
Этот материал посвящён применению последовательного A/B‑тестирования в Netflix.
1. Найдите отличия
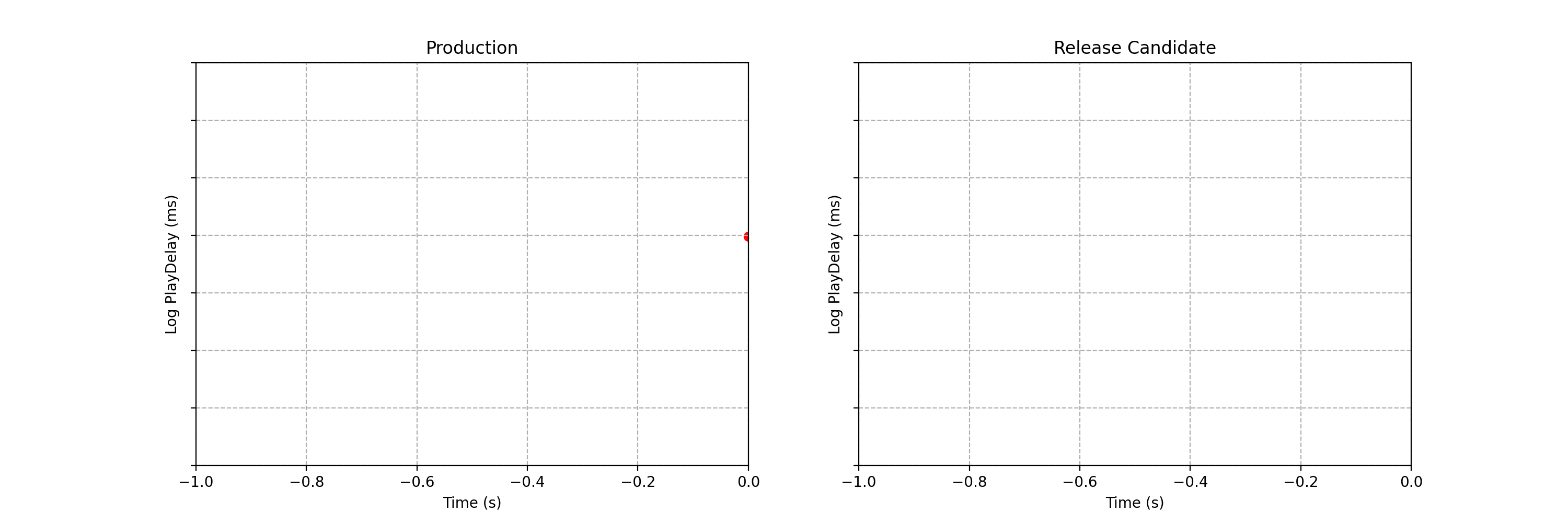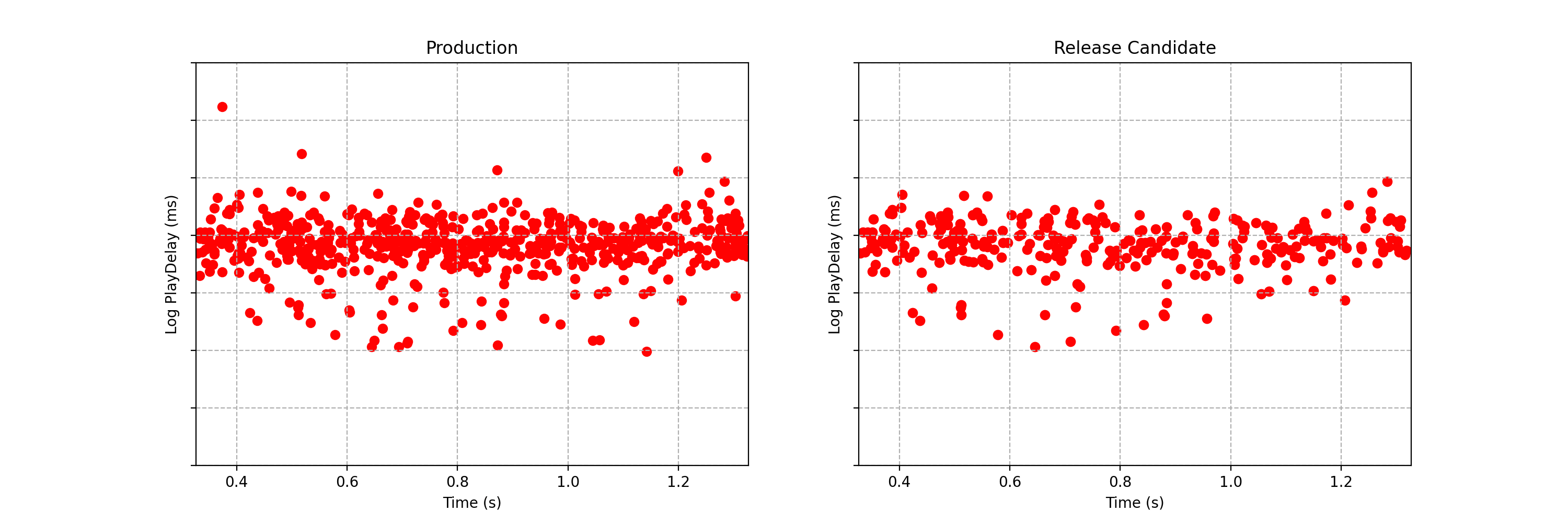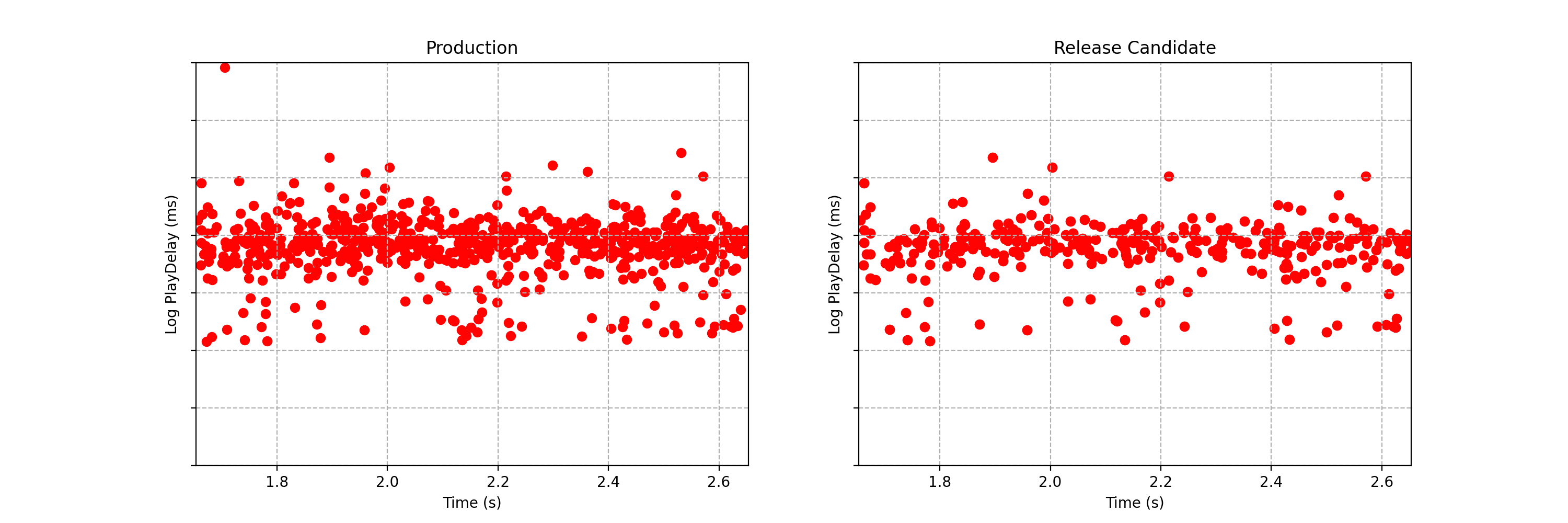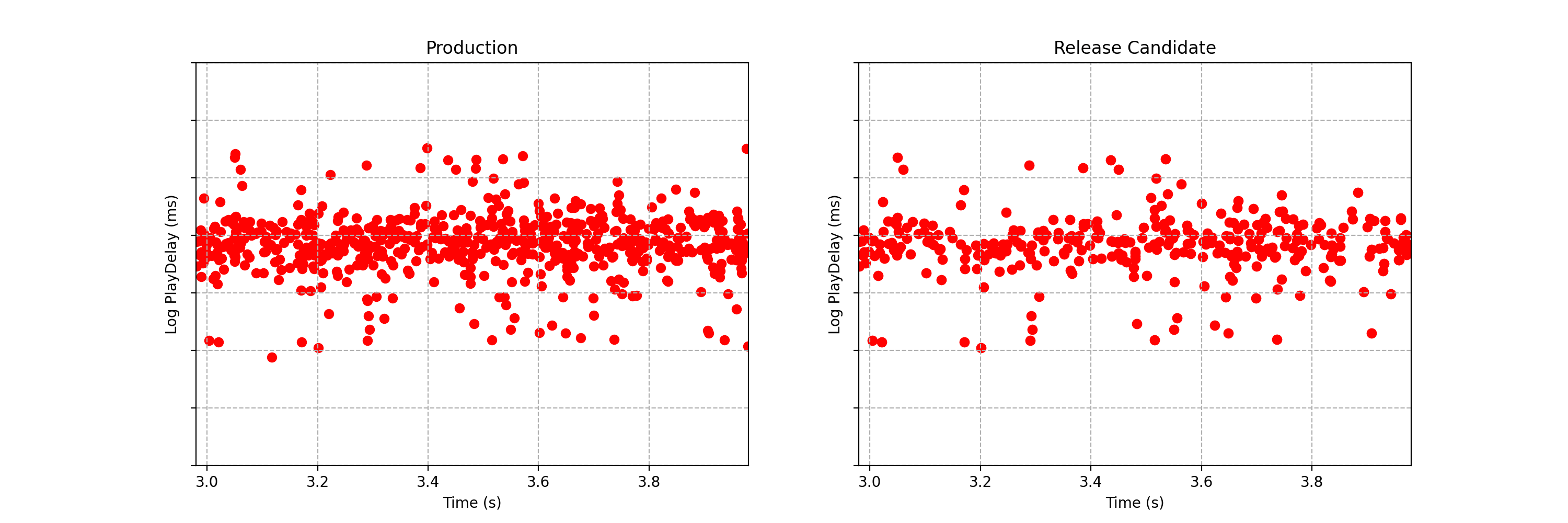
Можете увидеть разницу между двумя потоками данных, показанными ниже? Каждое наблюдение представляет собой временной интервал, который проходит между тем моментом, когда пользователь Netflix нажимает на кнопку воспроизведения видео, и моментом, когда видео начинает проигрываться. В Netflix этот показатель называют «задержкой воспроизведения» (play‑delay). Эти наблюдения получены в ходе A/B‑тестирования определённого типа, используемого в Netflix и называемого «тестированием канареечного релиза» или регрессионным экспериментом. Подробнее об этом мы поговорим ниже. Пока важно то, что, применяя подобные тесты, мы хотим быстро и надёжно выявлять наличие разницы в распределении показателя play‑delay, или приходить к выводу о том, что, в рамках определённых допусков, такой разницы нет.
