

Вступление
В один прекрасный денек я зашёл в библиотеку за одним рассказом. Сказав название и автора рассказа библиотекарю, получил стопку сборников данного автора. Для того чтобы найти среди всего этого многообразия нужный рассказ, пришлось перебрать все произведения. Намного легче было бы «загуглить» нужное произведение и получить желаемое в несколько кликов.

И тогда я задумался: ”А почему в библиотеках до сих пор нет подобного? Это же так удобно!”. Естественно, как любой порядочный ленивый программист, я пошел прямиком в поисковик искать подобные проекты. И столкнулся с проблемами. Все найденные проекты были либо коммерческими (платными), либо любительскими и некачественными.
Естественно, подобную несправедливость срочно нужно было решать, несмотря на приближающееся ЕГЭ и поступление в ВУЗ.
Выбор языка
Первым делом стало понятно, что без веб-части не обойтись. Несмотря на мою личную непереносимость к веб-программированию, я сел за гугл и начал изучать данный вопрос.
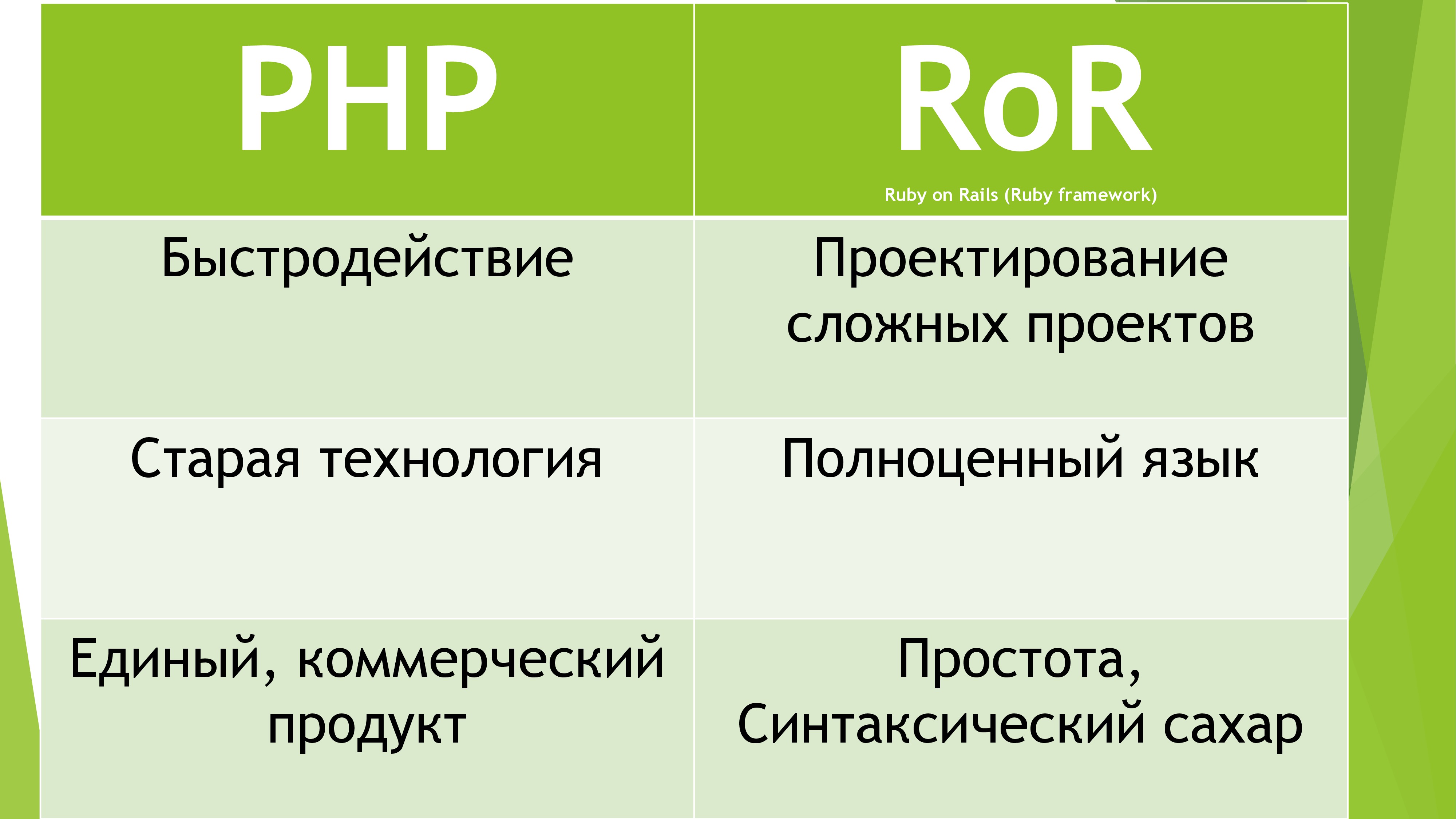
После нескольких часов я наконец-то выбрал необходимый язык. Точнее не язык, а FrameWork RubyOnRails. Почему он? Потому что он использует полноценный ООП язык, активно разрабатывается гигантским комьюнити и обладает быстрым ядром. К тому же, Ruby любят девушки (на презентации лучше не говорить).
Естественно, основан он был на “прекрасном” языке Ruby. Так как я на уровне Junior знаю Java, изучить любой другой ООП язык для меня не составило труда. Неделю каждый вечер смотрел по 2 лекции и в итоге мог похвастаться необходимыми знаниями синтаксиса Ruby. И потом мою самоуверенность опустили… А всё потому, что данный FrameWork настолько огромен и обширен, что знания Ruby помогли мне лишь чуть-чуть. Изучив MVC технологию и прочие задумки злобных веб-программистов, я приступил к реализации проекта.
Авторизация
Первым препятствием на моем пути стала, как это ни странно, авторизация. Решил я использовать технологию OAuth. Принцип её заключается в том, что используются токены вместо паролей. Использование токенов позволяет не беспокоиться, что твой пароль украдут, а так же настраивать каждый токен под себя (к примеру, можно брать одноразовые токены с правами лишь на одну операцию). Для хранения паролей на серверной части вначале я решил использовать MD5 шифрование, однако почитав про него в интернете, я решил, что данный метод устарел. Взлом на новых компьютерах осуществляется всего за 1 минуту. Поэтому я решил использовать bCrypt, который обеспечивает почти 100% защиту от расшифровки пароля в БД. Так как я решил самостоятельно сделать подобную систему, пришлось думать над оптимизацией. В первую очередь, токены пришлось переводить из строки в числовое значение, чтобы по БД можно было искать бинарным поиском.

