

Эта статья основана на материалах презентации, которую я представил в этом году на конференции OSCON. Я отредактировал текст, чтобы он был более лаконичным, а заодно учёл ту обратную связь, что я получил после своего выступления.
Про Go часто говорят, что он хорош для серверов: здесь есть статические бинарники (static binaries), развитый concurrency, высокая производительность. В этой статье мы поговорим о двух последних пунктах: о том, как язык и среда выполнения (runtime) ненавязчиво позволяют Go-программистам создавать легко масштабируемые серверы и не беспокоиться из-за управления потоками (thread) или блокирующих операций ввода/вывода.
Аргумент в пользу производительности языка
Но прежде чем перейти к техническим деталям, я хочу сделать два утверждения, характеризующие рыночный сегмент языка Go.
Закон Мура
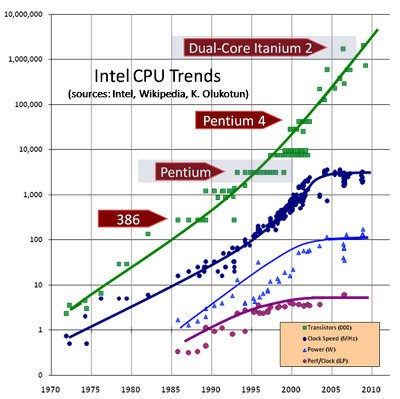
Согласно часто ошибочно цитируемому закону Мура, количество транзисторов на единице площади кристалла удваивается примерно каждые 18 месяцев. Однако рабочие частоты, зависящие от совершенно других свойств, перестали расти уже с десяток лет назад, с выходом Pentium 4, и с тех пор понемногу снижаются.
От пространственных ограничений к энергетическим

Sun Enterprise e450 — размером примерно с барный холодильник и потребляет примерно столько же электричества
Это Sun e450. Когда моя карьера только начиналась, эти компьютеры были рабочими лошадками индустрии. Они были массивны. Если поставить один на другой три штуки, то они займут целую 19-дюймовую стойку. При этом каждый потреблял всего лишь около 500 Вт.
За последнее десятилетие главным ограничением для дата-центров стало не доступное пространство, а уровень потребления электроэнергии. В последних двух случаях, когда я принимал участие в запуске дата-центров, нам не хватало энергии уже при заполнении стоек едва ли на треть. Плотность вычислительных мощностей выросла столь быстро, что теперь можно не думать о том, где же разместить оборудование. При этом современные серверы начали потреблять гораздо больше электричества, хотя и стали гораздо меньше. Это сильно затрудняет охлаждение, качество которого критически важно для функционирования оборудования.
Эффект от энергетических ограничений проявился:
- на макроуровне — мало кто может обеспечить работу стойки с 1200-ваттными 1U-серверами;
- на микроуровне — все эти сотни ватт рассеиваются на маленьком кремниевом кристалле в виде тепла.
С чем связан такой рост энергопотребления?

КМОП-инвертор
Это инвертор, один из простейших логических вентилей. Если на вход А подаётся высокий уровень, то на выход Q подаётся низкий, и наоборот. Вся современная потребительская электроника построена на КМОП-логике (КМОП — комплементарная структура металл-оксид-полупроводник). Ключевое слово здесь «комплементарная». Каждый логический элемент внутри процессора реализован с помощью пары транзисторов: когда один включается, другой выключается.
Когда на выходе инвертора высокий или низкий уровень, то от Vss к Vdd ток не течёт. Но во время переключений есть короткие периоды, когда оба транзистора проводят ток, создавая короткое замыкание. А потребление энергии — следовательно, и рассеяние тепла — прямо пропорционально количеству переключений в секунду, то есть тактовой частоте процессора.
Потребление энергии КМОП связано не только с короткими замыканиями при переключениях. Свой вклад вносит зарядка выходной ёмкости затвора. К тому же ток утечки затвора возрастает с уменьшением размера транзистора. Подробнее об этом можно почитать по ссылкам: раз, два.
Уменьшение размеров элементов процессора направлено в первую очередь на снижение энергопотребления. Это нужно не только ради экологии, основная цель — удерживать тепловыделение на приемлемом уровне, чтобы не допускать повреждения процессоров.
Вопреки снижению тактовых частот и энергопотребления, рост производительности в основном связан с улучшениями микроархитектуры и эзотерическими векторными инструкциями, которые не особо полезны для общих вычислений. В результате каждая микроархитектура (5-летний цикл) превосходит предыдущее поколение не более чем на 10%, а в последнее время едва дотягивают до 4–6%.
«Халява кончилась»
Надеюсь, теперь вы понимаете, что железо не становится быстрее. Если вам важны производительность и масштаб, то вы согласитесь со мной, что решать проблемы силами одного лишь оборудования уже не удастся, по крайней мере в общепринятом смысле. Как сказано у Герба Саттера — «Халява кончилась».
Нам нужен производительный язык программирования, потому что неэффективные языки просто не оправдывают своего использования в широкой эксплуатации, при масштабировании и с точки зрения капитальных вложений.
Аргумент в пользу параллельного языка программирования
Мой второй аргумент вытекает из первого. Процессоры не становятся быстрее, но зато становятся толще. Вряд ли для вас должно быть сюрпризом, что транзисторы развиваются в этом направлении.

