
Небольшой спойлер: в начале это казалось мне какой-то магией, но потом я понял подвох…
В наши дни машина Тьюринга (далее МТ) — универсальное определение понятия алгоритма, а значит и универсальное определение «решателя задач». Существует множество других моделей алгоритма — лямбда исчисление, алгорифмы Маркова и т.д., но все они математически эквивалентны МТ, так что хоть они и интересны, но в теоретическом мире ничего существенно не меняют.
Вообще говоря, есть другие модели — Недетерминированная машина Тьюринга, Квантовые машины Тьюринга. Однако они (пока) являются только абстрактными моделиями, не реализуемые на практике.
Полгода назад в Science Advances вышла интересная статья с моделью вычислений, которая существенно отличается от МТ и которую вполне возможно реализовать на практике (собственно статья и была о том, как они посчитали задачу SSP на реальном железе).
И да. Самое интересное в этой модели то, что, по заверению авторов, в ней можно решать (некоторые) задачи из класса NP полных задач за полином времени и памяти.
Наверное сразу стоит оговорить, что данный результат не означает решения проблемы
Сам я в данный момент отношусь скептически к возможности постройки данной машины в железе (почему я расскажу ниже), но сама модель мне показалась достаточно интересной для разбора и, вполне возможно, она найдет применение и в других областях науки.
Небольшое введение
Что представляет собой компьютер (точнее наиболее популярная реализация МТ — арх. фон-Неймана) сегодня? Какой-то интерфейс ввода-вывода, память и CPU, который физически от них отделен. В CPU же находятся как модуль, управляющий ходом вычислений, так и блоки, которые эти вычисления выполняют.
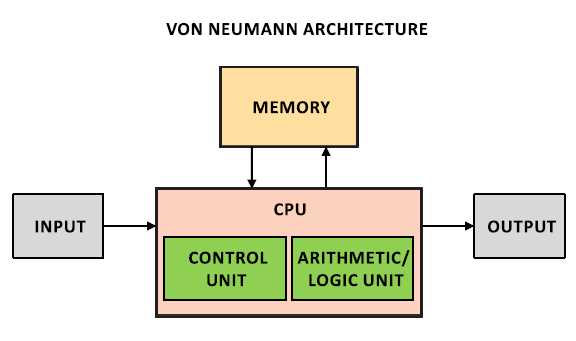
Физическое отделение CPU означает, что нам приходится тратить большое время на передачу данных. Собственно именно для этого были придуманы различные уровни кеш-памяти. Однако кеш-память, конечно, облегчает жизнь, но не решает всех проблем передачи данных.
Предложенная модель данных вдохновлялась работой мозга (фраза довольно избитая, но сюда вполне подходит). Её суть в том, что вычисления происходят не в отдельном устройстве, куда нужно перенести данные, а прямо в памяти. Порядок вычислений контролируются внешним устройством (Control Unit).
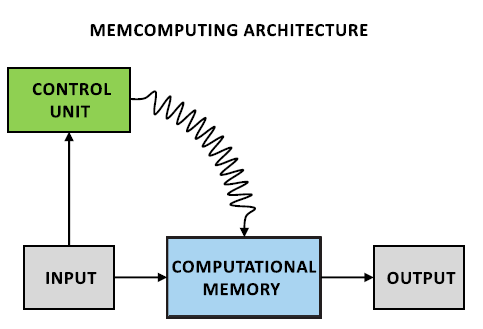
Эта модель вычислений, получила название Universal Memcomputing Machines (переводить этот термин я не стал. Далее я буду употреблять сокращение UMM).
В данной статье мы сначала вспомним как формально определяется МТ, потом посмотрим определение UMM, посмотрим на примере как задать алгоритм решения задачи на UMM, рассмотрим несколько свойств, в том числе самое важное — information overhead.
Формальное описание модели.
Universal Turing Machine (UTM)
Я думаю вы все помните, что такое машина Тьюринга (иначе смысла читать эту статью нет). Лента, каретка, все дела. Давайте лишь вспомним как она определяется формально.
Машина Тьюринга — это кортеж
где
Мемпроцессор.
Для начала определим нашу ячейку памяти UMM — мемпроцессор.
