
 Любой программный продукт сложнее «Hello, world!» необходимо тестировать — это аксиома разработки. И чем шире его функциональность и сложнее архитектура, тем больше внимания нужно уделять тестированию. Особенно аккуратно надо относиться к гранулярному измерению производительности. Часто бывает, что в одной части ускорили, а в другой замедлили, в итоге результат нулевой. Чтобы такого не происходило, мы в своей работе очень активно используем так называемые atomic-тесты. Что это такое и с чем их едят, читайте под катом.
Любой программный продукт сложнее «Hello, world!» необходимо тестировать — это аксиома разработки. И чем шире его функциональность и сложнее архитектура, тем больше внимания нужно уделять тестированию. Особенно аккуратно надо относиться к гранулярному измерению производительности. Часто бывает, что в одной части ускорили, а в другой замедлили, в итоге результат нулевой. Чтобы такого не происходило, мы в своей работе очень активно используем так называемые atomic-тесты. Что это такое и с чем их едят, читайте под катом.Предыстория
 По мере развития Parallels Desktop нам становилось всё труднее тестировать отдельные функциональности, а также находить после очередных обновлений и оптимизаций причины ухудшения производительности виртуальной машины. Из-за сложности системы целиком покрыть её unit-тестами было практически нереально. А стандартные пакеты измерения производительности работают по неизвестным для нас алгоритмам. К тому же они заточены под измерения не в виртуальных, а в реальных окружениях, то есть стандартные бенчмарки менее «чувствительны» к вносимым изменениям.
По мере развития Parallels Desktop нам становилось всё труднее тестировать отдельные функциональности, а также находить после очередных обновлений и оптимизаций причины ухудшения производительности виртуальной машины. Из-за сложности системы целиком покрыть её unit-тестами было практически нереально. А стандартные пакеты измерения производительности работают по неизвестным для нас алгоритмам. К тому же они заточены под измерения не в виртуальных, а в реальных окружениях, то есть стандартные бенчмарки менее «чувствительны» к вносимым изменениям.Нам нужен был новый инструмент, не требующий гигантских трудозатрат, как в случае с модульными тестами, и обладающий лучшей чувствительностью и точностью по сравнению с бенчмарками.
Atomic-тесты
В результате, мы разработали набор узкоспециализированных — атомарных, atomic — тестов. Каждый из них предназначен для измерения производительности какой-либо типовой механики гипервизора (например, обработка VM-exit'ов) или операционной системы (сброс TLB-кэшей с TLB-shootdown, переключение контекстов и тому подобное). Также с помощью atomic-тестов мы оцениваем выполнение простейших операций, не зависящих от реализации операционной системы и виртуальной машины: математические вычисления, работу с памятью и диском в разных начальных условиях, и так далее.

Результат работы каждого теста — это значение какой-то определённой метрики. Одни метрики взаимосвязаны, другие нет. Результаты atomic-тестов мы дополняем информацией, полученной при автоматическом прогоне стандартных бенчмарков. Проанализировав полученные при тестировании данные, можно получить представление о том, что и с какой подсистемой произошло.