Казалось бы, что сложного может быть в простейшем школьном проекте с авторизацией? Начнем с того, что окошко авторизации я делал 20 часов. А продолжим тем, что мой проект полностью OpenSource и запускается в локальной сети, а это значит, что достаточно развернуть свой сервер на мобильном, чтобы перехватывать токены. Поэтому я придумал собственную систему проверки валидности сервера. С каждым токеном сервер выдает два значения. ID в базе данных и уникальный малочисленный индетификатор. Каждый раз, когда клиент хочет проверить валидность сервера, он отправляет ID серверу, а сервер возращает ему индетификатор. И только тогда клиент отправляет серверу токен. Получается авторизация с двух сторон.
Алгоритм поиска
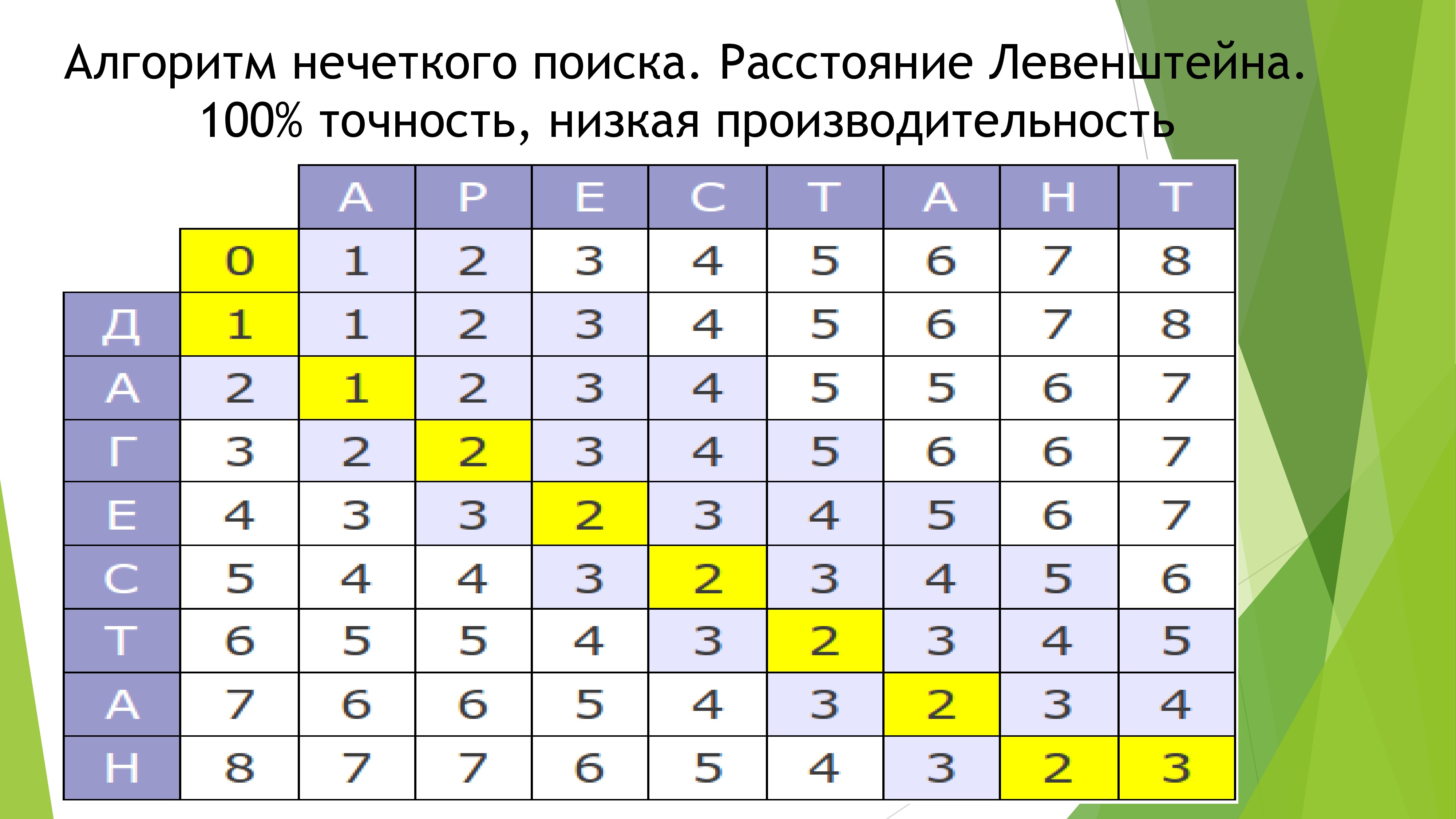
Во всех подобных проектах слабая сторона — поиск. Я бы не хотел, чтобы и в моем проекте присутствовал такой недостаток. Использование готовых решений полностью отметается по причине того, что все крупные поисковики требуют соединения с интернетом. Поэтому к данному