Мемпроцессор определяется как 4-кортеж
И, наконец,
Хочу напомнить, что мемпроцессор — не тот процессор, который мы обычно представляем в голове. Это скорее ячейка памяти, которая имеет функцию получения нового состояния (программируемую).
Universal Memcomputing Machine (UMM)
Теперь введем формальное определение UMM. UMM — модель вычислительной машины, сформированной из соединенных мемпроцессоров (которые, вообще говоря, могут быть как цифровыми, так и аналоговыми).
где
где
По аналогии с машиной Тьюринга, как вы могли уже догадаться,
Вообще говоря, отбрасывая формализм, главное отличие UMM от МТ в том, что в UMM влияя на одну ячейку памяти (то есть на мемпроцессор), вы автоматически влияете и на её окружение, без дополнительных вызовов из Control Unit.
Отметим 2 свойства UMM, напрямую вытекающие из его определения.
- Свойство 1. Intrinsic parallelism (я так и не определился, как правильно перевести этот термин, поэтому оставил как есть). Любая функция
может запускаться на любом множестве процессоров одновременно. В машине Тьюринга для этого нужно вводить дополнительные ленты и головки.
- Свойство 2. Функциональный полиморфизм. Оно заключается в том, что, в отличии от машины Тьюринга, UMM может иметь много различных операторов
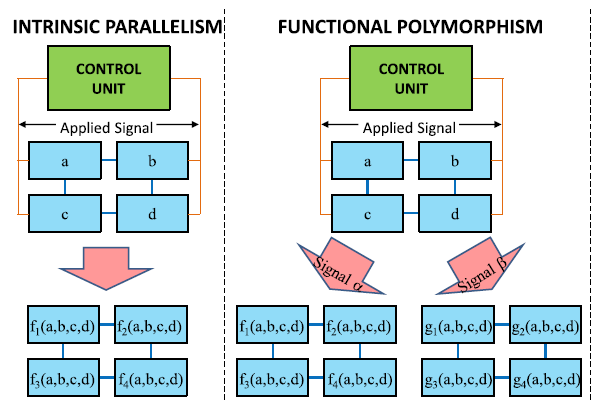
Вообще говоря, не так уж и сложно модифицировать машину Тьюринга так, чтобы она тоже обладала данными свойствами, но авторы настаивают.
И ещё несколько замечаний по определению. UMM, в отличии от машины Тьюринга, может иметь бесконечное пространство состояний при конечном количестве мемпроцессоров (из-за того, что они могут быть аналоговыми).
Кстати говоря, UMM можно рассматривать как обобщение нейронных сетей.
Докажем одну теорему.
UMM — универсальная машина (то есть машина, которая может симулировать работу любой МТ).
Доказательство.
Иными словами, нам нужно показать, что машина Тьюринга — частный случай UMM. (верно ли обратное — не доказано, и, если авторы статьи правы, то это будет эквивалентно доказательству
Пусть в определении UMM,
Теорема доказана.
Алгоритмы
Посмотрим на примере как можно решать задачи на UMM (пока просто чтобы познакомится с моделью). Возьмем задачу о сумме подмножества (Subset Sum Problem, SSP).
Пусть есть множество
Экпоненциальный алгоритм
Пусть в нашей UMM мемпроцессоры расположены в матричном виде (см. рисунок). Определим три операции.
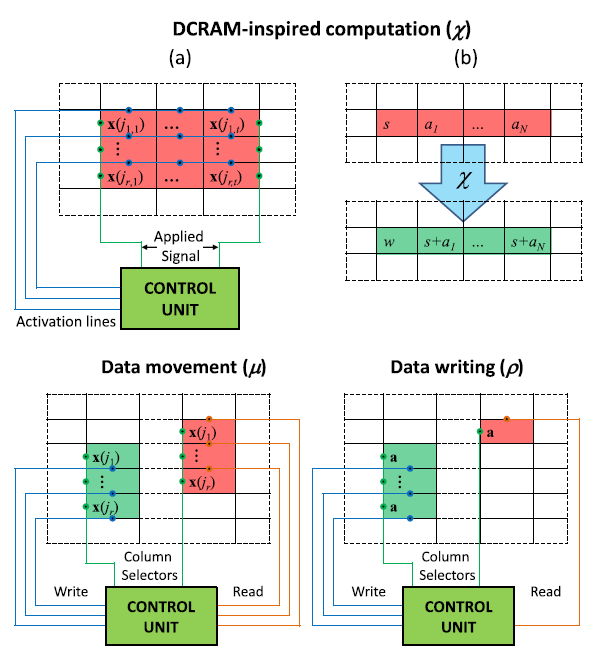
— это непосредственно вычисление. Используя активационные линии, мы можем выбрать строки и ограничивающие столбцы, в которых производятся вычисления. Суть вычисления в прибавлении значения крайней левой ячейки ко всей строке.
