

Мы сделали это! Несколько сотен наших application-серверов переведены на PHP7 и прекрасно себя чувствуют. Насколько нам известно, это второй переход на PHP7 проекта такого масштаба (после Etsy). В процессе мы нашли несколько очень неприятных багов в системе кеширования байт-кода PHP7, но они исправлены. А теперь — ура! — благая весть для всего PHP-сообщества: PHP7 действительно готов к продакшену, стабилен, потребляет значительно меньше памяти и дает очень хороший прирост производительности. Ниже мы подробно расскажем, как мы перешли на PHP7, с какими трудностями столкнулись, как с ними боролись и какие результаты получили. Но начнем с небольшого введения.
Мнение о том, что узким местом в веб-проектах является база данных — одно из самых распространенных заблуждений. Хорошо спроектированная система сбалансирована — при увеличении входной нагрузки удар держат все части системы, а при превышении пороговых значений тормозить начинает все: и процессор, и сетевая часть, а не только диски на базах. В этой реальности процессорная мощность application-кластера является чуть ли не самой важной характеристикой. Во многих проектах этот кластер состоит из сотен или даже тысяч серверов, поэтому «тюнинг» процессорной нагрузки на кластере приложений оказывается более чем оправданным экономически (миллион долларов в нашем случае).
Процессор в веб-приложениях PHP «съедает» столько же, сколько и любой высокоуровневый динамический язык — много. Но у PHP-разработчиков годами была особенная печаль (и повод для сильнейшего «троллинга» со стороны прочих сообществ) — отсутствие в PHP «честного» JIT или хотя бы генератора в компилируемый текст на языках типа С и С++. Неспособность сообщества предоставить подобные решения в рамках основного проекта породило неприятную тенденцию: крупные игроки стали придумывать собственные решения. Так появились HHVM в Facebook, KPHP во «Вконтакте», наверняка были и другие «поделки».
К счастью, в 2015 году сделан первый шаг к тому, чтобы PHP стал «взрослее»: вышел PHP7. JIT в PHP7 так и не появился, однако результат изменений в «движке» трудно переоценить: теперь на многих задачах PHP7 даже без JIT не уступает HHVM (см., например, бенчмарки из блога LiteSpeed и бенчмарки из презентации разработчиков PHP7). Новая архитектура PHP7 также упрощает дальнейшее добавление JIT.
Платформенные разработчики в Badoo пристально следили за этими страстями последние несколько лет и даже сделали пилотный проект с HHVM, но решили дождаться PHP7, поскольку посчитали его более перспективным. И недавно мы запустили Badoo на PHP7! Это был эпичный проект как минимум из-за размера: у нас больше 3 миллионов строк кода на PHP и 60 000 тестов. О том, как мы со всем этим справились, попутно придумав новый фреймворк для тестирования PHP-приложений (уже выпустили в open source — похож на Go! AOP) и сэкономили целый миллион — читайте дальше.
Опыты с HHVM
Перед переходом на PHP7 мы некоторое время искали другие способы оптимизировать наш backend. Конечно, первым делом мы решили «поиграться» с HHVM.
Потратив пару недель на исследование, мы получили весьма достойные результаты: после прогрева JIT на нашем фреймворке выигрыш по скорости и использованию CPU составлял сотни процентов.
Однако HHVM обладал неприятными недостатками:
- сложный и медленный деплой. При деплое необходимо обязательно прогревать JIT-кеш. В момент прогрева машина не должна быть нагружена продакшен-трафиком, потому как работает все достаточно медленно. Прогревать параллельными запросами тоже не рекомендуется. Короче, фаза прогрева большого кластера — операция небыстрая, плюс на большой кластер в несколько сотен машин надо научиться выкладывать порционно. В итоге получаем нетривиальную архитектуру и процедуру деплоя с непредсказуемым временем работы. А мы хотим иметь максимально простой и быстрый деплой: важной частью нашей девелоперской культуры является выкладка двух плановых релизов в день и возможность быстро «раскатать в бой» хотфиксы;
- неудобство тестирования. Для юнит-тестирования мы активно использовали расширение runkit, которое отсутствует в HHVM. Мы подробнее расскажем об этом дальше, но если вы вдруг не в курсе, то это такое расширение, которое позволяет на лету менять поведение переменных, классов, методов, функций практически как угодно, и делается это через весьма «хардкорную» интеграцию с «внутренностями» PHP. Ядро HHVM лишь отдаленно похоже на ядро PHP, так что эти самые «внутренности» там абсолютно разные. Поэтому реализовать runkit поверх HHVM самостоятельно — адов труд: из-за особенностей расширения нам пришлось бы переписывать десятки тысяч тестов, чтобы убедиться, что HHVM правильно работает с нашим кодом. Нам это показалось нецелесообразным. Если быть честными, это было проблемой любого из вариантов, и при переходе на PHP7 нам все равно пришлось переделать очень многое, в том числе выкинуть runkit, но об этом позже;
- совместимость. В первую очередь это неполная совместимость с PHP 5.5 (см. github.com/facebook/hhvm/blob/master/hphp/doc/inconsistencies, github.com/facebook/hhvm/issues?labels=php5+incompatibility&state=open) и несовместимость с уже написанными расширениями, а у нас их десятки. Обе несовместимости вытекают из очевидного структурного недостатка проекта: HHVM разрабатывается не сообществом, а отделом внутри Facebook. В таких случаях компаниям значительно проще поменять внутренние правила и стандарты, не оглядываясь на сообщество и тонны уже написанного кода. Им проще переделать все под себя, решить проблему своими ресурсами. Поэтому, чтобы успешно работать при таких же объемах задач, нужно иметь сравнимый по мощности ресурс и для первичного этапа внедрения, и для дальнейшей поддержки. Это рискованно и потенциально дорого — мы так рисковать не хотели;
- перспективы. Несмотря на то, что Facebook — большая компания с классными программистами, у нас были большие сомнения в том, что отдел разработки HHVM может оказаться мощнее PHP-сообщества. Мы полагали, что как только внутри PHP появится что-то похожее, все доморощенные проекты начнут медленно, но верно умирать.
И мы стали ждать PHP7.
Переход на новую версию интерпретатора — важный и сложный процесс, поэтому мы готовились к нему, составив четкий план перехода. Он состоял из трех этапов подготовки:
- изменение инфраструктуры для сборки и деплоя PHP и адаптация множества написанных нами расширений;
- изменение инфраструктуры и окружения тестирования;
- изменения PHP-кода приложений.
Расскажем обо всех этапах подробнее.
Исправления в ядре и расширениях
У нас есть собственная, активно поддерживаемая и дорабатываемая ветка PHP. Мы начали проект по переводу Badoo на PHP7 еще до его официального релиза, поэтому нам надо было плавно обеспечить регулярный rebase PHP7 upstream в наше дерево, чтобы иметь возможность получать обновления каждого релиз-кандидата. Все патчи и кастомизации (см. секцию «Патчи» нашего техсайта tech.badoo.com/open-source), которые мы используем в повседневной работе, также должны были быть портируемыми между версиями и работать корректно.
Мы автоматизировали выкачивание и сборку всех зависимостей, экстеншенов и дерева PHP под 5.5 и 7.0. Это не только упростило работу, но и дало хороший задел на будущее: когда выйдет версия 7.1, у нас уже все будет готово.
Над экстеншенами тоже пришлось попотеть. Мы подерживаем около 40 расширений, причем больше половины — внешние расширения open source с нашими доработками.
Для максимально быстрого перехода мы решили запустить параллельно два процесса. Первый — перепиcать самостоятельно самые критичные для нас расширения: шаблонизатор Blitz, кеш данных APcu в Shared memory, сбор статистики в Pinba и некоторые кастомные для работы с внутренними сервисами (в итоге около 20 расширений).
Второй — активно избавляться от расширений, которые используются в некритичных частях инфраструктуры. Легко избавиться нам удалось от 11 расширений — немало!
И, конечно, мы начали активно общаться с людьми, которые поддерживают основные открытые расширения, используемые нами, на предмет совместимости с PHP7 (отдельное спасибо Дерику Ретансу (англ. Derick Rethans), который разрабатывает Xdebug).
Далее мы немного подробнее остановимся на технических деталях портирования расширений под PHP7.
В 7-й версии PHP-разработчики изменили много внутренних API, что вызвало необходимость правки большого количества кода в экстеншенах. Самые важные изменения следующие:
- zval * > zval. Ранее, при создании новой переменной, структура zval всегда аллоцировалась, а теперь используется структура из стека;
- char * > zend_string. В PHP7 используется агрессивное кеширование строк в ядре PHP, поэтому в новом ядре повсеместно перешли с обычных строк на структуру zend_string, в которой хранится строка и ее длина;
- изменения в API массивов. Теперь используется zend_string в качестве ключа, в имплементации массивов заменили double linked list на обычный массив, который выделяется одним блоком вместо множества маленьких.
Все это позволило кардинально уменьшить количество небольших аллокаций памяти и в результате ускорить ядро PHP на десятки процентов.
Нужно отметить, что все эти изменения повлекли за собой необходимость если не переписывать, то активно править все экстеншены. Если в случае со встроенными экстеншенами мы могли рассчитывать на их авторов, то наши разработки могли править только мы, а правок нужно было много: из-за изменения внутренних API некоторые части кода было проще переписать.
К сожалению, введение новых структур, использующих сбор мусора, одновременно с ускорением выполнения кода усложняет сам движок и нахождение проблем в нем. Одной из них стала проблема в OPcache, которая заключалась в следующем: при очистке кеша байт-код закешированного файла разрушался в тот момент, когда он еще мог использоваться в другом процессе, что приводило к падению процесса. Внешне это выглядело так: строки (zend_string) в названиях функций или констант вдруг разрушаются и вместо них появляется мусор.
Поскольку у нас используется значительное количество экстеншенов собственной разработки, многие из которых активно работают со строками, то в первую очередь подозрение пало на неправильное использование строк в них. Написали много тестов, провели много экспериментов, но всё безрезультатно. В итоге пришлось обратиться за помощью к основному разработчику ядра PHP — Дмитрию Стогову.
В первую очередь он спросил, очищался ли кеш. Выяснили, что, действительно, в каждом случае так и было. Стало понятно, что проблема все-таки не у нас, а в OPcache. Мы быстро воспроизвели проблему и Дмитрий исправил ее в течение пары дней. Без этого исправления, которое вошло в версию PHP 7.0.4, использовать ее стабильно в продакшене было нельзя!
Изменение инфраструктуры тестирования
Тестирование в Badoo — наша особенная гордость. PHP-код мы выкладываем в продакшен 2 раза в день, в каждую выкладку у нас попадает 20-50 задач (мы используем feature branch в Git и автоматизированную сборку билдов с тесной JIRA-интеграцией). При таком графике и объеме задач без автотестов никак.
На сегодняшний день у нас около 60 тысяч юнит-тестов примерно с 50%-м покрытием, которые проходят в среднем за 2-3 минуты в облаке (об этом мы уже рассказывали на Хабре). Помимо юнит-тестов, мы используем автотесты более высокого уровня — интеграционные и системные тесты, selenium-тесты для веб-страниц и calabash-тесты для мобильных приложений. Все это разнообразие позволяет нам в кратчайшие сроки сделать вывод о качестве каждой конкретной версии кода и принять соответствующие решения.
Переход на новую версию интерпретатора — кардинальное изменение. Возможных проблем может быть сколько угодно, поэтому крайне важно, чтобы все тесты работали. Для того чтобы стало понятно, что, как и почему мы делали, необходимо совершить небольшой экскурс в историю и рассказать про эволюцию развития тестов в нашей компании.
Часто люди, задумывающиеся о тестировании своих продуктов, сталкиваются в процессе экспериментов (а некоторые уже при внедрении) с тем, что их код к этому не готов. Действительно, разработчик должен помнить о том, что его код должен быть тестируемым. Архитектура должна позволять юнит-тестам подменять вызовы и объекты внешних зависимостей, чтобы изолировать тестируемый код от внешних условий. Надо сказать, что требование это усложняет жизнь, и многие программисты из принципа не хотят писать код так, чтобы его можно было тестировать — навязываемые ограничения вступают в неравную борьбу с прочими ценностями «хорошего кода» и обычно проигрывают. И часто, представив себе объем имеющегося кода, написанного не по правилам, экспериментаторы просто откладывают тестирование до лучших времен либо пытаются довольствоваться малым, покрывая тестами только то, что можно покрыть (в итоге тесты не всегда дают ожидаемый результат).
Наша компания — не исключение. Мы тоже начали внедрять тестирование далеко не сразу после старта проекта. Было уже написано немало строк кода, который вполне себе работал в продакшене и приносил хорошие деньги. Переписывать весь этот код ради возможности покрыть его тестами так, как рекомендуется, вышло бы слишком долго и дорого.
К счастью, на тот момент уже был отличный инструмент, который позволял решить большинство проблем с нетестируемым кодом — runkit. Это расширение для PHP, которое позволяет во время исполнения скрипта менять, удалять, добавлять методы, классы и функции, используемые в программе. Он может еще много чего, но другие функции расширения мы не использовали. Инструмент разрабатывался и поддерживался в течении нескольких лет (с 2005 по 2008 годы) Сарой Гоулман (англ. Sara Golemon), которая сейчас работает в Facebook, в том числе и над HHVM. А с 2008 года и по сегодняшний день проект поддерживает наш соотечественник Дмитрий Зенович (работал руководителем отделов тестирования в «Бегуне» и Mail.Ru). И мы тоже немножко «наконтрибутили» в проект.
