

Если вы C# разработчик, то наверняка вам знаком класс Dictionary. В качестве значений вы, скорее всего, использовали классы. Но что если я скажу, что в Dictionary можно использовать структуры? Не стоит бояться того, что структуры копируются при передаче в метод или возврате из него. Есть способ этого избежать, и это работает быстро.
Дисклеймер
Информация в этой статье верна только при определённых условиях. Я допускаю, что бенчмарк может показать другие результаты на другом железе, с другим компилятором, во время другой фазы луны или при другом сценарии использования рассматриваемого функционала языка. Всегда проверяйте ваш код и не полагайтесь лишь на статьи из интернета.
Сценарий использования
Представим, что есть некоторый массив данных data. От нас требуется реализовать следующий функционал:
Преобразовать
dataв словарь для последующего поиска.По некоторому ключу найти в словаре объект и изменить его.
Повторить п. 2 столько раз, сколько требуется.
Напишем код, который имитирует такое поведение:
// Инициализация словаря
var dict = new Dictionary<int, SomeClass>(Length);
// Заполнение словаря
foreach (var (i, obj) in data) {
dict.Add(i, obj);
}
// Поиск значения и изменение данных
for (int i = 0; i < Length; i++) {
dict[i].DoWork(i);
}Код выше работает как задумано. Давайте попробуем его ускорить. Заменим класс SomeClass на структуру SomeStruct и сравним производительность обоих вариантов.
// Инициализация словаря
var dict = new Dictionary<int, SomeStruct>(Length);
// Заполнение словаря
foreach (var (i, obj) in data) {
dict.Add(i, obj);
}
// Поиск значения и изменение данных
for (int i = 0; i < Length; i++) {
var obj = dict[i];
obj.DoWork(i);
dict[i] = obj;
}Бенчмарк
Замер производительности осуществлялся на массиве данных в 100 000 элементов. Размер классов (без заголовка) и структур менялся от 4 до 128 байт. Для замеров производительности я использовал библиотеку BenchmarkDotNet. Код бенчмарка и результаты можно найти в GitHub.

Результаты бенчмарка показывают ухудшение производительности при использовании структур размером больше 20 байт. В реализации со структурами происходит их многократное копирование, а поиск в словаре осуществляется дважды. Это негативно сказывается на производительности. Давайте разобьем замеры кода на части, чтобы понять, что можно улучшить.
Инициализация словаря
Бенчмарк показал ожидаемые результаты. Время инициализации и размер словаря со структурами линейно возрастают с увеличением размера структур.

Связано это с тем, что массив entries в таком случае хранит непосредственно значения, а не ссылки. Соответственно, для хранения такого словаря нужно банально больше памяти.
Справедливости ради нужно отметить, что для классов CLR выделила памяти даже больше, просто это произошло ранее -- во время инициализации массива data. Если замерять время, затраченное на инициализацию массива классов и структур, то результаты будут не в пользу классов. Но это выходит за рамки статьи.
Заполнение словаря
И снова ожидаемые результаты. Время копирования структур, происходящее при заполнении словаря, линейно зависит от размера структур. Хотя разница между структурами и классами практически не заметна вплоть до 20 байт.

