

При разработке больших web-проектов нам часто приходится взаимодействовать с API сторонних или внутренних микросервисов. Когда количество таких взаимодействий растёт, настройки вызовов к другому API и подробности самих вызовов кратно множатся и могут растекаться по проекту.
В Домклике у нас микросервисная архитектура, и каждому сервису приходится взаимодействовать с десятком других. Чтобы межсервисное взаимодействие было предсказуемым, надёжным, удобным и отслеживаемым, мы следуем ряду практик при разработке, и в этой статье я расскажу вам о них.
Примечание: примеры кода показаны для Ruby, но подход можно перенести и в любые другие языки программирования, где есть взаимодействие с API других микросервисов.
1. Выберите единый подход к конфигурации API-клиентов в рамках проекта
Выделите инициализацию подключения к сторонним API со всеми настройками в какую-то единую точку в проекте. Это может быть директория, отдельный репозиторий или набор стандартизированных библиотек под каждую интеграцию. Такой подход позволит не повторять целый ряд настроек при каждом вызове API, а также держать настройки подключений в едином виде и формате. Новому разработчику будет понятно, где находится всё, что касается исходящих подключений, и где их настраивать.
2. Выберите оптимальную библиотеку для своего стека
При выборе библиотеки для взаимодействия с API следует обращать внимание на удобство использования, конфигурируемость, популярность, быстродействие и возможность своих расширений.
К примеру, сравнительная таблица для Ruby:
Имя клиента |
К-во звёзд |
К-во Issues |
Последний коммит |
Комментарий |
|---|---|---|---|---|
httparty |
Больше 5700 |
40 |
неделю назад |
Для новичков, слабо конфигурируемый. |
rest-client |
Больше 5200 |
88 |
5 лет назад |
Простой, но не гибкий. |
faraday |
Больше 5600 |
31 |
2 месяца назад |
Умеет в retry из коробки. |
http.rb |
Около 3000 |
81 |
месяц назад |
Нет конфигурации retry (повторных попыток). |
Такие же таблицы можно поискать в интернете для любого языка программирования.
3. Конфигурируйте подключения через ENV-переменные
Передавайте настройки в ваш API-клиент из переменных окружения (environment, ENV), чтобы легко управлять настройками в разных средах разработки и развёртывания. Если API-клиентов в рамках проекта несколько, то желательно соблюдать единый формат и правила именования переменных, чтобы можно было быстро ориентироваться по тому, где лежит настройка. К примеру, если вам срочно нужно увеличить тайм-аут на скачивание файла из хранилища.
Сам же факт хранения настройки в ENV-переменной позволит запустить ваше приложение в различных контурах (локальном, тестовом, prod) без конструкций if/else.
