
В первой (достаточно капитанской) части этой серии мы рассказали про базовые концепции MapReduce почему это плохо, почему это неизбежно, и как с этим жить в других средах разработки (если вы не про Си++ или Java). Во второй части мы-таки начали рассказывать про базовые классы реализации MapReduce на Cache ObjectScript, введя абстрактные интерфейсы и их первичные реализации.
Сегодня пришел наш день! – мы покажем первый пример собранный в парадигме MapReduce, да, он будет странный и не самый эффективный, и совсем не распределенный, но вполне MapReduce.
WordCount – простая, последовательная реализация
Вы уже, наверное, заметили что MapReduce – это про параллелизм и масштабирование. Но давайте признаемся сразу – алгоритм, какой бы элегантный и простой он ни был бы, очень сложно отлаживать сразу в его в параллельной инкарнации. Обычно, для простоты, мы стартуем с последовательной версии (в нашем случае это будет алгоритм wordcount) и затем подмешаем немного параллелизма.
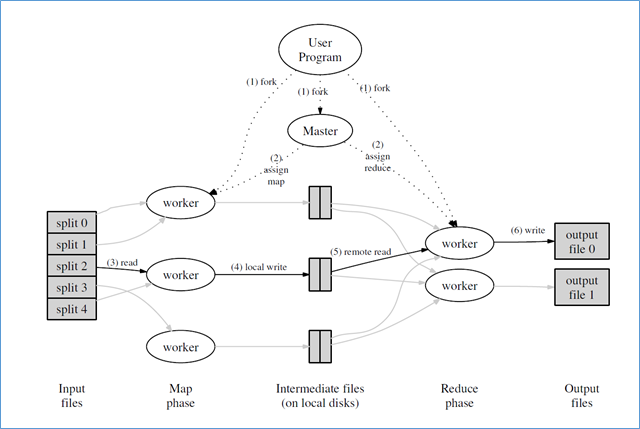
Исполнение в среде MapReduce из статьи "MapReduce: Simplified Data Processing on Large Clusters", OSDI-2004
Напомним суть задачки wordcount: у нас есть набор текстов (например, все тома «Войны и мир») и вам нужно подсчитать количество слов во всем массиве. Этот простой пример использовался в оригинальной статье Google про MapReduce, потому каждый следующий, рассказывающий про MapReduce использует тот же самый пример. Считайте это "HelloWorld!" параллельного исполнения.
Итак, последовательная реализация WordCount (но с применением MapReduce интерфейсов, введенных ранее) будет содержать все те же самые части, что и параллельная. И, например, mapper будет выглядеть примерно так:
Class MR.Sample.WordCount.Mapper Extends (%RegisteredObject, MR.Base.Mapper)
{
/// read strings from MR.Base.Iterator and count words
Method Map(MapInput As MR.Base.Iterator, MapOutput As MR.Base.Emitter)
{
while 'MapInput.IsAtEnd() {
#dim line As %String = MapInput.GetNext()
#dim pattern As %Regex.Matcher = ##class(%Regex.Matcher).%New("[^\s]+")
set pattern.Text = line
while pattern.Locate() {
#dim word As %String = pattern.Group
do MapOutput.Emit(word)
}
}
}
}Подпрограмма Map получает «входной поток» через параметр MapInput, и эмиттит данные в выходной MapOutput. Алгоритм тут очевиден – если во входном потоке еще остались данные (т.е. НЕ MapInput.IsAtEnd() ), то он прочтет следующую «строку» через MapInput.GetNext(), разобьет строку на слова при помощи %Regex.Matcher (смотри хорошую вводную статью про использование регулярных выражений в Cache на портале сообщества «Using Regular Expressions in Cache») и каждое выделенное слово пересылается в выходной эмиттер.