Поиск значения и его изменение
И в третий раз результаты не в пользу структур.
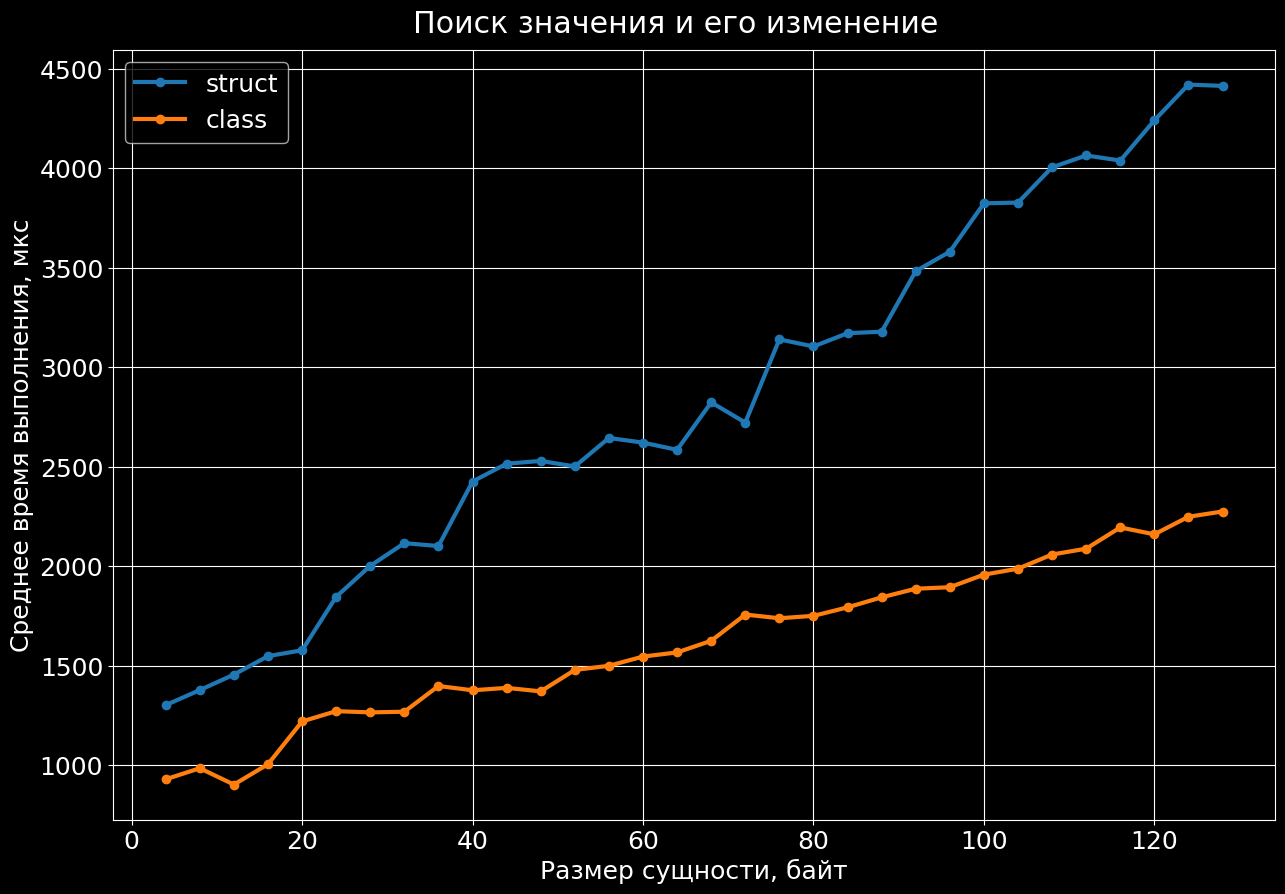
Связано это с тем, что поиск по ключу и копирование структур осуществляется дважды:
SomeStruct s = dict[i]; // 1-й поиск по ключу и копирование структуры
s.DoWork(i);
d[i] = s; // 2-й поиск по ключу и копирование структурыВот тут нам и поможет класс CollectionsMarshal.
Кто такой этот ваш CollectionsMarshal?
Если кратко, то это класс с четырьмя extension-методами:
AsSpan<T>-- возвращаетSpan<T>для элементовList<T>.GetValueRefOrAddDefault<TKey, TValue>-- по ключу возвращает из словаря ссылку на элементTValue, создаваяdefaultзначение если элемента не существует.GetValueRefOrNullRef<TKey, TValue>-- по ключу возвращает из словаря ссылку на элементTValueили ссылку наnull, если элемента не существует.SetCount<T>-- устанавливает значение Count дляList<T>.
Нас интересуют только GetValueRefOrAddDefault и GetValueRefOrNullRef. При помощи этих методов можно извлечь значения из словаря по ссылке, что позволит избежать двойного поиска по ключу и двойного копирования структуры. Например, код выше можно переписать следующим образом:
ref SomeStruct s = ref CollectionsMarshal.GetValueRefOrNullRef(dict, i);
s.DoWork(i);Ещё немного бенчмарков
Сделаем замеры реализации с GetValueRefOrNullRef и сравним с предыдущими результатами:

Время выполнения кода с CollectionsMarshal даже быстрее, чем с классами. Чтобы компенсировать потери производительности при инициализации и заполнении словаря, количество операций поиска должно быть многократно больше, чем размер массива.