При локальной разработке под каждый язык программирования есть различные библиотеки, позволяющие хранить локальный файл с секретными настройкам. Он добавляется в .gitignore, чтобы не попадать в систему контроля версий. Для Ruby пример таких библиотек — dotenv, config.
Пример JSON-файла с переменными окружения:
{
"SETTINGS_AUTH_API_ENDPOINT": "http://prod.kubernetes.internal/auth-service/",
"SETTINGS_AUTH_API_TOKEN": "d1312-3121-2311-3211-321d3a1",
"SETTINGS_AUTH_API_OPEN_TIMEOUT": "3",
"SETTINGS_AUTH_API_READ_TIMEOUT": "3",
"SETTINGS_IMAGER_API_ENDPOINT": "http://prod.kubernetes.internal/imager-service/",
"SETTINGS_IMAGER_API_BASIC_LOGIN": "loginchik",
"SETTINGS_IMAGER_API_BASIC_PASSWORD": "passwordchik",
"SETTINGS_IMAGER_API_OPEN_TIMEOUT": "3",
"SETTINGS_IMAGER_API_READ_TIMEOUT": "30",
}Что касается домена, в базовые настройки стоит выносить основной путь к сервису, а всё, что может меняться от запроса к запросу, лучше объявлять уже в отдельных константах.
Т. е. в базовую конфигурацию выносим domain.com или domain.com/base_path, а дальнейший относительный путь, к примеру /api/v1/stars, объявляем уже в константах.
4. Настройте тайм-ауты
Есть несколько видов тайм-аутов. В случае взаимодействия по API нам интересны на соединение и на запрос. Установка тайм-аута позволит соединению не зависнуть и не занимать рабочие потоки на продолжительное время. Особенно это важно там, где обращение к стороннему API происходит в рамках внешнего вызова от клиента. И если не настроить таймауты, то в случае проблем с сервисом или сетью клиент будет ждать очень долго.
Domclick::NewApi::Client.configure do |config|
config.open_timeout = 5
config.read_timeout = 30
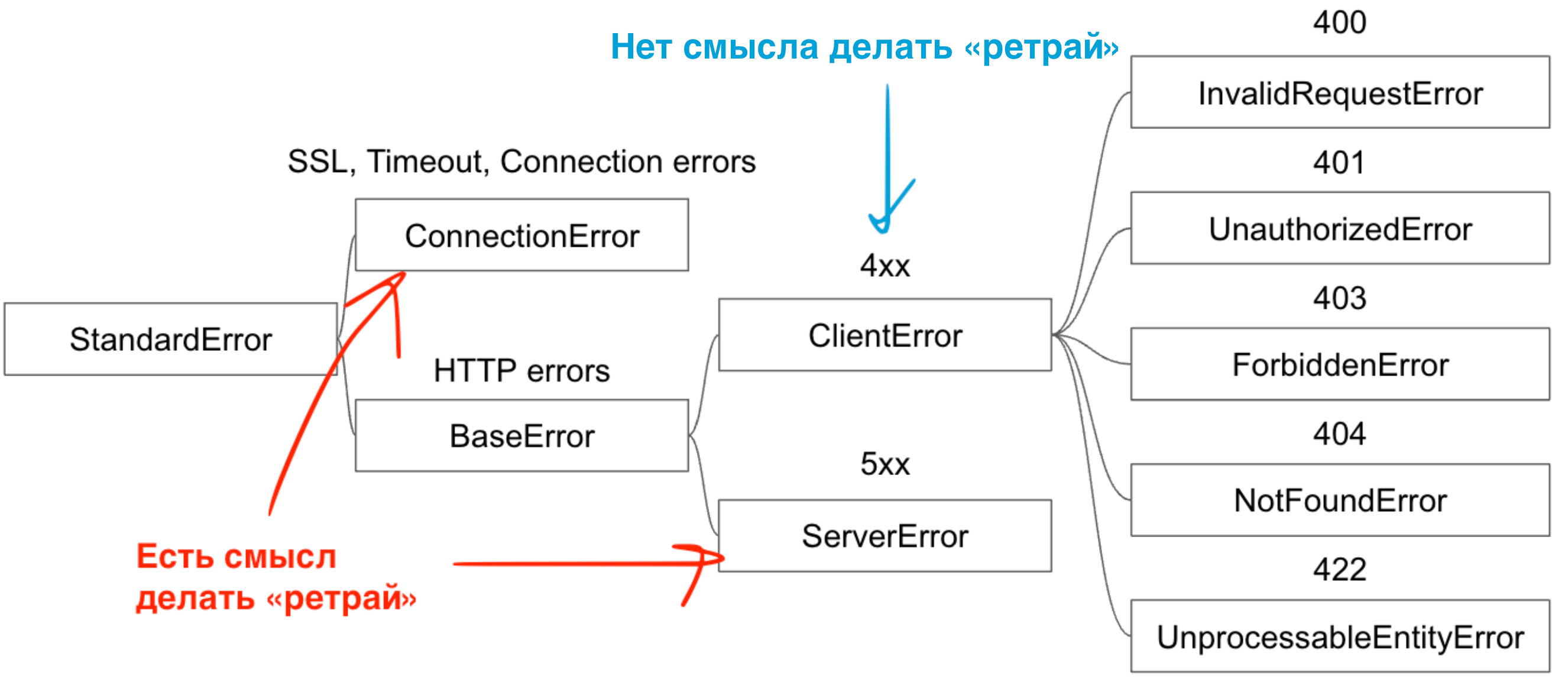
end5. Стандартизируйте и разграничьте ошибки
Полезно, если библиотека умеет различать ошибки. Если не умеет, то можно сделать свою надстройку для API-клиента, чтобы различить в коде ошибки.
Какие типичные ошибки можно выделить:
ошибки соединения;
ошибки с HTTP-кодом 400+;
ошибки с HTTP-кодом 500+.
Когда для каждой ошибки у вас своё исключение (класс ошибки), вы можете:
Добавить дополнительную логику к обработке конкретной ошибки в случае необходимости.
Видеть в трекере ошибок более понятное название возникшей проблемы.
Повторно обращаться к API только при определённых ошибках (об этом далее).
Также, если у вас есть какая-то особая логика (к примеру, «винтажные» микросервисы отдают код 200 и внутри success: false), то можете настроить специальный обработчик для таких ситуаций, чтобы для того, кто работает с кодом, это выглядело как понятная ошибка со своим экземпляром класса.