вопросу я подошел со всей серьезностью. Почитав книгу про алгоритмы, я решил, что для сравнения строк лучше использовать алгоритм расстояния Дамерау-Левенштейна, так как он обладает максимальной точностью в ущерб производительности, что наиболее важно для проекта. Но возникла проблема в сравнении целых предложений. Сначала я использовал подобный алгоритм, разложив таблицу сравнения на древо графов. Довольно долго я мучался с этим, но в итоге получил не тот результат. Поэтому всё снес и вставил другой алгоритм в сравнение предложений. Его принцип прост до безумия. Если слово имеет меньше 3 ошибок, принять его за правильное и добавить в итоговый индекс 1 балл. Если два правильных слова идут подряд, добавить ещё 1 балл. И так далее.
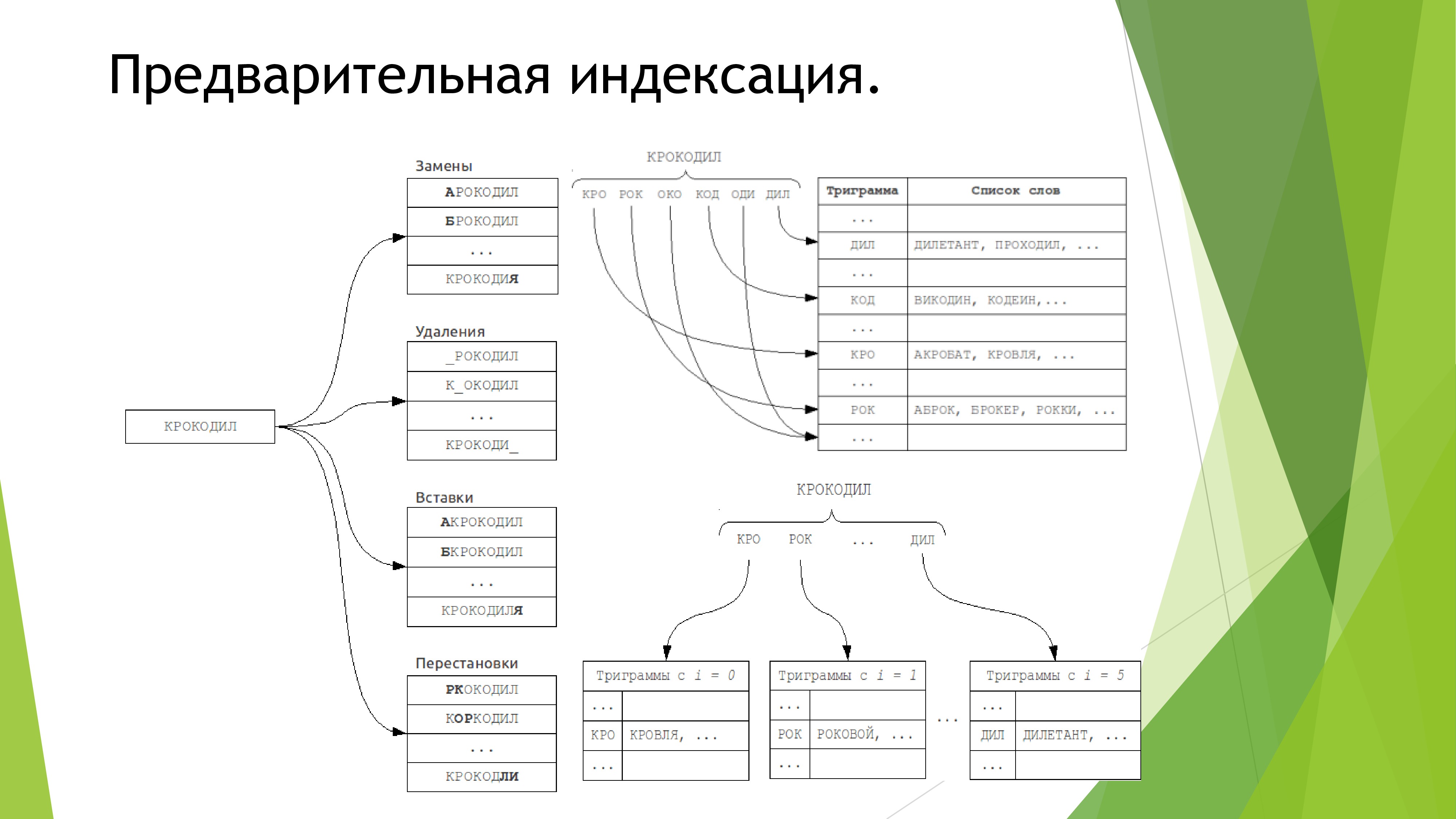
Так как поиск весьма жестко задан, использовать синтаксический смысл предложения не имеет смысла. Поэтому в будущем планируется добавить фонетический поиск и дальше работать в сторону улучшения самообучения системы и централизации всех данных.