Сам по себе runkit — очень опасный экстеншен. С его помощью можно менять константы, функции и классы прямо во время работы скрипта, который их использует. По сути, это инструмент, с помощью которого можно перестроить ваш самолет прямо во время полета. Runkit лезет в самые внутренности PHP на лету; одна ошибка или недоработка в runkit — и самолет красиво взрывается в воздухе, PHP падает, либо вы проводите много часов в поиске утечек памяти и прочей низкоуровневой отладке. Тем не менее, это был для нас необходимый инструмент: внедрить тестирование в проект без серьезного переписывания можно только так, через изменение кода на лету, просто заменяя его на нужный.
При переходе на PHP7 runkit оказался большой проблемой — эту версию PHP он не поддерживал. Был вариант спонсирования разработки новой версии, но этот путь не казался нам самым надежным в долгосрочной перспективе. Параллельно мы рассматривали несколько других вариантов.
Одним из перспективных решений было перейти с runkit на uopz. Это тоже расширение PHP c похожей функциональностью, появившееся в апреле 2014 года. Его нам предложили коллеги из «Mамбы», дав очень хорошие отзывы в первую очередь о скорости работы. Проект поддерживает Джо Уоткинс (англ. Joe Watkins) из First Beat Media (UK). Выглядел этот проект более живым и перспективным по сравнению с runkit. Но, к сожалению, перевести на uopz все тесты у нас не получилось. Где-то случались фатальные ошибки, где-то сегфолты — мы завели несколько репортов, но по ним, увы, движения нет (подробнее см. например этот баг на github). Обойтись переписыванием тестов в этом случае получилось бы очень дорого, да и не факт, что не выявилось бы что-то еще.
В результате мы пришли к очевидному для нас решению: раз нам и так необходимо переписать множество кода и при этом все равно зависеть от внешних проектов типа runkit или uopz, с которыми у нас постоянно появляются проблемы, которые очень дорого либо невозможно решать самостоятельно, то почему бы уже не переписать код так, чтобы по максимуму все зависимости убрать? Да так, чтобы подобных проблем у нас больше никогда не возникало, даже если мы захотим перейти на HHVM или любой другой подобный продукт. И тогда у нас появился свой фреймворк.
Система получила название SoftMocks. Слово soft подчеркивает, что система работает на чистом PHP вместо использования расширений. Это проект open source, он доступен в виде подключаемой библиотеки и находится в открытом доступе. SoftMocks не завязан на особенности реализации ядра PHP и работает с помощью переписывания кода на лету, по аналогии с фреймворком Go! AOP.
В нашем коде тестов в основном используются следующие вещи:
- Подмена реализации одного из методов класса.
- Подмена результата выполнения функции.
- Изменение значения глобальной константы или константы класса.
- Добавление метода в класс.
Все эти возможности прекрасно реализуются с помощью runkit. При переписывании кода это становится возможным, но с некоторыми оговорками.
Описание работы SoftMocks — материал для отдельной статьи, которую мы в ближайшее время напишем. А пока ограничимся лишь кратким описанием работы этой системы:
- пользовательский код подключается через функцию-обертку rewrite. После этого все операторы include автоматически рекурсивно подменяются на обертки;
- внутрь определения каждого пользовательского метода добавляется проверка на существование подмены, и если она есть, то выполняется соответствующий код. Прямые вызовы функций заменяются на вызов через обертку — это позволяет перехватывать как встроенные, так и пользовательские функции;
- обращения к константам в коде также динамически подменяются на вызов обертки;
- SoftMocks в работе использует PHP-Parser Никиты Попова. Эта библиотека не очень быстрая (парсинг примерно в 15 раз медленнее token_get_all), но предоставляет удобный интерфейс для обхода синтаксического дерева и дает удобный API для работы с синтаксическими конструкциями произвольной сложности.
Вернемся к нашей задаче — переходу на PHP7. После того как мы стали использовать в проекте SoftMocks, у нас осталось около 1000 тестов, которые требовалось «починить» вручную. Это можно считать неплохим результатом, если учесть, что изначально у нас было 60 000 тестов. Скорость их прогона по сравнению с runkit не уменьшилась, так что в плане производительности серьезных потерь от использования SoftMocks нет. Справедливости ради отметим, что uopz все-таки должен работать заметно быстрее.
Утилиты и код приложения
Помимо множества нововведений, PHP7 принес с собой и некоторые обратные несовместимости. Первое, с чего мы начали изучение проблемы — это чтение официального migration guide. Быстро стало понятно, что без исправления имеющегося кода мы рискуем как получить в продакшене фатальные ошибки, так и столкнуться с изменением поведения, которое не будет отражено в логах, но приведет к неправильной логике работы приложения.
Badoo — это несколько репозиториев кода на PHP, самый крупный из которых содержит более 2 миллионов строк кода. Причем на PHP у нас реализовано множество вещей: начиная от бизнес-логики веба и бекенда мобильных приложений и заканчивая утилитами тестирования и выкладки кода. Кроме этого ситуация осложнялась тем, что Badoo — проект с историей, ему уже 10 лет, и наследие PHP4, к сожалению, все еще присутствовало. Соотвественно, метод «пристального вглядывания» неприменим. Неприменима и «бразильская система», то есть выложить в продакшен как есть и смотреть, что сломается, чересчур увеличивает риски сломать бизнес-логику для слишком большого процента пользователей. Поэтому мы стали искать возможность автоматизировать поиск несовместимых мест.
Сначала мы попытались использовать наиболее популярные среди разработчиков IDE, но, к сожалению, на тот момент они либо просто не поддерживали синтаксис и особенности PHP7, либо обнаруживали подозрительно мало проблем, пропуская, очевидно, опасные места в коде. После небольшого исследования было решено попробовать утилиту php7mar. Это такой несложный статический анализатор кода, реализованный на PHP. Очень прост в использовании, работает довольно быстро, результат предоставляет в виде текстового файла, требует наличия PHP7. Конечно, данная утилита не является панацеей, имеются как ложные срабатывания, так и пропуски особенно «хитрых» мест в коде. Но около 90% проблем с ее помощью удалось обнаружить, что существенно ускорило и облегчило процесс подготовки кода к работе под PHP7.
Наиболее часто встречающимися и потенциально опасными проблемами для нас были:
- изменение поведения функций func_get_arg() и func_get_args(). В пятой версии PHP эти фунции возвращали значения аргументов функций на момент их передачи, а в седьмой версии — на момент вызова func_get_args(). Таким образом, если внутри функции до вызова func_get_args() переменная агрумента изменяется, то есть риск получить поведение, отличное от пятой версии. Это тот самый случай, когда в логах будет пусто, а бизнес-логика приложения может оказаться сломанной;
- непрямое обращение к переменным, свойствам и методам объектов. И снова опасность в том, что поведение может измениться «молча». В документации достаточно подробно описано, в чем именно заключаются отличия;
- использование зарезервированных имен классов. В PHP7 стало нельзя использовать bool, int, float, string, null, true и false в качестве имени класса. Да-да, у нас был класс Null. К счастью, этот случай уже проще, потому как приводит к ошибке;
- очень много было найдено потенциально проблемных конструкций foreach, которые используют ссылку. Но практически все из них вели себя одинаково в пятой и седьмой версии, так как мы и раньше старались внутри foreach не изменять итерируемый массив и не рассчитывать на его внутренний указатель.
Остальные случаи несовместимости либо встречались крайне редко (как, например модификатор ‘e’ для регулярных выражений), либо исправлялись простой заменой (например, теперь все конструкторы должны называться __construct(), использовать имя класса запрещено).
Но, перед тем как начать исправление кода, мы подумали, что пока одни разработчики вносят необходимые для совместимости изменения, другие будут продолжать писать несовместимый с PHP7 код. Для решения этой проблемы мы добавили pre-receive hook в каждый Git-репозиторий, который выполнял на изменяемых файлах php7 -l, т.е. проверял их на соответствие синтаксису PHP7. Это не гарантирует полную защиту от несовместимоcти, но уже устраняет ряд проблем. В остальных же случаях разработчикам просто приходилось быть чуть внимательнее. Кроме того, мы стали делать регулярный прогон полного набора тестов под PHP7 и сравнивать результаты с прогонами под PHP5. При этом использовать любые новые возможности PHP7 разработчикам было запрещено, т.е. старый pre-receive hook с php5 -l мы не выключали. Это позволило нам в определенный момент получить код, совместимый как с седьмой, так и с пятой версией интерпретатора. Почему это важно? Потому что помимо проблем с PHP-кодом, при обновлении на новую версию возможны проблемы с самим PHP7 и его расширениями (собственно, как сказано выше, мы с этими проблемами и столкнулись). И, к сожалению, не все из них воспроизводились в тестовом окружении, некоторые мы смогли увидеть только под значительной нагрузкой в продакшене.
«Запуск в бой» и результаты
Очевидно, нам требовался простой и быстрый способ менять версию PHP на любом количестве любых серверов. Для этого во всем коде пути к CLI-интерпретатору были заменены на /local/php, который, в свою очередь, являлся симлинком либо на /local/php5, либо на /local/php7. Таким образом, для изменения версии PHP на сервере требовалось изменить ссылку (операция атомарна — это важно для CLI-скриптов), остановить php5-fpm и запустить php7-fpm. Можно было бы иметь в nginx два upstream для php-fpm, запускать php5-fpm и php7-fpm на разных портах, но этот вариант нам не понравился усложением конфигурации nginx.
После того как все вышеперечисленное было выполнено, мы смогли перейти к прогону selenium-тестов в препродакшен-окружении, что позволило нам обнаружить ряд проблем, не замеченных ранее. Они каcались как PHP-кода (например, пришлось отказаться от устаревшей глобальной переменной $HTTP_RAW_POST_DATA в пользу file_get_contents(«php://input»)), так и расширений (разного рода ошибки сегментирования).
Исправив обнаруженные на предыдущем этапе проблемы и закончив переписывание юнит-тестов (в ходе которого нам тоже удалось обнаружить несколько багов в интерпретаторе, например, такой), мы наконец приступили к «карантину» в продакшене. «Карантином» мы называем запуск новой версии PHP на ограниченном числе серверов. Начали с одного сервера в каждом крупном кластере (бекенд веба и мобильных приложений, облако), постепенно увеличивая количество, если ошибок не возникает. Первым крупным кластером, полностью перешедшим на PHP7, стало облако. Причиной этому послужило отсутствие на нем потребности в php-fpm. Тем же кластерам, где работает fpm, пришлось подождать до тех пор, пока мы не обнаружили, а Дмитрий Стогов не исправил проблему с OPcache. После этого мы уже перевели и fpm-кластер.
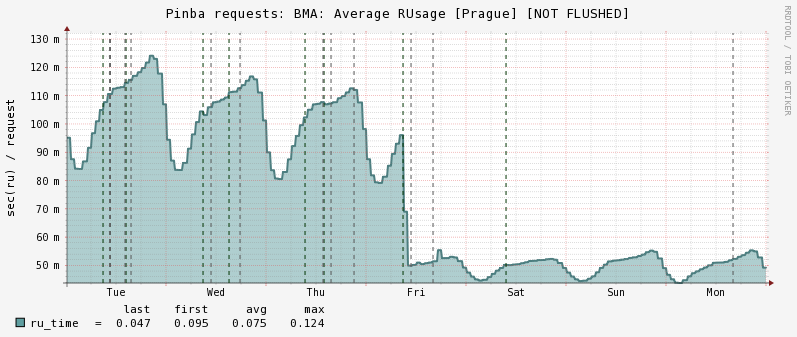
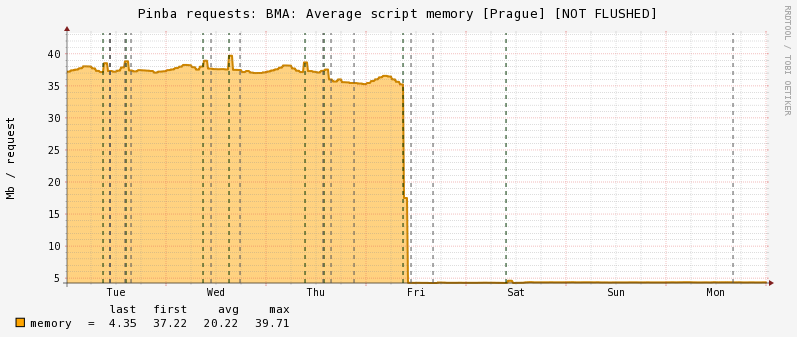
Теперь о результатах. Если коротко, то они более чем впечатляют. Ниже приведены графики времени ответа, rusage, потребления памяти и использования процессора в самом крупном (263 сервера) из имеющих у нас кластеров, а именно — бекенда мобильных приложений в пражском дата-центре:
Распределение времён ответа:
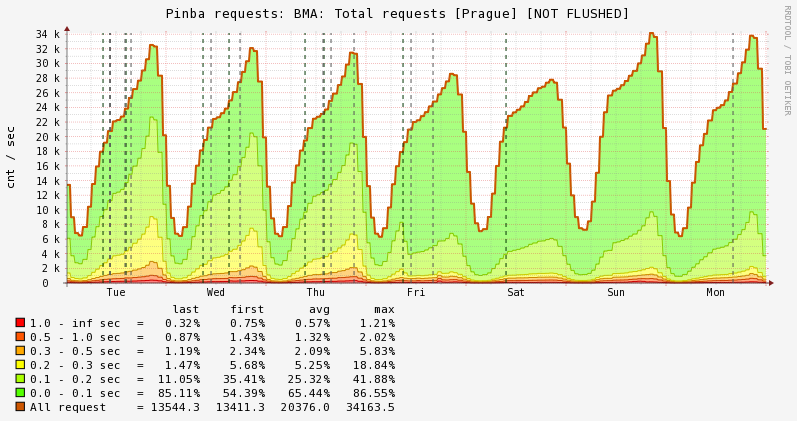
RUsage (CPU time):
Memory usage:
CPU load (%) на всём кластере:
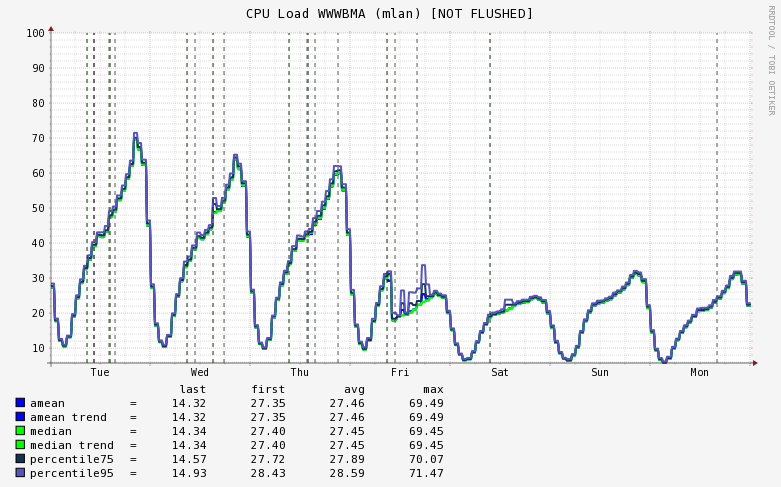
Таким образом, процессорное время сократилось в 2 раза, что улучшило общее время ответа примерно на 40%, так как некоторая часть времени при обработке запроса тратится на общение с базами и демонами, и с переходом на PHP7 эта часть никак не ускоряется, что ожидаемо. Кроме того, эффект несколько усиливается тем, что общая нагрузка на кластер упала ниже 50%, что указывает на некоторые особенности в работе технологии Hyper-Threading. Грубо говоря, при увеличении нагрузки выше 50% начинают работать HT-ядра, которые не настолько «полезны», как ядра физические, но это уже тема для другой статьи.
Потребление памяти, хотя никогда и не являлось для нас узким местом, снизилось примерно в 8 раз! И, наконец, мы сэкономили на оборудовании — теперь мы можем на том же количестве серверов выдерживать намного большую нагрузку, что, по сути, снижает затраты на его приобретение и обслуживание. Результаты на остальных кластерах отличаются незначительно, разве что выигрыш на облаке чуть скромнее (порядка 40% CPU) из-за отсутствия там OPcache.
Сколько мы сэкономили в деньгах? Давайте посчитаем. Кластер серверов приложений у нас состоит из 600 с лишним серверов. Снизив использование CPU в два раза, мы получаем экономию примерно в 300 серверов. Добавив начальную цену такого «железа» (порядка 4000$ за каждый) и амортизацию, получаем около миллиона долларов экономии плюс около ста тысяч в год на хостинге! И это не считая облака, производительность которого также выросла. Считаем, что это — отличный результат!
А вы уже перешли на PHP7? Будем рады услышать ваше мнение и вопросы в комментариях.
Комментарии (252)