В этом материале мы расскажем о разработке статистической процедуры для решения именно этой задачи и поговорим о влиянии таких разработок на Netflix. Основная идея тут заключается в том, чтобы перейти от подхода к решению задачи, предусматривающему получение результатов, актуальных в определённых временных пределах, к подходу, когда получаемые результаты актуальны всегда.
Гифка на 15 Мб
Рис. 1. Пример потока данных для A/B‑теста, где каждое наблюдение представляет собой значение задержки воспроизведения для контрольной (слева) и экспериментальной (справа) группы пользователей. Можете увидеть разницу в статистических распределениях между двумя потоками данных?
{kind=link}
2. Надёжное развёртывание ПО, тестирование канареечных релизов и задержка воспроизведения
Читатели‑программисты, наверняка, знакомы с модульным, интеграционным и нагрузочным тестированием ПО, а так же — с другими подходами к тестированию, которые нацелены на то, чтобы не пропустить ошибки в продакшн. В Netflix, кроме прочего, производится тестирование канареечных релизов. Речь идёт об A/B‑тестах, в которых сравниваются текущие и более новые версии программ. Подробнее об этом можете почитать в нашем предыдущем материале о надёжном обновлении клиентских приложений.
Тестирование канареечных релизов преследует две цели. Первая — контроль качества, направленная на отлов ошибок до выхода полного релиза. Вторая — измерение производительности нового кода в естественных условиях. Эти цели достигаются путём проведения рандомизированного контролируемого эксперимента с участием небольшой подгруппы пользователей. При этом экспериментальная группа получает обновлённую программу, а контрольная группа продолжает пользоваться существующей версией. Если в экспериментальной группе будут выявлены ошибки или падение производительности, полномасштабный выпуск новой версии программы может быть отложен, что позволяет ограничить «радиус поражения» пользовательской базы.
Одна из метрик, за которой наблюдают в Netflix, проводя тестирование канареечных релизов — это показатель «задержка воспроизведения» (play‑delay), описывающий то, сколько времени уходит на запуск воспроизведения видеопотока после того, как пользователь выразил желание воспроизвести некий видеоматериал. Мониторинг этой метрики при выпуске новых релизов позволяет обеспечить то, что эффективность стриминга видео в Netflix при выходе новых версий клиента постоянно улучшается. На Рис. 1, слева, показан поток данных, получаемых в реальном времени и описывающих показатель play‑delay у пользователей, работающих с существующей версией клиента Netflix. Справа показаны измерения того же показателя, сделанные у пользователей, использующих обновлённую версию клиента. Глядя на эти данные, мы задаёмся следующим вопросом: «Сталкиваются ли пользователи обновлённого клиента с более длительными задержками воспроизведения видео?».
Мы считаем, что любое увеличение показателя play‑delay указывает на серьёзное падение производительности, и не выпускаем соответствующие релизы в продакшн. Важно то, что для выявления подобных проблем недостаточно тестирования на наличие различий в средних или медианных значениях. Такое тестирование не даёт нам полной картины происходящего. Например, в одной ситуации мы можем столкнуться с тем, что медианные или средние значения задержки воспроизведения в контрольной и экспериментальной группах не различаются. Но при этом в экспериментальной группе наблюдается увеличение показателя play‑delay в верхних квантилях. Это соответствует падению скорости работы Netflix у тех пользователей, которые уже сталкиваются с высокими задержками воспроизведения. Это вполне могут быть пользователи, работающие на медленных или нестабильных интернет‑соединениях. Процедура тестирования, применяемая нами, не должна игнорировать подобные вещи.
Для полноты картины добавим, что нам нужна возможность надёжного и быстрого обнаружения смещения значений вверх в любой части распределения показателя play‑delay. Поэтому мы обязаны проводить соответствующие эксперименты и делать выводы о различиях между распределениями показателя в экспериментальной и контрольной группах.
