
Кстати, одновременно с публикацией этой расшифровки начинается вторая встреча из серии, посвящённой технологиям Яндекса. Сегодняшнее мероприятие — уже не про поиск, а про инфраструктуру. Вот ссылка на трансляцию.
Ну а под катом — лекция Петра Попова и часть слайдов.
Меня зовут Пётр Попов, я работаю в Яндексе. Здесь я уже примерно семь лет. До этого программировал компьютерные игры, занимался 3D-графикой, знал про видеокарточки, писал на SSE-ассемблере, в общем, такими вещами занимался.
Надо сказать, что, устраиваясь на работу в Яндекс, я достаточно мало знал о предметной области — о том, что здесь люди делают. Знал только, что здесь работают хорошие люди. Поэтому испытывал некоторые сомнения.

Сейчас я расскажу достаточно полно, но не очень глубоко о том, как выглядит наш поиск. Что такое Яндекс? Это поисковик. Мы должны получить запрос пользователя и сформировать десятку результатов. Почему именно десятку? Пользователи чрезвычайно редко переходят на более далёкие страницы. Можно считать, что десять документов — это всё, что мы показываем.
Не знаю, есть ли в зале люди, которые занимаются рекламой Яндекса, потому что они считают, что основной продукт Яндекса — это совсем другое. Как обычно, здесь две точки зрения и обе правильные.
Мы считаем, что основное — это счастье пользователя. И, как ни удивительно, от состава десятки и того, как десятка отранжирована, это счастье зависит. Если мы ухудшаем выдачу, пользователи пользуются Яндексом меньше, уходят в другие поисковики, плохо себя чувствуют.

Какую конструкцию мы соорудили ради решения этой простой задачи — показать десять документов? Конструкция достаточно мощная, снизу, видимо, разработчики на неё взирают.
Наша модель работы. Нам нужно сделать всего несколько вещей. Нам нужно обойти интернет, проиндексировать получившиеся документы. Документом мы называем скачанную веб-страницу. Проиндексировать, сложить в поисковый индекс, запустить над этим индексом поисковую программу, ну и ответить пользователю. В общем-то, всё, профит.
Пройдемся по шагам этого конвейера. Что такое интернет и какого он объема? Интернет, считай, бесконечный. Возьмем любой сайт, который продает что-нибудь, какой-нибудь интернет-магазин, сменим там параметры сортировки — появится другая страничка. То есть можно задавать СGI-параметры страницы, и содержание будет совсем другое.
Сколько мы знаем принципиально значащих страниц с точностью до отбрасывания незначащих CGI-параметров? Сейчас — порядка нескольких триллионов. Скачиваем мы странички со скоростью порядка нескольких миллиардов страничек в день. И казалось бы, что нашу работу мы могли бы выполнить за конечное время, там, за два года.
Как мы вообще находим новые странички в интернете? Мы обошли какую-то страничку, вытянули оттуда ссылки. Они — наши потенциальные жертвы для скачивания. Возможно, за два года мы обойдем эти триллионы URL, но появятся новые, и в процессе парсинга документов появятся ссылки на новые странички. Уже тут видно, что наша основная задача — бороться с бесконечностью интернета, имея на руках конечные инженерные ресурсы в виде дата-центров.
Мы скачали все безумные триллионы документов, проиндексировали. Дальше нужно положить их в поисковый индекс. В индекс мы кладем не всё, а только лучшее из того, что скачали.

Есть товарищ Ашманов, широко известный в узких кругах специалист по поисковым системам в интернете. Он строит разные графики качества поисковых систем. Это график полноты поисковой базы. Как он строится? Задается запрос из редкого слова, смотрится, какие документы есть во всех поисковиках, это 100%. Каждый поисковик знает про какую-то долю. Сверху красным цветом мы, снизу черным цветом — наш основной конкурент.
Тут можно задаться вопросом: как мы такого достигли? Возможны несколько вариантов ответа. Вариант первый: мы пропарсили страничку с этими тестами, выдрали оттуда все URL, все запросы, которые задает товарищ Ашманов и проиндексировали странички. Нет, мы так не делали. Второй вариант: для нас Россия является основным рынком, а для конкурентов она — что-то маргинальное, где-то на периферии зрения. Этот ответ имеет право на жизнь, но он мне тоже не нравится.
Ответ, который мне нравится, заключается в том, что мы проделали большую инженерную работу, сделали проект, который называется «большая база», под это закупили много железа и сейчас наблюдаем этот результат. Конкурента тоже можно бить, он не железный.