bestxp
11.03.2016 14:43+15Отлично отлично, живой пример оптимизации php7 на реальных данных, молодцы ребята

NightTiger
11.03.2016 14:48+5О, неожиданно ) Спасибо что сохранили копирайты на мою идею и на оригинальную реализацию в моем фреймворке!
fisher а почему не стали использовать готовое? Сейчас у меня версия 2.0-dev фреймворка работает как раз на PHP-Parser, поддерживает 5.6 и 7.0, имеет интеграцию с опкэшем и прозрачный механизм дебага. Вроде все что вам нужно, уже там есть для тестов )
youROCK
11.03.2016 14:59+1Про Soft Mocks ждите отдельную статью, в которой мы более подробно опишем, что и как :)

Vidog
11.03.2016 14:49-40Вы не сэкономили $1M, а потеряли, т.к. теперь есть 300 лишних серверов
symbix
11.03.2016 15:09+23Л — Логика
BasilioCat
11.03.2016 16:33-6В защиту первого коммента хочу сказать, что сервера не облачные и не в аренде ("… снижает затраты на его приобретение и обслуживание"), следовательно 300 освободившися серверов все равно будут стоять в ожидании роста числа посетителей (что не гарантировано) или увеличения нагрузки из-за растущей сложности приложений. То есть по факту перехода на PHP7 компания обнаружила, что уже потратила на закупку и будет тратить кучу денег на обслуживание уже ненужных серверов ;)

inkvizitor68sl
11.03.2016 16:56+5В большой компани всегда есть куда девать сервера, badoo — не исключение.
Also, всегда можно их использовать для увеличения отказоустойчивости всех сервисов.youROCK
11.03.2016 18:31+10Или включения новых фич, запуск которых откладывали из-за создаваемой нагрузки (спойлер :))
symbix
11.03.2016 19:44+3При их скоростях роста и объемах закупок железа — как раз просто сэкономили денег, просто не понадобится в ближайшие полгода-год докупать.
А если уж совсем излишек — можно банально продать: там Германия рядом, где полно low-end хостеров, вряд ли будет сложно найти покупателя.


Nikolay_Smeh
11.03.2016 15:11+6Есть ли подобная статья на английском? Коллегам показать.

Badoo
14.03.2016 20:12+1Английская версия статьи: https://techblog.badoo.com/blog/2016/03/14/how-badoo-saved-one-million-dollars-switching-to-php7/
dbelka
11.03.2016 15:17+3Мнение о том, что узким местом в веб-проектах является база данных — одно из самых распространенных заблуждений.
Золотые слова!
Как появятся все необходимые расширения под PHP7, так будем пробовать перейти.
tony2001
11.03.2016 16:21+2Подавляющее большинство расширений уже есть.
Вам каких не хватает?
shmaltorhbooks
11.03.2016 18:21redis, например
tony2001
11.03.2016 18:32Вижу там бранч php7: https://github.com/phpredis/phpredis/tree/php7
Не пробовали его?
zapimir
11.03.2016 19:56+5Тоже долго не переходили на PHP7 из-за Redis. Но потом почитали доки, оказалось у редиса же простейший протокол.
В итоге перешли на PHP7 + TinyRedisClient. Только допилили немного, чтобы пайплайнинг работал.
symbix
11.03.2016 21:33+2Predis очень шустро работает и без расширений. От опционального ext/phpiredis профит заметен только на жирных pipeline-ах с огромными ответами, подозреваю, что от перехода на PHP7 профит намного заметнее.

miga
11.03.2016 15:32+19Судя по графикам, на php7 вы переключились в пятницу?
ivansimonov
11.03.2016 22:41+6Увлекательно. Графики будут нагляднее, если начинать их от нуля, а не 5 или 50. Визуально выглядит, что память теперь вообще не используется.



zim32
11.03.2016 15:35-2Подскажите, вместе с пхп7 не стоит ждать настоящий fast_cgi?
tony2001
11.03.2016 16:20+2Дайте, пожалуйста, определение настоящего FastCGI.
zim32
11.03.2016 16:33+1это чтобы я мог написать где-то в коде контроллера echo $counter++ и и получить 1....2....3....4 на каждый заход.

Alexufo
11.03.2016 16:42Демона хотите из пыха сделать?) Ну вроде архитектура не та.
Меня интересует вот такая часть этой области, которую я не могу понять (платформа винда правда)
http://stackoverflow.com/questions/31731371/why-only-6-php-fastcgi-wokers-loaded-on-iis-8zim32
11.03.2016 16:49http://stackoverflow.com/questions/985431/max-parallel-http-connections-in-a-browser

fisher
11.03.2016 16:51+2о, это очень старая история, но она от семёрки вообще не зависит
в PHP принята абсолютно не побоюсь этого слова гениальная stateless модель fcgi, с полным очищением памяти после завершения выполнения запроса, практически гарантирующая отсутствие "распухание" по памяти и прочую радость в продакшене
ну и отдельно скажу что для share nothing архитектур состояние в приложении — злоNightTiger
11.03.2016 16:57Я все вот мечтаю, что рано или поздно они добавят shared-объекты между процессами с volatile-модификаторами для переменной, тогда в шаред-памяти можно хранить будет настоящие инстансы, например, подключений к базе или прогретые контейнеры классов и т.д.
В этом случае все остальное бы благополучно чистилось, а специальные объекты могли бы переживать несколько запросов. Но! Это должно быть обязательно с реализацией нормального IPC API, чтобы не было как mysql_pconnect и всяким шлаком в нем при повторном запросе.
Sannis
11.03.2016 17:16Какой смысл делать всё такие крутое если при рестарте всё равно пропадут данные?
А persistent connections к сервисам можно и так делать на уровне расширений.
gricom
14.03.2016 20:00я не могу найти ссылку на документацию, где было бы рассказано, как имплементить persistent connection к своему кастомному сервису. Не подскажете, где почитать?
Sannis
14.03.2016 22:53+2На документацию по написанию PHP extension с поддержкой persistent connect?
На деле всё не так просто и о persistent connection нужно думать начиная с протокола взаимодействие клиента с сервером.
А уже во вторую очередь думать о том как это сделать в расширении для определённого языка.
Для начала, ИМХО, стоит начать отсюда: http://www.slideshare.net/rybaxek/pconnect-12329335.

bolk
11.03.2016 20:27+2тогда в шаред-памяти можно хранить будет настоящие инстансы, например, подключений к базе
Есть persistent connection ко всем распространнёным СУБД, к сокетам и к memcached.

fear86
11.03.2016 20:36+2В чем проблема? memcache, redis, mongodb и прочие — решают эту проблему. Плюс дает вам возможность выбора конкретного решения под конкретную задачу. Нужно хранить объекты в памяти? вот вам memcache. Нужно шарить в кластере? Вот вам redis или mongo. Еще есть сессии, который нативные, и которые можно перенести по требованию в memcache или любое другое место. Ну а если вам нужен демон, то пишите демона, php отлично с этим справляется.
SantyagoSeaman
13.03.2016 17:29Нужно хранить объекты в памяти? вот вам memcache.
- Сериализация-десериализация крупных объектов может стать проблемой. Гораздо логичнее использовать уже созданный объект в shared memory. Конечно, это добавляет головняка с race conditions и на любое обновление данных придётся вешать мьютекс, но производительность сего решения может стоить того. Особенно если задача состоит в хранении крупного иммутабельного объекта вроде конфига, редко меняющегося и часто читаемого.
- Данный подход хорош для атомарных сущностей. Если же для инициализации объекта необходима инициализация зависимостей, то тут уже без велосипеда на костылях не обойтись.
fear86
13.03.2016 19:54+2Возможно тогда вам нужен не php? Есть же вон ruby, go, python, java (тут вообще ближе всего к пхп, так как из нее уже почти все перетянули). Там как раз с этим будет проще, и не надо будет извращаться.
Так же можно не ждать, а сделать самому) http://zephir-lang.com/SantyagoSeaman
13.03.2016 20:47+1Я к тому, что идея shared memory в PHP имеет право на жизнь. Хранить сериализованные данные в одном из хранилищ — это не всегда выход. Собственно, APCU частично решает эту задачу. Но было бы круто вслед за мега-фичей в виде PHP FPM следующим шагом дать нативный инструмент работы с объектами в shared memory.
Мне довелось поработать с true Fast CGI на С++. Это ад. Но сама идея иметь объекты, живущие между запросами, жива и её вполне можно было бы органично имплементировать в стандарте языка.fear86
13.03.2016 20:58+1Кстати есть же http://php.net/manual/en/book.shmop.php и http://php.net/manual/en/book.pthreads.php, так что можно что то придумать )
SantyagoSeaman
13.03.2016 21:14+2pthreads — совсем не то
shmop — почти то, если к нему ещё прикрутить мьютексы. И всё равно требует сериализации.
Идеально было бы: высокоуровневая языковая конструкция, позволяющая создавать и использовать объекты в разделяемой памяти с внутренней имплементацией exclusive&shared locking и TTL чтобы у дева голова об это не болела.
fear86
13.03.2016 21:04Ну и конечно же, у всего этого есть один большой минус который проигрывает микросервисному подходу. Вы будете ограниченны одним физическим сервером. Расшарить свой объект на 1+n серверов не получится.
SantyagoSeaman
13.03.2016 21:22+1Шарить что-то между серверами — это совсем другой уровень. Межпроцессный шаринг объектов очень пригодился бы для хранения тяжёлых read-only объектов вроде конфигов. На больших нагрузках может неплохо съэкономить на создании сокета, хендшейке, поиске информации в хранилище, отправке, закрытии соединения, десериализации. Всё это абсолютно лишнее, если уже готовый собранный конфиг лежит в виде zval где-то в памяти.