— это операция перемещения данных. Узел контроля выбирает две колонки и значения из первой копируются во вторую. Узел контроля не обязательно сам выполняет операцию копирования, он просто активирует колонки нужными линиями.
— операция, похожая на
Комбинируя эти три операции, мы можем получить функцию перехода
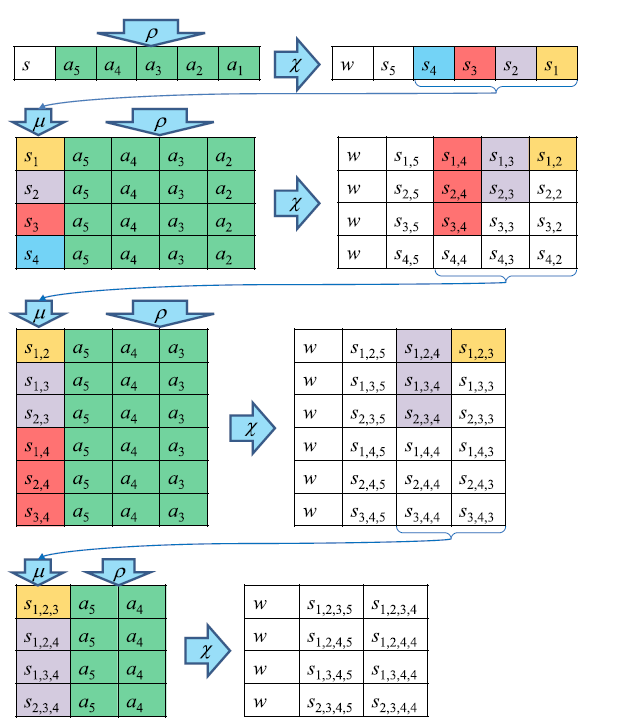
На первом шаге алгоритма мы получаем сумму всех подмножеств длиной
Теперь посчитаем сколько мемпроцессоров нам нужно для выполнения этих операций. На итерации k нам нужно
Думаю сейчас стало более-менее понятно что это за объект такой. Теперь перейдем к самому вкусному, что нам предлагает UMM, а именно к третьему свойству — information overhead.
Exponential Information Overhead
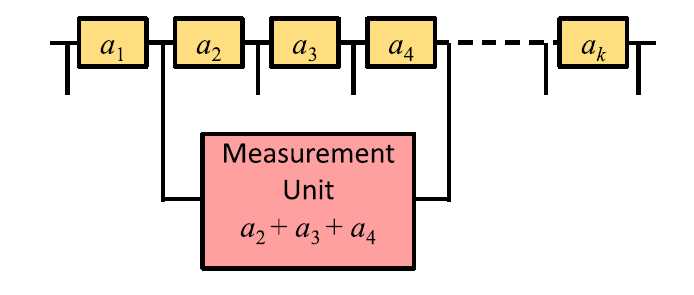
Пусть у нас имеются n мемпроцессоров, обозначим состояние выбранных мемпроцессоров как

Это устройство, подключенное к нескольким мемпроцессорам может считать состояние обоих, а значит их глобальное состояние, определяемое как
где
где
Теперь, имея множество
Теперь, беря n мемпроцессоров, мы выставляем ненулевые компоненты
Алгоритм решения SSP, использующий Exponential Information Overhead
Тут я вынужден сказать, что я так и не смог разобраться в деталях этого алгоритма (сложилось то, что я не так уж силен в электротехнике и обработке сигналов, а авторы, видимо, решили не расписывать все для таких неучей), но общая идея такая.