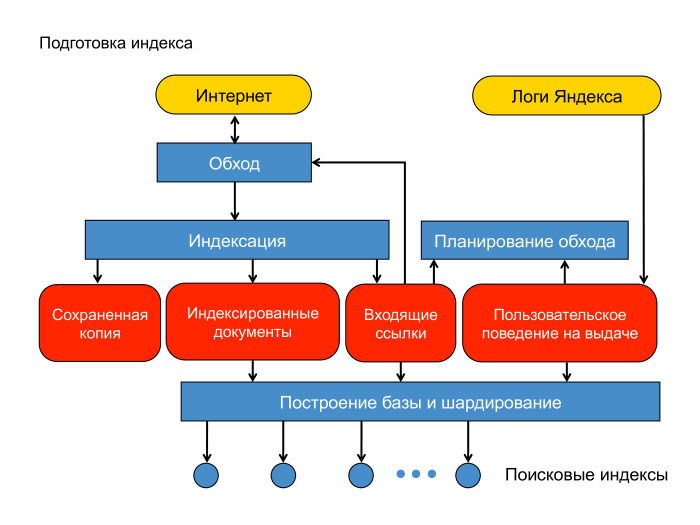
Документы мы скачали. Как мы строим поисковую базу? Вот схема нашей контент-системы. Есть интернет, облачко документов. Есть машины, которые его обходят — спайдеры, пауки. Документ мы скачали. Для начала — положили его в сохраненную копию. Это, фактически, отдельная междатацентровая хеш-таблица, куда можно читать и писать на случай, если мы потом захотим этот документ проиндексировать или показать пользователю как сохраненную копию на выдаче.
Дальше мы документ проиндексировали, определили язык и вытащили оттуда слова, приведенные согласно морфологии языка к основным формам. Ещё мы вытащили оттуда ссылки, ведущие на другие страницы.
Есть еще один источник данных, который мы широко используем при построении индекса и вообще в ранжировании — логи Яндекса. Задал пользователь запрос, получил десятку результатов и как-то там себя ведёт. Ему показались документы, он кликает или не кликает.
Разумно предположить, что если документ показался в выдаче, или, тем более, если пользователь по нему кликнул, провел какое-то взаимодействие, то такой документ нужно оставить в поисковой базе. Кроме того, логично предположить, что ссылки с такого хорошего документа ведут на документы, которые тоже хороши и которые неплохо бы приоритетно скачать. Здесь изображено планирование обхода. Стрелочка от планирования обхода должна вести в обход.
Дальше есть стадия построения поискового индекса. Эти округлые прямоугольнички лежат в MapReduce, нашей собственной реализации MapReduce, которая называется YT, Yandex Table. Тут я немножко лакирую — на самом деле построение базы и шардирование оперируют с индексами как с файлами. Мы это немножко зафиксим. Эти округлые прямоугольнички будут лежать в MapReduce. Суммарный объем данных здесь — порядка 50 ПБ. Тут они превращаются в поисковые индексы, в файлики.
В этой схеме есть проблемы. Основная связана с тем, что MapReduce — сугубо батчевая операция. Чтобы определить приоритетные документы для обхода, например, мы берем весь линковый граф, мёржим его со всем пользовательским поведением и формируем очередь для скачки. Это процесс достаточно латентный, занимающий какое-то время. Ровно так же с построением индекса. Там есть стадии обработки — они батчевые для всей базы. И выкладка так же устроена, мы или дельту выкладываем, или всё.
Важная задача при этих объемах — ускорить процедуру доставки индекса. Надо сказать, что эта задача для нас сложная. Речь идёт о борьбе с батчевым характером построения базы. У нас есть специальный быстрый контур, который качает всякие новости в real time, доносит до пользователя. Это наше направление работы, то, чем мы занимаемся.

А вот вторая сторона медали. Первая — контент-система, вторая — поиск. Можно понять, почему я рисовал пирамидку — потому что поиск Яндекса действительно похож на пирамиду, такую иерархическую структуру. Сверху стоят балансеры, фронты, которые генерируют выдачу. Чуть пониже — агрегирующие метапоиски, которые агрегируют выдачу с разных вертикалей. Надо сказать, что на выдаче вы наверняка видели веб-документы, видео и картинки. У нас три разных индекса, они опрашиваются независимо.
Каждый ваш поисковый запрос уходит по этой иерархии вниз и спускается до каждого кусочка поисковой базы. Мы весь индекс, который построили, разбили на тысячи кусков. Условно, — на две-три-пять тысяч. Над каждым куском подняли поиск, и этот запрос всюду спустился.