В итоге можно сказать, что мы предъявляем следующие требования к архитектуре системы тестирования канареечных релизов:
Как можно более быстрая идентификация ошибок и падения производительности путём измерения показателя play‑delay. Основная причина: минимизация неудобств, причиняемых пользователям. Если пользователи в экспериментальной группе испытывают какие‑либо проблемы с качеством стриминга — нам нужно как можно быстрее отменить канареечный релиз и вернуться к предыдущей версии ПО.
Жёсткий контроль вероятности возникновения ложноположительных результатов (ложных тревог). Основная причина: эта система является частью полуавтоматического процесса развёртывания всех клиентских продуктов. Ложноположительные результаты тестов приводят к необоснованному нарушению процесса выпуска ПО, что снижает скорость попадания программ к конечным пользователям и заставляет разработчиков искать несуществующие ошибки.
Система должна обладать способностью обнаружения любых изменений в распределении результатов. Основная причина: нас интересуют не только изменения в средних или медианных значениях, но и изменения в «хвостах» распределений и в других квантилях.
Сейчас мы расскажем о создании процедуры последовательного тестирования, которая удовлетворяет этим архитектурным требованиям.
3. Последовательный статистический анализ: основы
Стандартные статистические критерии вычисляют, используя тесты с фиксированной выборкой, или тесты, проводимые в течение фиксированного временного интервала. Проводя их, аналитик ждёт до тех пор, пока не будет собран некий, заранее заданный объём данных, после чего один раз выполняет анализ этих данных. Классические t‑критерии — критерий Колмогорова‑Смирнова или U‑критерий Манна‑Уитни — это примеры критериев, при вычислении которых используются выборки фиксированного размера. Ограничение таких критериев заключается в том, что они могут быть вычислены лишь один раз. Но в ситуациях, подобных вышеописанной, нам нужна возможность частого проведения тестов для как можно более быстрого нахождения различий между выборками. Проведение такого теста больше одного раза приводит к росту вероятности возникновения ошибки первого рода, то есть — вероятности сделать ложноположительное заключение.
Вот небольшая зарисовка, иллюстрирующая неправильное поведение тестов с фиксированной выборкой в условиях многократного повторения анализа. На следующем рисунке каждая красная линия отражает p‑значение, которое получено при повторяющемся вычислении U‑критерия Манна‑Уитни на наборе данных, максимальный размер которого составляет 10 000 наблюдений. При каждом вычислении критерия для экспериментальной и контрольной групп размеры выборки, используемой в вычислениях, увеличиваются. Каждая красная линия отражает результаты независимой симуляции, и в каждом случае нет разницы между экспериментальной и контрольной группами. То есть — речь идёт о симуляции A/A‑теста.
Чёрные точки отмечают те места, в которых p‑значение оказывается ниже стандартного порога отклонения нулевой гипотезы в 0.05. В ходе симуляции оказалось, что весьма большое количество сеансов симуляции, а именно — 70%, показало, что между выборками имеются серьёзные различия. Но сама симуляция устроена так, что различий между выборками нет. Реальное количество ложноположительных результатов оказывается гораздо выше, чем номинальное значение 0.05. То же самое можно наблюдать и при вычислении в подобных условиях критерия Колмогорова‑Смирнова.

Это — проявление проблемы «подглядывания», о которой много всего написано (например — взгляните на эту публикацию). Если мы ограничимся правильным применением статистических тестов с фиксированной выборкой, когда данные анализируются лишь один раз, мы столкнёмся с непростым выбором:
Можно проводить тесты достаточно рано, после сбора небольшого количества данных. В таком случае мы сможем обнаруживать лишь серьёзные отклонения, последствия больших ошибок. Небольшое падение производительности при таком подходе не выявить. Это означает, что мы, по мере того, как в систему постоянно проникают небольшие проблемы, рискуем постепенно ухудшить качество обслуживания пользователей.
Можно выполнять тесты после того, как будут собраны достаточно большие объёмы данных. В таком случае у нас появляется возможность обнаружения небольших проблем. Но в случае с проблемами более крупных масштабов окажется, что мы подвергаем пользователей негативному воздействию в течение неоправданно длительного периода времени.
