
TL;DR
Я написал инструмент для создания постеров с маршрутами общественного транспорта, разные цвета для разных видов транспорта, толщина и прозрачность линий соответствуют количеству поездок на сегменте маршрута. Репозитарий тут:
https://github.com/dragoon/cityliner
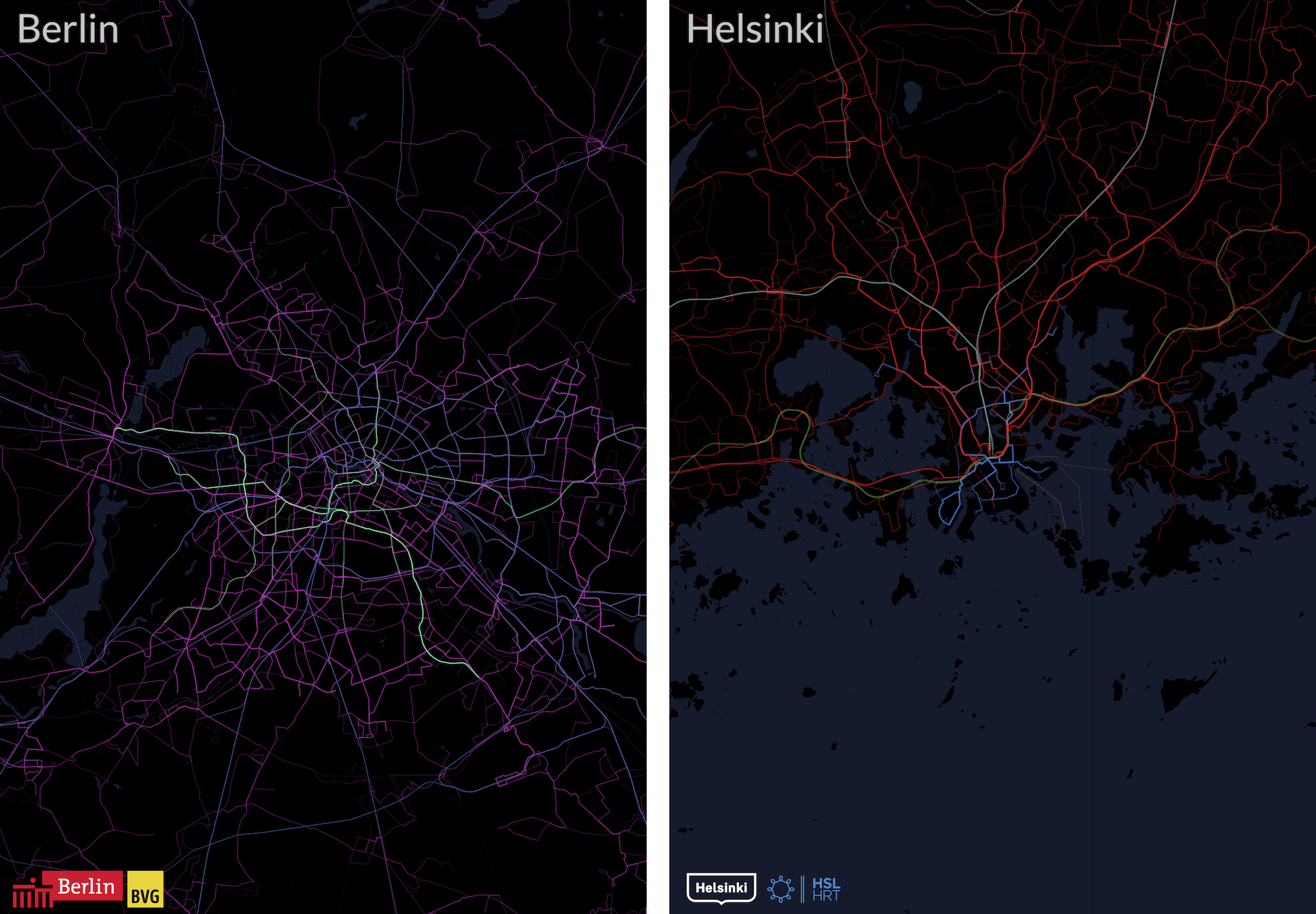
История
Около 10 лет назад Майкл Мюллер написал оригинальный код https://github.com/cmichi/gtfs-visualizations на смеси JavaScript/Node.js для обработки GTFS данных и Processing для отображения в PDF. Мне понравились эти визуализации, и я доработал его код, добавив возможность создания постера, ограничения изображения по радиусу, и переделал обработку данных так, чтобы файлы не загружались полностью в память (это было проблематично для городов даже среднего размера).
Пару месяцев назад я переписал этот проект c нуля на питоне, добавил цветовые темы и отображение водоемов, автоматизировал создание постера с иконками городов.
Ниже подробнее о том как это работает.
GTFS данные
GTFS (General Transit Feed Specification) — формат данных для описания маршрутов общественного транспорта. Изначально он был разработан Google для своих карт, сейчас де-факто стандарт для всех операторов общественного транспорта. Есть статичные (static) и real-time версии.