В классическом MapReduce интерфейсе мы всегда эмиттим «ключ, значение», в данном случае мы сделали упрощение для случая «ключ, 1», используя форму с 1 аргументом. Объяснение дано в предыдущей части
Процедура свертки (reducer) еще проще:
Class MR.Sample.WordCount.Adder Extends (%RegisteredObject, MR.Base.Reducer)
{
Method Reduce(ReduceInput As MR.Base.Iterator, ReduceOutput As MR.Base.Emitter)
{
#dim result As %Numeric = 0
while 'ReduceInput.IsAtEnd() {
#dim value As %String = ReduceInput.GetNext() ; get <key,value> in $listbuild format
#dim word As %String = $li(value,1)
#dim count As %Integer = +$li(value,2)
set result = result + count
}
do ReduceOutput.Emit("Count", result)
}
}Пока не встретили конца потока ('ReduceInput.IsAtEnd()) тот продолжает потреблять данные из потока ReduceInput, и на каждой итерации из потока вынимается пара «ключ-значение» в бинарном формате списка $listbuild<> (т.е. в виде $lb(word,count)).
Данная функция агрегирует число слов в переменную result и эмитит её итоговое значение н следующую стадию конвейера через поток ReduceOutput.
Итак, мы показали mapper и reducer, пришла очередь показать главную, управляющую часть программы. Не рискуя сразу упереться в сложность параллелизма, мы заходим с последовательной версии алгоритма, хотя и использующую MapReduce идиому и интерфейсы. Да, в последовательном режиме, все эти отжимания с конвейером, не имеют большого смысла, но … упрощение необходимо в педагогических целях.
/// Упрощенная, одно-поточная версия примера "map-reduce".
/Class MR.Sample.WordCount.App Extends %RegisteredObject
{
ClassMethod MapReduce() [ ProcedureBlock = 0 ]
{
new
//kill ^mtemp.Map,^mtemp.Reduce
#dim infraPipe As MR.Sample.GlobalPipe = ##class(MR.Sample.GlobalPipe).%New($name(^mtemp.Map($J)))
for i=1:1 {
#dim fileName As %String = $piece($Text(DATA+i),";",3)
quit:fileName=""
// map
#dim inputFile As MR.Input.FileLines = ##class(MR.Input.FileLines).%New(FileName)
#dim mapper As MR.Sample.WordCount.Mapper = ##class(MR.Sample.WordCount.Mapper).%New()
do mapper.Map(inputFile, infraPipe)
// reduce
#dim outPipe As MR.Base.Emitter = ##class(MR.Emitter.Sorted).%New($name(^mtemp.Reduce($J)))
#dim reducer As MR.Sample.WordCount.Adder = ##class(MR.Sample.WordCount.Adder).%New()
while 'infraPipe.IsAtEnd() {
do reducer.Reduce(infraPipe, outPipe)
}
do outPipe.Dump()
}
quit
DATA
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol1.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol2.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol3.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol4.txt
;;
}
}Попытаемся объяснить этот код строчка за строчкой:
В обычном случае мы такого не рекомендуем делать, но в данном случае это необходимо: мы выключаем процедурные блоки ProcedureBlock = 0 и возвращаемся к старой семантике с ручным управлением содержимым таблицы символов с локальными переменными. Нам это нужно для встраивания блока DATA содержащего входные данные (в данном случае пути до входных файлов), к которым мы будем обращаться через функцию
$TEXT. В данном случае мы используем 4 тома «Войны и мира» Льва Толстого;
Мы будем использовать для промежуточного хранения данных между стадиями конвейера глобалы вида
^mtemp.Map($J)и^mtemp.Reduce($J). По волшебному стечению обстоятельств, глобалы вида^mtemp*и^CacheTemp*автоматически отображаются во временную базу CACHETEMP не будут журналироваться и будут поддерживаться в памяти (насколько это возможно). Будем рассматривать их как "in-memory" глобалы.
- Промежуточный канал intraPipe является экземпляром
MR.Sample.GlobalPipe, который в нашем случае – просто синоним классаMR.EmitterSorted, и как мы описали в предыдущей части автоматически очищается в конце работы программы.
Class MR.Sample.GlobalPipe Extends (%RegisteredObject, MR.Emitter.Sorted) { }Мы проходим по строкам
$TEXT(DATA+i), вытаскиваем 3ий аргумент строки, разделенной ";". Если результат непустой – то мы используем это значение как имя входного файла.