Одновременная многопоточность, или Hyper-Threading, как это называет Intel, позволяет одному ядру параллельно выполнять несколько потоков инструкций благодаря добавлению небольшой аппаратной обвязки. Intel применяет технологию Hyper-Threading для искусственного сегментирования рынка процессоров, в то время как Oracle и Fujitsu активнее используют её в своей продукции, доводя количество аппаратных потоков выполнения до 8 или 16 на каждое ядро.
Двухпроцессорные материнские платы появились в конце 1990-х, когда вышел Pentium Pro. Сегодня это стандартное решение, большинство серверов поддерживают двух- или четырёхпроцессорные конфигурации. Увеличение плотности транзисторов позволило даже размещать несколько ядер на одном кристалле. Двухъядерные процессоры обосновались в мобильном сегменте, четырёхъядерные — в настольном, ещё больше ядер в серверном сегменте. По сути, сегодня количество ядер в сервере ограничено лишь вашим бюджетом.
И чтобы воспользоваться преимуществами всех этих ядер, вам нужен язык программирования с развитым параллелизмом.
Процессы, потоки выполнения и горутины
В основе параллелизма Go лежат так называемые горутины (goroutine). Давайте немного отвлечёмся и вспомним историю их возникновения.
Процессы
На заре времён, при пакетной модели обработки, компьютеры могли выполнять в один отрезок времени только одну задачу. Стремление к более интерактивным формам вычисления привело в 1960-х к разработке многопроцессных операционных систем, или систем, работающих в режиме разделения времени (time sharing). В 1970-х эта идея проникла в серверы, FTP, Telnet, rlogin, а позднее и в CERN httpd Тима Бернерса-Ли. Обработка всех входящих сетевых соединений сопровождалась порождением (forking) дочерних процессов.
В системах с разделением времени ОС поддерживает иллюзию параллельности, быстро переключая ресурсы процессора между активными процессами. Для этого сначала записывается состояние текущего процесса, а затем восстанавливается состояние другого. Это называется переключением контекста.
Переключение контекста