6. Настраивайте повторные попытки запроса при ошибке
У многих современных библиотек эта опция есть из коробки. Но, если такой нет, то наверняка можно подключить ещё одну библиотеку или написать простенький код самостоятельно.
Вы можете указать ряд ошибок, которые, на ваш взгляд, имеет смысл «ретраить», указать количество повторений и разницу по времени между ними.

Важно настраивать повторные попытки только на те ошибки, которые есть смысл повторять, иначе можно сгенерировать излишне много запросов в тех ситуациях, когда ответ сервера никак не изменится. Например, если был получен таймаут или 502-я ошибка, то есть смысл повторить попытку. А если мы получили ошибку 403 «Не авторизован», то от наших повторных попыток вряд ли сервер пропустит нас дальше.
7. Настраивайте заголовок UserAgent
Настраивайте заголовок UserAgent, чтобы в нём был существенный набор идентификационных данных. Это позволит вам или коллегам, отвечающим за сервисы, к которым вы обращаетесь, определить по логам, кто именно прислал запрос.
В User-Agent стоит включить идентификационные параметры, к примеру:
Имя приложения:
"MyProjectEX"Версия приложения:
"v1.0.0"Имя и версия API‑клиента:
"MyCustomClient; v0.23.1".Стек, на котором базируется приложение:
"Ruby","Python","Go".Среда развёртки:
"test";"staring";"prod".
Тогда наш примерный заголовок User-Agent будет выглядеть так:"MyProjectEX; v1.0.0; MyCustomClient; v0.23.1; Ruby; prod"

8. Настройте отдачу в метрики и логи
В конфигурацию вашего API-клиента можно передать логгер (экземпляр класса), который у вас используется в приложении. Это позволит, в случае необходимости, заменить его на какой-то другой, со своим уровнем журналирования или инструментом вывода (STDOUT, Kafka и пр).
Domclick::NewApi::Client.configure do |config|
config.logger = YourRailsApp.logger
endТакже, если ваш проект уже достаточно взрослый, требует высокой надёжности и масштабных мониторингов, то будет большим плюсом настроить единый вид отправки информации в систему сбора метрик.
В нашем случае мы собираем информацию в Prometheus, а потом выводим в Grafana количество запросов по различным методам с разбиением по кодам ответа и его скорости.