- Входной итератор «маппера» (объекта отображения) будем экземпляром MR.Input.FileLines, который мы еще не показывали...
Class MR.Input.FileLines Extends (%RegisteredObject, MR.Base.Iterator)
{
Property File As %Stream.FileCharacter;
Method %OnNew(FileName As %String) As %Status
{
set ..File = ##class(%Stream.FileCharacter).%New()
#dim sc As %Status = ..File.LinkToFile(FileName)
quit sc
}
Method GetNext() As %String
{
if $isobject(..File) && '..File.AtEnd {
quit ..File.ReadLine()
}
quit ""
}
Method IsAtEnd() As %Boolean
{
quit '$isobject(..File) || ..File.AtEnd
}
}Вернемся обратно к приложению MR.Sample.WordCount.App:
Объект «маппер» будет экземпляром уже известного
MR.Sample.WordCount.Mapper(см. выше). Экземпляр создается отдельно для каждого обрабатываемого файла.
В цикле мы последовательно вызываем функцию Map маппера, передавая экземпляр входного потока, работающего с открытым файлом. В этом конкретном случае стадия отображения линеаризуется в последовательном цикле. Что не очень типично для MapReduce но нужно в качестве упрощенного упражнения.
На стадии свертки мы получаем: выходной объект эмиттера (
outPipe) как экземплярMR.Emitter.Sorted, который указывает на^mtemp.Reduce($J). Напоминаю, что спецификойMR.Emitter.Sortedбудет использование реализации B*-Tree в движке Cache для различных оптимизаций. Ключи-значения хранятся в персистентном хранилище естественным образом отсортированными, и потому становятся возможными реализации свертки с автоинкрементом выходных значений.
Объект свертки является экземпляром
MR.Sample.WordCount.Adderописанного выше.
- Для каждого открытого файла, и на той же итерации цикла, мы вызываем
reducer.Reduce, передавая туда как промежуточный потокinfraPipe, так и выходной поток.
Вроде бы все части в сборе – давайте посмотрим как это все работает.
DEVLATEST:MAPREDUCE:23:53:27:.000203>do ##class(MR.Sample.WordCount.App).MapReduce()
^mtemp.Reduce(3276,"Count")=114830
^mtemp.Reduce(3276,"Count")=123232
^mtemp.Reduce(3276,"Count")=130276
^mtemp.Reduce(3276,"Count")=109344Здесь мы видим вычисленное число слов в каждом томе книги, которое выводится в конце каждой итерации цикла. Это все хорошо, но остаются 2 вопроса, на которые мы не получили ответ:
- Какое общее число слов во всех томах?
- И уверены ли мы, что выданные числа корректны? Что, кстати, не начальном этапе написания программ является более важным.
Начнем с ответа на второй вопрос, с верификации результата – проверить это просто, запустив Linux/Unix/Cygwin утилиту wc на тех же самих данных:
Timur@TimurYoga2P /cygdrive/c/Users/Timur/Documents/mapreduce/data
$ wc -w war*.txt
114830 war_and_peace_vol1.txt
123232 war_and_peace_vol2.txt
130276 war_and_peace_vol3.txt
109344 war_and_peace_vol4.txt
477682 totalВидим, что вычисленное число слов для каждого тома было правильным, т.ч. перейдем к вычислению финального, агрегатного значения.
Измененный вариант – с подсчетом общей суммы
Для подсчета финальной суммы нам надо внести 2 простых изменений в код программы показанный выше:
Нужно применить метод рефакторинга "Extract Method" на части кода маппера. В дальнейшем нам эта часть кода понадобится отдельно, в виде метода класса, что, в итоге, упростит дальнейшие модификации с параллелизацией или даже удаленным исполнением кода.
- Также, нам нужно вынести инстанцирование объектов reducer и вызов его функции Reduce из цикла вовне. Цель такой модификации – не удалять промежуточный канал с данными в конце каждой итерации, и продолжать аккумулировать данные между итерациями, для показа общей суммы после цикла. Агрегатная сумма будет подсчитываться автоматически, т.к. мы применим автоинкрементный вариант.
