случае это позволило в короткие сроки стабилизировать те сервисы, которые являются фундаментом системы. Их работоспособность и стабильность играет решающее значение на протяжении всего проекта. Инвестировав время в этот подход, мы, помимо прочего, создали примеры кода, на которые разработчики ориентировались в дальнейшем.
-
Контроль единообразия
Этот пункт очень похож на shared components, да и в основном реализуется именно этим набором библиотек. Но чтобы разработать микросервисный проект таких масштабов, как это предстояло сделать нам, важны единообразие и дисциплина в более широком смысле слова.
Для ускорения разработки мы договорились, что для сходных операций и задач все наши микросервисы будут использовать одни и те же реализации в рамках стека технологий. Например, во всех микросервисах REST-запросы реализованы только с помощью Feign, движок ORM — только Hibernate (причем в основном с использованием спецификаций) и так далее. Таким образом не пришлось тратить время на альтернативные реализации, если того явным образом в узком наборе кейсов не требовали конкретные задачи.
-
Ротации разработчиков
При разработке большого проекта для тимлида велик соблазн поделить команду на домены аналогично разрабатываемому приложению, и в дальнейшем получить глубоких специалистов, отвечающих за свой домен (один или несколько). Такой подход создает один из видов иерархии управления, позволяет делегировать ответственным часть архитектурного надзора за компонентами, ускоряет работы внутри компонента за счет высокой накопленной экспертизы.
В нашем случае мы решили сознательно отказаться от такого подхода, сделав ставку на ротации и взаимозаменяемость, то есть каждый разработчик хотя бы раз работал с каждым микросервисом. Такой подход дает ряд ощутимых преимуществ.
Во-первых, членов команды изначально было меньше, чем микросервисов, следовательно, при доменном подходе каждому ответственному пришлось бы контролировать целую группу сервисов.
Во-вторых, при доменном подходе существенную роль играет Bus Factor: во время отпуска, больничного или отсутствия сотрудника по иным причинам ему нужна столь же квалифицированная замена.
В-третьих, как было сказано выше, все микросервисы нашей системы обладают довольно высокой степенью однообразия, соответственно, создается минимальный порог вхождения.
В-четвертых, при ротационном подходе мы получили наиболее эрудированную, многофункциональную, мотивированную команду (это еще и покрывает интерес к новым технологиям!). Каждый ее участник готов решить практически любую проектную задачу.
-
Отложенная работа с деталями
В книге Р. Мартина «Чистая архитектура», которая по праву считается классикой среди литературы разработчика, красной нитью проходит мысль о том, что реализацию деталей, не являющихся ключевыми функциями приложения, необходимо откладывать настолько, насколько это возможно. Мы последовали этому совету и постарались в первую очередь с максимальной широтой охватить автоматизируемый бизнес-процесс, при этом не сильно вдаваясь в детали. На первых этапах были отложены не столь критичные для бизнеса части функциональности, мы не тратили время на разработку тех частей системы, которые использовались реже остальных. Наконец, мы откладывали принятие решений о некоторых аспектах реализации фичей, которые не играли основополагающей роли в ключевых бизнес-функциях.
Стоит признать, что следовать этому принципу нелегко: велика вероятность ошибиться и отложить критичное решение. Но при тесном взаимодействии с бизнес-аналитиками и заказчиком нам удалось свести число таких случаев к минимуму.
Обобщая всё сказанное выше, хочется отметить, что при реализации больших проектов с высокой степенью неопределенности крайне важно уже на начальных этапах принять основополагающие ключевые решения, обозначить базовые архитектурные границы, чтобы погрузиться в пучину супердетального проектирования там, где наиболее вероятны изменения. Излишняя щепетильность к неприоритетным деталям в начале может привести к картине разработки, аналогичной рисунку ниже, ведь бюджет не резиновый, а время сильно ограничено:

Далее мы рассмотрим наши подходы к реализации некоторых требований проекта.
Работа с файлами
Основные требования по работе с файлами, которые были выявлены в процессе проектирования:
множество видов файлов (договоры, презентации, счета на оплату и так далее) с возможностью конвертации файлов в формат PDF;
размер файлов, которые необходимо конвертировать, может достигать нескольких десятков Мб;
ограничения по количеству, типам, размеру – в зависимости от роли пользователя;
возможность удаления и восстановления файлов в системе;
уведомления для файлов «просмотрено»/«не просмотрено» для всех участников процесса;
наличие истории изменения файлов.
Для обеспечения вышеуказанных требований мы реализовали схему, изображенную на Рис 1.