Справиться с этими ограничениями помогают последовательные, или «всегда актуальные» методы статистического анализа. При проведении последовательных тестов разрешено «подглядывание». На самом деле — расчёт соответствующих показателей возможен после поступления каждой новой точки данных. При этом обеспечивается поддержание стабильного уровня ложноположительных результатов, или ошибок первого рода. В результате можно непрерывно мониторить потоки данных, такие, как на вышеприведённом рисунке, используя последовательные доверительные интервалы, или последовательные p‑значения. Это позволяет быстро обнаруживать большие проблемы, а, по прошествии некоторого времени, в итоге, обнаруживать и проблемы меньшего масштаба.
Несмотря на то, что эти методы начали применяться в цифровых экспериментах сравнительно недавно, они обладают внушительной академической историей, а появление изначальных идей восходит к работе 1945 года «Sequential Tests of Statistical Hypotheses». Исследования в этой области продолжаются. Специалисты компании Netflix в последние несколько лет сделали немало публикаций на эту тему (списки источников в этих публикациях позволят вам получить более полное представление о литературе, посвящённой последовательному подходу к статистическому анализу):
Anytime‑Valid Linear Models and Regression Adjusted Causal Inference in Randomized Experiments.
Design‑Based Confidence Sequences: A General Approach to Risk Mitigation in Online Experimentation.
В этом и в следующих наших материалах мы опишем и методы, разработанные нами, и их применение в Netflix. Остаток этой статьи посвящён обсуждению первой публикации из списка, которая вышла в сборнике KDD 2022 года (найти её можно на ArXiV). Мы опишем её здесь лишь в общих чертах. Читатель, которому интересны технические детали, может обратиться к самой этой публикации.
4. Система для проведения последовательного анализа
Различия в распределениях
В любой момент времени можно, основываясь на собранных к этому моменту данных, рассчитать эмпирические квантильные функции и для экспериментальной, и для контрольной группы.
 и экспериментальной (справа) групп, полученные в определённый момент времени после начала испытания канареечного релиза. Эти графики построены на основе реальных данных Netflix, поэтому мы убрали подписи с оси Y.")
Эти два графика выглядят очень похожими, но мы можем сравнивать их, используя инструменты, которые точнее наших глаз. И нам нужно, чтобы компьютер был бы способен непрерывно оценивать наличие существенных различий между этими распределениями. Кроме того, в соответствии с требованиями к архитектуре системы, нам нужно как можно раньше выявлять последствия крупных проблем, сохраняя при этом возможность, в итоге, обнаруживать и более мелкие проблемы. И нам нужно, обеспечивая возможность проведения непрерывного анализа (или «подглядывания»), поддерживать на номинальном уровне вероятность выдачи ложноположительных результатов.
Получается, что нам нужен механизм последовательного статистического анализа различий в распределениях.
Получение доверительных интервалов для квантильной функции можно организовать с использованием неравенства Дворецкого‑Кифера‑Вольфовица. Для получения доверительных интервалов, равномерных по времени, однако, мы используем всегда актуальные доверительные последовательности, описанные здесь (вот — версия этого материала на ArXiV). Так как охват этих доверительных интервалов, со временем, остаётся неизменным, можно наблюдать за тем, как они сужаются, не беспокоясь о «подглядывании». По мере того, как в нашем распоряжении оказывается большее количество точек данных, эти последовательные доверительные интервалы продолжают сужаться. Это означает, что любое различие в функциях распределения, если оно существует, в итоге окажется очевидным.
 и экспериментальную (справа) группы.")
Обратите внимание на то, что каждый кадр анимации привязан не к увеличению размера выборки, а некоему моменту времени, наступившему после начала эксперимента. На самом деле, тут нет требования относительно того, чтобы каждая экспериментальная группа характеризовалась бы выборкой одинакового размера.
Различия легче увидеть, визуализируя разницу квантильных функций для экспериментальной и контрольной групп.