Во всех остальных случаях эти два приводимых примера ведут себя идентично – оба используют временные глобалы ^mtemp.Map($J) и ^mtemp.Reduce($J) в качестве промежуточного и финального хранилища на стадиях отображения и свертки.
Class MR.Sample.WordCount.AppSum Extends %RegisteredObject
{
ClassMethod Map(FileName As %String, infraPipe As MR.Sample.GlobalPipe)
{
#dim inputFile As MR.Input.FileLines = ##class(MR.Input.FileLines).%New(FileName)
#dim mapper As MR.Sample.WordCount.Mapper = ##class(MR.Sample.WordCount.Mapper).%New()
do mapper.Map(inputFile, infraPipe)
}
ClassMethod MapReduce() [ ProcedureBlock = 0 ]
{
new
#dim infraPipe As MR.Sample.GlobalPipe = ##class(MR.Sample.GlobalPipe).%New($name(^mtemp.Map($J)))
#dim outPipe As MR.Base.Emitter = ##class(MR.Emitter.Sorted).%New($name(^mtemp.Reduce($J)))
#dim reducer As MR.Sample.WordCount.Adder = ##class(MR.Sample.WordCount.Adder).%New()
for i=1:1 {
#dim fileName As %String = $piece($Text(DATA+i),";",3)
quit:fileName=""
do ..Map(fileName, infraPipe)
//do infraPipe.Dump()
}
while 'infraPipe.IsAtEnd() {
do reducer.Reduce(infraPipe, outPipe)
}
do outPipe.Dump()
quit
DATA
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol1.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol2.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol3.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol4.txt
;;
}
}Параллельная реализация
Давайте сразу признаемся себе – такие отжимания с MapReduce интерфейсами при создании простого алгоритма для подсчета слов не были самым простым, очевидным и естественным подходом при разработке такой тривиальной программы. Но потенциальные «плюшки», которые мы можем получить здесь все же перевешивают все начальные проблемы и дополнительную боль. При разумном планировании параллелизма и с применением соответствующих алгоритмов, мы можем получить масштабирование, которое сложно получить на последовательных алгоритмах. Например, в данном случае, на простом low-power Haswell ULT ноутбуке, на котором пишется данная статья, последовательный алгоритм отрабатывал за 4.5 секунды, тогда как параллельная версия завершалась за 2.6 секунды.
Разница не такая драматическая, но достаточно существенная, особенно принимая во внимание малый входной набор и всего два ядра на ноутбуке.
Вернемся к коду – на предыдущем этапе мы, на стадии отображения, выделили функцию в отдельный метод класса, получающий два аргумента (имя входного файла и имя выходного глобала). Мы выделили данный код в отдельную функция с одной простой целью – облегчить создание параллельной версии. Такая параллельная версия будет использовать механизм worker в Cache ObjectScript ($system.WorkMgr) Ниже мы преобразуем последовательную версию, созданную на предыдущем шаге, в параллельную посредством вызова программ обработчиков (worker), запускаемых с выделенным методом класса.
