
Чтобы разрабатывать новые стратегии и укреплять позиции на рынке, компании необходимо апеллировать к структурированным и всегда актуальным данным. Для хранения, эффективного анализа данных и формирования единой версии правды внедряют корпоративные хранилища данных (Data Warehouse, DWH).
Зачем тратить время на выбор методологии построения DWH? Крайне важно правильно выбрать методологию моделирования данных для хранилища еще на этапе проектирования, это поможет обеспечить необходимый уровень гибкости и масштабируемости, а также позволит синхронизоваться с поставленными бизнес-задачами.
DWH может быть реализовано в одной из трех наиболее популярных моделей:
Снежинка
Data Vault 2.0
Anchor Modeling
C точки зрения экономической выгоды методологии можно оценивать по критериям:
Общая устойчивость
Расходы на поддержание
Расходы на развитие
Уровень необходимого для поддержки специалиста
Удобство документации
Простота командной работы
Для оценки методологий используем структуру TPC-H, стандартный тест для проверки аналитических хранилищ. Это синтетические данные, которые эмулируют реальную схему данных для бизнеса.

Снежинка
Снежинка - самый старый стиль проектирования DWH, имеет самый низкий порог входа среди приведенных выше методологий и подходит для большинства бизнесов. Представлена таблицей фактов, соединенной с таблицами измерений, использует нормализованные данные.
Снежинка лучше всего подходит для малых и средних проектов, так как универсальна и не несет больших рисков при поддержке, но менее адаптирована к изменению данных внутри больших таблиц.
Плюсы Снежинки
Высокая устойчивость, легко настроить проверки на консистентность (согласованность) и соответствие данных
Простая структура данных, хорошо соотносящаяся с доменной моделью, позволяет сократить расходы на поддержание и развитие
Модель остается понятной, даже в ситуациях, когда процессы документации не соответствуют стандартам, если имена таблиц и столбцов выбраны корректно. Документацию легко читать и править.
Минусы Снежинки
Модель не подходит для крупных проектов или для проектов с быстро меняющейся структурой данных (подключение новых источников, отключение старых источников). При создании новых источников взамен старых могут быть трудности с формированием корректных таблиц фактов.
При внесении и добавлении данных в хранилище требуется согласование с другими сотрудниками
Снижается производительность запросов - каждый запрос должен пройти несколько соединений таблиц

После тестирования с помощью TPC-H Снежинка почти полностью соответствует по структуре изначальным данным, за исключением нормализации и сформированных в результате обработки данных новых технических полей.
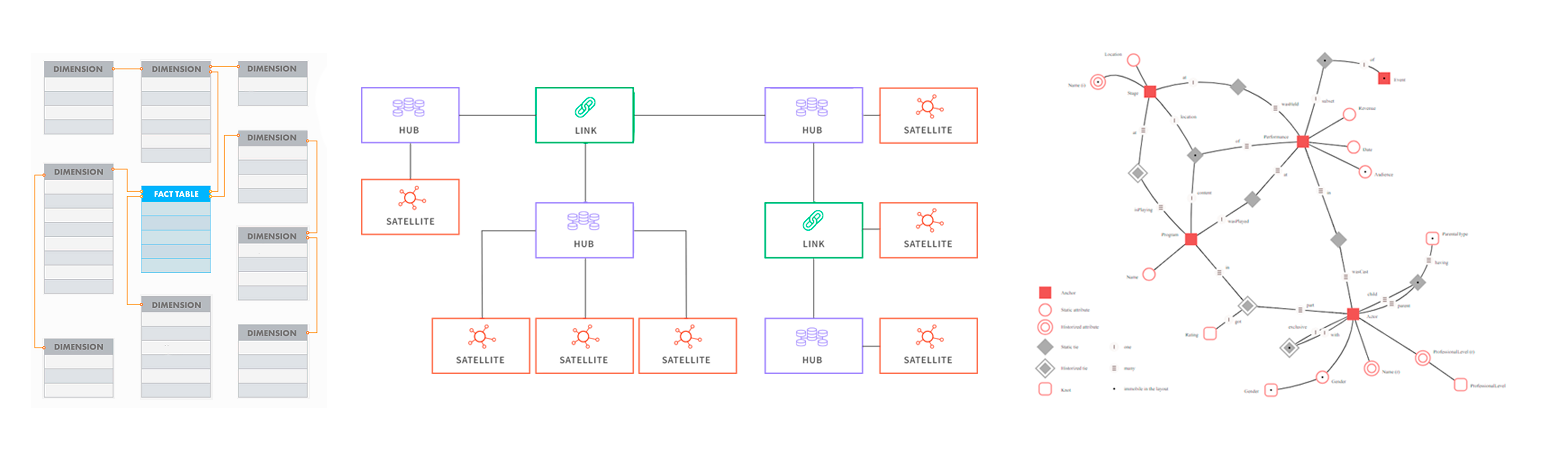
Data Vault 2.0
Data Vault 2.0 - гибкая методология, которая позволяет хранить большие объемы данных и отслеживать их изменения во времени.
Предназначена для обеспечения максимально возможной параллельной загрузки, поэтому очень крупные реализации могут масштабироваться без серьезной перестройки, но достигается это путем усложнения взаимосвязей данных и структур таблиц.