Тут же видно, что поиск Яндекса — большая штука. Почему она большая? Потому что мы в своей памяти храним, как вы видели на предыдущих слайдах, достаточно репрезентативный и мощный кусок интернета. Храним не один раз: в каждом дата-центре от двух до четырёх копий индекса. Запрос наш спускается до каждого поиска, фактически проходится по каждому индексу. Сейчас используемые структуры данных — такие, что мы вынуждены всё это хранить напрямую в оперативке.

Что нужно делать? Вместо дорогой оперативки использовать дешевый SSD, ускорить поиск, допустим, в два раза, и получить профит — десятки или сотни миллионов долларов капитальных расходов. Но тут не нужно говорить: кризис, Яндекс экономит и всё такое. На самом деле всё, что мы сэкономим, мы пустим в полезное дело. Мы увеличим индекс в два раза. Мы будем по нему качественнее искать. И это то, ради чего осуществляется такого рода сложная инженерка. Это реальный проект, правда, достаточно тяжелый и вялотекущий, но мы действительно так делаем, хотим поиск наш улучшить.
Поисковый кластер не только достаточно большой — он ещё и очень сложный. Там реально крутятся миллионы инстансов разных программ. Я вначале написал — сотни тысяч, но товарищи из эксплуатации меня поправили — таки миллионы. На каждой машинке в очень многих экземплярах 10-20 штук точно крутится.
У нас тысячи разных типов сервисов размазаны по кластеру. Надо пояснить: кластер — это такие машинки, хосты, на них запущены программы, все они общаются по TCP/IP. Программы имеют разное потребление CPU, памяти, жесткого диска, сети — короче, всех этих ресурсов. Программы живут на хостах в общежитии. Точнее, если будем сажать одну программу на хост, то утилизация кластера будет никакой. Поэтому мы вынуждены селить программы друг с другом.
Дальше слайд про то, что с этим делать. А здесь — небольшое замечание, что все данные программы, все релизы мы катаем с помощью торрентов, и число раздач на нашем торрент-трекере превышает оное число на Pirate Bay. Мы реально большие.
Что нужно делать со всей этой кластерной конструкцией? Нужно улучшать механизмы виртуализации. Мы реально вкладываемся в разработку ядра Linux, у нас есть собственная система управления контейнерами а-ля Docker, про неё Олег подробнее расскажет.
Нам нужно заранее планировать, на каких хостах какие программы друг с другом селить, это тоже сложная задача. У нас постоянно что-то на кластер едет. Сейчас там наверняка десять релизов катятся.
Нам нужно грамотно селить программы друг с другом, нужно улучшать виртуализацию, нужно-таки объединить два больших кластера — роботный и поисковый. Мы как-то независимо заказывали железо и считали, что есть отдельно машинки с огромным числом дисков и отдельно — тонкие блейды для поиска. Сейчас мы поняли, что лучше заказывать унифицированное железо и запускать MapReduce и поисковые программы в изоляции: одно жрет в основном диски и сеть, второе в основном CPU, но по CPU у них баланс, нужно туда-сюда крутить. Это большие инженерные проекты, которые мы тоже ведем.
Что мы с этого получаем? Пользу в десятки миллионов долларов экономии капитальных расходов. Вы уже знаете, как мы эти деньги потратим — мы потратим их на улучшение нашего поиска.
Здесь я рассказал о конструкции в целом. Какие-то отдельные строительные блоки. Эти блоки люди долбили стамеской, и у них что-то получилось.

Ранжирующая функция Матрикснет. Достаточно простая функция. Можете почитать — там лежат в векторе бинарные признаки документа, а в этом цикле происходит вычисление релевантности. Я уверен, что среди вас есть специалисты, которые умеют на SSE программировать, и они бы живо это ускорили в десять раз. Так оно в какой-то момент и случилось. Тысяча строчек кода нам спасли 10-15% общего потребления CPU на нашем кластере, что опять же составляет десятки миллионов долларов капитальных расходов, которые мы знаем, как потратить. Это тысяча строчек кода, которая стоят очень дорого.
Мы более-менее вычистили из репозитория, соптимизировали, но там ещё есть что поделать.
Имеется у нас платформа для машинного обучения. Индексы с предыдущего слайда нужно подбирать жадным образом, перебирая все возможности. На CPU это делать долго. На GPU — быстро, зато пулы для обучения не лезут в память. Что нужно делать? Или покупать кастомные решения, куда этих железок много-много втыкается, или связывать машинки быстрым, использовать интерконнект какой-то, infiniband, учиться с этим жить. Оно типично глючит, не работает. Это очень забавный инженерный вызов, с которым мы тоже встречаемся. Он, казалось бы, совсем не связа с нашей основной деятельностью, но тем не менее.