Для начала они предлагают посмотреть на функцию
Если мы раскроем скобки, то у нас будут произведения по всевозможным наборам индексов
Иными словами, наша функция
Теперь, все, что нам нужно — это применить к этому сигналу преобразование Фурье и посмотреть какие частоты имеются у нас в сигнале. Если у нас есть компонента с частотой
Если мы решаем эту задачу на обычном компьютере, то сейчас мы могли бы применить быстрое преобразование Фурье. Оценим асимптотику.
Для этого оценим количество точек, которое нужно взять из сигнала. По теореме Котельникова этих точек нужно
Таким образом, используя FFT мы можем решить задачу за
Теперь, своими словами (для более детального рассмотрения, обратитесь к оригинальным статьям), как они этого достигли.
Берем
Но это в нашей модели. В железе получается, что каждый мемпроцессор — генератор сигнала со своей частотой (соответствующий числу из
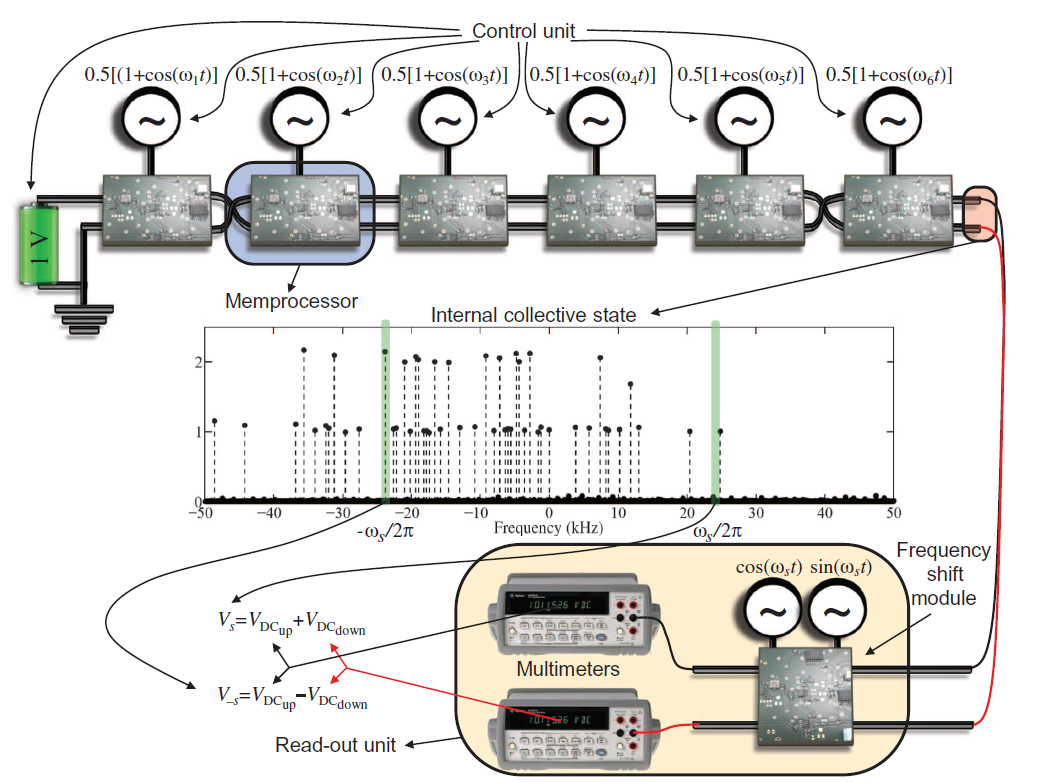
Ну и теперь, чтобы считать результат, нужно проверить есть ли в сигнале заданная частота. Вместо реализации FFT, они сделали железку, которая пропускает только заданную частоту (тут я тоже не совсем понял как, но это виноваты мои знания в электронике), которая уже работает за константное время.
Итого асимптотика по времени вообще составила
Некоторые проблемы модели
На самом деле, авторы хитро переложили «сложную» часть задачи, которая дает нам экспоненту, с программной части в техническую. В более ранней статье об этом вообще ни слова, в июльской они признаются в этом, но лишь несколькими строчками.
Дело все в кодировании сигнала (внятные объяснения я нашел здесь). Из-за того, что мы кодируем аналоговые сигналы, и используем дискретные генераторы сигналов, нам теперь нужна экспонентная точность по определению уровня сигнала (в той железке, которая вычленяет нужную частоту), что, возможно потребует экспоненты времени.