Ещё одним способом улучшить качество поиска стало самообучение. Дело в том, что каждый запрос записывается в БД и при необходимости возомжно выдавать добавлять баллы популярным книгам. Допустим, пользователь “Гоша” любит фантастику. Мы это поняли по тому, что количество найденных книг по фантастике намного превышает другие жанры. Поэтому впоследствии, при выдачи результатов поиска, система поиска будет добавлять пользователю “Гоша” дополнительные баллы для книг по фантастике. К тому же, такой большой пласт статистических исследований пригодиться.
Естественно, данный алгоритм потом обзавелся различными оптимизациями, но об этом в другой раз. Такой ресурсоемкий алгоритм я решил реализовать на C++ и сделать мостик из Ruby с помощью плагина Rice. Вот ещё один наглядный пример, почему я выбрал RubyOnRails и не пожалел.
Распознавание изображений
Решить проблему быстрой оцифровки библиотеки поможет только механизмы распознавания текста на картинке. Так как подносить к веб-камере ПК изображение для считывания довольно глупо, было принято решение разработать мобильное приложение для смартфонов. Написание базового приложения заняло порядка недели т.к. в смартфонах активно используется многопоточность и довольно жёсткие критерии для дизайна приложения.
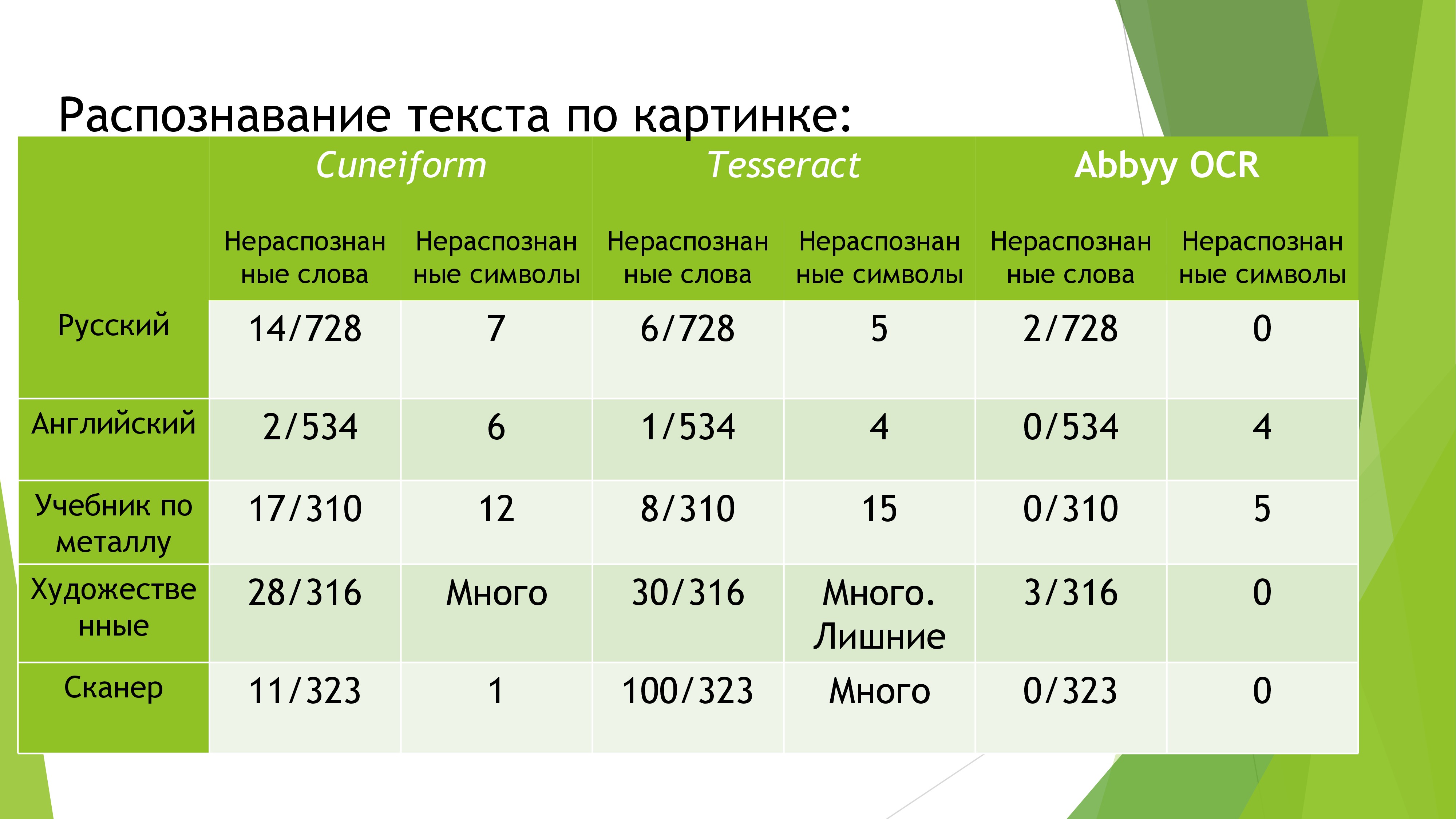
После, проведя глубокий анализ существующих решений, я выбрал Tessaract как самый лучший бесплатный open-source продукт, основанный на технологии OCR. К тому же, активно поддерживаемый Google. Попробовав с ним поиграться, я понял, что такой результат никуда не годиться. Для точного распознавания пришлось бы довольно долго работать с предварительной обработкой изображения. К тому же, в исходниках данного проекта я обнаружил пару грубых алгоритмических ошибок, исправление которых может затянуться на доооолго. Поэтому с грустью в голосе я пошёл просить временную лицензию у Abbyy. Спустя две недели ежедневных звонков, я получил её. Не могу не отметить, что документация и Java-обертка очень грамотно написаны и было в одно удовольствие работать с таким продуктом. Однако, механизм распознавания далёк от 100% точности. Поэтому мне пришлось делать автокоррекцию. За несколько часов я написал бота, который скачал всю БД книг с популярного сайта labirint.ru. Использовав подобную базу и вышеупомянутый алгоритм поиска, точность распознавания книг повысилось в разы.
ISBN