Во что мы ещё инвестируем, так это в алгоритмы сжатия данных. Основная задача сжатия выглядит примерно следующим образом: есть последовательность целых чисел, нужно её как-то компрессировать, но не просто компрессировать — нужно ещё иметь случайный доступ к i-тому элементу. Типичный алгоритм — маленькими блоками сжать это, иметь разметку для общего потока данных. Такая задача — совсем другая, нежели контекстное сжатие типа zip или LZ-family. Там совсем другие алгоритмы. Можно сжать Хаффманом, Varlnt, блоками типа PFORX. У нас есть собственный патентованный алгоритм, мы его улучшаем, и это опять же 10-15% экономии оперативной памяти на простенький алгоритм.
У нас есть всякие забавные мелочи, например доработки в CPU, планировщики Linux. Там какая проблема с гипертредными камнями от Intel? То, что на физическом ядре есть два потока. Когда там два треда занимают два потока, то они работают медленно, латенция увеличивается. Нужно правильно раскидывать задачки по физическим процессорам.
Если раскидывать правильно, а не так, как делает стоковый планировщик, можно получить 10-15% латентности нашего запроса, условно. Это то, что видят пользователи. Сэкономленные миллисекунды умножайте на число поисков — вот и сэкономленное время для пользователей.
У нас есть какие-то совсем странные вещи типа собственной реализации malloc, который на самом деле не работает. Он работает в аренах, и каждая локация просто сдвигает указатель внутри этой арены. Ну и ref counter арены поднимает на единичку. Арена жива, пока жива последняя локация. Для всякой смешанной нагрузки, когда у нас есть короткоживущая и долгоживущая локация, это не работает, это выглядит как утечка памяти. Но наши серверные программы устроены не так. Приходит запрос, мы там аллоцируем внутренние структуры, как-то работаем, потом отдаем ответ пользователю, всё сносится. Этот аллокатор идеально работает для наших серверных программ, которые без состояния. За счет того, что все локации локальны, последовательны в арене, оно работает очень быстро. Там нет никаких page fault, cache miss и т. п. Очень быстро — это от 5% до 25% скорости работы наших типичных серверных программ.
Это инженерка, что ещё можно делать? Можно заниматься машинным обучением. Про это вам с любовью расскажет Саша Сафронов.
А сейчас вопросы и ответы.
Я возьму очень понравившийся мне вопрос, который пришел на рассылку и который следовало бы включить в мою презентацию. Товарищ Анатолий Драпков спрашивает: есть знаменитый слайд про то, как быстро росла формула до внедрения Матрикснета. На самом деле и до, и после. Есть ли сейчас проблемы роста?
Проблемы роста у нас стоят в полный рост. Очередной порядок увеличения числа итераций в формуле ранжирования. Сейчас мы там порядка 200 тысяч итераций делаем в функции Матрикснет, чтобы ответить пользователю. Был получен следующим инженерным шагом. Раньше мы ранжировали на базовых. Это значит, что каждый базовый запускает у себя Матрикснет и выдает сто результатов. Мы сказали: давайте мы лучшие сто результатов объединим на среднем и отранжируем ещё раз совсем тяжелой формулой. Да, мы это сделали, на среднем можно вычислять в нескольких потоках функцию Матрикснет, потому что ресурсов нужно в тысячу раз меньше. Это проект, который нам позволил достичь очередного порядка увеличения объемов ранжирующей функции. Что будет ещё — не знаю.
Андрей Стыскин, руководитель управления поисковых продуктов Яндекса:
— Сколько занимала байт первая формула ранжирования Яндекса?
Пётр:
— Десяток, наверное.
Андрей:
— Ну, да, наверное, где-то символов сто. А сколько сейчас занимает формула ранжирования Яндекса?
Пётр:
— Где-то 100 МБ.
Андрей:
— Формула релевантности. Это для наших смотрителей с трансляций, специалистов по SEO. Попробуйте зареверсинженирить наши 100 МБ ранжирования.
Алеся Болгова, Intel:
— По последнему слайду про malloc не могли бы пояснить, как вы выделяете память? Очень интересно.
Пётр:
— Берется обычная страничка, 4 КБ, в начале у нее rev counter, и дальше мы каждую аллокацию… если маленькие аллокации меньше страницы, мы просто двигаемся в этой страничке. В каждом треде, естественно, эта страничка своя. Когда страничку закрыли — всё, про неё забыли. Единственное, у неё rev counter в начале.
Алеся:
— То есть вы страницу выделяете?
Пётр:
— Внутри страницы аллокациями вот так растем. Единственное, страничка живет, пока в ней последняя аллокация живет. Для обычного workload это выглядит как утечка, для нашего — как нормальная работа.
— Как вы определяете качество страницы, стоит её класть в индекс или нет? Тоже машинное обучение?