vintage
13.03.2016 21:32+1RO конфиги проще при деплое транслировать в PHP (или сразу писать их на PHP) и при первом обращении полученный для них байткод будет закеширован.
SantyagoSeaman
13.03.2016 21:38Да, это отличный подход, если конфиг не представляет собой здоровенное DOM-дерево с обёрткой вокруг для унификации и упрощения доступа.
vintage
13.03.2016 22:10DOM легко и просто транслируется во что угодно с помощью XSLT. ;-)
SantyagoSeaman
13.03.2016 22:21И что? Вопрос же не в том, как хранить и преобразовывать, а в том, чтобы вообще не создавать тяжёлые объекты на каждый запрос, а пользоваться расшаренными. Кеши байткода избавляют от стадии компиляции. Но не избавляют от процесса создания объекта. А это те самые потерянные миллисекунды и процессорное время, которое вполне можно было бы потратить на что-то полезное. Да и конфиги — это малая из бед. Половину аппликейшена можно было бы реюзать если был бы нормальный инструмент. Естественно, апплекейшн пришлось бы изначально проектировать как стейтлесс, но это уже тема для отдельного топика.
Конечно, можно было бы использовать язык, изначально заточенный под event-loop или с легковесными потоками как в Go. Но не вижу никаких препятствий запилить нечто подобное и в Пыхе. Всё равно имхо к этому идёт.
p4s8x
15.03.2016 18:16+1Конечно, можно было бы использовать язык, изначально заточенный под event-loop или с легковесными потоками как в Go. Но не вижу никаких препятствий запилить нечто подобное и в Пыхе. Всё равно имхо к этому идёт.
Много раз пытались "слезть с PHP" — везде свои плюсы и минусы.
Меня тоже очень интересуют объекты(immutable типа), зашаренные в память. Задача похожая — считывание огромного конфига. На самом деле даже иногда быстрее создать объект с нуля, чем заниматься десериализацией. Мы сейчас используем apcu+igbinary, поглядываем на всякие reactphp\icicle\amphp, но вообще есть идея попробовать реализовать это самостоятельно, взяв за основу APCu расширение, пока не очень понятно — можно ли это на самом деле реализовать.vintage
15.03.2016 18:32-2Так в чём оказалась проблема "слезть с PHP"?
p4s8x
15.03.2016 22:01+4Потому что это действие не решает ни одной конкретной бизнес задачи.
А с выходом PHP7 желания куда-то дергаться сильно поубавилось, а в RFC PHP7.1 все тоже становится очень приятно.vintage
16.03.2016 09:28-5А какие у вас бизнес задачи? Например, повышение эффективности процесса разработки является бизнес задачей или нет? А уменьшение багоёмкости? А уменьшение потребления ресурсов?
PHP стал в два раза меньше тормозить, да. Но значит ли это, что он сравнялся по эффективности с компилируемыми языками?AntonStepanenko
16.03.2016 10:48+2Откуда у вас такая ненависть к PHP? Да, gcc -O2 быстрее. Но у него есть свои минусы. И и других компилируемых языков они есть. Как есть и у PHP. Просто есть задачи, а есть инструменты их решения. Вы же почему-то решили применять один инструмент ко всем задачам, да ещё и остальным это мнение навязывать.
vintage
16.03.2016 14:26-6А откуда у вас такая любовь к устаревшим языкам типа PHP и C? Для меня просто это уже пройденный этап. Современные компилируемые языки вполне позволяют писать выразительный и быстрый код одновременно.
AntonStepanenko
16.03.2016 15:04+4Вы делаете утверждения без аргументов и вешаете ярлыки. Кроме этого, вы подменяете понятия: эффективность это не только и не столько скорость работы. PHP не сравнялся с компилируемыми языками по скорости исполнения, но вы говорите об эффективности, а это уже другое, значительно более широкое понятие. Всем этим вы в лучшем случае продемонстрируете свой идеализм и максимализм, а в худшем — очень скромный опыт коммерческой разработки, если не его отсутствие.
Отвечая на ваш вопрос — у меня нет "такой любви" к PHP. У меня любовь к использованию подходящих решений для разных задач. PHP, например, подходит для веб-разработки. Потому что высокая скорость разработки, большое комьюнити, множество готовых решений, и большой рынок разработчиков. При этом, естественно, отдельные части логики могут и должны быть реализованы на более подходящих для этого технологиях. Например, для особо требовательных к производительности компонентов неплохо подходит C или Go.
И, пожалуйста, перестаньте рассказывать сказки про 10-кратное превосходство 1 разработчика на D. Возможно, лично для вас некоторые языки это пройденный этап, но, к сожалению (или к счастью), есть очень много проектов, которые разрабатываются не только вами.

Fesor
16.03.2016 10:53+3Но значит ли это, что он сравнялся по эффективности с компилируемыми языками?
Нет конечно, до компилируемых еще далеко (хотя если jit добавят, а его добавят рано или поздно, хотя и уже есть всякие HippyVM и HHVM), но не для такого большого количества проектов производительность языка важнее производительности команды разработчиков. Удобство разработки (перезагрузил страничку и увидел результат), удобство деплоймента (stateless модель)… в целом для большинства проектов php — хороший выбор. Да и те, где производительность важна — опять же узкие места можно написать на всяких go/scala.vintage
16.03.2016 14:58-3В статье же упомянули проблемы прогрева JIT. Тут разве что AOT помочь может, как в .NET.
А можно сразу писать на чём-то типа Vibe.D, где рекомпиляция проекта проходит за секунды, сейчас пилят балансировщик, который сможет hot-swap, где не требуется установка интерпретатора (выложил бинарник и всё), не нужен прогрев, есть безопасная работа с shared memory, корутины, вебсокеты и прочее, прочее, прочее. А узкие места нет необходимости переписывать на другом языке и потом "дружить" с исходным.Fesor
16.03.2016 16:49+1hidden complexity. Увы, но разработчика который хорошо знает D надо еще поискать. D пока не получил такого распространения, что бы можно было безболезненно брать и делать весь проект только на нем. Даже тот же фэйсбук, в котором сидит Александреску, пилит на D только дев и внутренние тулы (в частности помниться был очень интересный проект статического анализатора для C++ и для ускорения сборки какие-то веселые штуки).
есть безопасная работа с shared memory, корутины, вебсокеты и прочее, прочее, прочее.
Если shared memory в качестве места хранения очень горячих данных — apcu — все есть, все даже относительно безопасно. Корутины — есть в php с версии 5.5 (2012-ый год), websockets — тут проще поднять сервачек на socket-io. Банально дешевле (как с точки зрения написания сервера так и с точки зрения написания клиентов, особенно если надо будет потом мобильные приложеньки пилить). Связать все каким pub/sub на zeromq (опять же готовые решения, все делается очень быстро если не нужно что-то нестандартное, а в рамках MVP оно не надо), и вот вам из коробки готовые солюшены, с подтверждением доставки сообщений, с готовыми реализациями чатиков и т.д.
А узкие места нет необходимости переписывать на другом языке и потом «дружить» с исходным.
YAGNI. Возможно проект, как и тысячи других, просто не доживет до проблем с производительностью и нагрузками. И в этом плане проще взять парочку толковых php разработчиков, запилить на нем MVP и в бой. А то что за сервак придется платить не 20 баксов а 50 — ну так и фиг с ним.
Тут разве что AOT помочь может, как в .NET.
В дискуссиях на php internals большая часть людей именно за AOT. Один из кор контрибьюторов php (ircmaxell) даже грозился сделать это дело в виде расширения хотя бы для кода, использующего сильную динамическую типизацию (информация о типах есть, что еще надо?). Но для этого надо решить еще парочку проблем.vintage
16.03.2016 17:22-5Разработчика, который хорошо знает PHP тоже поискать придётся ;-) А толковому разработчику разобраться в D не составит особого труда. Особенно JS-разработчику, ведь VibeD похож на NodeJS+node-fibers.
На самом деле это проблема многих руководителей — они ищут разработчиков на определённом языке, вместо того, чтобы искать разработчиков с опытом в определённой области.
apcu насколько я понял — это просто сериализация в общую память. Это не особо эффективно.
Корутин в PHP я не нашёл, только генераторы. Разница в наличие стека у корутин.
php+nodejs+zeromq — ну да, это куда проще, чем несколько строчек на VibeD, любой PHP-шник с завязанными глазами за пару минут сделает :-D

saksmt
19.03.2016 03:57+1Я конечно всё понимаю, но зачем писать о скале, будто это что-то сложное? Она же проще пыхи, лишь бы мозги были в правильную сторону развёрнуты (пяток акторов на акке, в слик и морду спрэя наружу = высокопроизводительное stateless [если конечно не совсем деревянный писал] приложение). Я конечно понимаю, что под скалу разрабов днём с огнём не сыщешь, да и тех, что найдёшь отправишь обратно (ЗП пхпшника * 3), но всё же.
Касательно большинства проектов: нынче в моде ресты, а как по мне значительно проще накидать элементарные контроллеры на спринге, сотворить POJO для hibernate и приправить аннотациями (для небыдла: роуты на кэмэле + сервисы в osgi для логики + mybstis с парой запросов + опционально конфиги в зукипере), чем громоздить неведомо что на пыхе (да симфони, да доктрина, да jmsserializer, но по объёму и выразительности кода — беда, это уже не говоря о производительности и масштабируемости).Fesor
19.03.2016 10:33+1Я конечно всё понимаю, но зачем писать о скале, будто это что-то сложное?
Некоторым компаниям у нас в Минске было настолько сложно найти адекватных Scala разработчиков, что они в итоге просто брали PHP разработчиков, жестко их фильтровали по "повернутости мозга" и переучивали на скалу. Причем делалось это все на перспективу.
Если же вы планируете стартовать разработку продукта, скалу брать имеет смысл только если у вас уже есть команда разработчиков на скале. Ибо иначе придется месяца 3-4, за которые можно было бы набросать MVP, тупо потратить на поиск и обучение сотрудников.
Вопрос банальной рациональнотси.
по объёму и выразительности кода — беда
У PHP и Java одна объектная модель. По функционалу Doctrine не сильно уступает Hibernate, Symfony — хороший такой клон Spring-а. А теперь объясните, как это при таком раскладе у PHP может быть все плохо с выразительностью? Вот честно, может быть вы просто видели плохие проекты на PHP? Их не мало, чуть больше чем для Java.
Если уж говорить про Kotlin, то тут про выразительность поверю.
не говоря о производительности и масштабируемости
PHP разработчики дешевле, так что даже если надо будет в два раза больше серверов, до какого-то момента это всеравно будет дешевле чем брать джавистов. А с масштабироемостью у PHP вообще проблем нет — stateless модель выполнения же.
Если огромное множество различных проектов, где я бы не стал брать PHP, с другой стороны, есть куда более огромное количество проектов, где PHP хорошо себе подходит. И больше встает вопрос о культуре разработки. Если разработчики на пыхе тесты пишут, знают что такое рефакторинг и технический долг — то я бы не особо парился. А еще есть ruby, там с культурой разработки в среднем получше. А есть java, где вроде бы все должно быть еще лучше, но практика показывает, что это такой же стериотип как "все php-ники быдло".saksmt
20.03.2016 16:20-1Вопрос банальной рациональнотси.
По коммерческой стороне всё понятно. Я про сторону разрабов и про то, что мне не всегда понятен выбор неглупых разрабов в пользу пыхи.
У PHP и Java одна объектная модель.
Да, но у явы как ни странно сахара больше и кода для какого-нибудь реста писать надо порядочно меньше. Особенно ярко это на уровне сериализации/десериализации из json/xml и валидации всего этого чуда (посмотрите spring-rest (camel + camel-validation, для "небыдла") — поймёте о чём я).
По функционалу Doctrine не сильно уступает Hibernate
Ну не считая "магических интерфейсов" — да. А вот mybatis (запросы пишешь сам, маппятся автоматически) найти для пыхи несколько сложнее.
Вот честно, может быть вы просто видели плохие проекты на PHP?
Видел и плохие и хорошие, да и сам в общем-то писал. И как разработчик скажу — кода на пыхе нужно писать больше. А у ж хороший такой DSL в пыхе — очень большая редкость.
Если уж говорить про Kotlin, то тут про выразительность поверю.
Он кстати не плох, но если знаешь скалу, то не нужен совершенно (ИМХО). Груви с грельсами кстати пхпшнику будет ближе — очень похож на пыху, за счёт динамической типизации, а грельсы очень похожи на симфони.
Если огромное множество различных проектов, где я бы не стал брать PHP, с другой стороны, есть куда более огромное количество проектов, где PHP хорошо себе подходит.
Весь мой спич сводится к тому, что ниша пыха — динамические сайты, а мы живём в мире с одностраничными приложениями. А рест на пыхе — не самая приятная вещь. + в мире микросервисов пыха тоже достаточно ограничена (например хорошо спроектированные микросервисы на яве можно запустить как в одной jvm, так и на разных машинах)
И больше встает вопрос о культуре разработки.
Вот с этим-то в пыхе как раз всё и плохо. Большинство разрабов даже об ООП не слышало, какой там тех.долг, тесты и рефакторинг. Пару раз встречал кадров, которые смотрят на тебя круглыми глазами, когда ты им говоришь о тестах, кодстайле и CI.
Конечно в яве такое тоже встречается, но это в целом редкость. И да я видел говнокод на яве, но по "силе запаха" он не так плох как говнокод на пыхе.
Если разработчики на пыхе тесты пишут, знают что такое рефакторинг и технический долг — то я бы не особо парился.
А я бы сильно удивился, что они до сих пор остаются в гнилом напрочь сообществе. (Хотя быть может это только я Иуда свалил)
стериотип как «все php-ники быдло»
Проблема в том, что этот стереотип процентов на 80 верен, как бы это ни было печально.Fesor
20.03.2016 17:28мне не всегда понятен выбор неглупых разрабов в пользу пыхи.
Опять же вопрос экономической эффективности. Я на PHP пишу 50% времени, еще 40% — javasript, и еще 10% — всякие баши пайтоны и т.д. Могу на go пописать если нужно будет. Но с большего php решает все мои задачи.
Неглупый разработчик должен понимать, то язык программирования это всего-лишь инструмент, и становиться мастером молотка и при этом понятия не иметь как с отверткой работать… Надеюсь поняли сравнение.
А я бы сильно удивился, что они до сих пор остаются в гнилом напрочь сообществе
На самом деле наблюдается тенденция улучшения в этом плане последние пару лет. Если бы я ее не видел я бы уже давно крест на PHP поставил.saksmt
20.03.2016 20:20-1Опять же вопрос экономической эффективности.
Мы ж вроде про "со стороны разрабов" говорим… Или я просто что-то недопонял?
На самом деле наблюдается тенденция улучшения в этом плане последние пару лет.
Да, но для сравнения посмотрите как меняются js, python, java. Вот это тенденция к улучшению (особенно js), а у пыхи как-то с этим печально — да добавили нэймспэйсы с трейтами и тайпхинты, но при этом первым слабо пользуются, второе в принципе не понимают, а на третье частенько приходится забивать из-за отсутствия дженериков (про седьмую версию я просто молчу — это ж надо было додуматься ТАК сделать).
Да о чём вообще можно говорить если до сих пор живы kohana, codeigniter и т.п.?