Данные в Data Vault представлены в виде трех сущностей:
Хаб (hub) – бизнес-сущность, например клиент, продукт, заказ. Связывается только с Линком или с Сателлитом. Хаб-таблица содержит несколько полей: натуральные ключи сущности, суррогатный ключ, ссылка на источник записи и время добавления записи.
Линк (связь, link) – представление отношений между Хабами. Линки строятся в виде таблиц «многие ко многим» и содержат ссылки на суррогатные ключи связанных Хабов.
Сателлит (satellite) - изменяемые атрибуты сущностей, контекстные данные для хаб-таблицы, связанные с Хабами и Связями по принципу «один ко многим».
Плюсы Data Vault
Интуитивно понятная структура, которая позволяет сформировать витрины под любые потребности бизнеса
Простой доступ к анализу - первые верхнеуровневые отчеты доступны уже после загрузки Хабов и Связей
Можно независимо разрабатывать смежные источники и легко заменять их, так как данные почти полностью отвязаны друг от друга
Минусы Data Vault
Большое количество таблиц и join'ов, которые повышают риск ошибок и замедляют выполнение запросов относительно традиционных DWH, где таблицы более денормализованы
Сложность выстраивания проверки данных из-за большого количества сущностей и сложных связей между ними
Методология хорошо задокументирована, но требует от специалиста богатого абстрактного мышления, дополнительных навыков и знаний особенности работы специфических функций, например хеширования
После теста на TPC-H структура данных стала сложнее. Появились таблицы, изолирующие данные от бизнес-логики. При изменениях в бизнес-логике не нужно перестаивать уже готовое хранилище, а можно создавать новые таблицы Сателлиты и прикреплять их к Хаб-таблицам и Связям в существующей модели.
Этот подход снижает стоимость добавления новых источников и замены старых, но увеличивает затраты на поддержку. Из-за большого количества объектов могут возникнуть трудности с их документированием, обновлением данных, поиском ошибок.
Anchor Modeling (Якорная модель)
Anchor Modeling – гибкий метод моделирования, подходящий для работы с постоянно растущими объемами данных, которые меняются по структуре или содержанию. Якорная модель позволяет воспользоваться преимуществами высокой степени нормализации, при этом оставаясь интуитивно понятной.
Якорная модель включает конструкции:
Якорь – представляет собой сущность или событие, содержит суррогатные ключи, ссылку на источник и время добавления записи
Атрибут – используется для моделирования свойств и характеристик якорей, содержит суррогатный ключ якоря, значение атрибута, ссылку на источник записи и время добавления записи
Связь – моделирует отношения между якорями
Узел – используется для моделирования общих свойств (состояния)
Плюсы Anchor Modeling
Нормализованная модель, которая эффективно обрабатывает изменения и позволяет масштабировать хранилища данных без отмены предыдущих действий
Можно независимо разрабатывать смежные источники, так как данные почти полностью отвязаны друг от друга
Значительная экономия места в связи с отсутствием нулевых значений (null) и дублирования
Минусы Anchor Modeling
Создает высокую нагрузку на базу даже для основных видов запросов
Сложно настроить проверку данных, так как модель состоит из большого количества сущностей со сложными связями
Большое количество таблиц и join'ов, повышающих риск ошибок
Требует постоянной поддержки и документирования, так как документация уникальна для каждого бизнеса. Специалистам необходимы дополнительные знания для понимания документации.
Anchor Modeling представляет возведенную в абсолют нормализацию данных: одна таблица - один атрибут (характеристика). Обеспечивает низкую стоимость добавления новых атрибутов даже на данных объемом в несколько десятков терабайт, но делает таблицу абсолютно не читаемой для человека. Усложняет процессы по поддержанию документации в актуальном состоянии, повышает стоимость разработки, так как увеличивает порог входа в проект и количество задач для обслуживания.
Выбор методологии для DWH
Каждая из методологий имеет свои уникальные особенности и характеристики, отвечает определенным задачам бизнеса и при верном выборе позволяет ускорить разработку и понизить стоимость владения DWH.
При выборе методологии для проектов специалисты Qlever Solutions оценивают объем поступающих новых данных, перспективы изменения (текучесть) и появления новых источников данных. На основе описанных ранее критериев мы разработали алгоритм выбора методологии построения DWH:

При необходимости возможен выбор гибридной модели. Гибрид подразумевает использование методологии Снежинка для базовой разработки, а при появлении сложностей с интеграцией и на проблемных направлениях частично внедряется подход Data Vault.
Так как исходные данные хранятся на Staging слое, можно полностью перейти на новую методологию, без потери данных и с минимальными изменениям в ELT/ETL процессах. Возможен органический переход от более простой модели Снежинка к Data Vault или Anchor Modeling для масштабирования и достижения необходимой гибкости хранилища.
Ситуации, в которых выбранная модель данных не эффективна и приводит к расходам, не всегда очевидны сразу. Компании могут годами строить корпоративное хранилище и тратить бюджеты на систему, которая не сможет быть органически встроена в дальнейшую стратегию развития бизнеса.
Чтобы такого не произошло, необходимо учитывать все имеющиеся бизнес-процессы, пользователей и источники данных в компании, а также перспективы их роста. Или можно обратиться к экспертам с опытом внедрения DWH, которые помогут выбрать оптимальную методологию проектирования или помочь с миграцией на новую модель.
Комментарии (7)

SSukharev
16.01.2024 13:08DV не предназначен для того, что бы строить по ней отчёты- это слой хранения данных. Что бы строить отчёты ещё нужен слой представления данных - это витрины. Главная цель DV - хранить данные и историю изменений данных в источнике. Строится она от источника данных, т.е. снизу вверх, строится как "предметно-ориентированое хд" иногда об этом забывают, подходят к моделированию ХД технически, лепят сущности без разбору, видят связь между двумя таблицами - тяп ляп слепили линк, а к линку ведь ещё нужна пара сателлитов но об этом никто не знает. Потом бросают - не получилось, плохая технология давайте по Инмону ХД теперь строить, или даталайк.
Анкер был разработан и впервые применен для страховой компании, где бизнес постоянно рос. Строится она от бизнес-требований к отчётам т.е.сверху вниз.
Есть ещё смесь dv и анкера, ещё её называют голландской моделью данных, применяется для слабосвязанных источников данных.

EvgenyVilkov
16.01.2024 13:08Аплодирую стоя, коллега!
Есть две стадии DV. Первая - сделал и потом написал статью на хабре, добавил в резюме и рассказал на конференции. Вторая - охренел от и начал лепить витрины в обход DV. Правда "забыл" всем рассказать что ты забил на DV.
EvgenyVilkov
16.01.2024 13:08К минусам якорной модели я бы добавил еще - очень выскую нагрузку на словарь данных. Посчитайте сколько у вас будет объектов если вы загрузите 10тыс таблиц источника по 30 атрибутов в каждом. Ведь ваш фреймворк загрузки будет работать со словарем данных очень интенсивно при таком подходе.
EvgenyVilkov
16.01.2024 13:08+1олды помнят что изначально DV разрабатывали не для "гибкости", а потому что в те годы СУБД и аппаратное обеспечение с трудом переваривали изменения. Идея DV была в том, чтобы атрибуты измерений разбивать по сателитам в зависимости от временной гранулярности изменений. Те, условно, те что загружаются\обновляются раз в час в одном сателите, те что раз в 4 часа в другом, раз в сутки в третьем. В теории это позволяло не обновлять длинную строку очень часто. С приходом эры MPP необходимость в таком подходе просто отпала.

am-habr
16.01.2024 13:08При написании этой статьи присутствует конфликт интересов. Судить можно по выводу, который не является нейтральным: исходя из картинки, фактически выбор осуществляется между anchor и DV. При этом минусом обоих указана сложность проверки качества данных. Сложно себе представить такое хранилище в финансовом секторе.
А что с другими, динамично развивающимися? Успех развития сложно представить с плохим качеством данных. Может поэтому куда ни глянь - сплошное надурилово, может оттого и нужно динамично развиваться, чтобы надурилово не бросалось в глаза.

Shippo
16.01.2024 13:08к сожалению картинки для последних двух моделей нечитаемые. я хотела понять чем там отличается представление данных от выбора модели - но по этим картинкам это не поймешь.
klyusba
Не понятно как связан объем поступающих новых данных и Anchor modeling. Классический пример, click stream, данных очень много, и скорее всего это будет одна таблица, никак не нормализованная.
Кажется, большие таблицы противопоказаны для Anchor modeling. База просто их не соединит.
Тезис про значительную экономию места в связи с отсутствием нулевых значений (null) и дублирования у Anchor modeling тоже сомнительный. Это скорее характерно для колочного хранения, и без дублирования ключа у каждого атрибута.
Думаю, Anchor modeling это про небольшие хранилища в смысле объема, но с большим разнообразием атрибутов, их источников и "текучести".