Пётр:
— Да, конечно. У странички есть множество факторов, от её размера до показов на поиске, до…
Андрей:
— До robot rank. Она находится на каком-то хосте, в какой-то поддиректории хоста, на неё сколько-то входящих ссылок. Те, кто на неё ссылаются, обладают каким-то качеством. Все это берем и пытаемся предсказать, с какой вероятностью, если данную страничку скачать, на ней будет информация, которая попадет по какому-то запросу в выдачу. Это предсказывается, отбирается топ с учетом размера документов — потому что в зависимости от размера документа вероятность, что она хоть по какому-то запросу попадет, повышается. Задача об оптимальном наполнении рюкзака. Отбирается с учетом размера документа и кладется топовая в индекс.
— …
Андрей:
— Давай мы тебя представим сначала.
— Может, не стоит?
Андрей:
— Владимир Гулин, начальник ранжирования поисковика Mail.Ru.
Владимир:
— Первый мой вопрос — про количество поисков вообще. Вы говорили, что вы там драматически увеличили размер базы. Хочется вообще понимать, с какого объема вы стартовали, каков был объем русского индекса, иностранного индекса, сколько документов приходилось на каждый шард, ну и после увеличения…
Пётр:
— Это такие цифры, слишком технические. Может, в кулуарах я бы сказал. Я могу сказать, во сколько раз мы примерно увеличились — на полтора порядка где-то. В 30 раз, условно. За последние три года.
Владимир:
— Я тогда абсолютные цифры в кулуарах уточню.
Пётр:
— Да, за отдельную плату, что называется.
Владимир:
— Ладно. Что касается свежести — какой приблизительно сейчас в Яндексе объем быстрого индекса? И вообще с какой скоростью вы это всё обновляете, смешиваете?
Пётр:
— Индекс реально реалтаймовый, там порядка двух минут латенции на то, чтобы добавить документ в индекс. От момента, как мы его проиндексировали, и дискавери тоже — скачка быстрая.
Владимир:
— Но именно найти документ. Сначала надо узнать, что документ существует.
Пётр:
— Я понимаю, что вопрос такой — непонятно, когда в интернете появилась первая ссылка на данный документ. Когда мы узнали первую ссылку, то дальше это вопрос минут в быстром слое.
Андрей:
— Речь идет о миллионах документов, которые ежедневно находятся в этом быстром индексе. Про них обычно очень много внешней информации: упоминание в Твиттере, сайтмэпы, упоминание новости на сайте Lenta.ru. И так как мы перекачиваем чуть ли не каждую секунду морду Lenta.ru, мы очень быстро обнаруживаем эти документы и в течение единиц минут в худшем случае доставляем их до поиска. Они могут искаться. По сравнению с большим индексом речь идет про драматически маленькое число документов, это миллионы.
Пётр:
— Да, на 3-4 порядка меньше.
Андрей:
— Да, это миллионы документов, которые умеют обновляться real time.
Владимир:
— Миллионы документов в сутки?
Пётр:
— Побольше чуть-чуть, но примерно так, да.
Владимир:
— Теперь вопрос про смешивание свежих результатов и результатов основного поиска.
Пётр:
— У нас два способа смешивания. Один — документ той же формулой ранжируется, что и батчевый обычный документ. А второй — специальное новостное подмешивание, когда мы определяем интент запроса, понимаем, что он реально свежий и что нужно что-то такое показать. Два способа.
Владимир:
— Как вы боретесь с ситуацией, когда у вас по популярным запросам, где дофига кликов, появляются свежие результаты? Как вы определяете, что свежий результат надо показывать выше того результата, который уже накликан? Спросили у вас: «Google». Вы вроде знаете, какие результаты по такому запросу хорошие. Но тем не менее, в новостях ещё что-то, какие-то статьи…
Пётр:
— Это всякие запросные факторы, всякие тренды и всё такое.
Андрей:
— Для всех поясню, в чем сложность задачи и в чем вопрос. Про документ, который долго существует в интернете, мы много чего знаем. Мы много знаем входящих на него ссылок, знаем, сколько на нем люди проводили времени, а про свежие документы этого всего не знаем. Поэтому сложность задачи ранжирования свежих документов и новостей — угадывать, будут ли люди это читать, уметь предсказывать количество ссылок, которые он наберет за какое-то время, чтобы его показывать нормально. И для подмешивания документов по запросу «Google», когда Google что-то хорошее сделал, там существует некая оптимизационная метрика, которая у нас называется профицит. Мы её умеем оптимизировать.
Пётр:
— Мы знаем поток запросов, содержание свежескачанных страниц. Эти две вещи мы можем анализировать и понимать, что реально свежий запрос требует подмешивания.