Fedot
14.03.2016 13:13-1Если хочется хранить только read-only объекты между запросами, то можно использовать reactphp, phppm или нечто подобное. Именно shared memory они не дают, но позволяют инициализировать окружение 1 раз и потом просто обрабатывать запросы.
Fesor
19.03.2016 10:44то можно использовать reactphp, phppm или нечто подобное.
То что вы перечислили не решает проблему хранения read-only объектов, поскольку нам надо будет делать несколько процессов воркеров в любом случае. То есть нам опять же нужно key-value хранилище в shared memory, что предоставляет нам APC user cache. Что до того что вы написали...
reactphp — это просто обертка над event loop для php, позволяющая писать приложения в стиле ноды. Я не вижу перспектив у него, поскольку уже есть более удачная реализация amphp на корутинах.
php-pm — это реализация SAPI на php для проектов использующих абстракцию от http, со своим управлением процессами и несколькими стратегиями для оного. Основное предназначение — что бы невилировать время бутстраппинга приложения.Fedot
19.03.2016 12:22Основное предназначение — что бы невилировать время бутстраппинга приложения
По моему именно эту проблему человек хотел решить тем что у него будет 1 read-only объект в shared memory. Да в подходе php-pm будет несколько копий объекта на каждый процесс, но время на его чтение с диска будет потрачено 1 раз, на запуск сервиса, а не на каждый запрос.
По поводу reactphp и amphp.
Я пока глубоко не копал amphp, но на первый взгляд они с reactphp похожи, так как amphp так же построен вокруг event loop. Хотя реализация у них разная, основная идея по моему у них схожа.
Так что я думаю что они будут развиваться параллельно.Fesor
19.03.2016 13:26По моему именно эту проблему человек хотел решить тем что у него будет 1 read-only объект в shared memory.
Изначально человек хотел решить проблему реюза коннекшенов в базе, что бы держать расшаренный пул соединений, или там хэндлеры очередй и т.д. и т.п. Просто данные хранить — для этого apcu есть и не надо из-за этого отказываться от умирающей парадигмы пыха.
А проекты типа php-pm — тут нужен уже другой уровень разработчиков, которые понимают что "делать stateful сервисы плохо", или как справляться с сайд эффектами в их коде (мутация состояний и состояние в принципе). А так то что я видел на реальных проектах — такая же умирающая модель выполнения, просто время бутстраппинга воркера (по сути загрузка фреймворков и т.д.) не влияли на время обработки запроса. Профит в этом есть, но не снижение нагрузки. Слишком часто находятся сайд эффекты в вендорных библиотеках и т.д. Для того что бы все было хорошо нужен тотальный контроль за всем кодом, который присуствует в проекте.
Так что я думаю что они будут развиваться параллельно.
вся соль именно в том что reactphp это тупо event loop, с колбэками и промисами. А amphp — это уже чуть другой уровень, полноценные крутины, почти async/await. По сути reactphp не развивается уже года два. Я бы свое время инвестировал в amphp, поскольку там уже реализовано больше.

alexkbs
15.03.2016 06:08Ну положите в Memcached объект типа Closure, например
fear86
15.03.2016 08:09-1В чем проблема то? Serialize и вперед. Другое дело что memcache ничего не хранится постоянно, это не база данных. И расчитывать, что то что вы туда положили, получится забрать нельзя.
alexkbs
15.03.2016 10:10+2Ну, расскажите, как Closure в кеш положить. Если в этом нет проблемы, как вы говорите.
Например, для массива:
echo serialize([1]);
мы положим в кеш это
a:1:{i:0;i:1;}
А теперь попробуйте так:
$example = function () use(&$example) { return 1; }; if ($example instanceof Closure) { echo serialize($example); }
Что мы положим в кеш?AntonStepanenko
15.03.2016 11:09Способы-то есть. Либо через eval(), но тогда появляются проблемы со ссылками, либо через Reflection. Есть даже готовые библиотеки: https://github.com/opis/closure, https://github.com/jeremeamia/super_closure. Но, по-моему, сериализация лямбд представляет чисто академический интерес.
fear86
15.03.2016 11:12Далеко нет, имеет отличное применение во всяких job queue. Лично пользуюсь super_closure + jmsjob.
AntonStepanenko
15.03.2016 11:16Лично моё мнение — сериализации подлежат только данные, но не логика работы с ними. Иначе это слишком много свободы, вопросы по безопасности (eval до добра не доведёт) и скорости работы. Хотя настаивать не буду, на вкус и цвет все фломастеры разные.
fear86
15.03.2016 11:17Все зависит от конкретных задач, если использовать closure как точку входа для асинхронных процессов, а всю логику хранить в моделях, то можно жить.
fear86
15.03.2016 11:26Closure нельзя но можно объект с методом __invoke или через рефлексию как super_closure сделать. Было бы желание )
Fesor
15.03.2016 10:19+1Начнем с того что смысла ложить Closure в memcached нет вообще никакого. Да и вообще держать "инстансы" в shared memory обычно ведет к диким сайд эффектам, особенно в руках неопытных php разработчиков. С другой стороны opcache и так держит опкоды в shared memory.
По поводу хранения ресурсов в shared memory — да как бы не проблема, любой вид IPC в принципе можно организовать. Другой вопрос — а оно вам надо?
Лично мне больше нравится подход всяких там php-pm, где можно просто по окончанию запросов прибивать все stateful сервисы (а их должно быть мало), где не нужно рвать коннект к базе (но надо следить за транзакциями и локами и т.д. то есть чистить после себя, а разработчики не очень хорошо с этим дружат, иначе не надо было бы изобретать сборщик мусора).
При очень большом желании для PHP можно даже файберы замутить.alexkbs
15.03.2016 10:25-1Вы о чем вообще?
Скромно напомню что тред начат с желания того комментатора получить "полноценный" FastCGI. Затем другой автор сказал что FastCGI не нужен, ибо всё можно в кеш засунуть. На что я предложил засунуть в кеш Closure (что невозможно)Fesor
15.03.2016 10:41суть замыканий и анонимных функций в том, что бы они находились в нужном контексте, обычно это какие-то одноразовые штуки. Да и потом, opcache неплохо хэндлит такие штуки и устраняет большую часть оверхэда на рантайм. Хотя с обычными функциями получше будет конечно.
Обсуждалось не "половижить все в кэш" а положить все общее в shared memory (если речь о коде, то opcache так и делает), в том числе ресурсы, сокеты, коннекшены к базам и т.д. И работать со всем этим через какую-то красивую API на IPC.
А не "положить Closure" в кэш. В этом нет никакой практической пользы. Но да, сериализовать замыкания можно, хоть это и попахивает извращением.alexkbs
15.03.2016 11:26"обычно это какие-то одноразовые штуки" — вы просто не умеете их готовить :)
Посмотрите хоть на код любого современного приложения на JS — замыкания в них идут сплошняком.
Суть замыканий в снижении связанности программы путём функционального DI, без необходимости создавать классы под каждую потребность. Если бы их можно было сериализовать, то можно было сохранять и повторно использовать экземпляры классов с произвольно измененным поведением. Впрочем, считайте как хотите. Не рассчитывайте на дальнейшие ответы.Fesor
15.03.2016 12:04в рамках функционального программирования функция не хранит состояния, то есть чистые функции — как раз таки "одноразовые", у них нет жизненного цикла.
Суть замыканий в снижении связанности программы путём функционального DI
Это не "суть", это один из вариантов применения. Для DI (dependency inversion) обычно модули все же юзают, а модули можно худо бедно сделать на замыканиях. Но в PHP таким заниматься как-то не очень удобно.
Fesor
15.03.2016 10:43Ну и да, по поводу "честного" fast cgi я чуть ниже уже приводил ссылки на различных подходы для достижения этой цели.
AntonStepanenko
15.03.2016 11:27Господа, ну зачем вы спорите? Те, кто говорят, что настоящий fastcgi для пхп есть и кидают ссылки на гитхаб правы. Просто потому, что PHP — это Turing complete язык и на нём можно написать всё, даже если на гитхабе этого нет. Те, кто говорят, что хотят из коробки быстро бесплатно без регистрации без смс — тоже правы. Потому что они не хотят выбирать из 10 библиотек, думать про каждую из них "а можно ли доверять" и плакать, когда библиотеку перестанут поддерживать.
Другое дело, что в PHP принята stateless модель. В этом и плюс, и минус PHP. Если вы хотите stateful и "настоящий fcgi"™ — может, вам не нужен PHP, а нужен кто-то другой?
И на всякий случай https://habrahabr.ru/company/badoo/blog/276353/ — там есть доклад про написание демонов на PHP и пара ссылок на статьи на эту тему.
NightTiger
11.03.2016 16:51Сделать-то не проблема, смотрите PHPFastCGI, этот товарищ занимается популяризацией этого подхода. Однако, там столько подводных камней с тем, чтобы процесс не умирал, например от "Mysql has gone away", "Remote connection closed" и т.д.
Если интересно играться, то у меня есть реализация сырого FastCGI-протокола для PHP lisachenko/protocol-fcgi, там можно поиграться с подключением Nginx напрямую к PHP, и да, ваш пример прекрасно будет там работать.
tony2001
11.03.2016 16:58+4FastCGI — это протокол. Не совсем понятно причём тут stateful/stateless реализации движка.
Конкретно такого поведения никогда не будет, я уверен.
Как минимум потому, что уже есть методы, которые позволяют добиться такого же результата без переписывания всего с нуля. Просто храните это значение где-то. В той же shared memory, например.

stalkerg
12.03.2016 13:09Советую тогда глянуть другие языки где с этим нету проблем (конечно там будут свои проблемы). PHP7 конечно знатный рывок но в сторону старой ниши. т.е. с PHP7 язык большим конкурентом Python/Ruby/Go/Rust/C++ и т.д. не стал.
ЗЫ statefull модель полезна для WebSockets. В том же Python+Tornado я в одном коде могу писать statefull вебсокет хендлеры и stateless http хендлеры, мне не нужны разные языки/фреймворки для этого. Использовать для хранения информации всякие Redis между состояниями конечно можно, но это медленно и далеко не всегда удобно.
Fesor
14.03.2016 14:29+3не стоит ждать настоящий fast_cgi?
Он как бы был и под php5.3, просто увы пока этот подход не пользуется сильно популярностью. На вскидку вот вам посмотреть да потыкать:
https://github.com/php-pm/php-pm — http сервер на php с управлением процессами-воркерами, совместимый с symfony/http-kernel (может уже и с psr-7). Можно прото невилировать время бутстраппинга приложения и его влияние на время запросов, либо полностью демонизировать приложеньки (но это уже сложно потому как надо учитывать сайд эффекты и чистить контейнер от stateful сервисов после ответа).
https://github.com/PHPFastCGI — немного более стремный но перспективный проект. Именно реализация fastcgi сервера.
https://github.com/amphp/aerys — мой любимчик, реализация http+websocket сервера на php7 и корутинах. Опять же можно завернуть в psr-7 и получить что-то типа php-pm но чуть более современное и удобное. Ну и маленькие проектики в принципе можно только на aerys писать (какие-то микросервисы критичные к нагрузкам, если нет возможности это на ноде делать).


maxru
11.03.2016 16:56-4> PHP7 действительно готов к продакшену
К сожалению, нет :(maxru
11.03.2016 17:13+4Специально для минусующих выкладываю скрин/ На скрине 7.0, но в 7.0.3 также повторяется.
https://habrastorage.org/files/d44/92b/6fd/d4492b6fdd3d4d2cb487283be5ce2029.jpgSannis
11.03.2016 17:18А что об этом пишут на https://bugs.php.net/?
maxru
11.03.2016 17:22Ничего.
Я всё оттрассировал и нашёл строчку в исходниках, где вываливается segfault, но чтобы написать простой пример, демонстрирующий багу, мне нужна ещё неделя, а у меня этого времени нет.
Скажу просто — если вы не занимаетесь обработкой данных / инстанцированием объектов на деструкторах, то бояться нечего
coh
11.03.2016 18:05+14Всегда казалось, инстанцирование объектов в деструкторе дурным тоном. Одно неловкое исключение — fatal, порядок вызова неявный, заголовки отправлены, рабочая дирректория может отличаться… Для чего вам понадобилась сложная логика в деструкторе?

vanxant
11.03.2016 20:14-1Ну не факт, что это вообще баг, а не фича.
Деструктор может быть вызван языком из исключения, поэтому ни в коем случае не должен допускать исключения сам. Иначе на стэке начинается трэш и угар.
В С++ это UAB например.AntonStepanenko
11.03.2016 20:21+14При чём здесь исключения? При чём здесь C++? Ни при каких обстоятельствах ошибка сегментирования в PHP не может являться фичей, как бы там ни было в плюсах.
vanxant
12.03.2016 13:43+1C++ для примера приведён, как опорная реализация всяких языковых фич. Быстрая, но позволяющая отстрелить себе ногу.
Когда ту же фичу реализуют в других языках и хотят реализовать это быстро, разрабы очень часто смотрят "а как оно в плюсах сделано".
При чём здесь исключения: ну, вы не даёте бэктрейс и вообще никаких зацепок, при этом занимаетесь заведомо never-do практиками (инициализация в деструкторе). Поэтому я предположил, что ошибка вызвана исключением в деструкторе, вызванном во время раскрутки стэка во время обработки другого исключения.
То, что оно не должно падать с сегфолтом — согласен. Но если ваш же багливый код будет падать с fatal error, пользователем вашей программы легче не будет.
Короче, я предполагаю, что в вашей программе есть намного более жирный баг, чем тот, который имеется в пхп. И винить во всём только свежую пхп — ну, так себе идея.
tony2001
11.03.2016 17:43+8Скриншот лога не очень помогает. Как минимум, нужен backtrace.
Как его получить — написано тут: https://bugs.php.net/bugs-generating-backtrace.php
Я понимаю, что у вас времени нет, но если просто жаловаться на Хабре, то ничего не изменится.maxru
11.03.2016 17:47+1trace у меня есть, у меня минимального примера нет, я выше об этом писал.
На одну из баг с обратной совместимостью мне ответили, что это фича и исправлять это они не будут. В документации по миграции это тоже не упомянуто.
В общем, лично я принял решение ждать 7.2-7.3tony2001
11.03.2016 17:58+2Есть backtrace — делайте баг-репорт, только предварительно поищите репорт с таким же трэйсом, чтоб не плодить дубли.
Ждать или делать — ваш выбор.maxru
11.03.2016 19:05-7А тут дело скорее не в конкретном баге, а в том, что он не первый и нет никакой уверенности, что не последний
AntonStepanenko
11.03.2016 19:16+19Почитайте чейнджлог пятой версии http://php.net/ChangeLog-5.php. Релиз состоялся 13 июля 2004 года, а в версиях от 3 марта 2016 года до сих пор фиксят баги. Я вам гарантирую, обнаруженный вами баг — не последний. Подождите хотя бы PHP 28.0, а лучше 29.0.