Несмотря на очевидную простоту использования считывания книг, я решил использовать автозаполнение полей через ISBN. Так как скачать всю БД книг ISBN глупо, решил использовать Google Book Api для поиска по ISBN. Так же Offline-пользователям до сих пор доступна БД лабиринта с >200 000 русскоязычных книг. К тому же, легко реализовать сканер штрих-кода книг (на том же Abbyy API) и тогда добавление книг будет только в удовольствие.
Алгоритм сверхбыстрой оцифровки библиотеки

Я подумал, что неплохо бы было сфотографировать полку и добавить все книги в электронный каталог. Реализовать такое легко возможно только с использованием бесплатной библиотеки OpenCV и с встроенным детектором границ Кенни. К тому же, потребуется написать свой алгоритм для более серьёзного анализа основных линий книг и отправлять каждый корешок в Abbyy API и получать нужный текст, обрабатывать его через БД лабиринта и отображать элементы взаимодействия с UI поверх сфотографированного изображения. (К сожалению, у меня так и не дошли руки допилить этот функционал до ума. Времени нет)
Заключение

Низкая стоимость проекта и обширная технологическая база позволяет получить доступ к высоким и удобным технологиям даже ученикам обычных муниципальных школ. Прошу взять тот факт за внимания, что продукт абсолютно открытый и прекрасно работает без доступа к интернету. К тому же, ресурсоемкость проекта позволяет запустить сервер даже на Raspberry PI, стоимостью 20$.
Несмотря на то, что это мне не помогло никак в жизни, я получил ценный опыт разработки полноценного сайта и приложения и мне это было дико интересно. Ну и пара скринов:

Источники информации
- Большое спасибо англоязычной аудитории сайта www.stackoverflow.com
- Большое спасибо пользователю habrahabr.ru ntz за серию шикарнейших статей по нечеткому поиску
- Также в проекте были использованы материалы www.wikipedia.org
- Большое спасибо моей однокласснице Евгении Лендрасовой за красивые и яркие логотипы
- Гигантское спасибо моему преподавателю за поддержку в моих начинаниях
- Гигантское спасибо компании ABBYY за предоставленный OCR для распознавания текста. Без него я бы не смог реализовать этот проект
Комментарии (65)