Андрей:
— А потом, на основе ручной оценки и пользовательского поведения именно в эту секунду в этот день, мы понимаем, что именно сегодня эта новость по запросу важна и у неё есть такие факторы: документ только появился, на него столько-то ретвитов. И поэтому следующую новость, которая будет с таким же распределением признаков, тоже нужно показывать, когда она наберет соответствующие значения.
Пётр:
—А факторы там могут быть такими: число найденного в обычном слое против числа найденного по этому запросу в свежем. Такие, самые наивные, хотя мы его выпиливаем тщательно.
Андрей:
— Для тех, кого пугает слово «факторы», специально будет третий доклад, где мы расскажем базовые принципы — как вообще устроено машинное обучение, ранжирование, что такое факторы, как с помощью этого сделать поисковик, который выдает нормальные хорошие результаты.
Владимир:
— Спасибо, остальное спрошу потом.
Никита Пустовойтов:
— Получается, у вас существует большое количество урлов, про которые вы в принципе знаете, а качать вы можете на несколько порядков меньше. Поскольку за время скачивания будут появляться новые, больше вы никогда не посетите. Для выбора применяется машинное обучение, какие-то эвристики?
Пётр:
—Только машинное обучение. Идея там простая: мы имеем сигнал на какой-то документ, любой, число показов, и его распространяем по ссылочному графу. Всё это агрегируем на странице «цель ссылки», дальше машинным обучением так же обучаем шанс показаться, исходя из этих данных.
Никита:
— Второй вопрос — инженерный. Вы говорили, что у вас много CPU-затратных задач. Рассматривали ли вы вариант использования процессора Xeon Phi от Intel? Он вроде гораздо быстрее работает с оперативной памятью, чем GPU.
Пётр:
— Мы его рассматривали для задач обучения именно нашего Матрикснета, нашей формулы, и там он феерично плохо себя показал. А так вообще у нас профиль очень плоский, у нас топовая функция где-то 1,5%. Мы всё, что можно, руками соптимизировали, а так у нас портянки С++-кода, который туда не ложится.
— Насколько я знаю, Яндекс был первым поисковиком, который начал работать с русской морфологией. Скажите, на данный момент это всё ещё является каким-либо преимуществом или все поисковики одинаково хорошо работают с русской морфологией?
Пётр:
— Сейчас в области морфологии наука не стоит на месте. Саша Сафронов расскажет о том, чего мы сейчас достигаем, там реально есть новые подходы и новые способы решения проблем. Например, определение запросов, похожих на этот, по пользовательскому поведению. Не расширение отдельных слов, а расширение запросов запросами.
Андрей:
— То есть это не совсем морфология. Морфологию действительно, наверное, все поисковики более-менее освоили, но это базовая вещь. А вот лингвистика, нахождение, чем и какие слова запроса можно расширить, какие ещё вещи стоит поискать в документе, чтобы найти кандидатов, которые будут более релевантные — про это будет третий доклад. Там наше ноу-хау, мы расскажем.
Пётр:
— По крайней мере, намекнем.
Андрей (зритель):
— Спасибо за краткий экскурс в столь сложную технологию, как поиск Яндекса. Использует ли Яндекс deep learning и алгоритмы обучения с подкреплением в построении быстрого индекса или кеша? Вообще если используете где-то, то как?
Пётр:
— Deep learning используем для того, чтобы факторы ранжирования обучать. Безотносительно к быстрому или медленному индексу. Он используется для картинок, веба и всего такого.
Андрей Стыскин:
— Летом запустили версию ранжирования, которая дала 0,5% прироста качества, где мы правильно сварили deep learning на словах. Приезжали наши бывшие коллеги из-за границы и рассказывали, что там такое не работает, а мы научились.
Пётр:
— А может, это потому, что мы для топ-100 документов это делаем. Речь идёт об очень затратной задаче. Наш способ построения пайплайна поиска позволяет для сотни документов это делать.
Андрей Стыскин:
— Невозможно посчитать deep learning для всех кандидатов, которых сотни миллионов на запросы, но для топа документов можно провернуть, и у нас эта схема поиска ровно так работает — позволяет такие очень сложные наукоемкие алгоритмы внедрять.
Игорь:
— Про будущее поисковика в целом. Интернет сейчас растет очень быстро, объем, наверное, растет экспоненциально. Уверены ли вы, что через 10 лет вы будете успевать за ростом интернета, и уверены ли, что будете охватывать его в таком же объеме? Повторите ещё раз, в каком объеме сейчас интернет охвачен по вашей оценке, и что будет через 10 лет?
Пётр:
— К сожалению, можно только процентно по отношению с кем-то степень охвата определять. Потому что он реально бесконечный.