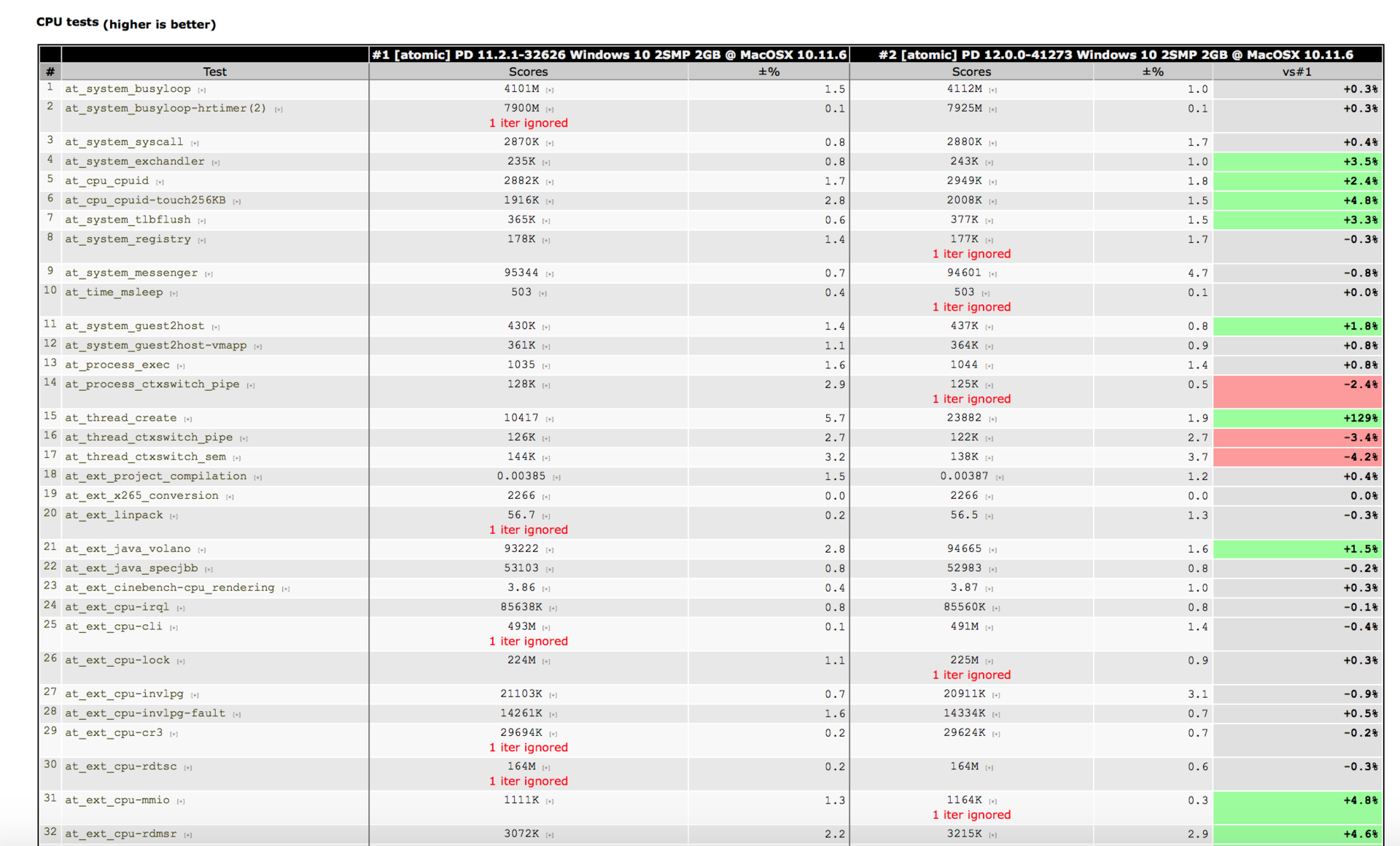
Решаемые задачи
Конечно, тестирование функциональности само по себе — работает или не работает, и если работает, то корректно? — вещь важная и необходимая. Но этим не ограничивается круг задач, решаемых нами с помощью atomic-тестов.
В первую очередь, мы ищем причины снижения производительности. Для этого мы регулярно прогоняем atomic-тесты, и если какой-то из них показал регрессию, то применяется стандартная процедура bisect: берётся вилка из двух коммитов и бинарным поиском ищется коммит, внёсший регрессию.