Особенности CollectionsMarshal
Проверка на default и null
Как упоминалось ранее, методы GetValueRefOrAddDefault и GetValueRefOrNullRef возвращают ссылку на default структуру и ссылку на null.
Проверить, дефолтная ли структура, т.е. все поля имеют дефолтное значение, довольно просто -- нужно проверить флаг exists:
ref var element = ref CollectionsMarshal.GetValueRefOrAddDefault(dict, key, out bool exist);
if (exist) {
// some code here
}Со ссылкой на null ситуация другая. Булевого флага нет, а при сравнении с null будет выброшено исключение NullReferenceException. Лучше воспользоваться методом Unsafe.IsNullRef<T>(ref T source).
ref var element = ref CollectionsMarshal.GetValueRefOrNullRef(dict, key);
if (Unsafe.IsNullRef<T>(ref element)) {
// some code here
}Изменение словаря после получения ссылки на структуру
В документации к методам GetValueRefOrAddDefault и GetValueRefOrNullRef прямым текстом указано, что нельзя изменять словарь после того, как была получена ссылка на структуру. Почему так делать не надо продемонстрировано на примере ниже. После изменения словаря, любые изменения структуры, полученной по ссылке, не повлияют на значение в словаре.
ref var element = ref CollectionsMarshal.GetValueRefOrNullRef(dict, key);
Console.WriteLine($"ref element: {element.Item1}"); // 30
Console.WriteLine($"dict[key]: {dict[key].Item1}"); // 30
element.Item1 = 50; // change #1
Console.WriteLine($"ref element: {element.Item1}"); // 50
Console.WriteLine($"dict[key]: {dict[key].Item1}"); // 50
dict.Add(100, new (100)); // add a new element
element.Item1 = 60; // change #2
Console.WriteLine($"ref element: {element.Item1}"); // 60
Console.WriteLine($"dict[key]: {dict[key].Item1}"); // 50Выводы
Структуры -- недооценённые элементы C#, которые, при определённых условиях, способны ускорить ваше приложение. При использовании структур в качестве значений для Dictionary лучше воспользоваться классом CollectionsMarshal. Методы этого класса GetValueRefOrAddDefault и GetValueRefOrNullRef позволяют получать элементы словаря по ссылке. Это, в свою очередь, может положительно сказаться на производительности кода при относительно большом количестве операций поиска в словаре.
Комментарии (21)

Kerman
12.04.2024 05:59+6Если мы получаем от словаря ссылку на структуру и потом работаем по ссылке, то чем, собственно говоря, это отличается от класса?
Да, есть небольшой выигрыш за счёт того, что ссылки не считаются и ансейф во все поля. Но этот выигрыш чувствителен только для сценария с большим количеством поисков и не пополняющимся словарём. Для такого сценария существуют контейнеры получше, вроде FrozenDictionary. А то и бинарное дерево.
И сравнение считаю некорректным. Структуры у вас с ружьём, направленным в ногу, а классы используют стандартный сейф механизм.
И ещё. Не нашёл в коде объявления GetHash и Equals. Может у вас хэш коллизит и поиск деградировал до линейного.

mayorovp
12.04.2024 05:59+3Так ключом в словаре является int, у него GetHashCode и Equals свои есть
mayorovp
12.04.2024 05:59+2Кто-то не верит, что там ключ int? Смотрим исходники: https://github.com/alexeyfv/speed-up-the-dictionary/blob/0f6ce393fe2fb7e32caef579640749e4dc2b18f2/CodeGen/SourceGenerator.cs#L235-L245
private readonly string _createDictionaryBenchmarkTemplate = @" Dictionary<int, {0}{1}> _dict{0}{1} = new(Length); {0}{1}[] _array{0}{1} = new {0}{1}[Length]; [Benchmark] [BenchmarkCategory(""{1}"")] public Dictionary<int, {0}{1}> {0}{1}DictCreate() {{ _dict{0}{1} = new(Length); return _dict{0}{1}; }}";

sdramare
12.04.2024 05:59Если мы получаем от словаря ссылку на структуру и потом работаем по ссылке, то чем, собственно говоря, это отличается от класса?В таком сценарии скорее всего все данные сразу попаду на кэш-линию, по-этому код будет работать быстрее.