Андрей:
— Это красивый философский вопрос. Пока мы в нашем коллективе за законом Мура успеваем, каждый год кратно увеличиваем наш размер базы. Но это правда сложно, правда интересно, и, конечно же, нам даже не хватает рук, чтобы это делать, но мы хотим и знаем, как это увеличивать в ближайшие несколько лет некоторыми сериями улучшений.
Пётр:
— 10 лет — слишком далеко, но ближайшие годы да, осилим.
Андрей (зритель):
— Сколько весит реплика интернета, как она разносится между ДЦ, и как осуществляется синхронизация реплик?
Пётр:
— Полный объем роботных данных — порядка 50 ПБ, реплика меньше, индекс меньше. Можете умножить на коэффициент, который вам кажется разумным. Вы же инженер, прикиньте.
Андрей:
— А как разносится?
Пётр:
— Разносится банально — через torrent, torrent share. Потом качаем этот файлик.
Андрей:
— То есть в какой-то момент времени они не консистентны?
Пётр:
— Нет, там потом консистентные переключения. Бывает, что переключаем по ДЦ, когда ночью оно вдруг не консистентно.
Андрей:
— То есть можно через F5 — если нажимаем, один документ имеем…
Пётр:
— Мы боремся с этой проблемой, знаем о ней, ее решение стоит в наших планах.
Иван:
— Как вы боретесь с различными бот-системами и за что можно отправиться в бан?
Пётр:
— У нас есть специальные люди, которые знают ответ на этот вопрос, но они не скажут.
Андрей Стыскин:
— На сегодняшнем мероприятии мы хотели поговорить про технические детали.
Пётр:
— Про роботоловилку мы можем ответить. Нас действительно регулярно ддосят, поэтому у нас прямо на балансере, на первом слое, когда запрос попадает, есть детекция, что запрос из какой-то сети пришел негодной. Это быстро обновляется, мы быстро реджектим, оно не валит наш кластер.
Андрей:
— И это тоже устроено методом машинного обучения. Показывается капча, и в зависимости от того, как ты её разгадываешь, мы получаем положительные и отрицательные примеры. На каких-то факторах — типа айпишника подсетки, какого-то поведения, времени между действиями — обучаем и баним или не баним такие запросы. DDoS не пройдет.
Андрей Аксёнов, Sphinx Search:
— У меня технические вопросы. Проходной вопрос — почему память? Неужели даже децл подисковать на SSD не получается, чтобы индекс чуть-чуть не влезал, изредка упирался в SSD?
Пётр
— Там получается так, что футпринт одного запроса порядка 50-100 МБ, он прямо жесткий. С такой скоростью ты не сможешь сервить тысячу запросов в секунду, как мы хотим. Мы работаем над тем, чтобы этот футпринт уменьшить. Проблема, что данные про документ рассыпаны по всему диску. Мы хотим их собрать в одно место, и тогда наша общая мечта осуществится.
Андрей Аксёнов:
— Упирается в bandwidth или latency?
Пётр:
— В оба. Мы и последовательно пейджфолдимся, и объемы большие.
Андрей Аксёнов:
— То есть невероятно, но факт: даже если чуть-чуть…
Пётр:
— Да, даже если чуть-чуть отожрешь — всё.
Андрей Аксёнов:
— Экспоненциальное падение во много раз?
Пётр:
— Да-да.
Андрей Аксёнов:
— Теперь важнейший вопрос для промышленного хозяйства: сколько классов строка и классов векторов в базе?
Пётр:
— А вот всё меньше и меньше.
Андрей Аксёнов:
— Ну конкретнее.
Пётр:
— У нас пришли правильные люди, они насаждают правильные порядки. Сейчас это число уменьшается.
Андрей Аксёнов:
— Векторов-то сколько и строк?
Пётр:
— Сейчас векторов, наверное, даже один-два максимум.
Андрей Аксёнов:
— Один не бывает, два хоть…
Пётр:
— Ну вот видишь.
Андрей Аксёнов:
— А строк?
Пётр:
— Ну должен же быть корпоративный какой-то дух Яндекса.
Андрей Аксёнов:
— Скажи, не томи, ну.
Пётр:
— Строк две минимум. Ну три, может.
Андрей Аксёнов:
— Не пять?
Пётр:
— Не пять.
Андрей Аксёнов:
— Налицо прогресс, спасибо.
Фёдор:
— Про вашу схему с метапоисками. У вас очень высокий каскад. Какие тайминги на каждом уровне, можете озвучить?