kolyaflash
23.06.2016 11:06+3Я так и не понял, что вы сделали и зачем (а картинка из заключения — её вообще лучше убрать).
Детально описаны какие-то тривиальные вещи, а про остальное просто сказали, что оно есть.
Для «юнного программиста» старт хороший и у вас всё получится и проект вам ещё пригодится.
Проект «абсолютно открытый», а где ссылка?
LionZXY
23.06.2016 11:19Веб-часть вот. У приложения на андроиде пришлось закрыть исходники по просьбе Abbyy. Да и в приложении нет ничего особого.
И да. Мне стыдно за этот код. По хорошему надо бы всё переписать, но у меня нет времени, да и проект заморожен до лучших времен.
По поводу сути — хотел облегчить страдания библиотекарям. Занести все книги в БД (описание, название, местоположение, кто и когда брал) с помощью мобильного приложения (фотографируешь книгу, isbn, корешок или вводишь вручную). По всему этому сделать поиск + низкая стоимость.
И да. Первый мой пост все же. Много косяков заметил уже после публикации. Буду иметь ввиду. Спасибо за комментарий.kolyaflash
23.06.2016 11:41+3> И да. Мне стыдно за этот код.
Значит вы хороший программист :)
Make it Work, Make it Right, Make it Fast.
> По поводу сути…
Теперь яснее. А то интерфейсы и логотип как бы намекают, что это для широкой аудитории (тоесть, посетителей библиотеки) и картинка в голове не складывалась.
LionZXY
23.06.2016 13:32+1Человек в любом месте подключается к локальной сети WiFi, смотрит есть ли такая книга в библиотеке. Прямо тут же можно будет забронировать книги. Потом идет в библиотеку и библиотекарь отдает книгу.
В будущем планировалось ещё и библиотека электронных книг.

lair
23.06.2016 11:24+3Так как я решил самостоятельно сделать подобную систему, пришлось думать над оптимизацией
Первое правило в работе с безопасностью: никогда не изобретать свою систему безопасности.LionZXY
23.06.2016 11:32+1Проект, в первую очередь, создавался для собственного развития и опыта.
lair
23.06.2016 11:41+1Это не повод вставлять в него собственную систему аутентификации/авторизации.
Если вам интересно поэкспериментировать с криптографией — есть курсы и тестовые задания. В проектах, которые выпускаются в реальную жизнь, надо использовать стандартные компоненты — тогда бы вам не пришлось придумывать собственную систему проверки подлинности сервера (которая, по вашему описанию, полностью подвержена MitM-атаке).
LionZXY
23.06.2016 13:29-1Самая главная причина такого решения — я захотел. Всё остально второстепенно. Не забывайте, что это не коммерческий продукт, а школьный проект.
lair
23.06.2016 13:45+1Самая главная причина такого решения — я захотел
"Я захотел" совершить ошибку, совершил ее, и исправлять не буду. Так это сейчас выглядит.
Не забывайте, что это не коммерческий продукт, а школьный проект.
Это повод делать его плохо?LionZXY
23.06.2016 14:16+3Это повод делать так, чтобы было интересно и полезно, в первую очередь, мне. Естественно, в будущем велосипедов постараюсь избежать.
lair
23.06.2016 14:18Это повод делать так, чтобы было интересно и полезно, в первую очередь, мне.
На безопасность тех, кто пользуется вашей программой, вам наплевать?LionZXY
23.06.2016 14:19В случае школьного проекта, да. В таком виде, всеравно в продакшн пускать это не буду. По хорошему это всё надо переписать.
AlexLeonov
23.06.2016 12:53+12PHP — старая технология и неполноценный язык. Поэтому я выбрал рельсы.
Закрыл статью, дальше не читал.LionZXY
23.06.2016 13:29+1Это я опрометчиво такую фразу оставил :) Давайте не будем разжигать конфликт по этому поводу. Признаю свою вину в этом вопросе.

basili4
23.06.2016 14:00а про быстрое ядро Ruby?



fuCtor
23.06.2016 13:08+4Дня старта не плохо, НО, если выбираете ruby и RoR в частности, то пользуйтесь всеми возможностями экосистемы и накопленными решениями:
— авторизация devise + Doorkeeper (OAuth2 server)
— хотите токены с проверкой, используйте JWT
— поиск, тут да elastic

serafims
23.06.2016 13:19Странно, в районной библиотеке, которой я пользовался 15 лет назад, стояли, конечно, старенькие по тем временам компы, но они позволяли очень гибко искать книги и определять их наличие в конкретный момент времени… И библиотека — не имени маяковского какая-нибудь со штрих-кодами на всем, а обычная…
LionZXY
23.06.2016 13:34Такого в моей школьной библиотеке нет. Да и простота установки такой системы и способ заполнения её данными ставиться под вопросом.


IvanPanfilov
23.06.2016 15:15-3ROR — лучший выбор школоты. любят они языки типа руби — непонятные и с кучей синтаксического сахара, любят манкипатчить код.
> PHP — старая технология
ололо
http://php.net/
LionZXY
23.06.2016 15:37Эта тема обсуждалась ни один раз. Давайте не будем поднимать это снова, хорошо?