У переключения контекста есть три основные статьи расходов:
- Ядро должно сохранять содержимое всех регистров процессора сначала для одного процесса, потом восстанавливать значения для другого. Поскольку переключение между процессами может произойти в любой момент, ОС должна хранить содержимое всех регистров, потому что она не знает, какие из них сейчас используются. Конечно, это крайне упрощённое описание. В ряде случае ОС может избегать сохранения и восстановления часто используемых архитектурных регистров, запуская процесс в таком режиме, при котором доступ к floating-point или MMX/SSE-регистрам вызовет прерывание (fault). В таких ситуациях ядро понимает, что процесс будет использовать эти регистры и их нужно сохранять и восстанавливать.
- Ядро должно очистить кеш соответствия виртуальных адресов памяти физическим (TLB, буфер ассоциативной трансляции). В некоторых процессорах используется так называемый tagged TLB. В этом случае ОС может приказывать процессору присваивать конкретным записям буфера идентификаторы, полученные из ID процесса, а не обрабатывать каждую запись как глобальную. Это позволяет избежать удаления записей из кеша при каждом переключении процессов, если нужный процесс быстро возвращается в то же ядро.
- Накладные расходы ОС на переключение контекста, а также накладные расходы функции-планировщика при выборе следующего процесса для обеспечения процессора работой.
Все эти расходы относительно постоянны с точки зрения оборудования, но от объёма выполненной между переключениями работы зависит, оправданны ли эти расходы. Слишком частые переключения сводят на нет количество выполненной работы между ними.
Потоки
Это привело к появлению потоков, которые представляют собой те же процессы, использующие общее адресное пространство. Благодаря этому они проще в планировании, чем процессы, быстрее создаются и между ними можно быстрее переключаться.
Тем не менее стоимость переключения контекста у потоков достаточно высока. Необходимо сохранять немало информации о состоянии. Горутины фактически являются дальнейшим развитием идеи потоков.
Горутины
Вместо того чтобы возлагать на ядро обязанности по управлению временем их выполнения, горутины используют кооперативную многозадачность. Переключение между ними происходит только в чётко определённые моменты, при совершении явных вызовов runtime-планировщиком Go. Основные ситуации, в которых горутина вернёт управление планировщику:
- отправка и приём из канала, если они приведут к блокировке;
- вызов инструкции go func(...), хотя нет гарантии, что переключение на новую горутину произойдёт немедленно;
- возникновение блокирующих системных вызовов, например операций с файлами или сетевых операций;
- после остановки выполнения для прогона цикла сборки мусора.
Иными словами, речь идёт о ситуациях, когда горутине не хватает данных для продолжения работы либо ей нужно больше места для записи данных.
В процессе работы runtime-планировщик Go переключается между несколькими горутинами в пределах одного потока операционной системы. Это удешевляет их создание и переключение между ними. Совершенно нормальная ситуация, когда в одном процессе выполняются десятки тысяч горутин, не редкость и сотни тысяч.
С точки зрения языка планирование выглядит как вызов функции и имеет ту же семантику. Компилятору известно, какие регистры используются, и он автоматически их сохраняет. Поток вызывает планировщик, работая с определённым стеком горутин, но по возвращении стек может быть другой. Сравните это с многопоточными приложениями, когда поток может быть вытеснен в любое время, в момент выполнения любой инструкции.
Всё это приводит к тому, что на каждый процесс Go приходится относительно немного потоков ОС. Среда выполнения Go заботится о том, чтобы назначать готовые к исполнению горутины в свободные потоки ОС.
Управление стеком
В предыдущем разделе мы говорили о том, как горутины снижают накладные расходы на управление многочисленными — иногда достигающими сотен тысяч — параллельными потоками. У истории с горутинами есть и другая сторона — управление стеком.
Адресное пространство процесса
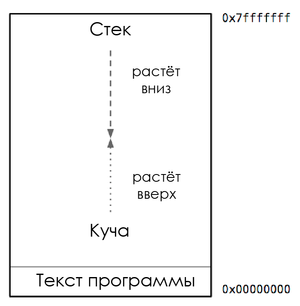
На этой схеме представлена типичная карта памяти процесса. Здесь нас интересует размещение кучи и стека. Внутри адресного пространства процесса куча обычно находится на «дне» памяти, сразу над программным кодом, и растёт вверх. Стек расположен наверху виртуального адресного пространства и растёт вниз.

Если куча и стек перепишут друг друга, это будет катастрофой. Поэтому ОС выделяет между ними буферную зону недоступной памяти. Она называется сторожевой страницей (guard page) и фактически ограничивает размер стека процесса, обычно в пределах нескольких мегабайтов.
Стеки потока

Потоки используют одно общее адресное пространство. Каждому потоку нужен свой стек с отдельной сторожевой страницей. Поскольку трудно спрогнозировать потребности каждого из потоков, под каждый стек приходится резервировать большой объём памяти. Остаётся только надеяться, что этого будет достаточно и мы никогда не попадём на сторожевую страницу.
Недостаток этого подхода в том, что с увеличением количества потоков в программе уменьшается объём доступного адресного пространства.
Управление стеком горутин
В ранней версии модели процессов программисты могли считать, что куча и стек достаточно велики, чтобы не переживать об этом. Однако моделирование подзадач становилось сложным и дорогим.
С внедрением потоков ситуация немного улучшилась. Но программисты должны угадывать наилучший размер стека. Будет слишком мало — программа вылетит, слишком много — закончится виртуальное адресное пространство.
Мы уже видели, что планировщик Go выполняет большое количество горутин внутри небольшого количества потоков. А что насчёт требований к размеру стеков этих горутин?
Рост стека горутин