Здесь использовались следующие принципы:
Разделение на слои абстракции.
Сервис работы с ФХ (файловым хранилищем) – нижний слой, адаптер над S3, который представляет собой наиболее общий функционал хранения.
Сервис документов – абстракция для работы с документами системы.
Документ – это категория файлов, свой бакет.
Может быть множество сервисов на том же уровне абстракции, что и сервис документов.
Благодаря такой абстракции удалось повторно использовать код сервиса ФХ для реализации сервиса шаблонов (см. Рис. 2).

Реализация системы шаблонов и уведомлений
Система шаблонов и уведомлений тоже была не так проста, как казалось на первый взгляд. Для реализации пришлось также использовать уровни абстракции над уровнем шаблонов и использовать его как базовый класс для реализации сервиса отчетов, оповещений и уведомлений (Рис. 3). Шаблоны используются как для отчетов, так и для email-сообщений, уведомления по email и внутрисистемные управляются из одного места.

MongoDB в проекте
Зачем мы с этим связались?
справочник с нефиксированной структурой;
журнал событий;
системные уведомления;
чат.

Что получили?
возможность быстрой выборки данных;
легко модифицируемую структуру;
… и ачивку за то, что у нас на проекте есть NoSQL:)
Авторизация от имени другого пользователя: картина мира глазами заказчика
Согласно текущему ТЗ, система авторизации должна обеспечивать следующую функциональность:
есть некоторая роль А и роль Б;
роль А должна уметь выполнять некоторые действия от имени роли Б, видеть всё то же, что и Б (типа teamviewer), но…
при этом оставлять «следы» того, что это на самом деле роль А (исключить возможность подлога);
при этом в системе есть «мультироли»…
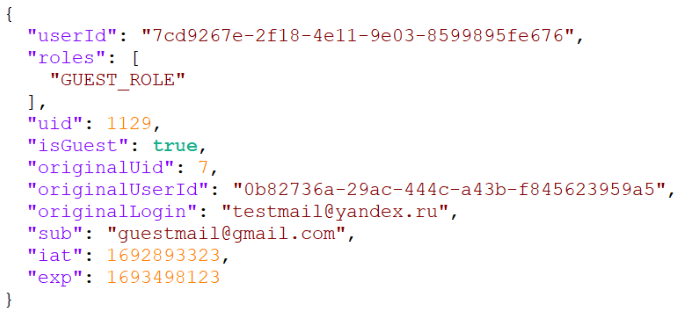
Для обеспечения набора этих требований была реализована схема авторизации через гостевой токен (Рис. 4).

Оригинальный токен:

Гостевой токен:
Микромонолиты: не от хорошей жизни

Монолит и микросервисы – это тема извечных споров. Нередко даже на собеседованиях встречаются кандидаты, категорически утверждающие, что только микросервисы приведут к светлому будущему, а монолиты – зло во плоти. Но на практике мир не делится на черное и белое, и даже такой, казалось бы, антипаттерн, как микромонолит, способен приносить некоторую пользу.
Собственно, на нашем проекте мы сознательно превратили два микросервиса в микромонолиты. Не вдаваясь в подробности того, как мы пришли к такой жизни, и чтобы не раскрыть излишние детали, попробуем сформулировать основанные на опыте нашего проекта рекомендации, когда же микромонолит может быть полезен.
Показания к применению:
Ограничения инфраструктуры. К примеру, если существует жесткое ограничение по соединениям с БД и нет возможности перейти на более удобный тариф. При этом микромонолит оказывается меньшим злом, чем нарушение подхода Database per service.
Cжатые сроки. Разработка каждого нового микросервиса – это накладные расходы (каркас, ревью, тестирование).
Производительность. Сетевое взаимодействие между сервисами – это также накладные расходы. А если вспомнить то требование нашего проекта, при котором каждая страница максимально насыщена разнообразными данными, то таких взаимодействий становится крайне много
Близость реализуемых бизнес-процессов. Но само собой, не любые два микросервиса стоит объединять в микромонолит. По меньшей мере это должны быть сервисы, реализующие сходные бизнес-процессы или их части. Остальные же части системы должны сохранять необходимую степень инкапсуляции.
Рекомендации при реализации:
Разделение кода. Рано или поздно микромонолит все-таки придется разделить. А чтобы упростить этот процесс и не порождать известные проблемы с разделением монолита, лучше сразу придерживаться высокой степени модульности и разделения кода внутри микромонолита.
Контроль за темпами роста. Важно понимать, когда стоит остановиться. Бесконтрольный рост микромонолита чреват превращением его в полноценный большой монолит, а значит и появлением связанных с этим проблем.
Что можно было сделать лучше?
Ретроспектива – важнейший этап жизненного цикла любого проекта, и мы не исключение. Если оглядываться назад, многое видится иначе. Поэтому постараемся перечислить ниже важнейшие выводы, которые мы сделали для себя спустя почти год разработки. А самые важные выводы, как правило, о том, что НЕ было сделано.
-
API Gateway как реальный способ снижения затрат
В погоне за уменьшением затрат решено было не вводить в систему компонент API Gateway. Предполагалось, что нашего security-компонента будет вполне достаточно для организации доступа. С одной стороны, это действительно так, но с другой — было бы на порядок удобнее вести разработку, отладку и, что немаловажно, конфигурирование безопасности и взаимодействия микросервисов, будь у нас API Gateway.
-
BFF: меньше «чехарды» с запросами
Как было указано выше, на начальных этапах разработки уровень неопределенности в требованиях был крайне высок. Соответственно ввод практики BFF выглядел на тот момент как некоторая деталь, которую по меньшей мере стоило отложить, а в идеале лучше избежать. На деле оказалось так, что цепочки бизнес-процессов оказались довольно сложными, требующими зачастую последовательного вызова нескольких микросервисов. Как результат, сэкономив на BFF, мы получили либо цепочки вызовов микросервисов один из другого, либо перенос логики BFF на сторону frontend. В первом случае микросервисы оказались нагружены дополнительной логикой, не присущей их бизнес-цели, а во втором произошел частичный перенос бизнес-логики на сторону frontend, что может осложнить потенциальный переход на другой UI/UX в будущем.
-
SAGA как удобный способ управления сложными бизнес-процессами
Исходя из того, что реализованные бизнес-процессы довольно сложные, требующие согласованности данных между микросервисами, имело смысл для подобного проекта заложить реализацию паттерна SAGA. На поздних этапах разработки многократно посещала мысль, что это сильно упростило бы многие аспекты разработки и снизило количество несогласованностей данных, выявленных на этапах отладки системы.
-
Отдельный узел для управления статусами
Еще одна особенность нашей системы – сложная разветвленная статусная модель с необходимостью откатов статусов. Причем статусы одних сущностей влияют на статусы многих других. Это доставило значительное количество проблем при разработке и тестировании.
Если говорить откровенно, то статусы – это наверное самая большая головная боль всего нашего проекта. Одним из способов решения подобной проблемы является вынос управления всей статусной моделью в отдельный микросервис (например, содержащей реализацию некой state machine) и обращение за необходимыми значениями статусов в этот сервис со стороны остальных. Это, как и применение SAGA – одна из наших основных рекомендаций по развитию системы в дальнейшем.
-
Многоуровневое логирование: чем раньше, тем лучше
Уж сколько раз твердили миру… Но раз за разом логи как-то отходят на второй план и в лучшем случае реализуются в недостаточном объеме. В нашем случае мы постарались оперативно взять ситуацию под контроль и реализовать многоуровневое логирование во всех микросервисах в едином виде. Однако часть времени всё равно оказалась упущена. Поэтому однозначно рекомендуем закладывать логирование на самых первых этапах разработки и следить за полнотой логируемой информации, что позволит значительно снизить расходы на поиск причин возможных ошибок.