Здесь нас интересует только статичная версия, в которой присутствует файл shapes.txt. Это опциональный файл, и не все операторы его предоставляют, но именно в нем содержатся географические координаты маршрутов в виде полилиний.
Входные параметры
Для генерации постера необходимы следующие параметры:
Координаты центра карты (широта/долгота).
Размер постера (высота/ширина в пикселях).
Максимальное расстояние по Y (км): расстояние по X вычисляется пропорционально размеру постера.
Обработка GTFS
Обработка поездок (trips)
Проходимся по всем поездкам (trips) в GTFS, считая количество поездок на каждой физической линии маршрута (shape_id ) и сохраняя тип транспорта (route_type):
def _get_trips_and_routes(self) -> Tuple[dict, dict]:
route_id_types = self._get_route_id_types()
route_types = {}
# count the trips on a certain id
trips_on_a_shape = defaultdict(lambda: 0)
for shape_id, route_id in self._parse_trips():
trips_on_a_shape[shape_id] += 1
route_type = route_id_types[route_id]
if shape_id not in route_types:
route_types[shape_id] = route_type
return route_types, trips_on_a_shape
# route_types = {"shape_id": route_type, ...}
# trips_on_a_shape = {"shape_id": N_trips, ...}Обработка физических линий (shapes)
Разбиваем shapes на последовательности, исключая те, что выходят за пределы заданного расстояния от центра:
def _get_sequences(self, center_point: Point, max_dist: MaxDistance) -> dict:
logging.debug("Starting shape iteration...")
sequences = defaultdict(dict)
for shape_id, shape_pt_lat, shape_pt_lon, shape_pt_sequence, shape_row in self._parse_shapes():
# check out of boundaries
if is_allowed_point(Point(float(shape_pt_lat), float(shape_pt_lon)), center_point, max_dist):
sequences[shape_id][shape_pt_sequence] = shape_row
return sequences
## sequences = {"shape_id": {"1": {lat/lon/...}, "2": {lat/lon/...}, ...} , ...}Генерация сегментов
Преобразуем данные, оставляя только число поездок на сегменте, его координаты и тип транспорта:
segments.append({
"trips": trips_n,
"coordinates": pts,
"route_type": route_type
})
## segments = [{"trips": N_trips, "coordinates": [{lat/lon}, ...], "route_type": route_type}, ...]Параллельно считаем максимальное/минимальное количества поездок на сегментах и ограничительную рамку (bounding box):
if trips_n > max_trips:
max_trips = trips_n
if trips_n < min_trips:
min_trips = trips_n
for seq, shape in shape_sequences.items():
y = float(shape['shape_pt_lat'])
x = float(shape['shape_pt_lon'])
min_left = min(x, min_left)
min_bottom = min(y, min_bottom)
max_top = max(y, max_top)
max_right = max(x, max_rightГенерация промежуточного файла
Конвертируем широту/долготу сегментов в координаты по x, y (в пикселях):
def coord2px(lat: float, lng: float, bbox: BoundingBox):
coord_x = bbox.width / 2 + (lng - bbox.center.lon) * bbox.scale_factor_lon
coord_y = bbox.height / 2 - (lat - bbox.center.lat) * bbox.scale_factor_lat
return {'x': int(coord_x), 'y': int(coord_y)}Так как размеры городов обычно значительно меньше размера Земли, то я использую простую проекцию: центр прямоугольника (0,0) соответствует координатам центра карты (из входных параметров), координаты остальных точек вычисляются от центра через коэффициенты масштабирования широты и долготы:
@dataclass(frozen=True)
class BoundingBox:
...
@property
def scale_factor_lat(self):
return self.render_area.height_px / max(abs(self.center.lat - self.top),
abs(self.center.lat - self.bottom))
@property
def scale_factor_lon(self):
return self.render_area.width_px / max(abs(self.center.lon - self.left),
abs(self.center.lon - self.right))
Грубо говоря, если у нас широта от 50 до 51, а пикселей 1000, то 1 градус широты будет линейно спроецирован в 1000 пикселей.
Далее сохраняем все сегменты в промежуточный файл с тремя колонками: количеством поездок, типом транспорта и спроецированными координатами.
Водоемы
Данные по границам водоемов берутся из OpenStreetMap.
Моря и океаны читаются напрямую из файла с полигонами от OpenStreetMap через GeoPandas и фильтруются по ограничительной рамке с помощью shapely:
import geopandas as gpd
from shapely.geometry import box
water_gdf = gpd.read_file('oceans/water_polygons.shp')
bbox = box(bbox_orig.left, bbox_orig.bottom, bbox_orig.right, bbox_orig.top)
filtered_water_gdf = water_gdf[water_gdf.geometry.intersects(bbox)]Файл с полигонами можно скачать здесь: https://osmdata.openstreetmap.de/data/water-polygons.html (WGS84 Projection).