Изначально у каждой горутины есть маленький стек, выделенный из кучи. Его размер менялся в зависимости от версии языка, в Go 1.5 по умолчанию выделяется по два килобайта. Вместо использования сторожевой страницы компилятор Go вставляет проверку, которая является частью вызова каждой функции.
Проверка позволяет выяснить, достаточен ли размер стека для выполнения функции. Если да, то функция выполняется в штатном режиме. Если же стек слишком мал, то среда выполнения выделяет в куче более крупный сегмент, копирует туда содержимое текущего стека, освобождает его и перезапускает функцию.
Благодаря этому механизму можно делать очень маленькие начальные стеки горутин. В свою очередь, это позволяет рассматривать горутины как дешёвый ресурс. Предусмотрен также механизм уменьшения размера стека, если достаточная его часть остаётся неиспользуемой. Процедура уменьшения выполняется в ходе сборки мусора.
Интегрированный сетевой поллер (network poller)
В 2002 году Дэн Кегель (Dan Kegel) опубликовал статью «Проблема c10k». Говоря простым языком, она была посвящена написанию серверного ПО, способного обрабатывать не менее 10 000 ТСР-сессий на недорогом оборудовании, доступном в то время. После написания этой статьи возникло расхожее мнение, что высокопроизводительные серверы нуждаются в нативных потоках. Позднее их место заняли циклы событий (event loops).
С точки зрения стоимости планирования и потребления памяти потоки имеют высокие издержки. У циклов событий ситуация получше, но у них есть собственные требования в связи со сложным, основанным на callback'ах принципом работы.
Go взял всё самое лучшее из этих двух подходов.
Ответ Go на проблему c10k
Системные вызовы в Go обычно являются блокирующими операциями. К таким вызовам относятся в том числе чтение и запись в файловые дескрипторы. Планировщик Go обрабатывает эти случаи, находя свободный поток или создавая новый, чтобы можно было продолжить обслуживать горутины, пока заблокирован исходный поток. В жизни это хорошо подходит для файловых операций, потому что небольшое количество блокирующих потоков может быстро исчерпать пропускную способность локального ввода/вывода.
Однако с сетевыми сокетами всё не так просто. В каждый момент времени почти все ваши горутины будут заблокированы в ожидании выполнения сетевых операций ввода/вывода. В случае примитивной реализации потребуется делать по одному потоку на каждую такую горутину, и все они окажутся заблокированы в ожидании сетевого трафика. Справиться с этой ситуацией помогает интегрированный сетевой поллер Go, обеспечивающий взаимодействие между средой выполнения языка и пакетом net.
В старых версиях Go сетевым поллером выступала одна горутина, которая с помощью kqueue или epoll запрашивала уведомления о готовности. Такая горутина общалась с ожидающими горутинами через канал. Это позволяло избегать выделения потока для каждого системного вызова, но приходилось использовать обобщённый механизм пробуждения посредством записи в канал. Это означает, что планировщик не был осведомлён об источнике или важности пробуждения.
В текущих версиях Go сетевой поллер интегрирован в саму среду выполнения (в runtime). Поскольку среда знает, какая горутина ожидает готовности сокета, то она может по прибытии пакета продолжить выполнять горутину на том же ядре процессора, уменьшая задержку и увеличивая пропускную способность системы.
Горутины, управление стеком и интегрированный сетевой поллер
Подведём итоги. Горутины являются мощной абстракцией, благодаря которой вы можете не беспокоиться о пулах потоков или циклах событий.
Стек горутины растёт по мере надобности, и вам не придётся волноваться об изменении размера стеков или пулов потоков.
Интегрированный сетевой поллер позволяет избегать использования витиеватых схем на основе callback'ов. При этом задействуется наиболее эффективная логика выполнения операций ввода/вывода, какую только можно получить от ОС.
Среда выполнения заботится о том, чтобы потоков было ровно столько, сколько нужно для облуживания всех ваших горутин и для загрузки ядер процессора.
И все эти возможности совершенно прозрачны для Go-программиста.
Комментарии (23)

nwalker
06.05.2016 13:48+4Не заметил, что перевод, ожидал от статьи гораздо большего.
Претензия к оригиналу — как обычно, про спорные аспекты поведения рантайма ни слова.