alexeyfv Автор
12.04.2024 05:59чем, собственно говоря, это отличается от класса
Да, есть небольшой выигрыш за счёт того, что ссылки не считаются и ансейф во все поля
Вы сами ответили на вопрос. :)
Если рассматривать только то, что приведено в статье, то да, выигрыш небольшой. Если смотреть шире, как структуры влияют на всё приложение, то за счёт их использования можно ускорить работу и снизить потребление памяти. Данные в массиве data из примера же не берутся из воздуха. CLR в какой-то момент времени 100 000 аллоцировала память под 100 000 экземпляров классов + 1 раз для словаря. В случае со структурами, аллокация произошла только для словаря. Что быстрее: аллоцировать 100 001 раз память в куче или всего 1 раз? Но, опять же, всё зависит от сценария. Я не утверждаю, что рассмотренный мною способ единственно правильный.
alexeyfv Автор
12.04.2024 05:59По поводу
FrozenDictionaryвы правы, работает быстрее.| Method | Categories | Repeats | Mean | Error | StdDev | Gen0 | Gen1 | Gen2 | Allocated | |----------------------------- |----------- |-------- |---------:|---------:|---------:|---------:|---------:|---------:|----------:| | FrozenDictionary | Class | 100000 | 24.23 ms | 0.327 ms | 0.376 ms | 437.5000 | 437.5000 | 437.5000 | 7.29 MB | | Dictionary | Struct | 100000 | 69.79 ms | 1.072 ms | 1.235 ms | 375.0000 | 375.0000 | 375.0000 | 4.14 MB | | DictionaryCollectionsMarshal | Struct | 100000 | 34.22 ms | 2.077 ms | 2.392 ms | 428.5714 | 428.5714 | 428.5714 | 4.14 MB |Опять же, выбор будет зависеть от сценария. Если создавать словарь нужно относительно редко (т.е. аллоцировать память для экземпляров классов), то это хорошее решение. Если же, например, на каждый запрос нужно достать из БД какие-то данные, преобразовать в словарь, потом осуществить поиск, то структуры + CollectionsMarshall, думаю, будут быстрее.

AgentFire
12.04.2024 05:59+1А точно ли со всей этой махиной "обрабатываем входящий запрос -> наполняем словарь -> лезем в БД через ORM" выигрыш в class->struct будет так сильно заметен по аллокациям?
alexeyfv Автор
12.04.2024 05:59Нет, это не точно. Пока не сделать конкретные замеры и не показать результаты, нельзя сказать, что один подход быстрее другого. И то, результаты будут валидны с определёнными оговорками. Так что пока мы можем только теоретически рассуждать, что мы и делаем. :)

Onni
12.04.2024 05:59Я давно видел эту штуку. Но никогда не проверял, что буде если:
ref var myRef = ref CollectionsMarshal.GetValueRefOrNullRef(dict, ket); dict.Add(...); // тут происходит рост коллекции myRef = value; // куда сейчас указывает myRef?mayorovp
12.04.2024 05:59Либо на актуальную ячейку, либо в мусорный массив с копией старых данных, а куда точно - не определено.
Интереснее результат можно получить если удалить ключ из словаря.
Onni
12.04.2024 05:59Проглядел что вы об написали об этом. С одной стороны ожидаемо, но я в тайне надеялся что есть какая-то магия.

mvv-rus
12.04.2024 05:59Интереснее результат можно получить если удалить ключ из словаря.
Причем, возможно - если удалить совсем другой ключ;-). Вы не посмотрели когда туда лазили, не открытая ли адресация там используется?
mayorovp
12.04.2024 05:59Нет, там используются односвязные списки на массивах. Но даже и при открытой адресации никаких специфичных для неё эффектов не было бы.
Aquahawk
какой отвратительный дизайн, вот как об этой вещи должен узнать разработчик? Тут https://learn.microsoft.com/en-us/dotnet/api/system.collections.generic.dictionary-2?view=net-8.0 нет ни слова. У Рихтера тоже.
mayorovp
А большинству разработчиков эта фича ни разу не понадобится.
Спрятана же она потому, что возвращённые ссылки, фактически, инвалидируются при добавлении или удалении элементов из словаря, в то время как способа выразить это в API нету. Я бы тоже не стал держать в основном пронстранстве имён API, которое настолько легко использовать неправильно.
И вообще, нефиг делать такие большие структуры. 3-4 ссылочных поля - предел, за которым от структуры становится больше проблем чем пользы.
Aquahawk
а какой тогда смысл делать "секретную" фичу, и не писать о ней в документации? Как разработчик, которому это потребовалось вообще должен вообще об этом узнать?
mayorovp
Ну автор же откуда-то про эту фичу знал? Теперь вот мы тоже знаем.
Aquahawk
Я вот теперь тоже откуда-то узнал. Но почему функционал предназначенный для работы с диктами не упомянут в референсе на дикты? Имхо это провал архитектуры и документации.
mvv-rus
Этот функционал предназначен для взаимодействия с кодом, выполняющимся не под управлением .NET. И находится там же, где всё подобное - в System.InteropServices.
В обычном (управляемом) коде .NET его лучше не использовать - как например и указатели, ровно по тем же причинам: unsafe.
Aquahawk
лучше - не лучше должен решать разработчик с головой на плечах, но в доке по диктам этот способ должен быть указан. Хотя он оказывается очень свежий, поэтому думаю если появится новое издание Рихтера он там будет
alexeyfv Автор
Случайно обнаружил вот это issue https://github.com/dotnet/runtime/issues/27062, когда гуглил как структуры подружить со словарём. :)