ibKpoxa
11.03.2016 21:49-3Кто-то больше выиграет от экономии ресурсов, кто-то больше проиграет при появлении бага, пользователи php бывают разные. Вероятность появления бага в продукте, только недавно вышедшем на рынок гораздо больше, чем в продукте, которые работает уже несколько лет, но вероятность ниже не значит, что она равно нулю.
AntonStepanenko
11.03.2016 22:06Баги есть всегда. У любых пользователей php. В пятой версии, в седьмой.
Что касается утверждения "Вероятность появления бага в продукте, только недавно вышедшем на рынок гораздо больше, чем в продукте, которые работает уже несколько лет" — оно неверно, начать получать ответ на вопрос "почему" можно с чтения https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D0%BD%D1%81%D0%B8%D0%B2%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%BE%D1%82%D0%BA%D0%B0%D0%B7%D0%BE%D0%B2.ibKpoxa
11.03.2016 22:49+2Удивительно, как можно применять правила для механизмов, т.е. продверженных в первую очередь износу, с ПО, не подверженному износу? У вас так хорошо получается гуглить, думаю что у вас не составит труда опровергнуть свои слова, у меня получилось найти аналогичные графики для ПО за минуту поиска. Они имеют другую форму.
AntonStepanenko
11.03.2016 23:16Это очень интересно. Не могли бы вы показать эти графики? А если в составе какой-то статьи, где эти графики объясняются — так вообще прекрасно. Мне вот удалось быстро найти http://www.1manteam.com/index.php/2011/01/facebooks-developer-love-initiative-3-months-later/ — что больше похоже на выводы обычной теории надёжности, чем на ваши утверждения.
ПО подвержено износу, только в качестве износа выступает усложнение и изменения этого ПО с течением времени. Кроме того, количество ошибок определяется не только износом, иначе бы в нулевой момент времени оно было бы нулём.AntonStepanenko
11.03.2016 23:28А вы были правы. Действительно, довольно быстро гуглится — картинки по запросу "software failure rate".
И насчёт применимости правил — вас не смущает, что люди, которые вас окружают, голосуют на выборах в соответствии с распределением Гаусса, а на мобильные телефоны звонят потоком Пуассона?
maxru
14.03.2016 11:50Ну вот и сравните кол-во багов а-ля segfault в php 5 до версии 5.3 и после.
AntonStepanenko
14.03.2016 12:07Сравнил:
? ~ wget -qO — http://php.net/ChangeLog-5.php | grep -iEc 'segfault|segmentation fault'
476
? ~ wget -qO — http://php.net/ChangeLog-5.php | grep -in 'version 5.3.0'
10084:Version 5.3.0
? ~ wget -qO — http://php.net/ChangeLog-5.php | head -n 10084 | grep -icE 'segfault|segmentation fault'
288
Правда, сравнение такое некорректно, потому что есть несколько веток развития пятой версии — 5.6 и 5.5, складывать количество сегфолтов неправильно. Кроме того, сегфолты часто происходят в расширениях, и тут надо смотреть в каких именно и насколько они часто используются.
Вы бы лучше сами привели статистику, которую посчитали. И выводы, которые сделали.ibKpoxa
14.03.2016 12:44Кстати, даже чисто визуально по http://php.net/ChangeLog-5.php видно, что число исправляемых ошибок в 5.6 намного выше, чем в 5.5, а уж 5.4 там встречается еще реже.
AntonStepanenko
14.03.2016 13:16+1Ага. 5.4 просто больше не поддерживают, вышел последний 5.4.45 и всё. По вашей логике надо четвёртую версию использовать, там последний раз ошибки исправляли в 2008 году.
ibKpoxa
14.03.2016 13:48-2Почему вы ограничиваете моё логику своими домыслами? Безусловно лучше иметь поддерживаемую версию.
Моя логика была проста — есть задачи, где цена ошибки очень высока, в таких задача, и только в таких, выгоднее использовать поддерживаемую версию где меньше шансов на ошибку, чем поддерживаемую версию с высокими шансами на ошибку, потому что цена ошибки, повторюсь, очень высока. Да, можно добавить сарказма в ответ и попыток подловить на чем-то, но смысл? Думаю, что вы меня поняли.

tsafin
11.03.2016 17:07А объясните мне, пожалуйста, такой простой вопрос — почему при большом количестве проектов JIT для PHP с больших компаниях ни один из них не продвигали upstream?
И почему вы сами не сделали его, раз у вас такая большая ферма серверов и большая зависимость?tony2001
11.03.2016 17:56+2Во-первых, очевидно, что никому это не надо настолько сильно, чтоб взяться за разработку.
Во-вторых, почему вы решили, что это какая-то серебряная пуля?
В Zend заимплементили JIT, поэкспериментировали и убрали пока в сторону:
http://marc.info/?l=php-internals&m=142503908926686
TL;DR: первое выполнение скрипта — вплоть до нескольких минут, второе — выигрыша особого не даёт.tsafin
12.03.2016 21:38Правильно ли я понял, что в итоге заброшенный JIT в Zend был сделан на LLVM? (Который не очень хорошо оптимизирован для JIT сценария и добавляет большой overhead...)
fisher
11.03.2016 19:39+1Потому что "сделать для себя" и "продвинуть в апстрим" — примерно равные по ресурсоёмкости задачи. Грубо, если один год девелопили, другой год будете двигать в апстрим. Мы это на своей шкуре несколько раз почувствовали и для не таких больших проектов. А почему не сделали сами — мы всё-таки слишком маленькие, чтобы такими задачами системно заниматься.
tsafin
12.03.2016 21:30+2Понятно, что первый пуш в апстрим идет долго первый раз (в зависимости от сообщества и его лидера, конечно, в linux-kernel это будет совсем больно, в llvm — одно удовольствие). Но никому и не обещали что это будет легко. Но это только первый раз, со временем, с ростом репутации push в upstream может стать довольно быстрым мероприятием.
Дело тут в политическом решении Если вы строите свой бизнес на наборе open-source продуктов, если вы инвестировали свою экспертизу и сильно развили эти продукты в нужном вам направлении, то вашей платой и благодарностью сообществу и авторам этих продуктов будет время потраченное на проталкивание этих наработок обратно в upstream.
Вне зависимости от того большая вы контора или маленькая, проталкивание своих наработок обратно в продукт, запуск тестовых ботов на своих железках, написание тестов, и любая другая релевантная активность, измеряемая в человеко- и машино-часах — это возврат долга за использование изначально бесплатного продукта.
Хотя, конечно, вам самим решать.vintage
12.03.2016 21:40+1К сожалению многие не разделяют этого мнения и воспринимают свои патчи в оупенсорс как конкурентное преимущество и соответственно не просто не проталкивают в апстрим, но даже и не открывают изменения.
fisher
14.03.2016 11:24Дело не в политическом решении, я повторяю, это исключительно проблема структурная: Фейсбуку проще на всех покласть и сделать своими силами под себя. Ну и у нас никогда не было своего JIT, а это очень ресурсоёмкий проект — так что почему мы не сделали JIT — ну потому что очевидно это очень непростая задача, это человеко-годы, это может позволить себе компания размером в тысячу человек и больше. Насчёт платы и благодарности: ну мы-то отдаём до чёрта всего, см. http://github.com/badoo. Но open source проекты неэффективны c точки зрения бизнеса. Если Вы вдруг не знаете, мы пушили в апстрим php-fpm, это был просто сторонний патч когда-то, Андрея Нигматулина, нашего программиста. Мы запилили проект по исправлению косяка со вложенными локами в MySQL, его года три назад делал лид Тарантула Костя Осипов, так на исправление ушла пара недель, а на проталкиваение в апстрим ораклу, перконе и марии — несколько лет. Так что мы готовы тратить время, не вопрос, но мы не готовы убиваться, потому что мы — маленькие.

Scat
11.03.2016 17:49+1Спасибо за статью, как раз сейчас тоже переходим на PHP7. Хотел бы уточнить каким профайлером и дебаггером пользуетесь? XDebug? Спасибо

Davert
11.03.2016 18:11Сарой Гоулман (англ. Sara Golemon), которая сейчас работает в Facebook, в том числе и над HHVM
уже нет https://twitter.com/SaraMG/status/702264356348624896
А вцелом повторюсь то, что написал в твиттере. Выложить на гитхаб — это одно, а сделать проект доступным сообществу — совершенно другое. Понятно, что скорее всего какие-то фишки из Go AOP вам не подошли, но вместо того чтобы делать ещё +1 решение для софт мокинга (AspectMock, Kahlan) можно было бы реально поделиться своими наработками, улучшить, и сделать более-менее универсальным существующий опенсорс движок. SoftMocks выглядит заманчиво, но будет ли кто-то им будет пользоваться за пределами Badoo...
Davert
11.03.2016 18:12+2О, и ещё вопросик: рассматривали ли вы Zephir в качестве инструмента для написания расширений?
youROCK
11.03.2016 20:58Рассматривали, пока что не используем.

alekciy
14.03.2016 10:38Руки не дошли? Вылезли ли какие-то проблемы? Текущий контекст (в виде наработанного кода) мешает? Другое?
Sannis
14.03.2016 10:59У нас не так часто появляется необходимость в новых расширениях. Навскидку за последний год это был только tarantool 1.6, нецелесообразно было писать его на Зефире с нуля.
youROCK
14.03.2016 11:12Я бы сказал, что больше всего "пугает" сырость и туманность перспектив. Не забывайте, что Badoo — это уже проект с 10-летней историей, и мы должны быть уверены, что те инструменты, которые мы используем, не будут заброшены авторами в обозримом будущем. Или же нам нужно будет у себя развить экспертизу по тому, как работает зефир и научиться самому его поддерживать и разрабатывать. Пока что оно не стоит того.

sloven
11.03.2016 19:26+1Пытаемся перейти на php7 но libxl + php_excel стабильно падают в core dump (пересобраны, ессно). Починить не можем. Плачем.
tony2001
11.03.2016 19:32+1Reproduce case внятный есть? Если есть — пришли мне, плз.
sloven
11.03.2016 19:36первая сложность в том, что код надо брать вот с этого pull request, так как master не собирается вообще
https://github.com/iliaal/php_excel/pull/114 и я не уверен насколько это правильно.
вторая сложность в том, что простые примеры работают на ура, а на реальных данных/запросах — падают 100%. постараюсь за выходные написать минимальный Reproduce case и отписаться.
sloven
11.03.2016 19:58+1Тестирование показало что все просто до не могу ))) Оно падет на проверке лицензии.
Если убрать ключ — в trial mode все ок.
А с реальным ключем падает вот так еще на создании обьекта:
<?php
$licenseName = 'Oleksandr Voytsekhovskyy';
$licenseKey = 'linux-somekey';
$a = new ExcelBook($licenseName, $licenseKey, true);
реальный ключ готов выслать в приват
sloven
11.03.2016 21:46+2еще 2 часа тестирования показали что если сделать так
[excel]
excel.license_name="Oleksandr Voytsekhovskyy"
excel.license_key="linux-somekey"
excel.skip_empty=1
new ExcelBook(null, null, true);
то все работаетtony2001
14.03.2016 13:32Как минимум в одном месте в патче не до конца исправлены типы, вот фикс:
https://gist.github.com/391f7728dddeecc8cc34
А вообще, это всё дебаг по телефону. Мне надо видеть, иметь возможность запустить это всё.
Ну, и совсем неясно почему это всё обсуждается в этом топике =)