creker
06.05.2016 15:09Основные ситуации, в которых горутина вернёт управление планировщику
Помимо этого в недавней версии управление планировщику передается при обычном вызове функции, если она не было заинлайнена. Таким образом управление возвращается даже без каких-либо блокирующих операций.
vintage
06.05.2016 16:17+2Любой функции?

vstarodub
06.05.2016 22:22Практически любой нетривиальной. Go много чего не инлайнит. Но планировщик мы должны вызывать только если действительно нужно вытеснить горутину. Более того, насколько я понимаю, там оверхед всего в одну проверку через которую сделано и увеличение стека, и вытеснение горутины.
Кроме того, вызов runtime-планировщика не такая уж и дорогая операция т.к. в отличие от планировщика ОС нет переключения контекста userspace -> kernel space. Это по сути вызов функции.
Но вообще, на каждый байт большого буффера/на каждый символ строки вызывать по несколько функций может быть довольно дорого если код критичный по производительности.creker
07.05.2016 00:08-1Да, проверка на передачу управления происходит там же, где увеличивается размер стека. Естественно при каждом вызове не будет происходить переключения на другую горутину, так же как и стек никто все время не трогает. Какой-то оверхед это имеет, но куда важнее то, что это обеспечивает более эффективное распределение ресурсов процессора между горутинами.
vstarodub
07.05.2016 00:18Я на самом деле хотел подчеркнуть, что не надо пугаться и в шедулер мы, строго говоря, не попадаем при каждом вызове функции :) Просто проверяем флажок.
creker
06.05.2016 23:55Любой, которую компилятор посчитает подходящей. Что-то заинлайнит, что-то посчитает слишком простой функцией. Сделано это было для обеспечения более эффективной кооперативной многозадачности, чтобы было меньше голодания горутин.
Вот искусственный пример, который позволяет увидеть это в действии. Собирать нужно с помощью «go build -gcflags '-l -N'», чтобы отключить оптимизации. Данный пример использует лишь один поток ОС для выполнения горутин, но горутина все равно будет выполнена, хотя рантайму нигде не передается управление.
package main import ( "fmt" "runtime" ) func foo() { m := 0 for i := 0; i < 100; i++ { m++ } for i := 0; i < 100; i++ { m++ } for i := 0; i < 100; i++ { m++ } for i := 0; i < 100; i++ { m++ } for i := 0; i < 100; i++ { m++ } } func main() { runtime.GOMAXPROCS(1) go func(){ fmt.Println("I'm alive") }() for i := 0; i < 10000000; i++ { foo() } }
billyevans
07.05.2016 00:20+1Как то неочивидно, почему стек в 2КБ менее ресурсоемок, чем, например в 24МБ, это же виртуальная память и выделить ее должно быть одинаково затратно. Так же как то неясно как может закончится виртуальная память, ее же сильно много. Я видел процессы в сотни гигабайт виртуальной памяти и они прекрасно выделяли память дальше. Возможно я чего то недопонял или не знаю.
creker
07.05.2016 00:33Виртуальная память, в конечном итоге, мапится на физическую. И при каждом вызове выделять по 24МБ из кучи (которая совсем не бесконечная и быстро приведет к свопингу) — вы представляет, что будет твориться с типичной Go программой, которая сотнями создает и убивает горутины постоянно? 2КБ хватит для большинства горутин, т.к. глубина стека у них обычно довольно маленькая. Если надо, объем этот увеличится или уменьшится. Все это делается, чтобы горутины были легковесными и быстрыми. Это не потоки, которые создаешь и держишься за них всю программу. Язык поощряет создавать большое количество маленьких короткоживущих горутин, а им большой стек совсем не нужен. Что, в свою очередь, упрощает написание конкурентного кода.
Вот статья от того же автора на эту тему http://dave.cheney.net/2013/06/02/why-is-a-goroutines-stack-infinitebillyevans
07.05.2016 01:39Вроде речь про сервера идет, я там не встречал свопа. В том то и дело, что malloc(2KB) и malloc(24MB) одинаково имеют одинаковую сложность и тоже самое с освобождением. Тк это всеголишь виртуальная и из нее использовано только несколько страниц будет.