uniqm
23.06.2016 15:33+3Понятно, что код в мусорку. Но там в контроллере на каждый запрос поиска все книги из базы ползут в память, потом преобразуются в массив и тд тп. Никакого железа не хватит. Я про следующий код:
…
books = Book.all
books =
books.to_a.sort { |book1, book2| book2.getSearchIndex(params[:srch]) — book1.getSearchIndex(params[:srch]) }
…
Мне кажется подтормаживать должно уже на 100-500 книгах. На каких объемах гонялся код, подозрений не вызывало время ответа?LionZXY
23.06.2016 15:36+1Понятно. А что вы в данном случае посоветуете? Загружать по одному?
uniqm
23.06.2016 16:03+3Применительно к Вашему случаю, необходимо менять подход. У Вас стратегия: тащим все в память, перебираем с некой логикой, пользуемся. А в подобных задачах желательно на этапе записи в БД составить индекс, что бы потом силами БД простым запросом вытащить нужное. Т.е. чуть дольше пишем, но потом быстро считаем. БД уже хранит данные в нужном формате. А так как операций записи сильно меньше, то получаем большой выигрыш.
Правильно выше писали, правильно было бы использовать Elasticsearch, Sphinx и подобное.
Ну и на будущее, при обработке коллекций вместо вытягивания всей таблицы и затем перебора в памяти, используем find_each. Т.е. порционно выкачиваем записи из БД.
Это элементарные вещи. Но и Вы только в начале пути, потом разум будут волновать вопросы совсем другого порядка. Удачи!LionZXY
23.06.2016 16:53Про find_each не знал. Всё остальное знал, но я указал в статье, что индексация дает прирост производительности только на больших данных. В случае маленькой библиотеки нам нужна точность, но не важна производительность
uniqm
23.06.2016 17:17+1Мало знать, нужно применять.
Правильная(читай «нормальная») архитектура окупается с лихвой уже на первых этапах жизни приложения.
Тут не выбор быстро<=>точно, тут выбор быстро<=>медленно, Вы выбрали медленно. И чем больше книг в библиотеке и активнее пользователи — тем хуже поведение системы.
Но это ладно, пишите на ruby Вы отвратительно =) И тут же набежали ruby-хейтеры, про сахар, про манкинпатчинг сразу вспомнили (я никогда в жизни не патчил, думаю я не один такой).
Например следующий код можно выбросить из экшена search, это переливание ни к чему:
@books_for_s = []
books.each do |i|
@books_for_s.push i
end
И тут уже не знаю что посоветовать, может больше чужого кода смотреть, в туториалы с примерами кода вникать, стайлгайды глянуть, типовые ошибки новичков погуглить и тд.LionZXY
23.06.2016 17:19-1Какая речь может идти о индексации, если поиск нечеткий и нам надо проработать все варианты.
uniqm
23.06.2016 17:28+1Посмотрите как устроена работа elasticsearch-а или sphinx-а и почему они быстро ищут (разумеется с морфологией и тд).
LionZXY
23.06.2016 17:31-1Там используется индексация, что приводит к ухудшению качества поиска, но к существенному увеличению скорости. О чем выше я и сказал.
lair
23.06.2016 17:55Там используется индексация, что приводит к ухудшению качества поиска,
Вы это утверждение проверяли? Сама по себе индексация к ухудшению поиска не приводит, к ухудшению приводит неправильно выбранный алгоритм. Для вашего случая (поиск по совпадениям слов с фиксированным количеством ошибок, никакой морфологии), если я не ошибаюсь, можно использовать n-граммы, где n — длина слова минус два, а дальше строить индекс по этим n-граммам.lair
23.06.2016 18:23+1А нет, я не совсем прав. n-граммы, конечно, использовать можно, но вот формировать их сложнее. Собственно, в статье ntz алгоритмы и показаны.
LionZXY
23.06.2016 19:48Да. Я про это и говорил
lair
23.06.2016 21:07Говорить-то говорили, только что-то я не вижу, чтобы вы их использовали (может, я, конечно, не туда смотрю?). Более того, вы даже не используете очевидную (из вашего требования "Если слово имеет меньше 3 ошибок, принять его за правильное") оптимизацию, основанную на длинах слов.
LionZXY
23.06.2016 21:19-1В коде идет 30% от длины слова и учитывается длинна слова при ранжировании поиска. Это опечатка в текста. И да. Индексацию я не использую, потомучто это медленно на малых количествах книг. О чем я и упоминал в тексте поста, ссылаясь на статью ntz.
lair
23.06.2016 21:45+1В коде идет 30% от длины слова
Где именно?
Индексацию я не использую, потомучто это медленно на малых количествах книг.
Вы это замеряли?
О чем я и упоминал в тексте поста
Серьезно? Приведите цитату.LionZXY
24.06.2016 08:17Вы это замеряли?
Да. Замерял. Делая индексацию, мы создаем множество слов. Поиск по индексированной базе O(logN*L). Поиск по непроиндексированной O(N*M*L). При малом N приемущества имеет поиск не по индексированной базе так как в случае индексации N пропорционально увиличиватся. На больших словарях выгодна индексация т.к. многие варианты уже обработаны.
Либо делать частичную индексацию. Но у неё точность маленькая. В данном случае производительность не критична, а вот точность важна.
Расширение выборки
Размер индекса: 65 Мб
Время поиска: 320 мс / 330 мс
Полнота результатов: 100%
N-грамм (оригинальный)
Размер индекса: 170 Мб
Время создания индекса: 32 с
Время поиска: 71 мс / 110 мс
Полнота результатов: 65%
N-грамм (модификация 1)
Размер индекса: 170 Мб
Время создания индекса: 32 с
Время поиска: 39 мс / 46 мс
Полнота результатов: 63%
N-грамм (модификация 2)
Размер индекса: 170 Мб
Время создания индекса: 32 с
Время поиска: 37 мс / 45 мс
Полнота результатов: 62%
Хеширование по сигнатуре
Размер индекса: 85 Мб
Время создания индекса: 0.6 с
Время поиска: 55 мс
Полнота результатов: 56.5%
BK-деревья
Размер индекса: 150 Мб
Время создания индекса: 120 с
Время поиска: 540 мс
Полнота результатов: 63%lair
24.06.2016 10:45+1Поиск по индексированной базе O(logNL). Поиск по непроиндексированной O(NM*L)
O(log N * L) меньше, чем O(NML)
Либо делать частичную индексацию. Но у неё точность маленькая
Да откуда вы это взяли? Возьмем банальнейший поиск по слову. Если у вас максимально допустимая дистанция редактирования — 2, значит, вам нужно выбрать для сравнения слова, чья длина в пределах двух от длины вашего слова. Что не так с "точностью"?
И зачем вы приводите не свои результаты?LionZXY
24.06.2016 15:48-1И зачем вы приводите не свои результаты?
Потомучто вы упорно не пытаетесь разобраться в этом вопросе. Я скидывал ссылку на статью ntc. Вам было лень её прочитать. Я любезно перекопировал её вам.
O(log N * L) меньше, чем O(NML)
N разное.
Что не так с «точностью»?
Попробуйте посмотреть на ту цитату, которую я скидывал
P.S. Я заканчиваю этот разговор со своей стороны. Я подозреваю, что вы просто тролль и даже не пытаетесь выяснить правду в данном вопросе.lair
24.06.2016 15:51Потомучто вы упорно не пытаетесь разобраться в этом вопросе. Я скидывал ссылку на статью ntc. Вам было лень её прочитать. Я любезно перекопировал её вам.
У вас свои замеры, подтверждающие ваши утверждения, есть?
N разное.
Значит, приводить эти две метрики рядом — нельзя.
Попробуйте посмотреть на ту цитату, которую я скидывал
И какое отношение она имеет к приведенной мной методике?