Реки, озера и прочие ручейки забираются сразу через Overpass Turbo API по той же рамке (так как данных обычно немного):
overpass_url = "<https://overpass-api.de/api/interpreter>"
query = f"""
[out:json][bbox:{bbox.bottom},{bbox.left},{bbox.top},{bbox.right}];
(
relation["natural"="water"]["water"~"lake|river|pond|reservoir|stream|canal"];
way(r);
way["natural"="water"]["water"~"lake|river|pond|reservoir|stream|canal"];
);
out tags body;
>;
out tags skel qt;
"""
response = requests.get(overpass_url, params={'data': query})
Затем все водоемы сохраняются вместе в JSON формате.
Постер
Оригинальный код использовал встроенные библиотеки от Processing для создания и отрисовки маршрутов в PDF, на питоне я нашел библиотеку ReportLab, которая имеет подходящий набор функций.
Небольшой отличие ReportLab в том, что все размеры указываются в физических единицах (миллиметры/дюймы), в то время как я конвертирую географические координаты в пиксели, поэтому все элементы нужно отмасштабировать:
c = canvas.Canvas(str(self.out_path), pagesize=(A0[0], A0[1]))
c.scale(A0[0] / self.render_area.width_px, A0[1] / self.render_area.height_px)Водоемы
ReportLab накладывает объекты друг на друга в порядке отрисовки, поэтому водоемы рисуем первыми. Сначала полностью заливаем область внутри внешних границ водоема выбранным цветом:
for body in water_bodies:
points = [coord for point in body["nodes"] for coord in (point["x"], point["y"])]
# Add a Polygon or any other shapes to the Drawing
if len(points) > 2:
polygon = Polygon(points, fillColor='#0e142a')
d.add(polygon)
Затем заливаем острова (interiors) черными полигонами поверх:
# add islands with black on top
if "interiors" in body:
for interior in body["interiors"]:
int_points = [coord for point in interior for coord in (point["x"], point["y"])]
if len(int_points) > 2:
polygon = Polygon(int_points, fillColor='#000000')
d.add(polygon)Маршруты транспорта
После этого отрисовываются собственно маршруты транспорта в виде полилиний.
Каждому типу транспорта соответствует определенный цвет из заданной палитры. Толщина линии пропорциональна логарифму от числа поездок, а прозрачность вычисляется как число поездок на сегменте, делённое на максимальное число поездок на карте, но не меньше 0.2:
factor = 1.7
stroke_weight = math.log(float(trips) * factor) * 3
if stroke_weight < 0:
stroke_weight = 1.0 * factor
alph = 100 * (float(trips) / max_trips)
if alph < 20.0:
alph = 20.0
Для водных маршрутов прозрачность линии фиксируется на 0.4, так как их частота обычно существенно меньше других.
Текст и иконки города
Напоследок вставляем иконки города, региона и/или транспортной компании и название города/места для придания постеру законченного вида:

На будущее
Было бы интересно добавить эффект затухания (fade out) по краям постера.
Пока что единственный способ, который я нашел — растеризация постера и последующее наложение маски с помощью Pillow. Это работает, но размер изображения на диске получается существенно больше из-за растеризации. Кроме того, текст и иконки на краях постера тоже “затухают”, поэтому нужно изменить последовательность генерации и добавлять текст и иконки уже с помощью Pillow после наложения маски.

Про установку и запуск можно прочитать в Readme к репозитарию: https://github.com/dragoon/cityliner
Каталог доступных GTFS данных можно посмотреть здесь: https://github.com/MobilityData/mobility-database-catalogs, хотя там не указано наличие файла shapes.txt в датасете.
Комментарии (9)

VadimGus
14.12.2023 22:30Роман, спасибо. А ваша версия на Javascript доступна?

black_bunny Автор
14.12.2023 22:30Не совсем понял вопрос, вы имеете в виду старая версия, которая была написана на NodeJS + Processing? Да, она тоже доступна здесь: https://github.com/dragoon/gtfs-visualizations
ebt
А насколько сложно было бы завернуть в веб-сервис? Типа, вводишь название своего города, а оно тебе генерит такой красивый постер.
velon
Наверняка не скажу, но вероятно всё упирается в "толщина линии пропорциональна логарифму от числа поездок", - где бы взять такое API которое по любому городу такую инфу выдаст, за бесплатно ещё?!
black_bunny Автор
Это как раз-таки в моем коде считается)
velon
Если оно присутствует в GTFS данных, разве нет? Которые ещё заранее надо где-то взять
black_bunny Автор
Вообще говоря файл c поездками должен присутствовать всегда, но конечно не у всех городов есть GTFS датасеты
velon
"не у всех городов есть GTFS датасеты" - вот, мой комментарий был как раз про это. Видимо сформулировал неправильно, подсчитать логарифм то конечно проблемы нет, если есть на чём считать
black_bunny Автор
Я тоже думал об этом, добавленная сложность на мой взгляд вот в чем:
Прикрутить поиск по доступным GTFS датасетам и определить начилие в них shapes.txt
Скачивать и сохранять эти датасеты куда-то (S3?) чтобы не скачивать каждый раз, в том числе файл в водоемами от OpenStreetMap
Кэшировать промежуточные файлы (в соответствии с входными параметрами), так как обработка больших датасетов вычислительно довольно интенсивная
Завернуть во Flask или Django наверное не так сложно если есть опыт.