vstarodub
07.05.2016 01:50Вообще говоря, malloc 2Kb и 24Mb будет выделять разными механизмами — 2Kb через brk (то есть, если место в куче есть, syscall-ов не делаем), 24Mb — через mmap.
billyevans
07.05.2016 02:10Зависит от реализации аллокатора, но да, скорее всего большой кусок будет mmap-ом.
vstarodub
07.05.2016 00:41Если выделить честные реальные 24Мб на горутину, то это будет ресурсоемко по памяти. Если выделять виртуальную и обрабатывать page fault-ы, то это будет ресурсоемко по CPU, т.к. не выходя из user space мы в принципе не сможем обработать этот случай. Более того, придется делать больше одного context switch-а.
Кроме того, нужно будет уметь отдавать обратно память в систему, что тоже проблематично из user space. Если использовать аллокации из кучи и копирование, то это в типичном случае должно быть быстрее, чем переключение контекста.
Ну и пока еще не умерли 32-битные архитектуры.billyevans
07.05.2016 01:46То есть идея в том, что вместо page-fault-ов при хождении в грубь стека и переключения в режим ядра го делает realloc стека по сути и это должно быть быстрее?
А что проблемотичного отдать память назад? mmap/unmap.
Чет мне кажется 32-х битные это уже какие то встраиваемые вещи, вроде на телефонах даже уже 64.vstarodub
07.05.2016 02:03Да, мне кажется, что основное преимущество тут в отсутствии переключений в режим ядра. Может быть я что-то еще из вида упускаю.
Получается, что для запуска горутины нужно сделать аллокацию на куче в 2Кб, поменять значение регистров и завести нужные структуры в шедулере. Все это быстро, т.к. почти всегда в user-space. Эти 2Кб целиком даже не обязательно трогать, если горутине будет достаточно всего, скажем, байт 100 стека. Отсюда и легковесность.
ARM-ов 32-битных по-моему еще достаточно много в телефонах. Например как минимум половина андроидов еще на версии ниже 5 (в 5-й начали поддерживать 64 бита). И, если я правильно понимаю, go достаточно активно пытаются внедрить на мобильных платформах.
vstarodub
07.05.2016 03:02Еще, по поводу mmap/unmap и соответствующих context switch. Цифр не нашел, специально померил — 150нс уходит просто на то, чтобы вернуть EINVAL. То есть это просто оверхед на сам факт вызова. А таких вызова будет 2 (mmap + munmap).
В Linux, адресное пространство у процесса меняется под несколькими локами (page_table_lock, mmap_sem, https://www.kernel.org/doc/gorman/html/understand/understand007.html) и такие операции будут выстраиваться в очередь. Плюс, там еще сама логика какое-то время будет занимать.
В простом бенчмарке запущенном с GOMAXPROCS=1 у меня получился оверхед на запуск пустой горутины в ~230нс (при этом все время проведено в user space):
package main import ( "runtime" ) func main() { for i := 0; i < 1e7; i++ { go func() {}() if i%20 == 0 { runtime.Gosched() } } }

hellosandrik
07.05.2016 03:06+2По-моему, тема event-loop'а не раскрыта (хотя он упоминается в названии статьи). Только вскользь сказано, что их минус — callback'и, хотя проблему с callback hell в js, например, уже давно решают с async/await. Это, конечно, претензия к оригиналу, но хотелось бы подробностей, как горутины помогают удобнее писать код, задействующий все ядра процессора.
vintage
07.05.2016 09:21+1Самое забавное, что в NodeJS проблема callback-hell решается аналогично Go — через сопрограммы (node-fibers, а не конечный автомат async-await). Хотя из статьи может сложиться впечатление, будто сопрограммы есть только в Go.
vstarodub
07.05.2016 17:01+2Async/await выглядит похожим механизмом. Но без поддержки со стороны языка (прологи функций в go), например, нельзя сделать «автоматическое» вытеснение. Не то, чтобы без этого никак, но это удобно.
Горутины прозрачно запускаются в нескольких системных тредах, в этом принципиальное отличие от стандартных имплементаций корутин/fiber-ов.
ZurgInq
Для сравнения, перевод этой же статьи