Пётр Попов:
— Прямо сейчас вставляем ещё один слой, не хватает. Времена ответов… Средний метапоиск делает три раунда хождений туда-сюда, у него порядка 250 мс, 95-я квантиль. Дальше построение выдачи не очень быстрое, но вся конструкция где-то за 700 мс отрабатывает.
Андрей Стыскин:
— Да, там выше JavaScript, так что это 250 мс, а там 700.
Пётр:
— То, что снизу, оно делает кучу раундов. У нас тоже специалисты заняты прямо сейчас решением этой проблемы.
Фёдор:
— У вас нарисовано три группы вертикалей. Но у вас есть ещё Афиша, Новости и так далее. Где вы их замешиваете в итоге?
Пётр:
— В построении выдачи у нас есть такой блендер, который объединяет все эти вертикали, по пользовательскому поведению решает, кого показать. Это как раз построение выдачи.
Андрей:
— Вертикалей порядка сотни, это слой, который называется верхним метапоиском. В нём сливаются результаты средних метапоисков из вертикали веба, Картинок, Видео и ряда других, а также из маленьких базовых источников типа Афиши, Расписаний, ТВ и Электричек.
Пётр:
— Это к вопросу о том, почему у нас тысячи разных типов программ. Там очень много всяких источников, оно набегает.
Фёдор:
— Раз у вас так много вертикалей, есть ли среди них сторонние, которые не вы считаете?
Пётр:
— Особо нет. Реклама наша тоже вертикальная, отдельно от поиска, но стороннего особо нет.
Артём:
— У вашего основного конкурента выдача всегда была real time, он дельта-индексами докидывал. А у Яндекс был up выдачи. Складывалось впечатление, что темной ночью раз в семь дней человек нажимает рычаг и раскатывает индексы.
Пётр:
— К сожалению, так и происходит.
Артём:
— Правильно понимаю, что быстрый индекс был сделан для того, чтобы актуализировать выдачу real time?
Пётр:
— Да, но решение общее. Многие так реально делают, в том числе и наш основной конкурент.
Артём:
— Стремитесь ли вы к тому, чтобы тоже дельта-индексами подкидывать, просто отказаться от быстрого индекса?
Пётр:
— Естественно, стремимся. Ещё бы знать, как.
Артём:
— Когда это можно ожидать?
Пётр:
— Хороший вопрос. На тех же графиках Ашманова видно, как мы обновляем индекс. Сейчас это видно меньше, и мы делаем так, чтобы это проходило совсем быстро и незаметно. Такова одна из наших задач.
Артём:
— Вы каждый раз обрабатываете запрос пользователя? Приходит запрос, вы отсылаете его на бэкенд, рассчитывается формула и результат?
Пётр:
— Есть кеши, но они работают в 50% случаев. 40-50% запросов пользователей — уникальные и никогда больше не будут заданы. Очень много по-настоящему уникальных запросов пользователей вообще за всю жизнь Яндекса. Кешируем 50-60%. Для кеширования тоже своя система.
Комментарии (5)

u007
16.10.2016 00:21+1А что за «классы в строке» и «вектора в базе», которых каждую пятилетку всё меньше и меньше? Какие-то мерялки качества кода?

ReanGD
17.10.2016 14:25+1Насколько я помню, там речь о количестве собственных реализаций классов строк и векторов.
JediPhilosopher
17.10.2016 23:45+1Думаю что это про типичную болезнь С++, где каждый городит свои велосипеды из-за убожества стандартных классов.
У меня рекорд был 4 разных класса строки в одном из проектов. Это был плагин для Maya кажется, который много лет писался и переписывался, в итоге там использовался std::string, стринг нашего собственного 3д движка, для которого плагин данные экспортировал, стринг из SDK самой Maya, и стринг от оригинальных авторов плагина. Перекладывать из одного в другой было тем еще цирком.

shurupkirov
17.10.2016 08:12+1что все-таки напрягает в поиске яндекса, так это излишняя привязка рейта к региону нахождения сайта.
Региональным интернет-магазинам тяжело работать на другие регионы России, если нет физических точек выдачи товаров, а физическая точка выдачи — это минимальные затраты в 50-100к рублей в месяц на один регион.
И контент здесь никак не помогает.
Хорошо только тем, кто когда-то давно купил ссылок и сидит в топе, из которого Яндекс их никуда не выкинет.
Так что текущая ситуация с поиском Яндекса далека от идеала.
FForth
Как интересно работает поиск с цитируемой (не с оригинального источника) информацией?
Поясню:
Цитируя какую то информацию не относящуюся прямо (зачастую) к основному наполнению ресурса —
таким способом повышают поисковый рейтинг странички.
P.S. Попробовал и поисковик по картинкам от mail при чётко заданном контексте поиска текстовой информации
и получил достаточно не релевантный результат.