
Даём детальную фабулу кадровых перестановок в OpenAI и Microsoft, рассказываем о Q*, его возможной связи с Q-learning и MRPPS с техническими подробностями и размышляем об искусственном общем интеллекте.
Не так давно мир ИИ потрясли новости о кадровых перестановках в OpenAI: совет директоров компании уволил её генерального директора Сэма Альтмана, самую яркую фигуру в сфере генеративного ИИ. О своей отставке Альтман узнал на онлайн-совещании совета директоров, организованном по инициативе Ильи Суцкевера, главного научного сотрудника OpenAI: «...Не был всегда откровенен в своем взаимодействии с советом, что ограничивает его способность выполнять свои обязанности» – именно так звучит часть формулировки заявления.

На место Альтмана временно пришла Мира Мурати, главный технический директор. Кроме того, кадровые перестановки коснулись и Грега Брокмана, который лишился статуса соучредителя. Инвесторы же, как и рядовые сотрудники, не были готовы к такому развитию событий. Если первых якобы оповестили об отставке «лица OpenAI» за несколько минут до объявления совета директоров, то для последних она определённо стала шокирующей. Случившееся, по версии СМИ, является результатом скрытой конфронтации между Альтманом, выступавшим за активную разработку ИИ, и советом директоров, чья позиция заключалась в более плавном и последовательном развитии искусственного интеллекта.
Меньше чем через день совет директоров OpenAI сменил своё мнение и начал рассматривать вариант возвращения Сэма Альтмана на прежний пост. Спустя сутки ему пришлось посетить офис компании по гостевому бейджу. Цель визита – переговоры с советом директоров. Те должны были согласиться с требованиями Альтмана и вернуть ему кресло генерального директора, чему, казалось, не суждено было случиться:

Тем временем новым «новым» генеральным директором OpenAI вместо Миры Мурати стал Эммет Шир. Раньше он занимал аналогичную должность в Amazon Twitch. Мурати вновь обрела статус технического директора.

Следующее потрясение – более 700 сотрудников компании подписали письмо, где призывали вернуть Альтмана и Брокмана и распустить прежний совет директоров OpenAI. Сами же они планировали последовать за своим идейным лидером в Microsoft, где сейчас занимаются развитием встроенного в Bing чат-бота и работой над DALL-E. И о, чудо! Спустя ещё пару дней OpenAI объявляет о возвращении Альтмана на должность генерального директора. А ещё он формирует новый состав совета директоров, в который входят его председатель Брет Тейлор, Ларри Саммерс и генеральный директор Quora Адам Д’Анджело. Илья Суцкевер, равно как и Таша МакКоли и Хелен Тонер, оставили свои кресла.


Интересно, что всему случившемуся предшествовало несколько событий. Первое – письмо совету директоров от группы исследователей компании. Что было в письме? Загадка. Ясно то, что содержащаяся в нем информация повлияла на решение об увольнении Альтмана. Предположительно, в нём говорится о создании ИИ, который, по мнению членов совета, может представлять реальную опасность. Речь идёт об алгоритме Q* или Q-Star – потенциальном прорыве в сфере искусственного интеллекта.

Второе – заявление Сэма Альтмана на саммите Азиатско-Тихоокеанского экономического сотрудничества мировых лидеров в Сан-Франциско: «За всю историю OpenAI мне уже четыре раза (последний раз – буквально в последние пару недель) доводилось присутствовать в комнате, когда мы как бы отодвигали завесу невежества и продвигали вперед границы открытий, и возможность сделать это - профессиональная честь всей жизни».
Спустя день и было принято решение о его увольнении.
")
На самом деле, неизвестно, как OpenAI развивает свою технологию. Неизвестно и то, как Альтман руководил работой над будущими, более мощными поколениями. Ясно лишь то, что кампания по неразглашению информации работает весьма успешно. Почти.
Теория 1: Q-learning
Q* основывается на методе Q-learning, включающем в себя обучение алгоритма. Он работает по принципу положительной или отрицательной обратной связи для создания игровых ботов и настройки ChatGPT так, чтобы он был более полезным. ИИ может самостоятельно находить оптимальные решения без вмешательства человека, в отличие от текущего подхода OpenAI – обучении с обратной связью от человека (RLHF).

В Q-обучении Q* является искомым состоянием, где агент знает, что надо сделать, чтобы повысить уровень общего ожидаемого вознаграждения с течением времени. С математической точки зрения он удовлетворяет уравнению Беллмана, которое описывает оптимальное значение функции состояния или стратегии в задачах, где решение принимается последовательно во времени. В случае задачи управления, уравнение Беллмана может быть выражено как рекуррентное соотношение, которое связывает оптимальное значение в текущем состоянии с оптимальными значениями в следующих состояниях.