Бывает и так, что при очередном тестировании была выявлена регрессия, по ней заявлен баг, но у разработчиков не сразу доходят руки до выяснения причины. А когда руки все-таки доходят могут уже быть потеряны условия, при которых баг легко воспроизводится. В некоторых задачах бывает очень большой backlog, и тестировать все изменения в обратном порядке слишком долго и трудоёмко. Иногда даже непонятно, когда именно возникла деградация производительности. В таких случаях программисты работают с тем, что есть: многократно тестируют соответствующую функциональность, исследуют поведение системы в разных условиях и анализируют логи системы отладки, чтобы найти причину описанной регрессии теста.
Вторая задача, решаемая с помощью atomic-тестов — сравнение с конкурентами. Берём две системы и тестируем на одной машине под разными гипервизорами. Если наш продукт в какой-то области уступает в производительности, то разработчики начинают вдумчиво разбираться, почему так.
И третья задача — определение эффективности оптимизаций. Даже когда всё работает быстро, у разработчиков регулярно возникают какие-то идеи по улучшению архитектуры и показателей. И atomic-тесты помогают быстро выяснить, пошло ли нововведение продуктам на пользу. Нередко оказывается, что оптимизации никак не улучшают производительность, а иногда даже ухудшают.
Особенности использования atomic-тестов
Atomic-тесты могут выполняться где угодно — на хостовой или гостевой ОС. Но, как и любой тест производительности, они зависят от конфигурации операционной системы и оборудования. Так что, если запустить тесты на хостовой ОС, которая не совпадает с гостевой, то полученные результаты будут бесполезны.
Как и любым тестам производительности, им требуются определённые условия, чтобы получались воспроизводимые результаты. Хостовая ОС очень сложна (благодаря системе виртуализации) и не является операционной системой реального времени. В ней могут появляться непредсказуемые задержки, связанные с оборудованием, активизироваться различные сервисы. Гипервизор — тоже сложный программный продукт, состоящий из многочисленных компонентов, исполняющихся в пространстве пользователя, пространстве ядра и собственном контексте. Гостевая ОС подвержена тем же проблемам, что и хостовая. Так что самое сложное при использовании atomic-тестов — получить повторяемость результатов тестирования.
Как это сделать?
Важнейшее условие для получения стабильных результатов — запуск тестов роботом, всегда при одних и тех же начальных условиях:
• чистая загрузка системы
• одна и та же виртуальная машина каждый раз восстанавливается из бэкапа на физический диск, в одно и то же место
• непосредственно тесты запускаются по одним и тем же алгоритмам
Если условия проведения измерений изменились, то им ищется какое-то разумное объяснение, и всегда сравниваются результаты до и после изменений.
Примеры из жизни
Когда нужно выполнить какую-то обработку с помощью компонентов, находящихся в пространстве пользователя, гипервизору требуется переключиться из собственного контекста в контекст ядра, потом в контекст пространства пользователя и обратно. А для того, чтобы передать прерывание гостевой ОС требуется:
1) сначала вывести поток виртуального процессора из состояния покоя с помощью сигнала от хостовой ОС
2) перейти из его контекста в собственный контекст гипервизора
3) передать прерывание в гостевую ОС
Проблема в том, что процессы переключения из контекста гипервизора в контекст ядра и обратно очень медленные. И когда виртуальный процессор находится в состоянии покоя (idle), при возврате ему управления получаются очень высокие издержки.
Однажды в Parallels Desktop мы столкнулись с дефектом в MacOS X Yosemite 10.10. Система генерировала аппаратные прерывания с такой интенсивностью, что мы только и делали, что их обрабатывали, и, в результате, гостевая ОС висла. Ситуация усугублялась тем, что поступающие в контексте гостевой ОС аппаратные прерывания нужно было немедленно передать хостовой ОС. А для этого приходится два раза переключать контекст. И при большом количестве таких прерываний гостевая ОС тормозила или зависала. Именно здесь нам и пригодились наши atomic-тесты.
Несмотря на то, что проблема была исправлена в 10.10.2, для того, чтобы этого больше не происходило, и чтобы ускорить работу гостевой ОС в целом, мы постепенно оптимизировали процедуру переключения контекстов, с помощью специального atomic-теста регулярно измеряя её текущую скорость. Например, вместо того, чтобы исполняться целиком в собственном контексте, мы перенесли исполнение в контекст более приближенный к контексту пространства ядра. В результате, уменьшилось количество операций при переключениях и увеличилась скорость обработки запросов к компонентам пространства пользователя и передача управления в гостевую операционную систему из состояния покоя. В итоге все счастливы!

Будем рады ответить на вопросы в комментариях к статье. Также спрашивайте, если что-то показалось непонятным.
Поделиться с друзьями

Temmokan
Хорошо бы чаще видеть ризалты транслейтинга, чтобы читать что-нибудь вроде «тонкой настройки» взамен «файнтюнинга».
И atomic-тесты — с другой стороны. Ну назовите их атомарными, с пояснением…