mantyr
23.06.2016 18:40У вас так же откровенно не корректный способ ранжирования результатов. Делать +1 на каждое последующее «не полное» совпадение значит почти стопроцентное перемешивание результатов где есть более важные ключевые слова и в тоже время куча второстепенных и малозначимых.
lair
23.06.2016 18:58+1… а у эластика прямо явно сказано, что они умеют делать поиск по расстоянию Левенштейна.
LionZXY
23.06.2016 19:47И что? Ещё раз! Я отказываюсь использовать готовые библиотеки на поиск в данном проекте!
lair
23.06.2016 21:04И что?
И то, что можно воспользоваться опытом.
Я отказываюсь использовать готовые библиотеки на поиск в данном проекте!
Угу. Мне ваша фраза "использование готовых решений полностью отметается по причине того, что все крупные поисковики требуют соединения с интернетом" с самого начала казалась лукавством, а теперь вы это сомнение подтвердили.
kolyaflash
23.06.2016 23:28+1Тоже правильно. На собеседованиях любят такие истории про реализацию алгоритмов своими руками.

MagicWolf
23.06.2016 20:46А все-таки, как этот проект помешал поступлению в ВУЗ?
LionZXY
23.06.2016 21:17Убитое время. Вместо проекта мог бы его потратить на подготовку к ЕГЭ

kstep
23.06.2016 21:42+3ЕГЭ не готовит к реальной жизни, он готовит только для поступления в вуз. Такие проекты — готовят.
То, что хочется пионерить и писать решения самому в ущерб «best practices» — это нормально и правильно в вашем возрасте.
Понятно, что «старичок» просто бы настроил Elasticsearch, взял пару готовых библиотек, написал бы обвязку за пару вечеров,
и писать было бы не о чем. У меня при прочтении тоже возникло много вопросов из серии «чем не угодил эластик?», «почему авторизация своя?» и т. п. Но потом я посмотрел на возраст автора и заплюсовал статью. Да, код неказистый, да, состоит из велосипедов, но каков запал, какая целеустремлённость! Вы даже не поленились потрясти Абби по поводу проприетарной библиотеки, а это много стоит, на самом деле.
Все с чего-то начинали. И я более чем уверен, что практически все комментаторы, которые выше тыкали в недостатки проекта, далеко не родились такими умными, а когда-то тоже пионерили. Делать ошибки хорошо и правильно, на них учаться. Главное понимать и принимать,
когда тебе на ошибки указывают, а вы это делаете, так что готовы учиться. Это вызывает уважение, из вас выйдет хороший программист.
Я рад, что растёт такая смена. Вы вернули мне веру в человечество.
aliev
24.06.2016 10:06+1Повторюсь, но ИМХО PHP постоянно развивается скоро релиз PHP 7.1.
Поэтому вопрос, только без отмазок. По каким критерям вы решили что это старая технология и не тру, а руби тру?LionZXY
24.06.2016 15:49+1Это я опрометчиво такую фразу оставил :) Давайте не будем разжигать конфликт по этому поводу. Признаю свою вину в этом вопросе.
Beanut
Чем вам elasticsearch не подошел в качестве поисковика?
LionZXY
На самом деле просто не знал про него. Да и не сильно искал. Просто хотелось самостоятельно разобраться в этом вопросе.