
Английская версия этой записи — на GitHub.
Итак, 9 из присланных решений оказались самообучающимися. Идея самообучения такова: поскольку все слова выбираются из конечного словаря, а не-слова генерируются случайно, то всякая строка, которая была представлена тестируемой программе повторно, с большей вероятностью окажется словом, чем не-словом. При достаточно продолжительном тестировании большинство слов из словаря успеют повториться, тогда как для не-слов случайные повторения встречаются гораздо реже.
Чтобы пронаблюдать поведение самообучающихся решений, мы протестировали их на 1 000 000 блоков. Тестировать на таком количестве блоков все решения было бы нереально, но эти девять оказались достаточно быстрыми.
На графике ниже показана зависимость процента правильных ответов от числа обработанных блоков. Обратите внимание, что горизонтальная шкала — логарифмическая.
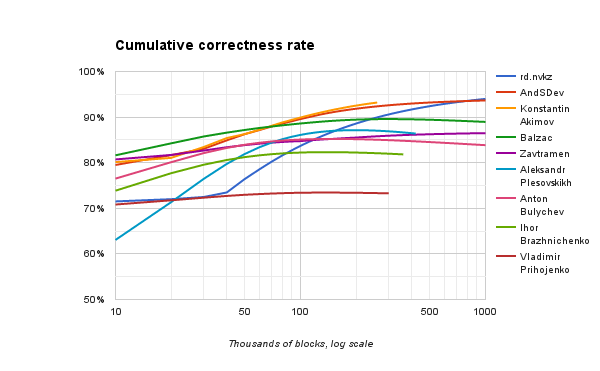
Некоторым решениям при тестировании на очень большом числе блоков не хватило памяти, поэтому их линии прерываются, не дойдя до отметки в миллион блоков.
На следующем графике показан не накопительный процент правильных ответов (средний за всё время работы), а только за последние 10 000 блоков в каждой точке. Здесь лучше видно, как решение ведёт себя после определённого объёма обучения.
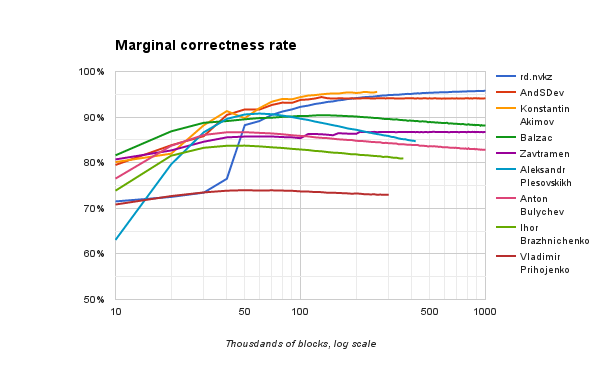
Ниже — графики частоты ложноотрицательных и ложноположительных результатов, соответственно. Здесь тоже учитывается поведение на последних 10 000 блоках, а не накопительное от начала работы.

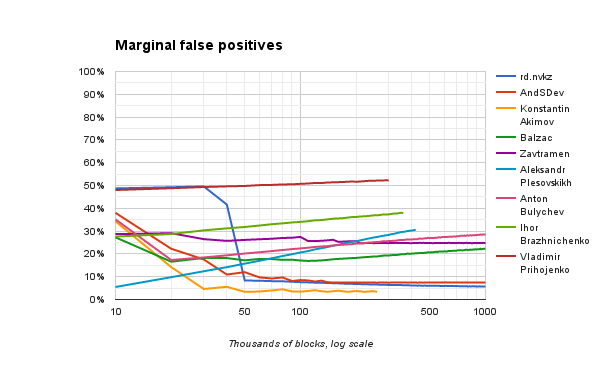
Обратите внимание, что результаты у некоторых решений при продолжительном обучении начинают несколько ухудшаться. Очевидно, это происходит из-за того, что некоторые не-слова тоже случайно повторяются, и алгоритм принимает их за слова. На последнем графике видно, что растут именно ложноположительные результаты.
На специальной странице на GitHub можно найти подробные результаты исследования на 1 000 000 блоков.
На основании проведённого исследования мы решили наградить специальными призами по 400 USD участников под псевдонимами rd.nvkz и AndSDev. Их решения достигли высочайших показателей — 93.99% и 93.65% соответственно. Кроме того, их поведение не ухудшается при продолжительном обучении, а у первого из них — даже продолжает улучшаться. Наши поздравления!
Следите за блогом компании Hola! Будут новые конкурсы.
Комментарии (13)

vintage
20.10.2016 18:55Было бы интересней увидеть анализ решений без этого чита.

feldgendler
21.10.2016 09:36Вы имеете в виду, каким получился бы общий зачёт, если бы у решений вообще не было возможности обучаться? Посмотрите на английскую страницу на GitHub, там есть такая информация.
vintage
21.10.2016 10:04Да, если бы тестирование проводилось правильно, с равными размерами словарей слов и не слов. А что ж не перевели?
feldgendler
21.10.2016 23:37Решений, результат которых зависит от возможности обучаться, всего 9. Здесь на GitHub приведена таблица, в которой показано, какие места они заняли бы без обучения.
https://github.com/hola/challenge_word_classifier/blob/master/blog/06-learning-solutions.md#baseline-correctnessvintage
22.10.2016 00:51А почему только они? Остальных дисквалифицировали за то, что не пользовались читом, действие которого вы в этом тесте нивелировали? :-)
feldgendler
22.10.2016 01:10Я неправильно выразился. От обучения зависят результаты только девяти решений. Если исключить возможность обучения, у девяти решений процент правильных ответов ухудшится, у остальных не изменится. Таким образом, девять строк из таблицы покинут свои места и переместятся пониже. В табличке как раз и приведено, на какие позиции они тогда попадут.
vintage
22.10.2016 01:43Так интересно-то не куда попадут эти решения, а какие оказались впереди и почему.
feldgendler
22.10.2016 09:32Первые пять мест в основном зачёте не зависят от обучения. Тот, кто был на 6 месте, съезжает на 14, тот, кто был на 15, съезжает на 30, и так далее.

knstqq
21.10.2016 13:04Ох, вот ведь незадача, вылетело-таки моё решение по потребляемой памяти. Я чистил время от времени кэш с запросами, но этого не хватило для миллиона блоков.
datacompboy
Всё это время они тестировались? :))
feldgendler
Нет, у нас один человек этим занимается, и он должен был заниматься другими критическими задачами.
jhonyxakep
как насчет призов за самый медленный алгоритм? :)
feldgendler
Хотя там в основном зачёте, кстати, было одно очень медленное решение, которое чисто для интереса оставили работать, хотя было ясно, что результат там будет даже не в сотне лучших. Но через месяц работы (на тот момент было обработано около трети тестовой последовательности) сервер пришлось перезагрузить, так что не судьба.