SergeAx
11.03.2016 19:31+3А почему у вас php-fpm на tcp, а не на сокетах? Неужели очереди в сокеты длиннее 0xFFFF бывают?
AntonStepanenko
11.03.2016 20:05А расскажите, почему unix-сокет будет лучше?
SergeAx
11.03.2016 20:08Скрижали гласят, что сокеты быстрее. Но я, если честно, давно не измерял, и вот fisher пишет, что скрижали слегка устареть могли.
AntonStepanenko
11.03.2016 21:13+1И да, и нет. На самом деле, в разных кластерах разные схемы балансировки нагрузки, и в одной из схем есть небольшое количество nginx на одних машинах, и большое количетво php-fpm на других. Собственно, это ответ на вопрос, почему AF_INET.
ibKpoxa
12.03.2016 14:37+1unix-сокет не требует для работы стэка ip протокола, который в данном случае и есть оверхед.
AntonStepanenko
12.03.2016 18:34Спасибо, тут уже выяснили, что разница есть, хотя и небольшая, заметная только под очень большой нагрузкой.
Покажите лучше графики количества багов в ПО в зависимости от времени, которые, как вы упоминали выше в комментариях, вам удалось найти за минуту. Мне очень интересна эта тема.ibKpoxa
12.03.2016 23:34Например в на этих слайдах есть пример графики для софта и для железа.
AntonStepanenko
12.03.2016 23:45Вы же читали все слайды, правда? График для софта справедлив при условии, что в софт не вносится никаких изменений, кроме исправлений ошибок. Мы изначально говорили про эволюцию PHP, в который изменения вносятся постоянно. Запрос, по которому надо гуглить, я уже писал выше.
ibKpoxa
13.03.2016 13:29Читал, разумеется, как раз описанная мною ситуация, что кому-то важнее иметь меньше шансов возникновения ошибок/фаталок, и в этом случае берется версия софта, в которой нет нововведений, есть только исправление ошибок, и для такого софта как раз такой график, а не пила, как для более новых версий, и разумеется график для железа не подходит для софта, так ведь?
fisher
11.03.2016 20:06-4когда-то на старых ядрах это типа может и отличалась но щас вроде разницы никакой
youROCK
11.03.2016 20:45+4Фиш, не хочу тебя разочаровывать, но это не совсем так. В целом, нет причин, по которым TCP мог бы вообще когда-нибудь работать быстрее, чем unix socket. В качестве примера можно привести бенчмарк редиса: http://redis.io/topics/benchmarks
$ numactl -C 6 ./redis-benchmark -q -n 100000 -s /tmp/redis.sock -d 256 PING (inline): 200803.22 requests per second PING: 200803.22 requests per second MSET (10 keys): 78064.01 requests per second
vs.
$ numactl -C 6 ./redis-benchmark -q -n 100000 -d 256 PING (inline): 145137.88 requests per second PING: 144717.80 requests per second MSET (10 keys): 65487.89 requests per secondfisher
11.03.2016 21:24-2а я не говорил, что "TCP мог бы вообще когда-нибудь работать быстрее, чем unix socket". я говорил, что теоретически могло быть наоборот на старых ядрах, unix сокеты могли быть быстрее tcp, ну и я тоже что-то когда-то слышал про скрижали, которые это говорили, но вроде давно уже без разницы. твой эксперимент это лишь подтверждает. выпей порто :)
youROCK
11.03.2016 21:18+2Если перефразировать AntonStepanenko, то TCP используется потому, что он гибче — мы в некоторых случаях мы ходим напрямую на FPM
tgz
11.03.2016 20:10-4Сколько RPS оно выдает с одного ядра? На каком-нибудь Go этот показатель примерно 10k. Может можно еще 300 серверов освободить? :)
fear86
11.03.2016 20:43+2Вот только цена разработки (портирования) будет выше и вряд ли окупится когда либо )
youROCK
11.03.2016 20:49+5Все-таки, справедливости ради, хотел бы сказать, что 10k rps на одно ядро на golang получить можно только в том случае, когда логика обработчика очень простая и не делает сотен запросов в другие сервисы по сложным условиям. В большинстве случаев на PHP пишут в том числе из-за сложности бизнес-логики, и на golang это все переводить будет нецелесообразно. Тем не менее, какие-то самые нагруженные части наверняка можно перевести на golang хотя бы из соображений низкого latency.
SergeAx
11.03.2016 20:12О своём опыте: перевёл пару проектов на WordPress, довольно плотно обвешанных плагинами и темами, под PHP7, разница в производительности впечатляет. 10-долларовый дроплет DigitalOcean отдаёт страницы за ~500ms (при правильной сборке и настройке nginx). Правда приходится регулярно ловить incompatibility issues в чужом коде. Особенно люто валятся всякие indirect references на функции или методы классов.
PaulBardack
11.03.2016 22:39+1500ms??? У нас на 5-долларовой ноде DO простой сервис на php5.6 c Lumen отдает по 50-70мс

dr1v3
12.03.2016 02:32+1Сравнивать Wordpress и Lumen это как сравнивать тёплое с мягким.
PaulBardack
12.03.2016 12:24+3Я не то что сравнивал, скорее констатирую и удивляюсь разнице.
Я с wordpress плотно не работал, но все же кажется, что 500ms на 7 это слишком много. Что-то с wordpress не тоalekciy
14.03.2016 10:47+1Для популярных CMS, да еще и "плотно обвешанных плагинами" это в принципе нормальный показатель. Не говоря уже о том, что сравнивать старую коробку и "простой сервис" совсем не корректно.
SergeAx
14.03.2016 12:17+1Вы большие молодцы, поздравляю вас. Но с развесистыми проектами на WP вы, вероятно, дела не имели.
SergeAx
11.03.2016 20:18Самое же прекрасное, что вы почему-то не упомянули, что в PHP7 нельзя использовать в качестве имени класса Error. А именно так назвать класс, унаследованный от Exception в PHP5, считает своим долгом в среднем каждый пятый разраб.
AntonStepanenko
11.03.2016 20:23+3использование зарезервированных имен классов
Вам не понравилось, что там не указано Error? На мой взгляд нет смысла заниматься копированием документации и migration guide, статья немного о другом.SergeAx
14.03.2016 12:15Мне статья вообще очень понравилась, не хотелось бы, чтобы у вас сложилось обратное мнение. Так что просто просто поделился опытом. Хотя вот у коллег ниже статистика другая.
bolk
11.03.2016 20:33+1Я сейчас, для интереса, посмотрел кол-во коммитеров в проект, которым я руковожу (полмиллиона строк кода). 32 человека. Ни один не назвал класс ошибок «Error». Я сломал вашу статистику! :)

varanio
11.03.2016 22:35Модификатор 'e' в регулярках, а также конструктор в виде названия класса уже давно deprecated. Или вы раньше просто подавляли такие ошибки?
AntonStepanenko
11.03.2016 23:06+1Модификатор e приводит к ошибке уровня E_DEPRECATED начиная с PHP 5.5.0. Во-первых, не сказать, что это очень давно. Во-вторых, по-умолчанию E_DEPRECATED отключены, так что я бы не сказал, что прям подавляли, но да, какое-то время просто не уделяли этому внимания.
Что касается конструкторов — вы ничего не путаете? Они не приводят к ошибкам. Единственная особенность — начиная с 5.3.3 у классов внутри неймспейса конструктор должен называться __construct, иначе он просто не будет вызван при создании объекта.varanio
11.03.2016 23:17Да, про конструктор ошибся. Просто так давно не встречал старых конструкторов, что был уверен, что deprecated

LastDragon
12.03.2016 09:22На самом деле конструкторы совпадающие с названием класса не рекомендуется использовать еще со времен выхода PHP 5.0 :) (да и неудобны они в живых проектах из-за
parent::).
For backwards compatibility with PHP 3 and 4, if PHP cannot find a __construct() function for a given class, and the class did not inherit one from a parent class, it will search for the old-style constructor function, by the name of the class.

dezconnect
12.03.2016 09:26+2Мнение о том, что узким местом в веб-проектах является база данных — одно из самых распространенных заблуждений. Хорошо спроектированная система сбалансирована — при увеличении входной нагрузки удар держат все части системы, а при превышении пороговых значений тормозить начинает все: и процессор, и сетевая часть, а не только диски на базах.
Таким образом, процессорное время сократилось в 2 раза, что улучшило общее время ответа примерно на 40%, так как некоторая часть времени при обработке запроса тратится на общение с базами и демонами, и с переходом на PHP7 эта часть никак не ускоряется, что ожидаемо.
Это прекрасно.vintage
12.03.2016 09:45-5Да, и база — узкое место, потому как stateless инстансы приложений легко масштабируются увеличением их числа. А вот для базы важна консистентность, её так просто не отмасштабируешь.
AntonStepanenko
12.03.2016 17:45Простите, а в чём вы видите несоответствие? Процессорное время сократилось в 2 раза, то есть на 50%. Если бы общения с базой не было — то и время ответа сократилось бы на 50%. Но общение с базой, очевидно есть, и оно не является узким местом, то есть занимает не так много времени — поэтому общее время ответа сократилось на 40%.
vintage
12.03.2016 18:06-8Видимо в том, что 80% времени тратилось на работу PHP, а на ожидание СУБД — жалкие 20%, что не очень похоже на сбалансированность. Скорее на существенный перекос в сторону PHP.
AntonStepanenko
12.03.2016 18:11+3Вы, к сожалению, путаете сбалансированность и равномерность распределения нагрузки. Сбалансированность не означает, что каждый компонент системы занимает одинаковое время. Сбалансированность означает то, что написано в статье: "при увеличении входной нагрузки удар держат все части системы" и далее по тексту.
vintage
12.03.2016 18:36-7Не путаю. В данном случае эти два понятия эквивалентны, ибо узкое место — это то, оптимизация чего даёт наибольший эффект. Двукратная оптимизация PHP дала 40% прироста общей производительности. Аналогичная двукратная оптимизация работы СУБД дала бы не более 10%.
AntonStepanenko
12.03.2016 18:43+3Вы, видимо, слабо представляете себе классические подходы к проектированию подобных систем. Двухкратная оптимизация PHP даёт 40% прирост производительности в кластере бекенда мобильных приложений потому, что наиболее тяжеловесные операции, нагружающие базу и демоны, вынесены в асинхронный процессинг, которым занимается упомянутое в статье облако. По этой же причине база занимает небольшой процент времени. И это очень хорошо. Потому что это упрощает масштабируемость кластера. Как вы сами заметили, базу масштабировать сложнее. Поэтому выгодно иметь такую архитектуру, где с увеличением трафика нужно в первую очередь просто нарастить мощности cpu, а не базы. Важно ответить пользователю быстро — именно поэтому при синхронном ответе всегда стремятся снизить количество взаимодействий со внешними по отношению к PHP сервисами — а асинхронно уже можно потратить 80% времени на работу с базой.
vintage
12.03.2016 18:57-5Если учесть, что большинство запросов в подобных сервисах являются чтениями, то не понятно, что вы там такое запускаете асинхронное на каждый запрос :-) Но даже если предположить, что каждый лайк запускал в СУБД пересчёт числа пи до последнего знака, что создавало существенную задержку ответа, поэтому было решено давать ответ пользователю не дожидаясь завершения операции, то да, было узкое место в расчёте числа пи, стало узкое место в интерполяции шаблонов в PHP, а нагрузка на сервера не поменялась.
vintage
12.03.2016 19:07-6Да, и асинхронные ответы — это не оптимизация, а фикция :-)
AntonStepanenko
12.03.2016 19:18Я ничего не говорил про асинхронные ответы. Ответ пользователю синхронный. Только часть операций выполняется уже после того, как пользователь получил ответ.
vintage
12.03.2016 19:39Это и называется асинхронный ответ, то есть не синхронизированный с вызванной запросом операцией :-) Но это мы ушли в терминологический спор. Как этот приём ни называй, а оптимизацией он не является.
AntonStepanenko
12.03.2016 19:47+3Теперь становится понятнее. Вы считаете, что оптимизация — это исключительно ускорение работы системы. На самом деле оптимизация — это улучшение эффективности системы, совершенно необязательно являющееся сокращением времени работы. Иными словами — сделать лучше можно не только заставив код работать быстрее. Вам, как архитектору, это должно быть известно.
vintage
12.03.2016 20:06-4Разумеется, лучшая оптимизация — не делать то, что можно не делать :-)
AntonStepanenko
12.03.2016 21:16Вы судите об оптимизации по тому, в чём она заключалась. А лучше судить по тому, что она дала.
vintage
12.03.2016 21:43-5А что она дала? Видимость скорости? Если клиенту не интересно завершилась ли операция, то он может и не дожидаться ответа, а сразу дропнуть соединение после отправки данных. :-)
AntonStepanenko
12.03.2016 23:46Что она дала — указано в заголовке статьи и в её завершающей части. Вы ведь читали статью?
AntonStepanenko
12.03.2016 19:15+2У вас неверное представление о том, что такое узкое место. Вы почему-то считаете, что компонент, занимающий по времени больше остальных, это и есть узкое место, которое следует оптимизировать. Именно так появляются так называемые premature optimization mistakes. Вы отталкиваетесь от того, что можно оптимизировать. Следует отталкиваться от того, что нужно оптимизировать. Что сделает приложение быстрее для пользователя. Не "теперь вместо 10 микросекунд мы рендерим щаблон за 2, 5x ускорение!", а быстрее для пользователя. Что сэкономит деньги. Не "мы заплатили разработчикам 20 миллионов зарплаты за год, чтобы они на 10% ускорили код, который работает на 10 серверах", а экономически выгодные решения.
Действительно, разделив обработку запроса на синхронную и асинхронную часть, не получится выиграть в суммарной нагрузке. Более того, поступив так, вы проиграете в нагрузке, потому что появятся накладные расходы на эту самую асинхронность. Но вы выиграете в гибкости, в масштабировании, в надёжности и во времени ответа.
И было бы очень интересно узнать, что такое интерполяция шаблонов? Это по имеющимся шаблону главной и шаблону профиля вычислить шаблон страницы поиска?vintage
12.03.2016 20:00-4Вы почему-то считаете, что компонент, занимающий по времени больше остальных, это и есть узкое место, которое следует оптимизировать. Именно так появляются так называемые premature optimization mistakes. Вы отталкиваетесь от того, что можно оптимизировать. Следует отталкиваться от того, что нужно оптимизировать. Что сделает приложение быстрее для пользователя.
Так оптимизация того, что занимает больше всего времени и сделает приложение быстрее для пользователя. И далее по тексту вы подтверждаете мои слова. :-D
Сказать, что покрасил забор, хотя сам за этот забор ещё не брался — это не оптимизация скорости покраски забора. Это ложь ради показателей. Иногда она необходима. Например, чтобы соединение не таймаутилось или чтобы не исчерпать ограничение на число одновременных соединений… Но в этом случае следует понимать, что время ответа перестаёт показывать что-либо осмысленное. Оно даже может равняться нулю. Поэтому замерять нужно уже не время ответа, а время завершения вызванных запросом операций. В случае синхронного ответа эти два показателя эквивалентны. В случае асинхронного — нет.
en.wikipedia.org/wiki/String_interpolationVolCh
16.03.2016 12:49+4Замерять нужно то, что важно для пользователя. Очень много сценариев, где гораздо важнее отправить команду на выполнение вычислительно тяжелой или физически долгой задачи и дать пользователю возможность продолжить работу, не дожидаясь окончания задачи. Да, общее время будет дольше. Да, могут потребоваться дополнительные механизмы отслеживания статуса задач и/или уведомления об их изменении, а то и механизмы управления задачами типа очереди, отмены, приостановки и возобновления. Но пользователь будет счастлив, что ему не нужно ждать завершения выполнения одной задачи, чтобы начать другую или просто выключить комп.
vintage
16.03.2016 15:10-3Он и так может не ждать, если ему не интересен результат ;-)
VolCh
18.03.2016 15:05+1Представьте себе, полно кейсов, где пользователю не важно даже получился результат или задача свалилась с ошибкой. Банальное техническое логирование — зачем пользователю ждать окончания записи в логи? А если не получилось записать, ему 500 выдавать? Или ресайзинг изображений при загрузке для оптимизации трафика сервера. Пользователю оно надо ждать окончания ресайзинга? Если что-то пошло не так при ресайзинге, ему надо повторно загружать оригинал?
vintage
18.03.2016 16:12-5О том и речь, что если пользователю не интересно, он всегда может дропнуть соединение после отправки данных. Это именно пользователю решать хочет он дождаться конца или нет. А вот если пользователь хочет дождаться конца, а сервер его обманул и ответил не дожидаясь, то какой прок от такой метрики? Что она показывает? Время создания асинхронной задачи?