Q- learning отсылает нас к алгоритму поиска A*, который может искать наилучшие пути решения. Например, как в случае с дроблением сложных математических задач на цепочку логических шагов. Это намекает на возможность создания ИИ, способного к более глубокому и стратегическому мышлению. Напоминает о методах, применяемых в системах AlphaGo или AlphaStar, не правда ли? Вспомним поиск траектории токена по дереву Монте-Карло. Этот метод наиболее полезен в программировании и математике, что объясняет информацию о Q* как о прорыве в решении математических задач.
 использует подход UCB (Upper Confidence Bound), который имеет четыре фазы: выбор, расширение, симуляция и обратное распространение.")
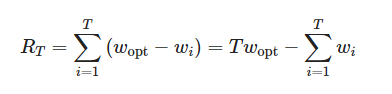
![Основой UCT является решение задачи многоруких бандитов. Эта версия имеет графики для четырёх метрик: вероятность выбора оптимально руки, среднее вознаграждение, суммарное вознаграждение и совокупное сожаление, которое представляет собой матожидание совокупного сожаления. При условии неоптимальной стратегии, оно ограничено снизу логарифмически: E[RT] = Ω (log T).](https://habrastorage.org/getpro/habr/upload_files/94c/6ff/245/94c6ff245e4654b7b45161e69c3d4f22.png "Основой UCT является решение задачи многоруких бандитов. Эта версия имеет графики для четырёх метрик: вероятность выбора оптимально руки, среднее вознаграждение, суммарное вознаграждение и совокупное сожаление, которое представляет собой матожидание совокупного сожаления. При условии неоптимальной стратегии, оно ограничено снизу логарифмически: E[RT] = Ω (log T).")
Также говорилось и о совершенствовании RAG (Retrieval Augmented Generation), результаты которого были не так давно показаны на OpenAI DevDAy. Сначала алгоритмы ищут и извлекают релевантные фрагменты информации на основе подсказки или вопроса пользователя, используя, к примеру, BM25. Далее следует генерация контента языковой моделью, такой как GPT. Она применяет полученный контекст для создания ответов на естественном языке.

Подробный анализ имеющихся отчётов в совокупности с наиболее злободневными проблемами в области ИИ позволяет сделать вывод, что проект, о котором OpenAI говорила в мае, строился на уменьшении логических ошибок, которые допускают крупные языковые модели, к примеру, LLM. Метод контроля процессов, который включает в себя обучение модели ИИ разбивать необходимые шаги для решения задачи, может повысить шанс получения правильного ответа алгоритмом. Так, проект показал, как это может помочь магистрам права, безошибочно решать задачи, где необходимы базовые знания математики.
«Q* может включать в себя использование огромных объемов синтетических данных в сочетании с обучением с подкреплением для обучения магистров права конкретным задачам, таким как простая арифметика. Камбхампати отмечает, что нет никакой гарантии, что этот подход будет обобщен во что-то, что может выяснить, как решить любую возможную математическую задачу», – Суббарао Камбхампати, профессор Университета штата Аризона, который исследует ограничения рассуждений магистров права.
«Магистры права не так хороши в математике, но и люди тоже», – говорит Ын. «Однако, если вы дадите мне ручку и бумагу, то я намного лучше умею умножать, и я думаю, что на самом деле не так уж сложно настроить LLM с памятью, чтобы иметь возможность пройти через алгоритм умножения» – Эндрю Ын, профессор Стэнфордского университета, руководитель лабораторий искусственного интеллекта в Google и Baidu.
Теория 2: MRPPS
Предполагаемая взаимосвязь алгоритма Q* и системы MRPPS (Maryland Refutation Proof Procedure System), которая состоит из нескольких методов: двоичного разрешения и факторинга, набора вспомогательных средств, P1-Deduction, линейного разрешения, входного разрешения, линейного разрешения с функцией выбора, комбинации систем логического вывода и парамодуляции. Самое явное поле применения – вопросно-ответная система. Суть состоит в объединении семантической и синтаксической информации, что может означать прогресс в дедуктивных способностях ИИ.
 для использования. Кроме того, MRPPS позволяет одновременно использовать множество комбинаций вышеуказанных систем логического вывода, хотя в некоторых случаях результирующая система логического вывода может быть неполной. Например, если бы set-of support и Pl-deduction использовались одновременно, можно было бы гарантировать полноту только в том случае, если предполагаемая теорема вместе со всеми положительными предложениями имела поддержку. Тык.")
Наиболее просто объяснить это можно, вспомнив Шерлока Холмса, героя книг Артура Конан-Дойля. Вымышленный детектив собирает подсказки в виде семантической информации и связывает их с помощью синтаксиса. Подобным образом и работает Q из MRPPS.
Стоит отметить, что в OpenAI не объяснили структуру и даже не подтвердили и не опровергли слухи о существовании Q*. Но нельзя не принимать во внимание, что, возможно, OpenAI стала ближе к модели, понимающей задачу и без текстового запроса.
Последствия
В случае, если Q* – апгрейднутая форма Q-learning, то ИИ улучшит свою способность к автономному обучению и адаптации. Это может найти применение в сферах, где необходимо принятие решения за доли секунды в условиях постоянно меняющихся значений. В области автономных транспортных средств, к примеру.
Если же Q* относится к алгоритму Q из MRPPS, то искусственный интеллект будет способен на более глубокие дедуктивные рассуждения. Например, в сферах, где задействовано аналитическое мышление: медицинская диагностика, юридический анализ и т.п.
При любых обстоятельствах, скачок в развитии ИИ весьма правдоподобен. Однако вместе с этим возникает ряд новых этических и правовых вопросов, затрагивающих аспекты безопасности и конфиденциальности. Нельзя не отметить и экономические последствия: в очередной раз вспоминается пресловутое сужение кадрового рынка.
А AGI?
Не стоит забывать, что конечная цель исследований в области ИИ в виде AGI пока ещё недостижима, так как внятной альтернативы когнитивным человеческим способностям ещё нет, а современный искусственный интеллект нельзя назвать полностью адаптивным и универсальным. Пока что алгоритм Q* не способен самоидентифицироваться и работает исключительно в пределах начальных данных, а также заданных алгоритмов.
Заключение
Не так давно технические форумы захлестнул термин вероятности того, что искусственный интеллект уничтожит человечество. Имя ему – p(doom). Он представляет собой стобалльную шкалу. Чем больше процентов на ней вы себе присваиваете, тем больше вы убеждены в беспомощности человека перед ИИ. Пишите ваше значение, обосновав его, конечно. Будет интересно. Не так интересно, как если ИИ захватит человечество, но всё же.