Авторы утверждают, что эту неприятность можно обойти, если вместо дискретных генераторов сигнала использовать аналоговые. Но у меня большие сомнения, что можно использовать аналоговые схемы для любого
Итог
Чудесной магии не произошло. NP полные проблемы по-прежнему сложны для вычислений. Так зачем я все это написал? Главным образом потому, что хоть физическая реализация сложна, сама модель кажется мне очень интересной, и их изучение необходимо. Скоро (если уже не сейчас) подобные модели будут иметь большое значение во многих сферах науки.
Например, как я уже упоминал, нейронные сети являются частным случаем UMM. Вполне возможно, что мы узнаем о нейронных сетях немного больше, если посмотрим на них с другой стороны, используя немного другой мат. аппарат.
Комментарии (9)

deniskreshikhin
06.01.2016 19:17+4Я не очень понял теоретическую часть, но что касается сигнальной части — выскажу свое мнение по двум пунктам.
1. Т.к. рабочая частота у электронных устройств ограничена, то при увеличении количества элементов N будет сужаться полоса для фильтров. Но что бы узкополосный фильтр выдал свой отклик, требуется подождать некоторое время ~ 1/df, где df ширина полосы этого фильтра.
В итоге с ростом N физическая скорость вычисления на 1 мемустройство будет оставаться той же самой.
Фактически это решение имеет квадратичную сложность, а не линейную. Т.к. с ростом N нужно увеличивать как количество фильтров, так и вермя ожидания.
2. Вообще создание константного алгоритма для некоторого фиксированного N не является проблемой, всегда можно составить таблицу которая будет хранить заранее подготовленные значения. Проблема только в памяти, которой не бывает слишком много.
Такая же беда и здесь, как нельзя построить ПЗУ бесконечной памятью, так нельзя построить и электронное устройство с бесконечной рабочей частотой.
Пример подхода, когда константный алгоритм зашит в аппаратную часть всем известен это умножение в ЦПУ. Ведь умножение даже двоичных чисел произвольной длины требует минимум N*log(N) операций. Т.к. с точки зрения математики умножение и свертка это операции имеющие одну и ту же природу.


sophist
07.01.2016 13:21Интересно, а с мемристорами как элементной базой идея мемпроцессоров как-нибудь состыковывается?

myxo
07.01.2016 14:41очень даже стыкуется. Мемристоры — естественные элементы для конструирования мемпроцессоров. Я об этом как-то не стал писать (хотел сконцентрироваться на другом), но в оригинальной статье приводятся, например, уравнения перехода, если делать мемпроцессор из мемэлементов.
lockywolf
08.01.2016 01:31Выглядит любопытно, но я несколько не понял:
«задачи из класса NP полных задач за полином времени и памяти.»
Полином по памяти — это очень плохо. NP \in PSPACE
Ну, и вторая проблема в том, что даже обычную машину тьюринга мы не можем сделать, потому что у неё по условию бесконечная лента, и это условие нельзя ослабить.
Правильно я понимаю, что у мемристорной машины для имитации бесконечной ленты требуется бесконечное число мемпроцессоров?
myxo
08.01.2016 02:09я вас тоже не понял
Полином по памяти — это очень плохо. NP \in PSPACE
Чего плохого-то?
По поводу бесконечной ленты да, нужно бесконечное кол-во мемпроцессоров.
supernapalm
На самом деле, если вы решаете одну NP-полную задачу за полином то сразу же решаете и ВСЕ NP задачи за полином. Причем в этой же модели вычислений, как я понимаю, раз она симулирует МТ. А если даже нет — на практике как раз свести (за полином) одну NP задачу к некоторой NP-полной совсем не проблема.
Поправьте если я не прав.
myxo
Все правильно за одним исключением: данная модель, при решении задач, не симулирует МТ (приведенная теорема была для иллюстрации того, что она в принципе может это делать). Она решает задачи, скажем так, по-своему.
В том и проблема равенства классов NP и P, что есть модели вычислений, которые решают NP полные задачи за полином (та же недетерминированная машина Тьюринга), но реализовать на практике мы
(пока что)можем только обычную машину Тьюринга. Поэтому есть, вообще говоря два выхода из положения. Понять как решать быстро задачи на МТ, либо предложить хорошую модель, которую мы сможем построить в нашей реальности.