baltazorbest
18.03.2016 17:18Как писали выше пользователю точно не нужно ждать пока ошибка запишется в лог файл.
Fesor
18.03.2016 18:53А вот если пользователь хочет дождаться конца, а сервер его обманул и ответил не дожидаясь, то какой прок от такой метрики?
Вы о каких-то сферических в вакууме пользователях рассуждаете, для которых имеет ценность сидеть и ждать чего-то.
Пример с видео на ютубе более показательный. Залилось, могли быть ошибки, все хранится в очереди, когда закончится — не известно. Пользователю надо только файл залить, а когда там его full hd запроцессится ему особо не интересно.vintage
18.03.2016 19:21-3Вообще-то очень даже интересно. Он же его не просто так заливает. И очень бесит, когда видео вроде как залилось, а посмотреть его нельзя или можно, но лишь в убогом качестве. Пользователя интересует не когда видео будет залито на сервер, а когда его можно будет нормально смотреть с сервера.
VolCh
18.03.2016 21:00Разница синхронной загрузки с асинхронной при больших объёмах данных на грани погрешности, но при синхронной пользователь будет вынужден ждать ещё и окончания обработки, которая может и фэйлом завершиться. А ему самому обработка особо и не нужна — у него оригинал есть. В редких случаях ему самому нужна обработка, чаще кто-то другой ждёт, если вообще ждёт.
vintage
18.03.2016 22:00Видео на ютуб закачивают не для того, чтобы посмотреть, а для того, чтобы поделиться.
Fesor
18.03.2016 23:07Ну так делитесь, от того ценность асинхронной загрузки для пользователя выше. Он может быстро залить видос, скинуть ссылку, а лицезреть видяшки в паршивом качестве будут уже те, с кем поделились. А через пол часика уже и нормальное качество подтянется.
vintage
19.03.2016 01:53-2Получить ссылку можно и ещё до закачки файла, но зачем? Чтобы отвечать на тысячу вопросов "почему у меня не играет?" да "чего качество такое лажовое?"?
vintage
12.03.2016 09:42-5У вас же обычный дэйтинг-вымогатель. Чем таким важным занимаются эти 3 миллиона строк кода? Ну и не понятно стремление держаться за PHP, который требует ферму из 600 серверов и ораву кодеров. Давно бы уже распилили на микросервисы, да начали переводить их на что-то компилируемое.
dbelka
12.03.2016 10:15+3Правильно ли я вас понял? Сначала вы называете узким местом базу, а потом предлагаете избавиться от оравы кодеров и переписать 3 млн. рабочего, отлаженного и оптимизированного кода с PHP на мифический компилируемый, который-то и решит все проблемы? Я просто уточнить...
vintage
12.03.2016 10:45-13То, что узким местом является база, не означает, что куча денег не вылетает в трубу из-за использования php ;-)
Касательно "рабочего, отлаженного и оптимизированного кода" не буду повторяться:
Чем больше кода, тем больше в нём ошибок. Более того, чем больше кода, тем больше процент этих ошибок. Так что если вы видите огромный зрелый фреймворк, то можете быть уверенными, что на отладку таких объёмов кода была потрачена уйма человекочасов. И ещё уйму предстоит потратить, как на существующие ещё не замеченные баги, так и на баги, привносимые новыми фичами и рефакторингами. И пусть вас не вводит в заблуждение «100% покрытия тестами» или «команда высококлассных специалистов с десятилетним опытом» — багов точно нет лишь в пустом файле. Сложность поддержки кода растёт нелинейно по мере его разрастания. Развитие фреймворка/библиотеки/приложения замедляется, пока совсем не вырождается в бесконечное латание дыр, без существенных улучшений, но требующее постоянное увеличение штата.
Кроме как копипастой и костылями я не знаю чем можно забить 3 миллиона строк для этого не хитрого сервиса.
Конкретно, я бы предложил язык D, в котором и метапрограммирование есть из коробки, а не в виде отваливающегося расширения, и статическая типизация с автоматическим выведением типов, и динамические типы, и многопоточность, и сборщик мусора, и перегрузка операторов, и удобная стандартная библиотека и ещё много всего, чего либо нет в PHP (например, ленивых параметров), либо только-только созрели ввести (например, строки, хранящие свою длину).
AlexSane
12.03.2016 16:04+7Перейти на D, который знают 1.5 человека? Нехитрый сервис? Серьезно?
vintage
12.03.2016 16:54-12Эти полтора человека стоят 15 пхпыхеров, которые без устали строчат шаблонный код. Есть у меня смутное подозрение, что пресловутые 2 релиза в день — это хотфиксы на хотфиксы.
Ну а что там хитрого? Я весь во внимании.malaf
13.03.2016 00:17+5Простите, но вы очень примитивно рассуждаете.
Эти полтора человека стоят 15 пхпыхеров, которые без устали строчат шаблонный код. Есть у меня смутное подозрение, что пресловутые 2 релиза в день — это хотфиксы на хотфиксы.
Оценивать качество и возможности разработки продукта разработчиком по тому на каком языке он пишет — совершенно неправильно, это оценивается его знаниями, опытом, а язык программирования выступает исключительно инструментом, да, язык может обладать своими недостатками, но как раз хороший разработчик часто может нивелировать это. Знания языка D ещё не делает разработчика сильным, он также может написать плохой код, которым потом будет тяжело поддерживать.
Ну а что там хитрого? Я весь во внимании.
Я уверен там очень много различной бизнес логики. Начиная от формирования контента для web/mobile версий со всей своей логикой, до поиска, рекомендаций, email-маркетинга, процессинга, сбора и обработки аналитики и много другого.
Если так рассуждать, то и facebook простой, страничка профиля и связи с другими, вот и всё…
В тему про размер кодовых баз, есть интересная статистика — http://www.informationisbeautiful.net/visualizations/million-lines-of-code/vintage
13.03.2016 10:04-9Я утрирую.
А вы говорите очевидные вещи. Но не обращаете внимание на то, что человек, который интересуется повышением своей эффективности, не сидит в пузыре одного единственного языка, слепленного из палок и изоленты, Тут дело не в том, знает ли программист язык D, а в том, знает ли он что-либо, кроме PHP. И если знает, то понимает насколько PHP ущербен, ведь единственное преимущество PHP перед другими языками — наличие большого пласта дешёвой рабочей силы, генерирующей типовой код методом генномодифицированной копипасты.
Конечно там много бизнес логики. Целых 3 миллиона строк. Вопрос лишь в том, как эти строки написаны. Если не поддаваться копипасте, а хотябы минимально обобщать решения, то всё, что вы перечислили очень сложно растянуть на 3 миллиона. А фейсбук функционально и правда не ахти какой сложности проект. Подобную соцсеть пара толковых программиста с толковыми инструментами могут сваять за пол года.AlexSane
13.03.2016 13:51+13Золотой фонд цитат хабра:
А фейсбук функционально и правда не ахти какой сложности проект. Подобную соцсеть пара толковых программиста с толковыми инструментами могут сваять за пол года.
malaf
13.03.2016 17:11+1Про "пузырь" и php, как инструмента на все случаи жизни речи не было, посмотрите на список репозиториев badoo — https://github.com/badoo, там обилие разных языков программирования: PHP, С, Ruby, Python, Go, Lua, Java и другие, никто не ограничен, для разных задач используются более подходящие из ходя из множества требований и условий.
vintage
13.03.2016 18:55-4Ох уж эта наивная вера в программистов, не подверженных когнитивным искажениям :-)
https://github.com/yandex — ни одного проекта на PHP. Более того, PHP-шный кинопоиск яндексоиды зачем-то решили переписать на Java. Наверно, ребята не знают, что для веб-сайтов, исходя из множества требований и условий, лучше подходит PHP. :-)
PS. И, если не понятно, то суть даже не в том, что Java лучше PHP, а в том, что у каждого свой пузырь. И в конечном счёте язык выбирают не самый эффективный, а тот который лучше знают.
PPS. Но объективно, старые огромные PHP-проекты поддерживать очень тяжко. Чувствуешь себя археологом.AntonStepanenko
13.03.2016 19:08+2Я думаю, многие хаброюзеры с удовольствием почитают статью о вашем опыте поддержки старых огромных PHP-проектов (да и вообще любых проектов), где вы расскажете о проблемах, с которыми приходится сталкиваться, и методиках их решения.
vintage
13.03.2016 19:31-2Нечто такое я как раз недавно писал про JS проекты.
AntonStepanenko
13.03.2016 19:43+3Очень жаль, что там нет ни слова ни про один старый большой проект и ваш опыт его поддержки. Но фотография сухогрузов красивая.
symbix
12.03.2016 17:24+2«Кроме как копипастой и костылями я не знаю чем можно забить 3 миллиона строк для этого не хитрого сервиса»
Предлагаю остановиться на том, что вы чего-то не знаете.vintage
12.03.2016 17:43-7Я много чего не знаю, поэтому и попросил рассказать что делают эти 3 миллиона строк. А останавливаться на незнании — удел тех, кто сейчас рьяно сливает мне карму. :`-D

Snick
12.03.2016 10:48+1А сколько $$ вы потратили на все работы по переходу на PHP7?
youROCK
12.03.2016 19:46+2Я думаю, не сильно ошибусь, если скажу, что примерно на порядок меньше

Aingis
13.03.2016 15:41-2Хм, 100k$ — это, грубо, пара человеколет. Судя по статье, есть подозрение, что затрат было больше.
youROCK
13.03.2016 15:43+2Совершенно точно мы потратили меньше, чем пару человеколет рабочего времени на то, чтобы перейти на PHP7. Даже разработка и внедрение Soft Mocks (самая тяжелая часть, по сути) заняли в сумме не больше пары месяцев рабочего времени.
sloven
18.03.2016 08:57+1У нас проект немного меньше, но все равно 200 000 строк кода
вылезло только
$this->$moduleVoc[$key]($callParams)
в одном месте, все остальное взлетело на ура сразу

UUSER
12.03.2016 19:55-4во всем коде пути к CLI-интерпретатору были заменены на /local/php, который, в свою очередь, являлся симлинком либо на /local/php5, либо на /local/php7
Какой ужас. Ядро пыха патчите, а казалось бы такой простой штуки наподобие гентушного eselect в свой well-established и LSB не прикрутили. Хотя бы для себя. Чудеса)

sergpenza
13.03.2016 13:12А Blitz в семерке не работает?
youROCK
13.03.2016 13:31+4Почему не работает :)? https://github.com/alexeyrybak/blitz/tree/php7 — пользуйтесь на здоровье. У нас эта ветка в продакшене.
Badoo
14.03.2016 20:12+1Вот тут можно почитать английскую версию статьи: https://techblog.badoo.com/blog/2016/03/14/how-badoo-saved-one-million-dollars-switching-to-php7/

hitman47h
15.03.2016 10:27+4"The so-called Brazilian System", I've never heard this term before. Why is it called that? Did you guys coin the term? ))))))))))))))))


wickedweasel
15.03.2016 15:35+1Маленькая просьба: очень хотелось бы видеть графики, начинающиеся с нуля.
DjOnline
16.03.2016 14:04Отличный кейс!
Почему в другом кластере не используется OPCache?
PHP у вас по прежнему живёт моделью always die, не рассматривали переход на phpDaemon/react-php?
Кстати, почему igbinary до сих пор не включили в ядро?Fesor
16.03.2016 14:07+1переход на phpDaemon/react-php?
Хочу заметить что на базе проекта amphp можно сделать вещи поинтереснее. В частности недавно вот вышел ayres-reverse для проксирования запросов, а стало быть можно прикрутить amphp/process для управления воркерами и получить на выходе более-менее православный php-pm, с хот-релоадом воркеров и т.д.
sloven
16.03.2016 17:27+3По мотивам вашего поста обновились на production на php7
вылезла одна странная штука… Либо я не понимаю как оно работает либо это баг
https://bugs.php.net/bug.php?id=71837&thanks=4

AHTOH
17.03.2016 18:55Мне одному кажется, что вы сэкономили не 300 серверов, а 600?
Вы увеличили производительность вдвое, как если бы вы без оптимизации добавили столько же серверов, сколько у вас было.
То есть текущая производительность после оптимизации примерно равна двойной производительности до, то есть 600+600 серверов.
В итоге экономия в $2 млн на железе и $200к на хостинге.VolCh
18.03.2016 15:08+1При текущих нагрузках экономия 300 серверов, которые можно, например, продать.
AHTOH
18.03.2016 15:36+1Я исходил из фразы автора
теперь мы можем на том же количестве серверов выдерживать намного большую нагрузку, что, по сути, снижает затраты на его приобретение и обслуживание
В этом случае выгода составляет 600 серверов.
Если же рассматривать выгоду с точки зрения продажи освобождаемого оборудования, то Вы совершенно правы — 300 железных серверов. Но в этом случае цена каждого used сервера будет намного ниже $4000, что в итоге составит менее $1М.
baltazorbest
18.03.2016 17:19+1А подскажите пожалуйста, как себя ведет APcu при больших нагрузка? И на сколько большие данные вы там храните? Спасибо.
youROCK
19.03.2016 12:47+1Данные храним небольшие, в основном нам это нужно для нашего аналога circuit breaker (https://en.wikipedia.org/wiki/Circuit_breaker) — механизма, который предотвращает исчерпание всех воркеров при «затупах» одного сервиса (не важно, mysql это, memcache или самописный демон).
На больших нагрузках он начинал упираться во внутренние mutex'ы, и вроде бы с тех пор ситуация стала получше. Мы также переписали свой код с использования cas на использование inc/dec (атомарные операции, также как и cas), и с тех пор вообще проблем с этим механизмом не имеем.
AloneCoder
Круто, молодцы!