Ждем вас в комментариях и спасибо за прочтение!
Автор: Влад Смирнов
DenSigma
Независимо от того, какую выгоду несет АИ и насколько низка вероятность p(doom), разработки АИ необходимо прекратить и запретить. Обоснование простое. При запрете АИ проигрыш небольшой и конечный (отсутствие ботов и картинкогенераторов). Выигрыш - мы сохраняем свое существование. Выигрыш при дальнейшем развитии АИ - небольшой и конечный (те самые картинкогенераторы). Проигрыш же бесконечно велик - исчезновение человечества.
Tiriet
а чем это отличается от атомной бомбы? в случае появления управляемого ИИ "у них" проиграет не все человечество, а только "мы", а в случае появления управляемого ИИ у "нас"- проиграет не все человечество, а только "они". Следовательно, "они" не могут отказаться от возможности получить себе управляемый ИИ, и вынуждены развивать ИИ вообще ( и может быть - не управляемый). И мы тоже вынуждены развивать управляемый ИИ, который внезапно может выйти из под контроля. Ну так и атомную бомбу террористы могут стытрить- и ниче, риск велик, но боеголовок уже десятки тысяч по всему миру запасено. Ваша стратегия (а давайте не будем строить "Звезды смерти") хороша, когда все игроки честные. Но все игроки не честные, а потому строят все, кто может и не может.
QviNSteN
Несколько сотен боеголовок потеряно даже)
MaxMxMz
"Джина" можно остановить только ценой входа в технологию, как с атомной бомбой - порог входа достаточно высок. Обязательно найдется кто-нибудь, кто не смотря на все запреты будет разрабатывать технологию дальше, не обязательно из-за возможной прибыли, но с верой в самые радужные перспективы.
nemajo
Независимо от того, какую выгоду несет Интернет и насколько низка вероятность Y2K, разработки Интернета необходимо прекратить и запретить. Обоснование простое. При запрете Интернета проигрыш небольшой и конечный (отсутствие ботов и видео с котиками). Выигрыш - мы сохраняем свой здравый смысл. Выигрыш при дальнейшем развитии Интернета - небольшой и конечный (те самые видео с котиками). Проигрыш же бесконечно велик - сессионные игры.
StriganovSergey
Человечеству в любом случае уже конец в том биологическом виде, в котором существует сегодня.
Свое дело сделает генная инженерия, нейроинтерфейсы, экзоскелеты, встроенные в тело различные вспомогательные модули ( от простых датчиков уровня сахара в крови, до модулей, улучшающих различные процессы). AGI лишь сделает этот переход более быстрыми и эффективным.
Конечно, быть может, какие-то дикари останутся жить без таких изменений.
Подобно тому, как сегодня какие-то племена живут в джунглях, с луками и стрелами.
Так и эти "новые дикари" будут жить - пусть даже и в городах, с машинами и даже с самолетами.
Но в каком-то своем, остановившемся навсегда, времени.
ParaMara
Коммент рисует столь яркую и живую картину, что я её узнал, я читал об этом.
pavel_kudinov
не переживайте, скоро цикл повторится и мы снова откатимся к богоугодному уровню существования
MMS02E09 Про Бога из машины (осторожно, ненормативная лексика)
https://www.youtube.com/watch?v=gYaBiYoOqoo