

Swift словарь представляет собой контейнер, который хранит несколько значений одного и того же типа. Каждое значение связано с уникальным ключом, который выступает в качестве идентификатора этого значения внутри словаря. В отличие от элементов в массиве, элементы в словаре не имеют определенного порядка. Используйте словарь, когда вам нужно искать значения на основе их идентификатора, так же как в реальном мире словарь используется для поиска определения конкретного слова. (прим.)
Swift словарь:
- Swift словарь состоит из двух общих типов: ключей (должны относиться к категории Hashable) и значений;
- Можно создавать записи посредством введения ключа и его значения;
- Значение может задаваться через ссылку на введенный ранее ключ;
- Можно удалить запись, указав соответствующий ключ;
- Каждый ключ связан с одним единственным значением.
Существует несколько способов хранения данных записей (ключей, значений), один из которых предполагает открытую адресацию посредством линейного пробирования, необходимого для запуска Swift-словаря.
Рассмотрим пример словаря, рассчитанного на 8 элементов: в нем предусмотрено максимум 7 записей (ключей, значений) и, как минимум, одно пустое место (так называемый пробел) в буфере словаря, благодаря которому происходит своеобразная блокировка поиска по выборкам/вставкам (retrivals/insertions).
В памяти это будет выглядеть, примерно, так:

Постоянная память задается через:
size = capacity * (sizeof(Bitmap) + sizeof(Keys) + sizeof(Values))Если систематизировать данные логически, получаем что-то вроде:
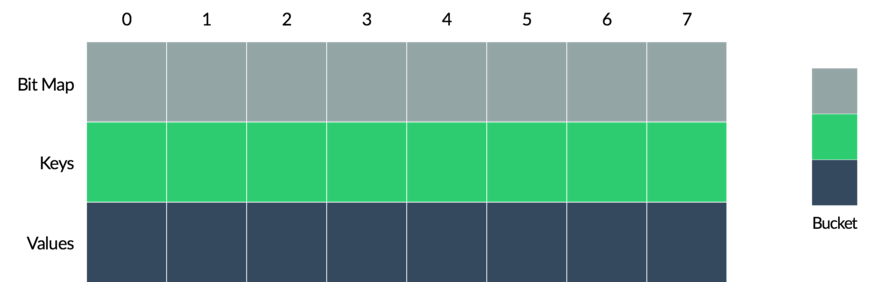
Каждая колонка образует сегмент памяти, в котором фиксируется три параметра: bitmap value, ключ и value.
Bitmap value в сегменте указывает, действительны и определены ли ключ и соответствующее значение. Если данные недействительны/неинициализированы, сегмент называется пробелом.
_HashedContainerStorageHeader (struct)
Эта структура выступает в качестве заголовка для будущего буфера памяти. В ней прописана емкость и сведения об объеме, где емкость — фактическая емкость выделенной памяти, а сведения об объеме – количество действительных элементов, находящихся в буфере на данный момент.
maxLoadFactorInverse — это коэффициент, позволяющий расширять буфер в случае необходимости._NativeDictionaryStorageImpl<Key, Value> (class)
Подкласс
ManagedBuffer<_HashedContainerStorageHeader, UInt8>Главная задача данного класса — выделить оптимальную для словаря память и создать указатели на bitmap, ключи и значения, которые впоследствии нужно будет обработать. Например:
internal var _values: UnsafeMutablePointer<Value> {
@warn_unused_result
get {
let start = UInt(Builtin.ptrtoint_Word(_keys._rawValue)) &+
UInt(_capacity) &* UInt(strideof(Key.self))
let alignment = UInt(alignof(Value))
let alignMask = alignment &- UInt(1)
return UnsafeMutablePointer<Value>(
bitPattern:(start &+ alignMask) & ~alignMask)
}
}
Поскольку память Bitmap, ключей и значений смежная, значение для указателей будут иметь вид:
internal class func create(capacity: Int) -> StorageImpl {
let requiredCapacity = bytesForBitMap(capacity) + bytesForKeys(capacity)
+ bytesForValues(capacity)
let r = super.create(requiredCapacity) { _ in
return _HashedContainerStorageHeader(capacity: capacity)
}
let storage = r as! StorageImpl
let initializedEntries = _BitMap(
storage: storage._initializedHashtableEntriesBitMapStorage,
bitCount: capacity)
initializedEntries.initializeToZero()
return storage
}
В процессе создания буфера все записи в bitmap приравниваются нулю, то есть все сегменты памяти, по сути, представляют собой пробелы. Стоит также отметить, что для подобного способа хранения информации общий тип ключа данного класса вовсе не обязательно должен быть Hashable.
// Примечание: Предполагается, что здесь используются ключ, значение
// (без: Hashable) - это хранилище должно работать
// с типами, отличными от Hashable.
_NativeDictionaryStorage<Key : Hashable, Value> (структура)
Эта структура фиксирует сохраненную информацию в буфере и подбирает функцию, преобразующую смежную выделенную память в массив логического сегмента. Также обратите внимание на то, что окончание массива сегмента связано с началом массива, благодаря чему образуется логическое кольцо. А, значит, если вы в конце массива сегмента и запрашиваете следующую функцию, в итоге, вас перенаправят к началу массива.
Для того, чтобы осуществить вставку или задать значение с помощью ключа, необходимо выяснить, к какому сегменту этот ключ принадлежит. Так как ключ у нас Hashable, подойдет функция hashValue, результатом которой служит Int. Правда указанное hashValue может превышать емкость буфера словаря, а потому, возможно, придется его сжать в пределах от нуля до максимального значения емкости:
@warn_unused_result
internal func _bucket(k: Key) -> Int {
return _squeezeHashValue(k.hashValue, 0..<capacity)
}
Мы можем перемещаться между сегментами, обращаясь к опциям
_next и _prev. Емкость всегда представляет собой число, которое можно выразить в двоичной системе. Если мы находимся в конце массива сегмента, при желании откат к исходной позиции задается через вызов _next.internal var _bucketMask: Int {
// The capacity is not negative, therefore subtracting 1 will not overflow.
return capacity &- 1
}
@warn_unused_result
internal func _next(bucket: Int) -> Int {
// Bucket is within 0 and capacity. Therefore adding 1 does not overflow.
return (bucket &+ 1) & _bucketMask
}
@warn_unused_result
internal func _prev(bucket: Int) -> Int {
// Bucket is not negative. Therefore subtracting 1 does not overflow.
return (bucket &- 1) & _bucketMask
}
Для добавления нового элемента нам понадобится узнать, к какому сегменту он будет принадлежать и затем вызвать функцию, вставляющую соответствующий ключ и значение в выбранный сегмент, а также задающую действительные параметры для записи bitmap.
@_transparent
internal func initializeKey(k: Key, value v: Value, at i: Int) {
_sanityCheck(!isInitializedEntry(i))
(keys + i).initialize(k)
(values + i).initialize(v)
initializedEntries[i] = true
_fixLifetime(self)
}
Функция _find
- Функция _find позволяет выяснить, какой сегмент будет задействован при работе с ключом (вставка или выборка);
- Запрашивает исходный сегмент для ключа, чтобы вызвать
_bucket(key); - В случае, если ключ в параметре совпадает с ключом сегмента, возвращает на исходную позицию объекта;
- Если объект не найден, расположение первого пробела определяется возможным участком для вставки ключа;
- Bitmap позволяет проверять сегменты, отделяя заполненные участки от пробелов;
- Это и есть линейное пробирование (linear probing);
/// Поиск для данного ключа начинается с указанного сегмента.
///
///Если ключ не обнаружен, возврат к месту его возможной
/// вставки.
@warn_unused_result
internal
func _find(key: Key, _ startBucket: Int) -> (pos: Index, found: Bool) {
var bucket = startBucket
// The invariant guarantees there's always a hole, so we just loop
// until we find one
while true {
let isHole = !isInitializedEntry(bucket)
if isHole {
return (Index(nativeStorage: self, offset: bucket), false)
}
if keyAt(bucket) == key {
return (Index(nativeStorage: self, offset: bucket), true)
}
bucket = _next(bucket)
}
}
- Фактически, squeezeHashValue – индикатор того, что ключ присутствует в массиве сегмента, но возможны, коллизии. Например, у двух ключей могут быть одинаковые значения хеш;
- В таком случае выберите функцию, которая выявит ближайший сегмент для вставки ключа.
Именно поэтому при анализе значений хеш Hashable выступает в роли, едва ли не идеальной функции, гарантирующей высокую производительность.
- squeezeHashValue действительно пытается создать отличный хеш с помощью нескольких опций;
- Похоже, для того, чтобы при исполнении программы сохранить различные значения хеш, ядро запуска было привязано к hashValue, указанному в типе ключа. Правда, мы говорим о постоянном значении заполнителя;
_BitMapstruct используется в качестве оболочки, позволяющей читать и делать записи в bitmap.
Наглядно получаем, примерно, следующее:

_NativeDictionaryStorageOwner (class)
Этот класс создан для отслеживания правильного подсчета сносок для копий, сделанных в процессе записи. Так как сохранение данных осуществляется с помощью опций Dictionary и DictionaryIndex, счетчик ссылок будет присваивать вводимой информации значение 2, но, если словарь относится к вышеупомянутому классу и количество ссылок для него отслеживается, вам не о чем беспокоиться.
/// Данный класс – идентификатор запуска COW. Он
/// необходим исключительно для разделения уникальных счетчиков ссылок для:
/// — `Dictionary` и `NSDictionary`,
/// — `DictionaryIndex`.
///
/// Это важно, поскольку проверка на уникальность для COW проводится исключительно
/// для выявления счетчиков первого вида.
Так это выглядит не очень приятно:

_VariantDictionaryStorage<Key : Hashable, Value> (перечисляемый тип)
Этот перечисляемый тип работает с двумя операторами Native/Cocoa в зависимости от сохраняемых в них данных.
case Native(_NativeDictionaryStorageOwner<Key, Value>)
case Cocoa(_CocoaDictionaryStorage)
Основные характеристики:
- Перечисляемый тип, основанный на Native или Cocoa, задает функции корректировки в процессе сохранения информации в словаре для таких операций, как, как вставка, выборка, удаления и т.д;
- Расширяет объем памяти для хранения данных по мере ее заполнения;
- Обновляет или задает связку ключ-значение.
- Если необходимо удалить Значение из массива сегмента, может появиться пробел, который вызовет побочные эффекты в процессе пробирования, что приведет к его преждевременному прерыванию. Для предотвращения подобных негативных явлений важно учитывать позиции всех элементов словаря.
/// - параметр idealBucket: идеальный сегмент, предполагающий возможность удаления элемента.
/// - параметр offset: офсет элемента, который будет удален.
///Необходима инициализация записи на смещение.
internal mutating func nativeDeleteImpl(
nativeStorage: NativeStorage, idealBucket: Int, offset: Int
) {
_sanityCheck(
nativeStorage.isInitializedEntry(offset), "expected initialized entry")
// удалить элемент
nativeStorage.destroyEntryAt(offset)
nativeStorage.count -= 1
// Если в ряду смежных элементов появляется пробел,
// некоторые элементы после пробела могут заполнить промежуток нового пробела.
var hole = offset
// Определите первый сегмент смежного ряда
var start = idealBucket
while nativeStorage.isInitializedEntry(nativeStorage._prev(start)) {
start = nativeStorage._prev(start)
}
// Определите последний сегмент смежного ряда
var lastInChain = hole
var b = nativeStorage._next(lastInChain)
while nativeStorage.isInitializedEntry(b) {
lastInChain = b
b = nativeStorage._next(b)
}
// Перемещайте элементы, перенесенные на новые места в ряду, повторяя процедуру до тех пор,
// пока все элементы не окажутся на соответствующих позициях.
while hole != lastInChain {
// Повторите проверку в обратном направлении, с конца ряда смежных сегментов в поиске
// элементов, оставшихся не на своих местах.
var b = lastInChain
while b != hole {
let idealBucket = nativeStorage._bucket(nativeStorage.keyAt(b))
// Элемент оказался между началом и пробелом? Нам необходимо
// два отдельных теста с учетом возможного появления упаковщиков [начало, пробел]
// в конце буфера
let c0 = idealBucket >= start
let c1 = idealBucket <= hole
if start <= hole ? (c0 && c1) : (c0 || c1) {
break // Found it
}
b = nativeStorage._prev(b)
}
if b == hole { // No out-of-place elements found; we're done adjusting
break
}
// Переместите найденный элемент на место пробела
nativeStorage.moveInitializeFrom(nativeStorage, at: b, toEntryAt: hole)
hole = b
}
}

И вот как выглядит наш словарь
(всего лишь один из видов перечисляемых данных)

Комментарии (2)

dirtyHabrBobr
26.01.2016 14:57+1Тогда уж и коммент из источника возьмем
It seems you're using first-come-first-serve linear probing. Why not robinhood (with backshifting)? As far as I know, this significantly improves average search times, even when increasing the load factor. This is the current strategy that Rust's HashMap takes (load factor 0.91).
Instead of a bitset, we also store the hashes themselves to facilitate the robinhood checking (we set the most-significant bit of hashes so 0 doesn't occur naturally). This also provides a fastpath for equality checking. Even under a collision, the full (63-bit) hash is unlikely to be equal, so you only only ever incur the cost of looking at the keys when you hit an exact hash-match, which is almost guaranteed to be an exact key match. You don't expect to ever look at the keys if the key isn't present.
ragequit
Как обычно, обо всех неточностях, ошибках и просто казусах перевода прошу сообщать в ЛС. Спасибо.