9. Сериализуйте запросы и ответы от сервиса
Этот пункт опционален и более применим к сложным API, но для Ruby-гемов в Домклике мы преобразовываем в модель все запросы. К примеру, когда API принимает целый ряд атрибутов c большой вложеностью и возвращает такой же вложенный набор, можно объявить удобные модели в коде для работы с этими данными.
Пример кода для объявления сложно-составного запроса:
contract_data = NewApi::Models::SalesContract::Data.new(
starting_at: Time.now, item: 'helicopter', price: '90000' …)
buyer = NewApi::Models::SalesContract::Buyer.new(
document_number: '1111 11111', first_name: 'Firstname', …)
seller = NewApi::Models::SalesContract::Seller.new(
license_id: 12, first_name: 'Firstname', …)
request_model = NewApi::Models::SalesContract::Create::Request.new(
contract_data: contract_data,
buyer: buyer,
seller: seller)
response = NewApi::Deals.create(request_model)
pp response.class # => NewApi::Models::SalesContract::Create::Response
pp response.as_json # = >
{
"contractdata": { "starting_at": "2024-03-27T09:14:45Z", "item": "helicopter", "price": "90000" …},
"participants": {
"buyer_dto": { "document_number": "1111 11111", "first_name": "Firstname", …},
"seller_dto": { "license_id": "12", "first_name": "Firstname", …},
}
}Также, возможно, у вас возникнет идея проверять входные и выходные данные при создании таких сущностей. Но мы решили оставить это на стороне API, потому что правила валидации могут поменяться, и содержать их в двух местах, тем самым тесно связывая клиент и сервер, не хочется. На мой взгляд, лучше грамотно обработать ошибку от сервера.
Дополнительные настройки
Подход с выделением настройки API-клиента в единое место позволит вносить дополнения под конкретно вашу ситуацию. К примеру, возможно, API, с которым вы работаете, возвращает ответы в camelCase, а вы в проекте привыкли работать со snake_case — тогда можно сделать единую конвертацию для всего взаимодействия.
Заключение
Для соблюдения этих практик и быстрого создания библиотек API-клиентов у нас на Ruby разработана отдельная опубликованная библиотека: Gemfather.
Подробнее про то, как мы к этому пришли, что дают эти подходы и как использовать библиотеку, можно узнать из моего выступления на RubyRussia в 2022.
Спасибо за прочтение!
А как у вас?
А как вы работаете с API в больших проектах? Есть ли ещё какие-то нюансы или подходы, которые вы наработали со временем и можете порекомендовать?
Комментарии (5)

Saidkomil
02.04.2024 08:56Также на текущем месте работы мы используем "стандарт" JSONRPC что делает по сути очень удобным подключение новых микросервисов, путём настройки передаваемых параметров и названий "методов", и подключение к новым API можно почти прописывать в конфигурационный файл

dbashinsky
02.04.2024 08:56В какой СУБД у вас хранятся логи запросов?
За какими графиками в графане вы следите в первую очередь?

DarkSideF Автор
02.04.2024 08:56Сами логи у нас хранятся в связке Elasticsearch/Kafka, вот в этой статье наши коллеги DevOPS подробно рассказали как реализовали мощный кластер логирования.
Касательно метрик запросов - их собирает Prometheus. За какими графиками следим - зависит от бизнес-задачи.
С точки зрения надёжности сервисов - в первую очередь смотрим на возрастающее количество ответов 4xx и 5xx, чтобы заблаговременно видеть возникающую деградацию и не допускать её развития в проблему клиентов.
PaulIsh
Можно еще добавить:
Добавьте трассировки чтобы отслеживать прохождение вашего запроса через набор микросервисов. Трассировки позволят найти узкое место или удивиться что вместо одного запроса вы шлете N.
Кроме retry еще посмотрите на circuit breaker, иначе, возможно, вы создадите ненужную нагрузку при сбое.
Сделайте включаемым сбор лога тела запросов/ответов, так как иногда нужны не только метрики времени и статусов, но и разбор причин ошибок. А постоянный лог не всегда нужен/возможен/добавляет тормоза.
DarkSideF Автор
Спасибо за дополнение.
По поводу трассировки да, хорошая идея изначально закладывать какой-то один идентификатор на протяжении всего запроса на уровне всего IT-ландшафта. Это тоже удобно можно внедрить в стандартизированный API-клиент
Да, хорошая практика, можно добавить доп.обработчики на специфичную ошибку для ответа о том что сервис временно недоступен из-за перегрузки.
Согласен. Это как раз можно решить передачей отдельного логгера в инициализацию API-клиента и передавать туда отдельный LOGLEVEL, который можно, при желании, переопределить через ENV-переменные.