 — Q_a(p) (слева). Последовательное p-значение (справа).")
Так как последовательный доверительный интервал на квантильной функции экспериментальной группы является всегда актуальным, процедура статистического вывода оказывается довольно‑таки понятной. Мы можем продолжать наблюдать за тем, как сужаются доверительные интервалы. И если в какой‑то момент времени, на любом квантиле, интервал перестанет перекрывать нулевое значение, мы можем сделать вывод о том, что распределения различаются, и остановить эксперимент. В дополнение к последовательным доверительным интервалам мы можем сконструировать последовательное p‑значение, которое позволит нам узнавать о том, что распределения различаются. На предыдущей анимации видно, что момент, когда 95% доверительный интервал перестаёт включать в себя 0 — это тот же момент, когда последовательное p‑значение падает ниже 0.05. Как и в случае тестов с фиксированной выборкой, тут наблюдается согласованность между доверительными интервалами и p‑значениями.
Тут нас интересует множество показателей, относящихся к различным тестам. Наша система одновременно контролирует ошибки первого рода по всем квантилям, все экспериментальные группы и все совместные размеры выборок (подробности смотрите здесь и здесь). Результаты справедливы для всех квантилей и для всех моментов времени.
5. Воздействие на Netflix
Выпуск новых версий ПО — это всегда риск, и мы стремимся снизить риски нарушения работы служб или снижения качества обслуживания клиентов. Наш подход к тестированию канареечных релизов программ — это дополнительный уровень защиты продакшн‑версий от проникновения в них ошибок и недоработок, ухудшающих производительность. Процесс тестирования полностью автоматизирован, он стал неотъемлемой частью процесса доставки приложений в Netflix. Разработчики могут отправлять код в продакшн с лёгким сердцем, зная о том, что система быстро обнаружит ошибки и проблемы с производительностью. Эта вот дополнительная уверенность вдохновляет разработчиков на то, чтобы чаще отправлять код в продакшн, снижает время, необходимое для того, чтобы обновления дошли бы до наших пользователей, и повышает интенсивность работы нашей системы доставки приложений.
К настоящему моменту эта система успешно остановила множество серьёзных ошибок на их пути к нашим пользователям. Приведём пример.
Пример из жизни: надёжное развёртывание клиентского приложения Netflix
Рисунки 3–5 были взяты из теста канареечного релиза, в котором поведение клиентского приложения было изменено (были отключены реальные числовые значения показателя задержки воспроизведения). Как можно видеть, тест канареечного релиза выявил то, что применение новой версии клиента приводит к увеличению показателя play‑delay во множестве квантилей. А именно, медианное значение и 75% перцентиль испытывают рост, как минимум, соответственно, на 0.5% и 1%. Изменение последовательного p‑значения во времени показывает, что, в данном случае, мы, на уровне 0.05, по прошествии 60 секунд, смогли отклонить нулевую гипотезу, в соответствии с которой распределения не отличаются друг от друга. Такой подход позволяет быстро узнать о том, что происходит с исследуемым релизом, что помогает программистам оценивать производительность нового ПО и ускоряет процесс разработки.
6. Что дальше?
Если вас серьёзно интересуют технические детали применения последовательных статистических эксперименто, о разработке которых мы рассказали — обратитесь к нашей публикации, где вы можете ознакомиться со всеми математическими выкладками (найти её можно здесь и здесь).
Возможно, вам интересно узнать о том, что произойдёт, если данные представляют собой нечто, не являющееся результатом непрерывных измерений каких-то показателей. Количество ошибок и исключений — это чрезвычайно важные метрики, которые нужно регистрировать при развёртывании ПО. То же самое можно сказать и о многих других метриках, которые лучше всего выражаются через подсчёт чего-либо. В следующем материале мы расскажем о процедурах последовательного тестирования, применимых к событиям, которые, для их анализа, нужно считать.
О, а приходите к нам работать? ? ?
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.