/// Версия #2 Более продвинутая, использующая несколько воркеров
Class MR.Sample.WordCount.AppWorkers Extends %RegisteredObject
{
ClassMethod Map(FileName As %String, InfraPipeName As %String) As %Status
{
#dim inputFile As MR.Input.FileLines = ##class(MR.Input.FileLines).%New(FileName)
#dim mapper As MR.Sample.WordCount.Mapper = ##class(MR.Sample.WordCount.Mapper).%New()
#dim infraPipe As MR.Sample.GlobalPipeClone = ##class(MR.Sample.GlobalPipeClone).%New(InfraPipeName)
do mapper.Map(inputFile, infraPipe)
quit $$$OK
}
ClassMethod MapReduce() [ ProcedureBlock = 0 ]
{
new
#dim infraPipe As MR.Sample.GlobalPipe = ##class(MR.Sample.GlobalPipe).%New($name(^mtemp.Map($J)))
#dim outPipe As MR.Base.Emitter = ##class(MR.Emitter.Sorted).%New($name(^mtemp.Reduce($J)))
#dim reducer As MR.Sample.WordCount.Adder = ##class(MR.Sample.WordCount.Adder).%New()
#dim sc As %Status = $$$OK
// do $system.WorkMgr.StopWorkers()
#dim queue As %SYSTEM.WorkMgr = $system.WorkMgr.Initialize("/multicompile=1", .sc)
quit:$$$ISERR(sc)
for i=1:1 {
#dim fileName As %String = $piece($Text(DATA+i),";",3)
quit:fileName=""
//do ..Map(fileName, infraPipe)
set sc = queue.Queue("##class(MR.Sample.WordCount.AppWorkers).Map", fileName, infraPipe.GlobalName)
quit:$$$ISERR(sc)
}
set sc = queue.WaitForComplete() quit:$$$ISERR(sc)
while 'infraPipe.IsAtEnd() {
do reducer.Reduce(infraPipe, outPipe)
}
do outPipe.Dump()
quit
DATA
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol1.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol2.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol3.txt
;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol4.txt
;;
}Ранее пример назывался AppSum, Новый пример нзывается AppWorkers, и разница между ними очень маленькая, но важная – мы вызываем процедуру отображения в отдельном треде (процессе) обработчике посредством $system.WorkMgr.Queue API. Это API может вызывать простую подпрограмму, или метод класса, но (по естественным причнима) не может вызывать методы объекта, т.к. не предусмотрен механизм передачи объекта во внешний процесс.
При вызове параллельного обработчика через это API накладываются дополнительные ограничения и на типы передаваемых значений:
- Мы не можем передавать значения по ссылке и, как следствие, не можем возвращать измененные значения таких аргументов;
- Более того, мы можем передавать только простые скалярные значения (числа и строки), но не объекты.
Но тут, дорогой Хьюстон, у нас проблема. В предыдущем примере метод MR.Sample.WordCount.AppSum::Map получал в качестве 2го аргумента экземпляр класса MR.Sample.GlobalPipe. Но мы не можем передавать объекты между процессами (а worker – это отдельный процесс из пула процессов). И в данном случае, нам нужно придумать простую схему «сериализации»/«десериализации» объекта в литеральные значения, для того чтобы это можно было передать в параллельный обработчик через $system.WorkMgr.Queue API.
В случае сGlobalPipe"простой метод сериализации" – действительно получается простым. Если передать имя промежуточного глобала то этого достаточно для адекватной передачи состояния нашего объекта. Вот почему вторым аргументом методаMR.SampleWordCount.AppWorkers::Mapстановится строка с именем глобала, а не объект.
Рекомендуем прочитать документацию по параллельным обработчикам здесь, но на будущее запомните, что если вы хотите использовать параллельные обработчики (в максимальном количестве, которое позволительно при вашем железе и лицензии) то при инициализации обработчиков вам стоит передать параметр со странным именем "/multicompile=1". [Странное имя объясняется тем, что эта функциональность была добавлена для параллельной компиляции в трансляторе классов Cache ObjectScript. С тех пор этот модификатор стал использоваться и вне кода транслятора.]
Как только мы запланировали исполнение метода через $system.WorkMgr.Queue, мы можем запустить все запланированные подпрограммы и дождаться их завершения через $system.WorkMgr.WaitForComplete.
Все параллельные обработчики будут использовать один и тот же промежуточный глобал infraPipe для передачи данных между стадиями конвейера, но коллизий с данными не стоит ожидать, т.к. нижележащий движок данных отработает их корректно. Напомним, что архитектура Cache изначально многопроцессная, с множеством масштабируемых механизмов синхронизации между процессами, работающими с одними и теми же данными. Дополнительно заметим, что наш упрощенный пример с вычислением общего числа слов во всех томах исполняет свертку (reducer) в одном потоке, что также упрощает код и избавляет нас от некоторой головной боли.
Таким образом, на текущий момент мы успели рассказать об общих терминах алгоритмов MapReduce, создали базовые интерфейсы MapReduce при реализации их в контексте среды Cache ObjectScript, и создали в этой же среде простой пример с подсчетом слов. В следующей статье мы покажем другие используемые в нашей реализации идиомы, используя второй классический пример из WikiPedia – AgeAverage. Всё только начинается!