Выводы
Отчасти выводы были сделаны в предыдущем разделе, однако хотелось бы подвести некоторые итоги и обозначить основные мысли, которые удалось вынести из нашего опыта разработки.
Проект эволюционирует как живой организм.
В нашем случае это было особенно заметно. На каждом этапе был крайне высок уровень неопределенности. Приходилось буквально на каждом шагу адаптироваться к меняющимся условиям. Поэтому в таких условиях требуется максимальное внимание архитектора, которому приходится прогнозировать дальнейшее развитие требований и пытаться организовать систему, максимально устойчивую к этим изменениям.Необходимо отделять адаптеры, даже если они используются в одном месте.
По-другому, не забывать про SOLID, особенно про букву «S». Узкоспециализированные компоненты – действительно мощный инструмент, который вполне оправдывает накладные расходы на разработку и развертывание.Если есть хоть какая-то вероятность множества – делать множество.
Помните про договоры и роли? В нашем проекте это не единственный случай, когда изначально требования утверждали наличие некоторой сущности в единственном числе, а затем переходили к множеству. Здесь задача архитектора – увидеть те элементы системы, которые с высокой долей вероятности могут стать множеством, и сразу же заложить это. Естественно не везде и без фанатизма. Но будучи примененным по назначению, этот подход позволяет не тратить время и усилия на перепроектирование и переписывание кода в будущем.Иметь альтернативы по способам взаимодействия.
В нашей системе заложены сразу несколько способов взаимодействия микросервисов: REST, Kafka, Websocket. В нашем случае это продиктовано требованиями и особенностями системы. Однако на будущее мы бы рекомендовали иметь под рукой шаблон реализации каждого из этих механизмов и при необходимости (например, через те же shared components) иметь возможность быстро ввести их в проект, что позволит в короткие сроки решить многие важные вопросы. Допустим, если система проектируется только для REST, то брокер сообщений может неожиданно пригодиться для механизма инвалидации кэша.Осознанные нарушения некоторых паттернов – вполне себе решение.
Нужно уметь не только соблюдать правила, но и понимать, когда имеет смысл их нарушить. В конечном итоге цель проекта – автоматизация бизнеса клиента, поэтому если перед нами дилемма – выдать очередную версию уже завтра или залезть в отладку и приведение кода к красивому паттерну, то решение должно быть принято в пользу выдачи, ведь именно в этом первоочередная цель разработки. Конечно же, речь идет о критических моментах, и мы ни в коем случае не призываем нарушать общепринятые выработанные IT-сообществом правила повсюду. Однако некоторая гибкость и способность отойти от догмы в экстренной ситуации позволяет выйти из сложной ситуации победителем.Дважды, нет, трижды перепроверять ТЗ.
Это правило в особенности актуально в условиях, когда ТЗ часто меняется и формируется в процессе разработки. В ходе нашего проекта приходилось буквально каждый день на протяжении всей разработки перечитывать ТЗ, задавать множество вопросов аналитикам, заказчику, консультироваться со специалистами в конкретных технологиях… и снова читать ТЗ. И знаете, это обязанность не только архитектора. В нашем случае, так как команда получилась многофункциональная, все разработчики также многократно перечитывали ТЗ, что позволило охватить требования с разных сторон свежим взглядом и задать как можно больше вопросов до начала разработки. И, как следствие, сэкономить драгоценное время.Вопрос «зачем?» творит чудеса.
Говоря о вопросах к ТЗ и к заказчику, нельзя отдельно не упомянуть важность вопроса «зачем?». Крайне важно, увидев требование, ведущее к сложной реализации, потенциально тяжелым для системы изменениям, не бросаться сразу их выполнять, а поинтересоваться у аналитиков и заказчика, зачем это нужно. Как показала практика, в очень существенно числе случаев подобные требования ослаблялись или вовсе отклонялись. Своевременно заданный вопрос «зачем?» способен сильно снизить объем работ и сопутствующие риски.Даже когда времени в обрез, уделять минимальное внимание качеству кода.
Как говорилось выше, на начальных этапах ревью кода – крайне обязательный элемент разработки. На дальнейших этапах мы отчасти ослабили критерии прохождения ревью, но несмотря на цейтнот, не отказались от этого процесса. Ревью кода – первый барьер, который позволяет найти потенциальные ошибки и, по сравнению с последующим тестированием, наиболее дешевый, несмотря на кажущуюся затратность.Во всём важны порядок и дисциплина!
Этим правилом можно обобщить всё вышесказанное. Чем сложнее проект, чем сильнее дефицит времени и ресурсов, тем большее значение приобретает стройность процессов разработки и дисциплина самих разработчиков. В нашем случае дисциплина и огромный уровень ответственности команды, наряду с высоким профессионализмом и самоотдачей, позволил успешно завершить этот далеко не простой проект.
Спасибо за внимание!
Рекомендуем другие статьи от нашего Архитектурного комитета:
Design API First как паттерн проектирования контрактов межсервисного взаимодействия
Как мы внедряли Design API First. Показываем на примере сервиса аутентификации
Интеграция паттерна Design API First в конвейер разработки ПО: наш опыт
Как генерировать модели интерфейсов на основе спецификации на стороне frontend-приложений
Design API First. Кодогенерация Roslyn
Как мы разрабатывали браузерную игру: взгляд со стороны frontend-архитектора
Авторские материалы для разработчиков и архитекторов мы также публикуем в наших соцсетях – ВКонтакте и Telegram.
Комментарии (4)

zubrbonasus
07.11.2023 08:16Если разработчики работают в компании продолжительнок время, почему бы не выбрать Agile и Userstory?

ArchitectSimbirSoft Автор
07.11.2023 08:16Мы работали по Agile, но дело было не только в часто меняющихся требованиях, а в том, что помимо них, проект был с фиксированной длительностью и стоимостью. Если бы не этот фактор, разумеется, Agile решил бы многие проблемы.

Onandoff
07.11.2023 08:16Прикольные выводы стартующие с одной посылки: "улучшить функциональность имеющийся системы " -> Изначальный монолит делал тот же разработчик. Вы где то видите указание на это в статье ? Я - нет.
manyakRus
1) Провалили проект первый раз с монолитом.
2) Провалили проект ещё раз, признание: "Что добавилось и изменилось в процессе работы..." - переводится как : "... поэтому мы не смогли доделать этот проект"
3) "Ротации разработчиков..." - у вас нет ни одного шанса доделать свой проект до конца.